一种地面气温数据质量控制方法与流程
本发明涉及地面观测站采集数据的质量控制领域,特别是针对温度数据的质量控制方法。
背景技术:
中国自1951年以来就有近1800个气象站,气象数据的积累丰富,然而这些气象数据中可能存在一些观测、录入和传输等错误,这些错误降低了气象站观测数据的质量,对气象的研究产生了阻力,因此对气象数据的质量控制成为了气象数据应用中不可或缺的环节。
地面气象站观测数据质量控制一般分为两类,一类是单站质量控制方法,主要包括极值检查、气候极值检查、内部一致性检查、时间一致性检查;另一类是多站联网质量控制方法,目前国内外已经提出了很多质量控制的方法,例如数值预报模式插值方法、反距离加权发和空间回归检测方法等等。
技术实现要素:
本发明的目的在于克服以上技术不足之处,针对多站质量控制的不足提出一种基地面气温数据质量控制方法,解决了目前多站联网质量控制方法不稳定、准确度不高的问题,具体由以下的方案实现:
所述地面气象观测站观测的气温数据质量控制方法,包括以下步骤:
步骤1.采集采样时间T内的目标地面气象观测站温度数据X0(t),t=1,2,3,…,T,其中t为采样时间;
步骤2.采集采样时间T内的邻近地面气象观测站温度数据Xi(t),i=1,2,3,…,n,其中n为邻近站的个数;
步骤3.对采集到的数据进行基本质量控制,得到新的数据集x0(t)和xi(t),将样本按时间序列以9:1的比例分为训练集和测试集;
步骤4.使用随机森林方法对训练集数据进行建模,利用Bagging方法进行采样,样本数足够大时约有37%的数据没有抽取到,称为袋外数据(OOB),利用袋外误差(OOB error)测试模型的泛化能力,假设袋外数据总数为a,用这a个数据作为输入,带入分类器得到分类结果,与正确的分类情况进行比较统计错误数据大小为b,则袋外误差为OOBerror=b/a,随机对袋外数据所有样本特征加入噪声干扰,在此计算袋外误差得OOBerror2,则某特征m1的重要性为n为树个数,利用遗传算法寻找重 要性较高的特征,即邻近站点,选择重要性较高的站点建立随机森林质量控制模型;
步骤5.将测试集中的邻近站点数据作为样本集,利用步骤6建立的随机森林模型进行回归预测,得到目标站的预测值;
步骤6.将预测值与实际观测值进行比较,通过均方根误差和平均绝对误差 评价模型,其中yobs为目标站实际观测值,yest是模型预测值。
其中,步骤3中所述基本质量控制方法包括格式检查、极值检查、气候极值检查、内部一致性检查、时间一致性检查、空间一致性检查。
其中,步骤4中的遗传算法寻优过程为pc=f(xi)/∑f(xi),其中pc是某台站被选择的概率,xi为第i个台站,f(xi)为第i个台站的适应度函数值,即变量重要性值,∑f(xi)为所有台站适应度函数值之和。
其中,步骤8中所述检错方法公式为:|yobs-yest|≤f·δ,f是质量控制参数设置为3,δ是目标站观测值与预测值之间的标准误差,如果满足公式的条件,就判断该数值正确,如果不满足公式的条件,则将该数据记为存疑数据,通过这样的方法来实现对数据的质量控制。
有益效果
本发明的一种地面气温数据质量控制方法,通过周围邻近站点的气温观测数据,利用优化后的随机森林方法构建基于邻近站点气温观测数据的气温数据质量控制模型,提出了一种新的多站联网质量控制方法,模型搭建速度快,泛化能力强,能够有效的提高地面观测数据的准确性。
