基于FP增长算法模型的中药配方数据挖掘方法及系统与流程
本发明涉及数据处理
技术领域:
,尤其涉及一种基于FP增长算法模型的中药配方数据挖掘方法及系统。
背景技术:
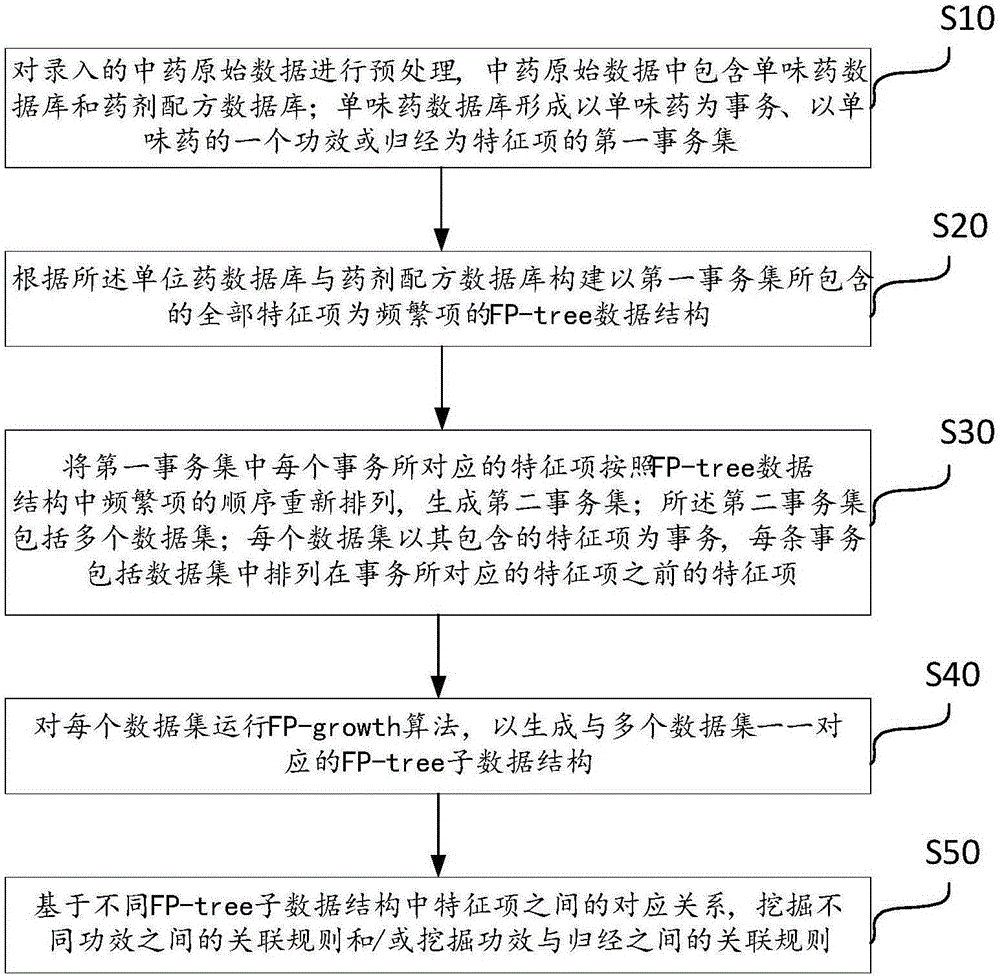
:目前,方剂数据预处理方法大多数是按照词典或者教科书的内容,再人为进行分类处理,例如对症状名和药物别名的处理,缺乏客观性和统一标准。并且现有配方挖掘系统需要手动输入药方或者药材名称,然后从数据库里面检索抓取合适的药方配伍信息,在这过程中由于常用药材的药方组合非常多,大量的信息干扰增加了制定药方时检索的用时。技术实现要素:本发明的主要目的在于提供一种基于FP增长算法模型的中药配方数据挖掘方法及系统,旨在通过对现有数据库的挖掘,提供向用户提供药材的功效以及功效与归经的关联关系,以减少信息干扰,便于用户快速制定药方。为实现上述目的,本发明提供的一种基于FP增长算法模型的中药配方数据挖掘方法包括以下步骤:对录入的中药原始数据进行预处理,所述中药原始数据中包含单味药数据库和药剂配方数据库;所述单味药数据库形成以单味药为事务、以所述单味药的一个功效或归经为特征项的第一事务集;根据所述单位药数据库与药剂配方数据库构建以所述第一事务集所包含的全部特征项为频繁项的FP-tree数据结构;将所述第一事务集中每个事务所对应的特征项按照所述FP-tree数据结构中频繁项的顺序重新排列,生成第二事务集;所述第二事务集包括多个数据集;每个所述数据集以其包含的所述特征项为事务,每条所述事务包括所述数据集中排列在所述事务所对应的特征项之前的特征项;对每个所述数据集运行FP-growth算法,以生成与所述多个数据集一一对应的FP-tree子数据结构;基于不同所述FP-tree子数据结构中特征项之间的对应关系,挖掘不同功效之间的关联规则和/或挖掘功效与归经之间的关联规则。优选地,所述药剂配方数据库包含药剂配方及其组成和功效;构建以所述第一事务集所包含的全部特征项为频繁项的FP-tree数据结构包括:扫描所述第一事务集,以所述第一事务集中所包含的全部特征项生成第一频繁项集,按照所述特征项在所述药剂配方中出现的频次为支持度,降序排列所述第一频繁项集,以生成项头表;按照重新排列的顺序把每个所述事务的每个频繁项插入以null为根的FP-tree中;如果插入时频繁项节点已经存在了,则把该频繁项节点支持度加1;如果插入时频繁项节点不存在,则创建支持度为1的节点,并把该节点链接到所述项头表中。优选地,所述对每个所述数据集运行FP-growth算法,以生成与所述多个数据集一一对应的FP-tree子数据结构包括:以所述数据集中所包含的全部特征项生成第二频繁项集,通过FP-growth算法获得同一频繁项在所述FP-tree数据结构中的所有节点的祖先路径的集合,取并集得到支持度大于阈值的所有模式;循环获得所述数据集中每一频繁项支持度大于阈值的所有模式;形成所述数据集中条件模式基;将所述条件模式基按照FP-tree的数据结构形成节点链。优选地,所述将所述条件模式基按照FP-tree的数据结构形成所述FP-tree子数据结构之后还包括:根据所述FP-tree子数据结构获得每个所述频繁项的频繁模式,所述频繁模式包含所有与所述频繁项具有关联的特征项及其与所述频繁项关联的支持度。优选地,所述基于不同所述FP-tree子数据结构中特征项之间的对应关系,挖掘不同功效之间的关联规则包括:遍历各所述FP-tree子数据结构,若两个不同所述FP-tree子数据结构的子项头表中存在相同的特征项,则在该两个不同所述FP-tree子数据结构的子项头表之间建立索引指向;重复所述遍历各所述FP-tree子数据结构,若两个不同所述FP-tree子数据结构的子项头表中存在相同的特征项,则在该两个不同所述FP-tree子数据结构的子项头表之间建立索引指向;直到遍历完成所有所述FP-tree子数据结构。此外,为实现上述目的,本发明还提供一种基于FP增长算法模型的中药配方数据挖掘系统包括:预处理模块,用于对中药原始数据进行预处理,所述中药原始数据中包含单味药数据库和药剂配方数据库;所述单位药数据库形成以单味药为事务、以所述单味药的一个功效或归经为特征项的第一事务集;FP-tree模块,用于以所述第一事务集所包含的全部特征项为频繁项构建FP-tree数据结构;数据划分模块,用于把所述第一事务集中每个事务所对应的特征项按照所述FP-tree数据结构中频繁项的顺序重新排列,生成第二事务集;所述第二事务集包括多个数据集;每个所述数据集以其包含的所述特征项为事务,每条所述事务包括所述数据集中排列在所述事务所对应的特征项之前的特征项;FP-tree子模块,用于对每个所述数据集运行FP-growth算法,以生成与所述多个数据集一一对应的FP-tree子数据结构;挖掘模块,用于基于不同所述FP-tree子数据结构中特征项之间的对应关系,挖掘不同功效之间的关联规则和/或挖掘功效与归经之间的关联规则。