物体识别模型的建立方法及物体识别方法与流程
本发明实施例涉及模式识别、机器学习及计算机视觉技术领域,具体涉及一种物体识别模型的建立方法及物体识别方法。
背景技术:
进入二十一世纪以来,随着互联网技术的快速发展,以及手机、相机、个人电脑的普及,图像数据呈现出爆炸式增长。google+推出100天就上传了34亿张图片,而著名的社交网站facebook的图片数据更是超过了100亿。另一方面,随着建设平安城市的需要,监控摄像头的数量越来越多,据不完全统计,仅北京市的监控摄像头数量就超过了40万个,而全国的监控摄像头数量更是达到2000多万,并仍以每年20%的数量增长。如此大规模的数据远远超出了人类的分析处理能力。因此,智能地处理这些图像和视频数据成为迫切需要。在这种背景下,如何利用计算机视觉技术自动、智能地分析理解图像数据受到人们的广泛关注。
物体识别是计算机视觉任务中的经典问题,同时也是解决很多高层视觉任务的核心问题,物体识别的研究为高层视觉任务(例如:行为识别、场景理解等)的解决奠定了基础。它在人们的日常生活中以及工业生产中有着广泛的应用,如:智能视频监控、汽车辅助驾驶、无人车驾驶、生物信息身份认证、智能交通、互联网图像检索、虚拟现实以及人机交互等。
近几十年来,随着大量统计机器学习算法在人工智能和计算机视觉领域的成功应用,计算机视觉技术有了突飞猛进的进步。尤其是近年来,大数据时代的到来为视觉任务提供了更加丰富的海量图像数据,高性能计算设备的发展给大数据计算提供了硬件支持,大量成功的计算机视觉算法不断地涌现出来。尽管如此,计算机视觉技术与人的视觉认知能力仍存在很大的差距,尤其是在物体识别任务中仍存在很大量的挑战和难题。这主要是由于真实图像中的物体往往存在复杂的弹性变形、姿态变化、以及拍摄视角变化等问题。这使得物体的表观差异非常大,因此,传统的机器学习算法很难处理这些含有复杂形变的图像样本。
有鉴于此,特提出本发明。
技术实现要素:
为了解决现有技术中的上述问题,即为了解决视觉任务中物体复杂的弹性变形、姿态变化及视觉变化的技术问题而提供一种物体识别模型的建立方法及基于该建立方法的物体识别方法。
为了实现上述目的,提供以下技术方案:
一种物体识别模型的建立方法,其特征在于,所述方法包括:
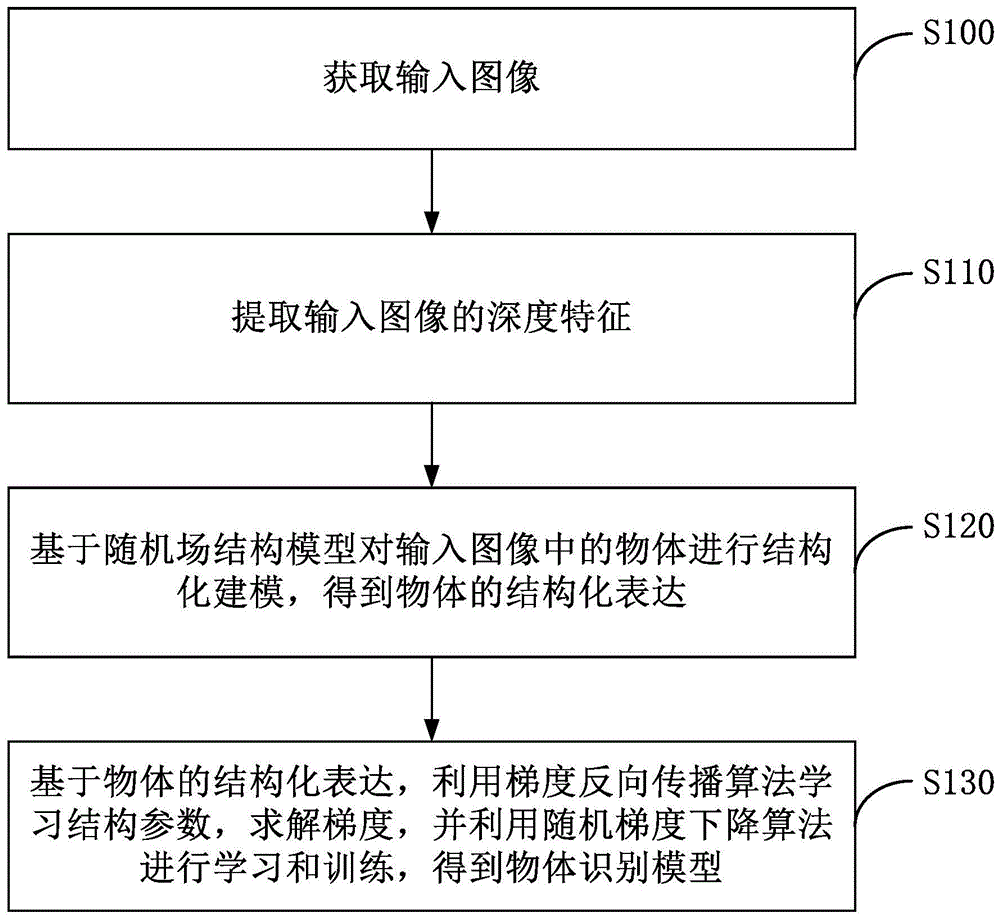
获取输入图像;
提取所述输入图像的深度特征;
基于随机场结构模型对所述输入图像中的物体进行结构化建模,得到所述物体的结构化表达;
基于所述物体的所述结构化表达,利用梯度反向传播算法学习结构参数,求解梯度,并利用随机梯度下降算法进行学习和训练,得到物体识别模型。
进一步地,所述提取所述输入图像的深度特征具体可以包括:
利用卷积神经网络模型的卷积层和池化层,提取所述输入图像的所述深度特征。
进一步地,所述基于随机场结构模型对所述输入图像中的物体进行结构化建模,得到所述物体的结构化表达具体可以包括:
对所述输入图像的深度特征进行部件卷积操作,得到所述输入图像中所述物体各个部件的表观表达;
