一种基于Redis内存数据库的复杂规则匹配方法与流程
本发明涉及一种互联网数据审计方法,尤其是一种针对实时数据流的、基于Redis内存数据库且支持复杂逻辑与、或、非的规则匹配方法。
背景技术:
随着互联网技术的发展,网络数据审计显得的尤为重要了,国家需要对互联网数据进行审计,查找数据中的特殊或者特定行为,并针对进行相应的业务处理。
传统的规则匹配大致为:
采用AB内存队列的方式存储规则,在实时数据中进行规则匹配。此种方式能满足时效性的要求,但是当面对种类繁多、逻辑运算复杂、类型多变且大规模的业务规则时,开发人员很难对此作出及时响应,业务人员也无法单独进行业务布署。
综上所述,互联网数据审计实时规则匹配系统需要:
1)实时性:面向实时数据流;规则实时生效;
2)可扩展:能够由业务人员单独进行规则的编写管理;
3)可定制:可支持多个业务系统;
4)可靠性:大规模的数据和大规模的规则就决定了系统必须要有足够的稳定性和健壮性。
本发明基于Redis内存数据库进行处理,所述Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的API。
技术实现要素:
本发明的目的就在于提供一种满足上述实时互联网数据审计系统要求的设计,保证数据的实时性,保证规则可扩展、可定制、并且能够实时更新,保证系统的稳定健壮。其技术方案如下所述:
一种基于Redis内存数据库的复杂规则匹配方法,包括规则解析系统、Redis内存数据库、规则匹配系统,包括下列步骤:
1)业务中心根据用户相关具体业务生成业务规则,并将业务规则下发给规则中心;
2)所述规则中心将业务中心下发的业务规则下发到规则解析系统,并同时将业务规则存储到规则数据库中;
3)所述规则解析系统接收到规则中心下发的业务规则,对业务规则进行解析,形成结构化规则,并将对应的信息分别存储到Redis内存数据库主库的规则信息实例、索引实例、规则ID映射实例中;
4)通过Redis内存数据库的主从模式,将主库更新信息同步到所有规则匹配系统中;
5)规则匹配系统集群对互联网审计数据进行规则匹配,并根据匹配的规则进行相对应操作,同时输出对应的业务数据。
进一步的,步骤3)中,所述规则解析系统解析规则用可扩展xml语言描述,所述规则的内容包括规则类型,规则系统,规则ID,规则逻辑,规则过滤条件,规则动作,所述解析方法包括新增规则、修改规则和删除规则,所述新增规则是直接对规则解析,将解析后的规则关联信息分别插入到Redis内存数据库主库的规则信息实例、索引实例、规则ID映射实例中;所述修改规则是根据解析获取的规则ID,在规则信息实例、索引实例、规则ID映射实例中查找对应的信息进行删除,再将解析后的规则关联信息分别插入到Redis内存数据库主库的规则信息实例、索引实例、规则ID映射实 例中;所述删除规则是根据解析获取的规则ID,在规则信息实例、索引实例、规则ID映射实例中查找对应的信息进行删除。
进一步的,所述Redis内存数据库包括规则信息实例、索引实例、规则ID映射实例,步骤4)中,所述Redis内存数据库主库接收到规则解析系统解析后的结构化规则,将规则信息分别存入Redis内存数据库主库的规则信息实例、索引实例、规则ID映射实例中;通过Redis的主从模式,自动将信息实例、索引实例、规则ID映射实例变化数据同步到规则匹配系统集群中所有Redis从库中。
进一步的,所述规则信息实例是以规则编号为表名,规则信息成员变量为索引,规则信息成员变量值为内容;所述索引实例是以简单合取式中的单个条件为表名,以简单合取式编号为表中的内容;所述规则ID映射实例是以拆分出的简单合取式和需要命中次数的组合为表名,规则编码为表中内容。
进一步的,步骤5)中的规则匹配的方法步骤如下所述:
(1)所述规则匹配系统提取数据流中需要进行匹配的字段拼接成表名到索引实例中查询,取得对应的简单合取式编号,归并简单合取式编号并记录命中次数;
(2)拼接简单合取式编号和需要命中次数查询规则编号映射实例,得到规则编号;
(3)使用以规则编号表名到规则信息实例中,取得对应的规则信息;
(4)从规则信息成员中取得规则过滤条件,对数据命中的规则进行过滤,过滤后的规则即为数据命中的最终规则;
(5)从规则信息成员中取出规则动作,对数据进行相应的操作;
(6)通过业务系统编号输出到对应的业务系统;