优选地,所述FP-tree模块包括:项头表模块,用于扫描所述第一事务集,以所述第一事务集中所包含的全部特征项生成第一频繁项集,按照所述特征项在所述药剂配方中出现的频次为支持度,降序排列所述第一频繁项集,以生成项头表;排序模块,用于按照重新排列的顺序把每个所述事务的每个频繁项插入以null为根的FP-tree中;如果插入时频繁项节点已经存在了,则把该频繁项节点支持度加1;如果插入时频繁项节点不存在,则创建支持度为1的节点,并把该节点链接到所述项头表中。优选地,所述FP-tree子模块包括:路径模块,用于以所述数据集中所包含的全部特征项生成第二频繁项集,通过FP-growth算法获得同一频繁项在所述FP-tree数据结构中的所有节点的祖先路径的集合,取并集得到支持度大于阈值的所有模式;循环获得所述数据集中每一频繁项支持度大于阈值的所有模式;形成所述数据集中条件模式基;节点链模块,用于将所述条件模式基按照FP-tree的数据结构形成节点链。优选地,所述系统还包括:频繁式模块,用于根据所述FP-tree子数据结构获得每个所述频繁项的频繁模式,所述频繁模式包含所有与所述频繁项具有关联的特征项及其与所述频繁项关联的支持度。优选地,所述挖掘模块包括:索引模块,用于遍历各所述FP-tree子数据结构,若两个不同所述FP-tree子数据结构的子项头表中存在相同的特征项,则在该两个不同所述FP-tree子数据结构的子项头表之间建立索引指向;循环模块,用于重复所述遍历各所述FP-tree子数据结构,若两个不同所述FP-tree子数据结构的子项头表中存在相同的特征项,则在该两个不同所述FP-tree子数据结构的子项头表之间建立索引指向;直到遍历完成所有所述FP-tree子数据结构。本发明的方案,通过与中药原始数据进行预处理,获得能够通过算法规则进行运算数据,根据单味药数据库与药剂配方数据库之间的联系,构建以所有单味中药的所有功效为频繁项的FP-tree数据结构,根据FP-tree数据结构对现有单味药数据库按照每一味药重新分为多个数据集,每个数据集根据FP-tree数据结构的节点链,挖掘单味药中不同功效之间的关联规则,以及单味药中功效与归经之间的关联规则,从而获得每一味药的功效关联置信度,功效归经关联置信度,从而减少检索过程中的信息干扰。附图说明图1a为本发明基于FP增长算法模型的中药配方数据挖掘方法第一实施例的流程示意图;图1b为本发明基于FP增长算法模型的中药配方数据挖掘方法第一实施例中获得药物模糊剂量的流程图;图2为FP-tree数据结构的示意图;图3为本发明基于FP增长算法模型的中药配方数据挖掘方法第二实施例中构建FP-tree数据结构步骤的细化流程示意图;图4为本发明基于FP增长算法模型的中药配方数据挖掘方法第三实施例中生成FP-tree子数据结构步骤的细化流程示意图;图5为图2中I5的FP-tree的示意图;图6为图2中I3的FP-tree的示意图;图7为图2中I1的FP-tree的示意图;图8为本发明药配方数据挖掘方法第四实施例的流程示意图;图9为本发明基于FP增长算法模型的中药配方数据挖掘方法第五实施例中挖掘关联规则步骤的细化流程示意图;图10为本发明基于FP增长算法模型的中药配方数据挖掘系统一实施例的功能模块示意图;图11为本发明基于FP增长算法模型的中药配方数据挖掘系统另一实施例的功能模块示意图。本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。具体实施方式应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。本发明提供一种基于FP增长算法模型的中药配方数据挖掘方法,参照图1a,在一实施例中,该方法包括:步骤S10,对录入的中药原始数据进行预处理,所述中药原始数据中包含单味药数据库和药剂配方数据库;所述单味药数据库形成以单味药为事务、以所述单味药的一个功效或归经为特征项的第一事务集;数据预处理是数据挖掘过程中的一个重要步骤,包括数据清洗、数据集成、数据转换和数据消减。其目的是提高数据挖掘对象的质量,并最终达到提高数据挖掘所获模式知识质量的目的。