附图说明
图1是本发明方法的流程图。
图2是本发明方法2005年重要性与台站排序图。
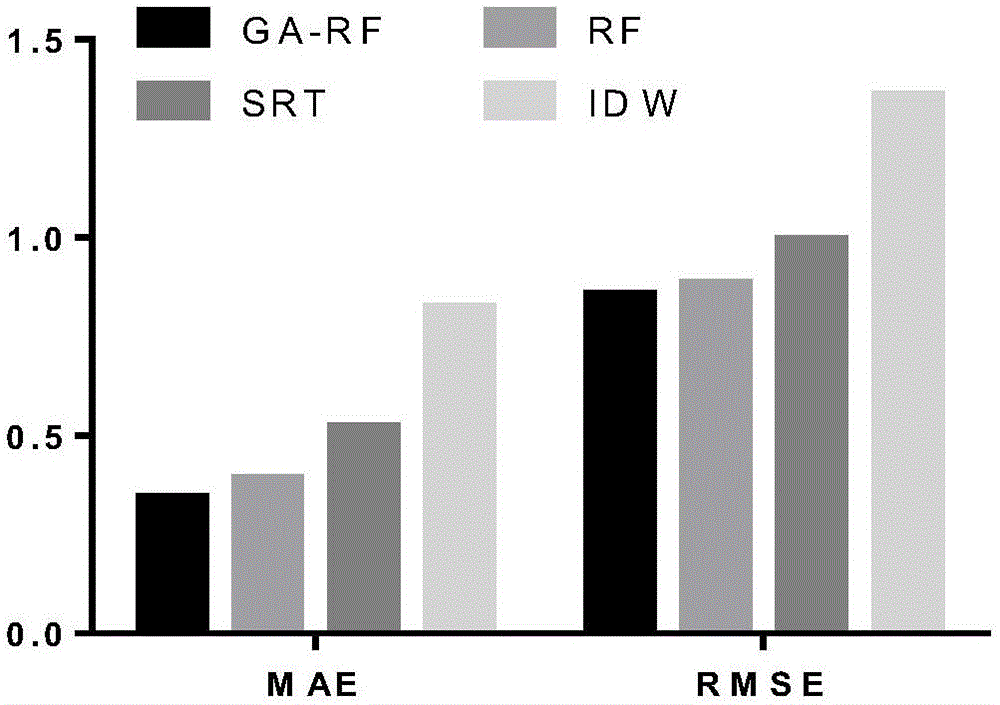
图3是本发明方法与反距离加权和空间回归检验方法的MAE、RMSE效果对比图。
图4是本发明方法与反距离加权和空间回归检验方法月02:00时均温实际观测值与预测值对比图。
具体实施方式
下面结合附图就实施例对本发明进行进一步说明。
本实施例的地面气温数据质量控制方法,如图1所示将福建站及周围的71个站点2005年到2014年逐日02:00时气温数据进行实施例分析,进一步说明本发明:
步骤1.采集采样时间T内的目标地面气象观测站温度数据X0(t),t=1,2,3,…,T,其中t为采样时间,本实施例中T=3654为样本数;
步骤2.采集采样时间T内的71个邻近地面气象观测站温度数据Xi(t),i=1,2,3,…,n,其中n为邻近站的个数,在本实施例中n=71;
步骤3.对采集到的数据X0(t)和Xi(t)进行基本质量控制,得到新的数据集x0(t)和xi(t),取样本中1-3289行的数据作为训练集,3290-3654行的数据作为测试集;
步骤4.使用随机森林方法对训练集数据进行建模,利用Bagging方法进行采样,样本数足够大时约有37%的数据没有抽取到,称为袋外数据(OOB),利用袋外误差(OOB error)测试模型的泛化能力,假设袋外数据总数为a,用这a个数据作为输入,带入分类器得到分类结果,与正确的分类情况进行比较统计错误数据大小为b,则袋外误差为OOBerror=b/a,随机对袋外数据所有样本特征加入噪声干扰,在此计算袋外误差得OOBerror2,则某特征m1的重要性为n为树个数,本实施例中为500,利用遗传算法寻找重要性较高的特征,即邻近站点,选择重要性较高的站点建立随机森林质量控制模型,将2005-2013年每年数据进行建模得到密云站邻近站点每年重要性数据,综合比较每年数据得出结果,图2为2005年台站重要性情况,一共运行了9年重要性数据进行GA优化,本实施例中选取重要性前20的站点进行随机森林质量控制模型建模;
步骤5.将测试集中的邻近站点数据作为样本集,利用步骤6建立的随机森林模型进行回归预测,得到目标站的预测值;
步骤6.将预测值与实际观测值进行比较,通过均方根误差(RMSE)和平均绝对误差(MAE)比较随机森林质量控制效果,在实施例中MAE为0.341,RMSE为0.882。
为了分析本方法的优点,将同样的数据应用与反距离加权方法和空间回归检验方法中,并进行对比,如表1所示,本方法得到的平均绝对误差(MAE)和均方根误差(RMSE)明显要优于另外两种方法。
表1本发明方法综合9年台站重要性数据GA后得到的前20个重要性较高的台站
本实施例通过周围邻近站点气温观测数据,利用优化后的随机森林方法构建基于邻近站点气温观测数据的气温数据质量控制模型,提出了一种新的多站联网质量控制方法,模型搭建速度快,泛化能力强,能够有效的提高地面观测数据的准确性,选择重要性较高的20个站点也减少了以后进行气象数据质量控制的时间。通过图3与图4的对比分析验证本发明方法质量控制效果明显。
- 还没有人留言评论。精彩留言会获得点赞!