一种基于分类间隔样本贡献度的SVM样本加权方法与流程
本发明涉及模式识别方法,特别是涉及一种基于分类间隔样本贡献度的支持向量机(Support Vector Machine,简称SVM)样本加权方法。
背景技术:
随着人工智能的越来越成熟,其在生产生活中得到了更多实际应用。机器学习技术作为人工智能技术中最核心算法进一步吸引了人们的目光,成为模式识别和分类算法中的研究热点。其中,统计学习理论自从提出以来就得到了广泛的应用,基于SVM的分类算法因为其结构简单、泛化能力强、学习和预测时间短、能实现全局最优等卓越性能而得到广泛关注和良好发展。特别是,SVM分类算法在解决小样本,非线性和高维模式识别上具有很大优势,被广泛应用于人脸识别,笔迹鉴定和其他相关领域。SVM算法通过满足Mercer条件的核函数,把原始空间上样本的非线性问题变换为高维空间的线性问题,实现了非线性问题的线性化,也直接关系到SVM分类算法的性能。
分类器模型训练中,为对分类有利的样本分配较大的权值是一种常用的手段,有利于训练获得的分类器模型后续的分类。基于SVM分类模型原理中,分类间隔大意味着能以充分大的确信度对训练数据进行分类。也就是说,不仅能将正负样本点分开,而且对最难分的样本点也有足够大的确信度将他们分开。这样具有较大间隔的超平面对未知的样本也将有很好的分类预测能力。
基于以上考虑,本专利提出一种基于分类间隔样本贡献度的SVM样本加权方法。基于测试样本对SVM分类器模型形成的分类间隔的贡献度,为不同样本点提供不同大小的自适应权值。让对提高分类模型性能有益的样本点具有较大权值,进而达到使构建的分类器模型对后续样本有更好的分类预测能力。
技术实现要素:
针对传统SVM分类模型对样本对分类间隔贡献度考虑的不足,提出一种基于分类间隔样本贡献度的SVM样本加权方法。不同于以往的SVM分类器模型训练方法,对样本对分类间隔贡献度的研究较少,本专利中充分考虑了分类间隔的大小对后续SVM分类器模型分类性能的影响至关重要,决定了分类器模型的后续潜在分类能力,从考虑增加分类间隔的角度为不同样本提供不同大小的权值。
基于对SVM分类算法中不同样本对分类间隔大小影响的分析,并依据实际应用中特定分类效果的偏好,设计了一种随样本不同而自适应变化的权值。通过计算不同样本对SVM算法产生分类间隔的贡献度的大小,为其分配相应的权值,使对分类间隔增加贡献度大的样本在分类器模型构建的过程中起到更大的作用,进而提高最终分类器模型的后续潜在分类能力。最后,应用本文方法进行了笔迹鉴权,实验结果证明与其它组合核函数选取方法相比,本文提出的方法具有更好表现。
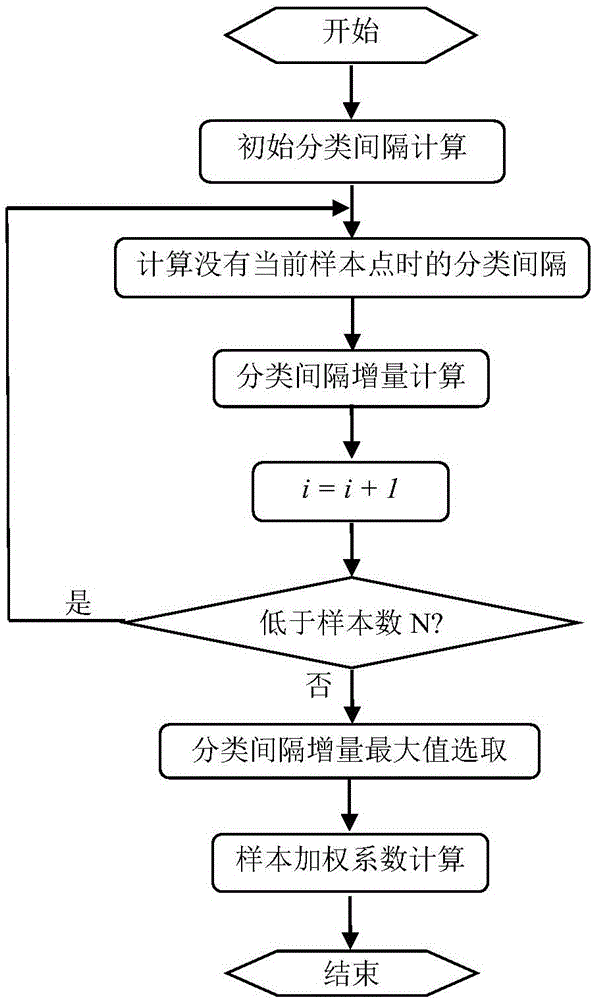
一种基于分类间隔样本贡献度的SVM样本加权方法,包括如下步骤:
(1)初始分类间隔计算
利用全部测试样本,基于SVM算法,训练分类器模型,并给出分类器模型的初始分类间隔,设为d0;
(2)计算没有当前样本点时的分类间隔
利用除去当前样本点的全部测试样本,基于SVM算法,训练分类器模型,并给出分类器模型当前的分类间隔di;