原始数据中包含单味药数据库和药剂配方数据库,单味药数据库中包含若干味药材,以及对应于每味药材的若干功效和归经;药剂配方数据库中包含若干药剂配方,以及对应于每个药剂配方中的药剂组成、药剂含量及药剂功效、归经;首先录入中药原始数据并进行预处理,提取质量高的数据作为采样样本,并对上述药材、功效、归经分别进行标号,以便后续的计算和处理。例如录入的单味药的原始数据内容参见表1.1:表1.1药物基本属性表示例求功效-功效关联时,将每味药的功效组合看成一个项集,参见表1.2:表1.2功效-功效关联输入项集TID功效项集列表T13018130111301193020330259T230181302433026330203……求功效-归经关联时,将每味药的功效组合和归经组合看成一个项集,如表1.3。其中“3”开头的数字代码表示功效,“5”开头的数字代码表示归经。表1.3功效-归经关联输入项集TID功效项集列表T1301813011130119302033025930132500025000650005T2301813024330263302035000250005……对方剂(即药剂配方)原始数据处理过程如下:1)方剂原始数据录入处理。在《方剂学》中对具体方剂的描述包括方剂名、组成、用法、功用等,如表2.1所示:表2.1通过对文档信息的规范与提取,将获得的方剂数据按照下表2.2的格式录入到数据库当中。方剂处理后的数据表2.22)中药原始数据处理。在中药的描述中包括药名、来源、性能、功效等,如表2.3所示。表2.3通过对文档信息的规范与提取,将每味药物的基本属性和应用分别录入到数据库中。药物的基本属性标识如表2.4药物的应用标识表2.5病案数据整理在原始病案数据采集完毕后,对每个病案进行处理,每个病例都用症状、辩证、治法、处方来藐视,如表2.6所示。并直接按照编号、姓名、年龄、症状、辩证等格式录入数据库。原始病例数据示例表2.6对数据库里出现的药物、功效等词语进行提取的时候,判断标准此表中的每个词条是否在文本中存在,记录存在的词条在文本中出现的位置,加到结果数组中。最后对所有查找存在的词条进行筛选,保留长的词条,并按照在文本中出现的顺序进行排序。在文本中药物用量紧接着药物名称,所以如果需要获得方剂中的药物用量,则可以从对应的药物名称所在的位置开始查找数字,得到的结果即为药物的用量。经过药物、功效等提取后的方剂如表2.7所示,结果用代码表示,便于后期关联、匹配等算法的处理。表2.7方名麻黄汤组成麻黄9g,桂枝6g,杏仁尖6g,甘草炙3g药物代码40113400044009340088剂量9663功效代码30002300073000430155下面通过对方剂数据中的药剂量信息进行处理,获得方剂中药剂量的模糊剂量,用于提示用户在使用该方剂时每味药的安全剂量上限。以提高方剂在使用过程中的安全性能。如从系统中已有的药方中,提取出的每一味药的剂量表现形式有离散型(9g)和连续型(4.5g-6g)两种。要判断不同的药方中的同一味药的用量是否相同,如果仅从药剂量的绝对数值判断是不合理的,例如两个药方中的当归分别为9g与10g,我们可以认为它们是处于同一个用量等级,用量是相同的。所以系统使用时需要将剂量数值模糊化至对应的低、中、高药量区间中,参见图1b。首先统计每味药在所有的方剂和病案中出现的剂量和频次,把这些剂量聚成三类,然后将类中心进行模糊化,通过三角函数模型计算隶属度将绝对的药剂量模糊为药物用量区间。具体参见以下步骤:步骤1,统计每味药在所有方剂中剂量出现的频次,例如人参5g100次,人参50g5次,……。步骤2,提取每味药剂量的数值信息,对其按照公式(2.1)计算。对于剂量单位为kg的,换算成为以g为单位。这里的连续指的是自然数的连续,例如2、3、4则认为是连续值,2、5、8则认为是离散值。步骤3,对药剂进行聚类,并判断聚类结果中是否有异常数据,如果有并去除异常数据。分析剂量时,我们用“L(低)、M(中)、H(高)”三个模糊区域来表示药剂用量。选择K-均值方法对每味药的剂量进行聚类分析,取K=3.由于具体到每一味药的剂量数据量较小,并且存在噪声数据,所以对初次聚成的聚类中心需要进行合理性判断,如果判断不合理则去除干扰数据重新聚类。如果样本最大中心的数据比最小中心的数据大10倍以上,则视为异常数据,例如人参5g出现100次,人参50g出现5次,则认为人参50g为异常数据,去除后重新进行聚类。表2.8:聚类结果药名当归白芍剂量中心L(g)5.279.68剂量中心M(g)11.5316.64剂量中心H(g)9056步骤4,通过三个模糊集函数获得隶属度函数;模糊集函数表示如下:模糊集L:模糊集M:模糊集H:综合以上三式得隶属度函数为:步骤5,由各个方剂中的药剂的绝对剂量,根据上述隶属度函数获得方剂中药剂量的模糊剂量。