(7)业务系统根据规则匹配系统输出过来的数据进行实时告警业务操作。
其中,所述Redis内存数据库设置为主从模式,主库负责读写操作,从 库只负责读操作;所述主库部署在规则解析系统的服务器上,从库部署到规则匹配系统的服务器上,以此保证除了Redis内存数据库的主从同步外,单个节点的Redis内存库操作都为本机操作,降低Redis内存数据库操作的网络延时。
并且,在规则内容中,所述规则类型是定义规则执行动作,包括规则增加、删除、更新操作;所述业务系统编号是为了标明下发规则的业务系统,本系统支持多个业务系统同时进行规则匹配;所述规则编号是规则唯一标识;所述规则逻辑是业务要处理的逻辑规则表达式,支持由与、或、括号组成的复杂逻辑表达式;所述协议类型编号是规则命中数据的协议过滤条件;所述规则动作是描述规则命中数据所要执行的操作。
进一步的,步骤3)中,所述规则解析系统收到业务中心下发的业务规则后,对业务规则进行解析,将业务规则拆成析取范式的形式,并给析取范式中拆分出来的每一个简单合取式一个新的编号,同时记录每个简单合取式的条件个数。
本发明能够做到1)实时性:面向实时数据流,规则实时生效;2)可扩展:能够由业务人员单独进行规则的编写管理;3)可定制:可支持多个业务系统;4)可靠性。能够满足需求。
附图说明
图1是所述规则信息实例的示意图;
图2是所述索引实例的示意图;
图3是所述规则ID映射实例的示意图;
图4是所述Redis内存数据库模式的示意图;
图5是所述规则匹配系统设计的示意图;
图6是本发明的系统总体结构流程示意图;
图7是所述规则解析的流程示意图;
图8是所述Redis内存数据库的工作示意图;
图9是所述规则匹配的流程图。
具体实施方式
本发明中主要包含规则解析系统、Redis内存数据库、规则匹配系统。
所述规则解析系统:对规则中心下发的规则xml文件进行解析;
Redis内存数据库:存储规则解析系统解析每一个条规则的对应关联关系信息;
规则匹配系统:实时数据流中的数据与规则进行匹配
其中,规则用可扩展xml语言描述,内容由规则类型,规则系统,规则ID,规则逻辑,规则过滤条件,规则动作等部分组成:
1)规则类型(rule_type):定义规则执行动作,包括规则增加、删除、更新操作;
2)业务系统编号(rule_systemid):主要为了标明下发规则的业务系统,本系统支持多个业务系统同时进行规则匹配;
3)规则编号(ruleid):规则唯一标识;
4)规则逻辑(rule):业务要处理的逻辑规则表达式,支持由与、或、括号组成的复杂逻辑表达式;
5)协议类型编号(protocol_id):规则命中数据的协议过滤条件;
6)规则动作(rule_action):描述规则命中数据所要执行的操作。
7)规则解析系统收到业务系统下发的规则后,对规则进行解析。将规则拆成析取范式的形式,并给析取范式中拆分出来的每一个简单合取式(subrule)一个新的编号(subrule_id),同时记录每个简单合取式的条件个数(hitnum)。
例如:
业务系统100,需要在10.11.12.13的IP上,搜索账号为“example@163.com”,或者手机号码为“18012345678”的即时通信协议,然后单独入库告警。形成的规则结构应为:
rule_type:add
rule_systemid:100
ruleid:10000123(此id由业务系统生成的规则ID,并保证唯一性)
rule:(IP=10.11.12.13)&((username=aa@163.com)|(mobile=18012345678))
protocol_id:协议类型=即时通信
rule_action:告警标识=true
析取范式形式:
(IP=10.11.12.13)&((username=aa@163.com)|(mobile=18012345678))
subrule:
subruleA:(IP=10.11.12.13)&(username=aa@163.com)
subrule_idA:11
hitnumA:2
subruleB:(IP=10.11.12.13)&(mobile=18012345678)
subrule_idB:12
hitnumB:2
简单合取式(sub_subrule):
sub_subrule1:(IP=10.11.12.13)