(3)分类间隔增量计算
利用公式Δdi=di-d0计算当前样本的分类间隔增量;
(4)循环计算
重复步骤(2)到(3),直到每一个样本对应的分类间隔增量都被计算;
(5)分类间隔增量最大值选取
从全部样本对应的分类间隔增量中选取出分类增量的最大值Δdmax;
(6)加权系数计算
根据公式hi=1+Δdi/Δdmax,由样本对应的分类间隔增量计算每一个样本对应的权值系数hi;
(7)样本加权
根据计算所得加权系数为样本加权。
与现有技术相比,本发明具有以下明显的优势和有益效果:
(1)本发明提出一种基于分类间隔样本贡献度的SVM样本加权方法,基于SVM算法,通过计算每个样本对分类间隔的贡献度的大小,为不同样本自适应的分配权值系数。这是基于SVM分类模型原理中,分类间隔大意味着能以充分大的确信度对训练数据进行分类。也就是说,不仅能将正负样本点分开,而且对最难分的样本点也有足够大的确信度将他们分开。这样具有较大间隔的超平面对未知的样本也将有很好的分类预测能力。
(2)本发明中充分考虑了分类间隔的大小对后续SVM分类器模型分类性能的影响至关重要,通过提高对分类性能有益样本的权值训练分类器,进而提高SVM分类器模型分类间隔,达到使构建的分类器模型对后续样本有更好的分类预测能力。
附图说明
图1为本发明所提出的一种基于分类间隔样本贡献度的SVM样本加权方法功能框图;
图2为本发明所涉及方法的流程图;
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的描述。
如图1、2所示,本发明实施例提供一种基于分类间隔样本贡献度的SVM样本加权方法,包括以下步骤:
(1)初始分类间隔计算
利用全部测试样本,基于SVM算法,训练分类器模型,并给出分类器模型的初始分类间隔,设为d0;
(2)计算没有当前样本点时的分类间隔
利用除去当前样本点的全部测试样本,基于SVM算法,训练分类器模型,并给出分类器模型当前的分类间隔di;
(3)分类间隔增量计算
利用公式Δdi=di-d0计算当前样本的分类间隔增量;
(4)循环计算
重复步骤(2)到(3),直到每一个样本对应的分类间隔增量都被计算;
(5)分类间隔增量最大值选取
从全部样本对应的分类间隔增量中选取出分类增量的最大值Δdmax;
(6)加权系数计算
根据公式hi=1+Δdi/Δdmax,由样本对应的分类间隔增量计算每一个样本对应的权值系数hi;
(7)样本加权
根据计算所得加权系数为样本加权。
运用本发明方法到笔迹验证试验中。本实验中,根据实验需求每次从HIT-MW样本库随机的选取2个不同人的10份笔迹样本。其中,8份笔迹作为训练样本,2份笔迹作为测试样本,更换不同人的笔记样本,重复上述试验多次,取平均精度。对笔迹书写人身份进行判断,当测试样本采用权值设置时,其分类精度可达到96.52%,而未采用样本加权的SVM分类器模型,其对应的分类精度为93.17%。
- 还没有人留言评论。精彩留言会获得点赞!