以麻黄汤为例,剂量模糊处理结果如表2.9:表2.9:麻黄汤剂量模糊处理结果组成药物麻黄桂枝杏仁尖甘草炙药物代码40113400044009340088绝对剂量(g)9663模糊剂量1.0001.0001.0001.000这个结果提示用户,在麻黄汤这个药剂处方中麻黄的用量最多不得超过10g,最少不能低于8g;桂枝的用量最多不得超过7g,最少不能低于5g;杏仁尖的用量最多不得超过7g,最少不能低于5g;甘草炙的用量最多不得超过4g,最少不能低于2g。步骤S20,根据所述单位药数据库与药剂配方数据库构建以所述第一事务集所包含的全部特征项为频繁项的FP-tree数据结构;把单味药数据库看成一个事务集,每味药材为一条事务,每味药材对应的功效和/或归经为事务的特征(如果挖掘功效-功效之间的关联规则,需要利用表1.2功效-功效关联输入项集,如果挖掘功效-归经之间的关联规则,需要利用表1.3功效-归经关联输入项集),构建FP-tree数据结构;该数据结构中以所有药材的功效和/或归经为频繁项,根据药材出现在配方中的频率对频繁项进行降序排列,构件项头表;由FP-tree算法生成节点链。FP-Tree算法的基本数据结构,包含一个一棵FP树和一个项头表,每个项通过一个结点链指向它在树中出现的位置。基本结构如下所示。需要注意的是项头表需要按照支持度递减排序,在FP-Tree中高支持度的节点只能是低支持度节点的祖先节点。参见图2。步骤S30,把所述第一事务集中每个事务所对应的特征项按照所述FP-tree数据结构中频繁项的顺序重新排列,生成第二事务集;所述第二事务集包括多个数据集;每个所述数据集以其包含的所述特征项为事务,每条所述事务包括所述数据集中排列在所述事务所对应的特征项之前的特征项;将单味药材库即上述事务集(表1.2功效-功效关联输入项集或表1.3功效-归经关联输入项集)进行划分,可分为若干数据集,每个数据集包含一味药材,及该味药材具备的功效和/或归经;按照这个排列顺序对数据集中的功效进行重新排列,数据集中以每个特征项为事务,每条事务包括排列在该事务对应的特征项之前的特征项;例如,进行功效关系规则挖掘,即每味中药的数据形成一个数据集,这个数据集中,构成的功效作为事务,其他排列在作为事务的功效的之前的功效作为该事务的特征项,参见图2,加入图2为其中一味中药的FP-Tree数据结构,那么它包含四条事务(I5、I4、I3、I1),功效I5的特征项为:I4、I3、I1、I2;功效I4的特征项为:I3、I1、I2;功效I3的特征项为:I1、I2;功效I1的特征项为:I2。步骤S40,对每个所述数据集运行FP-growth算法,以生成与所述多个数据集一一对应的FP-tree子数据结构;FP-growth算法的核心在于通过FP-growth函数的递归调用获得条件模式基,在此基础上将条件模式基按照FP-Tree的构造原则形成的一个新的FP-Tree,即FP-tree子数据结构。这里相当于获得条件模式基,包含FP-Tree中与后缀模式一起出现的前缀路径的集合。也就是同一个频繁项在PF树中的所有节点的祖先路径的集合。比如I3在图2中的FP-Tree中一共出现了3次,其祖先路径分别是{I2,I1:2(频度为2)},{I2:2}和{I1:2}。这3个祖先路径的集合就是频繁项I3的条件模式基。具体计算过程如下:调用FP-growth(Tree,null)开始进行挖掘。伪代码如下:FP-growth函数的输入:tree是指原始的FPTree或者是某个模式的条件FPTree,a是指模式的后缀(在第一次调用时a=NULL,在之后的递归调用中a是模式后缀)。FP-growth函数的输出:在递归调用过程中输出所有的模式及其支持度(比如{I1,I2,I3}的支持度为2)。每一次调用FP_growth输出结果的模式中一定包含FP_growth函数输入的模式后缀。模拟一下FP-growth的执行过程。1、在FP-growth递归调用的第一层,模式前后a=NULL,得到的其实就是频繁1项集。2、对每一个频繁1项集,进行递归调用FP-growth()获得多元频繁项集。将条件模式基按照FP-Tree的构造原则形成I3的FP-Tree。参照图3,可以看出,表现的是与I3有关联的功效,及其关联支持度。步骤S50,基于不同所述FP-tree子数据结构中特征项之间的对应关系,挖掘不同功效之间的关联规则和/或挖掘功效与归经之间的关联规则。基于前面步骤S10~S40,能够获得所有功效之间的关联关系,以及功效与归经之间的关联关系,遍历各FP-tree子数据结构,即可获得不同功效之间的关联规则和/或挖掘功效与归经之间的关联规则。