对所述物体各个部件的表观表达进行结构池化操作,确定所述物体各部件的最优位置;
基于所述物体各部件的最优位置,利用平均场算法对随机场结构模型进行推理,获得所述物体的所述结构化表达。
进一步地,所述对所述输入图像的深度特征进行部件卷积操作,得到所述输入图像中所述物体各个部件的表观表达具体可以包括:
根据以下公式将所述物体各部件的部件滤波器在所述部件滤波器变形区域内进行卷积,从而得到所述输入图像中所述物体各个部件的所述表观表达:
zi(di)=wi·φ(h,pi,di);
其中,所述i表示所述物体部件个数;所述h表示结构网络层的输入特征;所述wi表示第i个部件滤波器的权重;所述pi表示所述第i个部件滤波器的初始位置;所述di表示所述第i个部件滤波器的变形量;所述φ(h,pi,di)表示在pi+di处的输入响应;所述zi(di)表示所述部件在响应位置的分数。
进一步地,所述对所述物体各个部件的表观表达进行结构池化操作,确定所述物体各部件的最优位置具体可以包括:
根据以下公式确定所述物体各部件之间的变形结构损失:
其中,所述u(di,dj)表示第i和第j个部件之间的连接权重;所述fi表示所述第i个部件的特征矢量;所述fj表示所述第j个部件的特征矢量;所述k(m)(·)表示作用在特征空间上的高斯函数;所述m表示所述高斯函数的个数;所述w(m)表示第m个高斯函数的权重,其中高斯核为
最小化以下能量函数,从而确定所述物体各部件的最优位置:
其中,e(d)表示能量函数。
进一步地,所述基于所述物体各部件的最优位置,利用平均场算法对随机场结构模型进行推理,获得所述物体的所述结构化表达具体可以包括:
根据以下公式获得所述物体的结构化表达:
其中,所述
进一步地,所述基于所述物体的所述结构化表达,利用梯度反向传播算法学习结构参数,求解梯度,并利用随机梯度下降算法进行学习和训练,得到物体识别模型具体可以包括:
根据以下公式确定结构网络层关于wi的梯度:
其中,所述l表示所述物体识别模型的最终损失;所述yi表示所述第i个部件的结构网络层输出;所述
根据以下公式确定所述结构网络层关于w(m)的梯度:
其中,所述
基于所述结构网络层关于wi的梯度和所述结构网络层关于w(m)的梯度,利用随机梯度下降算法进行端到端的学习和训练,得到所述物体识别模型。
为了实现上述目的,还提供以下技术方案:
一种基于上述建立方法的物体识别方法,所述物体识别方法包括:
获取待测图像;
利用上述建立方法建立的物体识别模型对所述待测图像进行识别,以预测所述待测图像中物体的类别。
本发明实施例提供一种物体识别模型的建立方法和物体识别方法。其中,该物体识别模型的建立方法包括:获取输入图像;提取输入图像的深度特征;基于随机场结构模型对输入图像中的物体进行结构化建模,得到物体的结构化表达;基于物体的结构化表达,利用梯度反向传播算法学习结构参数,求解梯度,并利用随机梯度下降算法进行学习和训练,得到物体识别模型。从中可见,本发明实施例同时结合了深度学习和结构模型的各自优势,提高了深度网络模型的结构表达能力,解决了视觉任务中物体复杂的弹性变形、姿态变化及视觉变化的技术问题。本发明实施例可以应用于诸如物体分类、物体检测、人脸识别等涉及物体识别的众多领域。