本发明的方案,从海量中药方数据中提取出常用的处方数据,并结合国家中药词典标准进行规范化处理;在收集的海量中药方数据中利用数据挖掘方法对药对、药组进行关联分析、数据提取,组成常用药对药组,并对频繁集进行有效梳理,使得用户在采用该系统下药方时自动精准地进行有效药方配对,减少用户对药方数据库查询检索时间,并有辅助学习功能,对常用的药方及对应症状进行归纳分析,加深医务人员在药方检索时的印象和药方学习。作为实施例二,在实施例一的基础上,参见图3,所述药剂配方数据库包含药剂配方及其组成和功效;步骤S20包括:步骤201,扫描所述第一事务集,以所述第一事务集中所包含的全部特征项生成第一频繁项集,按照所述特征项在所述药剂配方中出现的频次为支持度,降序排列所述第一频繁项集,以生成项头表;例如,第一频繁项集包含的全部特征均为功效,通过提取配方应用数据表中各功效的数量,并按照降序排列,如果功效30002在所有的配方数据中出现了10000次,那么它的支持度计为10000,以此类推,按照现有的药剂配方能获得目前使用各功效的频次排列表。项头表中的TID表示功效的ID号,支持度为代表各功效的使用频次。步骤202,按照重新排列的顺序把每个所述事务的每个频繁项插入以null为根的FP-tree中;如果插入时频繁项节点已经存在了,则把该频繁项节点支持度加1;如果插入时频繁项节点不存在,则创建支持度为1的节点,并把该节点链接到所述项头表中。利用上述算法规则建立功效之间的节点链即FP-tree,这个节点链表示了所有功效(包含药剂配方中衍生的功效以及药物基本属性中描述的功效)之间的关联关系,参照图2。作为实施例三,参见图4,步骤S40包括:步骤401,以所述数据集中所包含的全部特征项生成第二频繁项集,通过FP-growth算法获得同一频繁项在所述FP-tree数据结构中的所有节点的祖先路径的集合,取并集得到支持度大于阈值的所有模式;循环获得所述数据集中每一频繁项支持度大于阈值的所有模式;形成所述数据集中条件模式基;下面以图2表示的数据结构为数据集,举两个例子说明FP-growth的执行过程。I5的条件模式基是(I2I1:1),(I2I1I3:1),I5构造得到的条件FP-tree如下。然后递归调用FP-growth,模式后缀为I5。这个条件FP-tree是单路径的,在FP_growth中直接列举{I2:2,I1:2,I3:1}的所有组合,之后和模式后缀I5取并集得到支持度>2的所有模式:{I2I5:2,I1I5:2,I2I1I5:2}。参见图5。I5的情况是比较简单的,因为I5对应的条件FP-tree是单路径的,我们再来看一下稍微复杂一点的情况I3。I3的条件模式基是(I2I1:2),(I2:2),(I1:2),生成的条件FP-tree如图6,然后递归调用FP-growth,模式前缀为I3。I3的条件FP-树仍然是一个多路径树,首先把模式后缀I3和条件FP-树中的项头表中的每一项取并集,得到一组模式{I2I3:4,I1I3:4},但是这一组模式不是后缀为I3的所有模式。还需要递归调用FP-growth,模式后缀为{I1,I3},{I1,I3}的条件模式基为{I2:2},其生成的条件FP-树如图6所示。这是一个单路径的条件FP-树,在FP_growth中把I2和模式后缀{I1,I3}取并得到模式{I1I2I3:2}。理论上还应该计算一下模式后缀为{I2,I3}的模式集,但是{I2,I3}的条件模式基为空,递归调用结束。最终模式后缀I3的支持度>2的所有模式为:{I2I3:4,I1I3:4,I1I2I3:2}。I1的条件模式基是(I2:2),在FP-growth递归调用的第一层,模式前后a=NULL,就得到I1的条件模式基。步骤402,将所述条件模式基按照FP-tree的数据结构形成节点链。将条件模式基按照FP-Tree的构造原则形成的新的FP-Tree,参照图5~图7中节点链结构示意图。作为实施例四,参照图8,所述步骤S40之后还包括:步骤S40A,根据所述FP-tree子数据结构获得每个所述频繁项的频繁模式,所述频繁模式包含所有与所述频繁项具有关联的特征项及其与所述频繁项关联的支持度。继续以上述图2表示的数据集为例,根据FP-growth算法,最终得到的支持度>2频繁模式如下:由上述频繁模式可以看出,数据集中各功效之间的关联关系;重复上述步骤,能够获得每一个数据集中各功效之间的关联关系,为下一步获得具体的置信度奠定基础。优选地,作为实施例五,参见图9,所述步骤S50包括:步骤S501,遍历各所述FP-tree子数据结构,若两个不同所述FP-tree子数据结构的子项头表中存在相同的特征项,则在该两个不同所述FP-tree子数据结构的子项头表之间建立索引指向;步骤S502,重复步骤S501;直到遍历完成所有所述FP-tree子数据结构。采用FP-增长算法挖掘症状与辨证、症状与药物、辨证与药物、药物与药物之间的关联关系,包括单维关联和两维关联关系的挖掘。使用的方法是将两维的信息合并成一维,并当成一个事务数据库来处理。在本方剂分析系统中,主要挖掘功效与功效、功效与归经之间的关联关系,前者属于单维关联挖掘,后者属于两维关联挖掘。在运用FP-增长算法对单维关联规则进行挖掘后,结果中是所有满足最小支持度阈值的频繁项集,功效-功效关联为挖掘功效之间的对应关系,所有只要对频繁2项集进行置信度预算处理。功效-归经关联为挖掘功效与归经的对应关系,所有也只要对频繁2项集进行处理,但此时的2项集必须是功效与归经两维信息的组合。运用关联规则算法求得的功效-功效关联结果如表3.1和功效-归经关联结果如3.2所示。表3.1功效-功效双向关联结果示例:(min_sup=2,min_conf=0.4)功效1功效2置信度(1=>2)置信度(2=>1)解毒消热0.630.62消肿利水0.400.83通淋利尿0.820.81通便滑肠0.500.41养阴生津0.500.41平肝定惊0.420.42敛疮生肌0.730.62解郁疏肝0.440.80渗湿退黄0.430.67平肝潜阳0.430.67固精缩尿0.430.86开窍醒神0.561.00敛肺涩肠0.800.44固表收汗0.750.50发散同鼻1.000.75表3.2功效-归经关联结果示例:(min_sup=2,min_conf=0.8)采用上述方案,用户在输入药物名称时,本方案能够对已有配方数据进行挖掘,获得上述功效关联结果或功效与归经的关联结果,下药方时自动精准地进行有效药方配对,减少用户对药方数据库查询检索时间,并有辅助学习功能,对常用的药方及对应症状进行归纳分析,加深医务人员在药方检索时的印象和药方学习。本发明还提供一种基于FP增长算法模型的中药配方数据挖掘系统,参照图10,在一实施例中,该系统包括:预处理模块10,用于对中药原始数据进行预处理,所述中药原始数据中包含单味药数据库和药剂配方数据库;所述单位药数据库形成以单味药为事务、以所述单味药的一个功效或归经为特征项的第一事务集;数据预处理是数据挖掘过程中的一个重要步骤,包括数据清洗、数据集成、数据转换和数据消减。其目的是提高数据挖掘对象的质量,并最终达到提高数据挖掘所获模式知识质量的目的。原始数据中包含单味药数据库和药剂配方数据库,单味药数据库中包含若干味药材,以及对应于每味药材的若干功效和归经;药剂配方数据库中包含若干药剂配方,以及对应于每个药剂配方中的药剂组成、药剂含量及药剂功效、归经;首先录入中药原始数据并进行预处理,提取质量高的数据作为采样样本,并对上述药材、功效、归经分别进行标号,以便后续的计算和处理。FP-tree模块20,用于以所述第一事务集所包含的全部特征项为频繁项构建FP-tree数据结构;把单味药数据库看成一个事务集,每味药材为一条事务,每味药材对应的功效和/或归经为事务的特征(如果挖掘功效-功效之间的关联规则,需要利用表1.2功效-功效关联输入项集,如果挖掘功效-归经之间的关联规则,需要利用表1.3功效-归经关联输入项集),构建FP-tree数据结构;该数据结构中以所有药材的功效和/或归经为频繁项,根据药材出现在配方中的频率对频繁项进行降序排列,构件项头表;由FP-tree算法生成节点链。FP-Tree算法的基本数据结构,包含一个一棵FP树和一个项头表,每个项通过一个结点链指向它在树中出现的位置。基本结构如下所示。需要注意的是项头表需要按照支持度递减排序,在FP-Tree中高支持度的节点只能是低支持度节点的祖先节点。参见图2。数据划分模块30,用于把所述第一事务集中每个事务所对应的特征项按照所述FP-tree数据结构中频繁项的顺序重新排列,生成第二事务集;所述第二事务集包括多个数据集;每个所述数据集以其包含的所述特征项为事务,每条所述事务包括所述数据集中排列在所述事务所对应的特征项之前的特征项;将单味药材库即上述事务集(表1.2功效-功效关联输入项集或表1.3功效-归经关联输入项集)进行划分,可分为若干数据集,每个数据集包含一味药材,及该味药材具备的功效和/或归经;按照这个排列顺序对数据集中的功效进行重新排列,数据集中以每个特征项为事务,每条事务包括排列在该事务对应的特征项之前的特征项;例如,进行功效关系规则挖掘,即每味中药的数据形成一个数据集,这个数据集中,构成的功效作为事务,其他排列在作为事务的功效的之前的功效作为该事务的特征项,参见图2,加入图2为其中一味中药的FP-Tree数据结构,那么它包含四条事务(I5、I4、I3、I1),功效I5的特征项为:I4、I3、I1、I2;功效I4的特征项为:I3、I1、I2;功效I3的特征项为:I1、I2;功效I1的特征项为:I2。