附图说明
图1为根据本发明实施例的物体识别模型的建立方法的流程示意图;
图2为根据本发明实施例的物体识别方法的流程示意图;
图3为根据本发明另一实施例的物体识别方法的流程示意图。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
本发明实施例的核心思想是在深度学习算法中提出一个新的结构网络层,并利用平均场算法对其进行快速结构推理,利用一种结构网络层来建模物体的内在结构属性,从而表达物体的不同表观变化,并利用深度学习算法对该深度结构模型进行端到端的训练,从而学习到有效的结构参数,最后获得物体的结构表达。
本发明实施例提供一种物体识别模型的建立方法。该方法可以包括:
s100:获取输入图像。
其中,该输入图像就可以是整幅图像,也可以是整幅图像中可能存在目标的感兴趣区域(图像区域)。例如:在图像分类任务中,整幅图像即为输入图像。在物体检测任务中,输入图像为图像中可能存在目标的感兴趣区域。
s110:提取输入图像的深度特征。
具体地,本步骤利用卷积神经网络模型的卷积层和池化层,提取输入图像的深度特征。
本发明实施例将深度特征作为输入图像的表观表达。
s120:基于随机场结构模型对输入图像中的物体进行结构化建模,得到物体的结构化表达。
本步骤对物体识别模型的网络层进行结构化建模,建立一种结构网络层。该结构网络层包括部件卷积操作和结构池化操作。其中,部件卷积操作和结构池化操作可以分别看成是物体的表观特征表达层与物体的视觉结构表达层。
具体地,本步骤可以包括:
s121:对输入图像的深度特征进行部件卷积操作,得到输入图像中物体各个部件的表观表达。
部件卷积操作利用不同的部件滤波器来对物体不同的局部区域进行表观建模。具体地,利用多个部件滤波器对物体进行描述,并将部件滤波器在其变形区域内的卷积响应当作是物体的表观特征表达。
例如:假设物体的部件在一定的区域附近变形,部件滤波器在一定的变形区域内对物体做卷积,并将卷积响应作为待测图像中物体的表观特征(也即外观表达)。部件滤波器在变形区域内的卷积响应就是该部件模型在其区域内的表达。
本步骤将图像的深度特征输入结构网络层,利用结构网络层来建模物体的内在结构属性,表达物体的不同表观变化,然后利用部件滤波器在其变形区域内卷积,并将卷积响应作为物体各个部件的表观表达。
在实际应用中,本步骤可以根据以下公式将代表物体不同部件的部件滤波器在部件滤波器变形区域内进行卷积,从而得到输入图像中物体各个部件的表观表达:
zi(di)=wi·φ(h,pi,di);
其中,i表示物体部件个数;h表示结构网络层的输入特征;wi表示第i个部件滤波器的权重;pi表示第i个部件滤波器的初始位置;di表示第i个部件滤波器的变形量;φ(h,pi,di)表示在pi+di处的输入响应;zi(di)表示部件在响应位置的分数。
s122:对物体各个部件的表观表达进行结构池化操作,确定物体各部件的最优位置。