FP-tree子模块40,用于对每个所述数据集运行FP-growth算法,以生成与所述多个数据集一一对应的FP-tree子数据结构;这里相当于获得条件模式基,包含FP-Tree中与后缀模式一起出现的前缀路径的集合。也就是同一个频繁项在PF树中的所有节点的祖先路径的集合。比如I3在图2中的FP-Tree中一共出现了3次,其祖先路径分别是{I2,I1:2(频度为2)},{I2:2}和{I1:2}。这3个祖先路径的集合就是频繁项I3的条件模式基。具体计算过程如下:调用FP-growth(Tree,null)开始进行挖掘。伪代码如下:FP-growth函数的输入:tree是指原始的FPTree或者是某个模式的条件FPTree,a是指模式的后缀(在第一次调用时a=NULL,在之后的递归调用中a是模式后缀)FP-growth函数的输出:在递归调用过程中输出所有的模式及其支持度(比如{I1,I2,I3}的支持度为2)。每一次调用FP_growth输出结果的模式中一定包含FP_growth函数输入的模式后缀。模拟一下FP-growth的执行过程。1、在FP-growth递归调用的第一层,模式前后a=NULL,得到的其实就是频繁1项集。2、对每一个频繁1项集,进行递归调用FP-growth()获得多元频繁项集。将条件模式基按照FP-Tree的构造原则形成I3的FP-Tree。参照图3,可以看出,表现的是与I3有关联的功效,及其关联支持度。挖掘模块50,用于基于不同所述FP-tree子数据结构中特征项之间的对应关系,挖掘不同功效之间的关联规则和/或挖掘功效与归经之间的关联规则。基于前面步骤S10~S40,能够获得所有功效之间的关联关系,以及功效与归经之间的关联关系,遍历各FP-tree子数据结构,即可获得不同功效之间的关联规则和/或挖掘功效与归经之间的关联规则。本发明的方案,从医案的处方出发,结合症状、辨证等信息,对处方进行基本方剂库中的基本方剂匹配,对未匹配到的药物再进行药物配伍、对症用药等药物应用模式的匹配,对仍未匹配到的药物,根据药物属性表查出每味药物的功效。统计医案处方中所有药物的归经,根据功效与归经的关联关系筛选出与归经关联度大的单味药的功效,获得处方的功效集合。对汇总后的功效集合根据功效之间的相似关系进行功效规约,从而归纳出处方的功效。优选地,作为另一实施例,参见图11,所述FP-tree模块20包括:项头表模块201,用于扫描所述第一事务集,以所述第一事务集中所包含的全部特征项生成第一频繁项集,按照所述特征项在所述药剂配方中出现的频次为支持度,降序排列所述第一频繁项集,以生成项头表;例如,第一频繁项集包含的全部特征均为功效,通过提取配方应用数据表中各功效的数量,并按照降序排列,如果功效30002在所有的配方数据中出现了10000次,那么它的支持度计为10000,以此类推,按照现有的药剂配方能获得目前使用各功效的频次排列表。项头表中的TID表示功效的ID号,支持度为代表各功效的使用频次。排序模块202,用于按照重新排列的顺序把每个所述事务的每个频繁项插入以null为根的FP-tree中;如果插入时频繁项节点已经存在了,则把该频繁项节点支持度加1;如果插入时频繁项节点不存在,则创建支持度为1的节点,并把该节点链接到所述项头表中。利用上述算法规则建立功效之间的节点链即FP-tree,这个节点链表示了所有功效(包含药剂配方中衍生的功效以及药物基本属性中描述的功效)之间的关联关系,参照图2。优选地,参见图11,所述FP-tree子模块40包括:路径模块401,用于以所述数据集中所包含的全部特征项生成第二频繁项集,通过FP-growth算法获得同一频繁项在所述FP-tree数据结构中的所有节点的祖先路径的集合,取并集得到支持度大于阈值的所有模式;循环获得所述数据集中每一频繁项支持度大于阈值的所有模式;形成所述数据集中条件模式基;节点链模块402,用于将所述条件模式基按照FP-tree的数据结构形成节点链。下面以图2表示的数据结构为数据集,举两个例子说明FP-growth的执行过程。I5的条件模式基是(I2I1:1),(I2I1I3:1),I5构造得到的条件FP-tree如下。然后递归调用FP-growth,模式后缀为I5。这个条件FP-tree是单路径的,在FP_growth中直接列举{I2:2,I1:2,I3:1}的所有组合,之后和模式后缀I5取并集得到支持度>2的所有模式:{I2I5:2,I1I5:2,I2I1I5:2}。参见图5。I5的情况是比较简单的,因为I5对应的条件FP-tree是单路径的,我们再来看一下稍微复杂一点的情况I3。I3的条件模式基是(I2I1:2),(I2:2),(I1:2),生成的条件FP-tree如图6所示,然后递归调用FP-growth,模式前缀为I3。I3的条件FP-树仍然是一个多路径树,首先把模式后缀I3和条件FP-树中的项头表中的每一项取并集,得到一组模式{I2I3:4,I1I3:4},但是这一组模式不是后缀为I3的所有模式。还需要递归调用FP-growth,模式后缀为{I1,I3},{I1,I3}的条件模式基为{I2:2},其生成的条件FP-树如图6所示。这是一个单路径的条件FP-树,在FP_growth中把I2和模式后缀{I1,I3}取并得到模式{I1I2I3:2}。理论上还应该计算一下模式后缀为{I2,I3}的模式集,但是{I2,I3}的条件模式基为空,递归调用结束。最终模式后缀I3的支持度>2的所有模式为:{I2I3:4,I1I3:4,I1I2I3:2}。I1的条件模式基是(I2:2),在FP-growth递归调用的第一层,模式前后a=NULL,就得到。优选地,作为实施例四,参见图11,所述系统还包括:频繁式模块40A,用于根据所述FP-tree子数据结构获得每个所述频繁项的频繁模式,所述频繁模式包含所有与所述频繁项具有关联的特征项及其与所述频繁项关联的支持度。继续以上述图2表示的数据集为例,根据FP-growth算法,最终得到的支持度>2频繁模式如下:由上述频繁模式可以看出,数据集中各功效之间的关联关系;重复上述步骤,能够获得每一个数据集中各功效之间的关联关系,为下一步获得具体的置信度奠定基础。优选地,参见图11,所述挖掘模块50包括:索引模块501,用于遍历各所述FP-tree子数据结构,若两个不同所述FP-tree子数据结构的子项头表中存在相同的特征项,则在该两个不同所述FP-tree子数据结构的子项头表之间建立索引指向;循环模块502,重复上述过程直到遍历完成所有所述FP-tree子数据结构。采用FP-增长算法挖掘症状与辨证、症状与药物、辨证与药物、药物与药物之间的关联关系,包括单维关联和两维关联关系的挖掘。使用的方法是将两维的信息合并成一维,并当成一个事务数据库来处理。在本方剂分析系统中,主要挖掘功效与功效、功效与归经之间的关联关系,前者属于单维关联挖掘,后者属于两维关联挖掘。在运用FP-增长算法对单维关联规则进行挖掘后,结果中是所有满足最小支持度阈值的频繁项集,功效-功效关联为挖掘功效之间的对应关系,所有只要对频繁2项集进行置信度预算处理。功效-归经关联为挖掘功效与归经的对应关系,所有也只要对频繁2项集进行处理,但此时的2项集必须是功效与归经两维信息的组合。运用关联规则算法求得的功效-功效关联结果如表3.1和功效-归经关联结果如3.2所示。表3.1功效-功效双向关联结果示例:(min_sup=2,min_conf=0.4)功效1功效2置信度(1=>2)置信度(2=>1)解毒消热0.630.62消肿利水0.400.83通淋利尿0.820.81通便滑肠0.500.41养阴生津0.500.41平肝定惊0.420.42敛疮生肌0.730.62解郁疏肝0.440.80渗湿退黄0.430.67平肝潜阳0.430.67固精缩尿0.430.86开窍醒神0.561.00敛肺涩肠0.800.44固表收汗0.750.50发散同鼻1.000.75表3.2功效-归经关联结果示例:(min_sup=2,min_conf=0.8)通过双向关联规则算法获得的功效-功效关联对,以及获得的功效-归经的关联对,在本系统中进行方剂分析并通过规律的总结给配方分析和输入自动关联提供技术基础,也是系统对中药配方进行数据挖掘的应用。采用上述方案,用户在输入药物名称时,本方案能够对已有配方数据进行挖掘,获得上述功效关联结果或功效与归经的关联结果,下药方时自动精准地进行有效药方配对,减少用户对药方数据库查询检索时间,并有辅助学习功能,对常用的药方及对应症状进行归纳分析,加深医务人员在药方检索时的印象和药方学习。以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的
技术领域:
,均同理包括在本发明的专利保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1