为了推理出物体各个部件的最优位置,本发明实施例采取结构池化操作。本步骤将部件卷积操作得到的各个部件的表观表达输入结构池化层,对物体进行结构表达。
其中,结构池化操作对物体部件之间的结构关系进行建模,并推理物体各部件的最优位置。例如:全连接的二阶随机场模型对物体部件之间的关系之间建模。相邻部件之间的损失势能是一个高斯损失函数。
在一些可选的实施方式中,本步骤可以通过以下方式来实现:
s1221:根据以下公式确定物体各部件之间的变形结构损失:
其中,i和j表示物体部件个数;di表示第i个部件滤波器的变形量;dj表示第j个部件滤波器的变形量;u(di,dj)表示第i和第j个部件之间的连接权重;fi表示第i个部件的特征矢量;fj表示第j个部件的特征矢量;k(m)(·)表示作用在特征空间上的高斯函数;w(m)表示第m个高斯函数的权重,高斯核为
部件i和部件j的参考位置距离越近,则两个部件之间的联系越强,反之越弱。
s1222:最小化以下能量函数,从而确定物体各部件的最优位置:
其中,zi(di)表示部件滤波器在响应位置的分数;
在实际应用中,在随机场模型中,最小化e(d)的求解可以等价于最小化吉布斯能量函数。
s123:基于物体各部件的最优位置,利用平均场算法对随机场结构模型进行推理,获得物体的结构化表达。
在本步骤中,平均场算法将全连接的高斯条件随机场的推理问题转化为高斯核卷积过程。其中,平均场算法的步骤例如可以包括:将softmax函数作用在所有节点的一阶势能项上;进行消息传递,用高斯核在随机场模型的概率分布上进行卷积;进行高斯滤波器加权输出;考虑节点之间的变形信息,进行二阶项转换;增加各自节点的一阶项;进行归一化操作,对每个节点进行软最大化(softmax)操作。
具体地,本步骤可以根据以下公式获得物体的结构化表达:
其中,
本步骤对物体的结构信息进行建模,得到的结构表达同时考虑了物体部件的表观特征,同时又考虑了部件之间的结构关系,从而得到网络层的最终结构输出。
s130:基于物体的结构化表达,利用梯度反向传播算法学习结构参数,求解梯度,并利用随机梯度下降算法进行学习和训练,得到物体识别模型。
其中,本步骤可以通过以下方式来现实:
s131:根据以下公式确定结构网络层关于wi的梯度:
其中,i表示物体部件个数;h表示结构网络层的输入特征;pi表示第i个部件滤波器的初始位置;di表示第i个部件滤波器的变形量;l表示物体识别模型的最终损失;
s132:根据以下公式确定结构网络层关于w(m)的梯度:
其中,
s133:基于结构网络层关于wi的梯度和结构网络层关于w(m)的梯度,利用随机梯度下降算法进行端到端的学习和训练,得到物体识别模型。
作为示例,本发明实施例可以将最后一层卷积神经网络层和池化层用经过步骤s131至步骤s133得到的结构网络层代换,并用随机梯度下降算法进行训练,从而得到物体识别模型。
本发明实施例同时结合了深度学习和结构模型的各自优势,利用结构网络层来建模物体的内在结构属性,从而表达物体的不同表观变化,并利用深度学习算法对该深度结构模型进行端到端的训练,从而学习到有效的结构参数,同时提高了深度网络模型的结构表达能力。本发明实施例得到的物体识别模型比传统的卷积神经网络模型具有更强的物体表达能力,在物体分类任务中能取得更好的分类结果。
此外,本发明实施例还提供一种基于上述建立方法的物体识别方法。如图2所示,该方法可以包括:
s200:获取待测图像。
s210:利用上述物体识别模型的建立方法所建立的物体识别模型对待测图像进行识别,以预测待测图像中物体的类别。
本发明实施例通过采用上述技术方案,解决了视觉任务中物体复杂的弹性变形、姿态变化及视觉变化的技术问题。
如图3所示,下面以一优选的实施例来更好地说明本发明。
步骤s301:获取输入图像。
其中,该输入图像就可以是整幅图像,也可以是整幅图像中可能存在目标的感兴趣区域(图像区域)。例如:在图像分类任务中,整幅图像即为输入图像。在物体检测任务中,输入图像为图像中可能存在目标的感兴趣区域。在训练过程中,物体的标注数据已知,例如:分类任务中图像中所包含物体的类别,检测任务中物体的类别以及所在的位置。
步骤s302:对输入图像进行预处理。
本步骤将输入图像(即整幅图像或图像区域)归一化到统一大小,比如256×256,并减去均值图像,然后将其输入要训练的深度结构网络。其中,均值图像指的是将所有归一化到统一大小的图像在每个像素上的rgb值分别求平均所得到的结果。
步骤s303:提取预处理后图像的深度特征。
本步骤利用卷积神经网络模型的卷积层和池化层对预处理后的图像进行提取特征,作为图像的表观表达。
步骤s304:对提取的深度特征进行部件卷积操作,得到物体各个部件的表观表达。
本步骤将图像的深度特征输入结构网络层,然后利用部件滤波器在其变形区域内卷积,并将卷积响应作为物体各个部件的表观表达。
步骤s305:对物体各个部件的表观表达进行结构池化操作。
本步骤将部件卷积操作得到的各个部件的表观表达输入结构池化层,利用建模好的结构模型对物体进行结构表达,并利用平均场模型对物体各个部件的最优位置进行快速推理,最终获得结构网络层的输出。
步骤s306:基于深度学习的参数训练,得到深度结构网络模型。
本步骤利用链式法则求解结构网络层的参数梯度,并利用随机梯度下降算法对深度结构网络模型中的参数进行训练。
步骤s307:利用深度结构网络模型对待测试图像中的物体进行识别。
本步骤将结构网络层的响应输入到全连接层,并最终得到物体类别的预测,从而得到物体识别结果。本发明实施例可以应用于诸如物体分类、物体检测、人脸识别等涉及物体识别的众多领域。
需要说明的是,对一个实施例的说明可以应用于另一个实施例,在此不再赘述。
上述实施例中虽然将各个步骤按照上述先后次序的方式进行了描述,但是本领域技术人员可以理解,为了实现本实施例的效果,不同的步骤之间不必按照这样的次序执行,其可以同时(并行)执行或以颠倒的次序执行,这些简单的变化都在本发明的保护范围之内。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围并不局限于此。在不偏离本发明的原理的前提下,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!