sub_subrule2:(username=aa@163.com)
sub_subrule3:(mobile=18012345678)
Redis内存数据库实例设计如下所述:
本设计的Redis单节点内存数据库包括规则信息实例、索引实例、规则ID映射实例。
规则信息实例如图1所示:
以规则编号(ruleid)为表名,规则信息(ruleinfo)成员变量为key,规则信息(ruleinfo)成员变量值为内容。
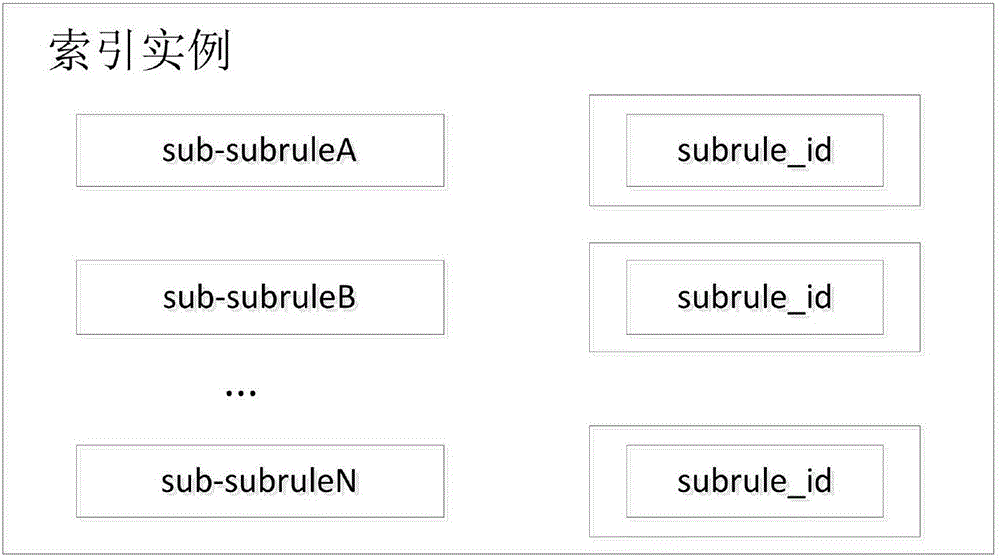
索引实例如图2所示:
以简单合取式(sub-subrule)中的单个条件为表名,以简单合取式编号(subrule_id)为表中的内容。
规则ID映射实例如图3所示:
以拆分出的简单合取式(sub-subrule)和需要命中次数(hitnum)的组合为表名,规则编码(ruleid)为表中内容。
Redis内存数据库模式设计是采用Redis的主从模式,如图4所示,主库负责读写操作,从库只负责读操作。Redis的主从模块能够保证主库的更新能够快速准确的同步到从库上,并且它的增量更新机制也保证了网络资源的不拥堵。
主库部署在规则解析系统的服务器上,从库部署到规则匹配系统的服务器上,以此保证除了Redis内存库的主从同步外,单个节点的Redis内存库操作(主库的更新操作,从库的查询操作)都为本机操作,大大降低Redis库操作的网络延时。
规则匹配系统设计如图5所示:
规则匹配系统接入互联网审计数据,经过解析还原、格转、标准化等处理后形成的结构化数据流。
规则匹配系统提取数据流中需要进行匹配的字段拼接成表名到索引实例中查询,取得对应的简单合取式编号(subrule_id),归并简单合取式编号(subrule_id)并记录命中次数。
拼接简单合取式编号(subrule_id)和需要命中次数(hitnum)查询规则编号映射实例,得到规则编号(ruleid)。
使用以规则编号(ruleid)表名到规则信息实例中,取得对应的规则信息(ruleinfo)。
从规则信息(ruleinfo)成员中取得规则过滤条件,对数据命中的规则进行过滤,过滤后的规则即为数据命中的最终规则。
从规则信息(ruleinfo)成员中取出规则动作,对数据进行相应的操作。
通过业务系统编号(rule_systemid)输出到对应的业务系统。
业务系统根据规则匹配系统输出过来的数据进行实时告警等其他业务操作。
本发明的流程如图6所示:
1)由业务中心,根据用户相关具体业务,生成规则,并下发给规则中心;
2)规则中心,将业务中心下发的业务规则,下发到规则解析系统,并同时将业务规则存储到规则数据库中;
3)规则解析系统接收到规则中的下发的规则,对规则进行解析,形成结构化规则,并将对应的信息分别存储到Redis主库的规则信息实例、索引实例、规则ID映射实例中;
4)通过Redis内存数据库的主从模式,将主库更新信息同步到所有规则匹配系统中;
5)规则匹配系统集群,对互联网审计数据进行规则匹配,并根据匹配的规则进行相对应操作,同时输出对应的业务数据。
其中,规则解析如图7所示:
1)新增规则(add):
直接对规则解析,将解析后的规则关联信息分别插入到Redis主库的规则信息实例、索引实例、规则ID映射实例中。
2)修改规则(mod):
根据解析获取的规则ID,在规则信息实例、索引实例、规则ID映射实例中查找对应的信息进行删除;
再将解析后的规则关联信息分别插入到Redis主库的规则信息实例、索 引实例、规则ID映射实例中。
3)删除规则(del):
根据解析获取的规则ID,在规则信息实例、索引实例、规则ID映射实例中查找对应的信息进行删除。
如图8所示,所述Redis内存数据库包括主库和从库:
Redis主库接收到规则解析系统解析后的结构化规则,将规则信息分别存入Redis主库的规则信息实例、索引实例、规则ID映射实例中;
通过Redis的主从模式,自动将信息实例、索引实例、规则ID映射实例变化数据同步到规则匹配系统集群中所有Redis从库中。
规则匹配如图9所示:
1)对结构化字段进行提取,将字段编码和字段内容进行拼接,已拼接后的内容为表名,在索引实例查询,获取subrule_id;
2)归并subrule_id,并记录每一个subrule_id的需要命中次数;
3)以subrule_id#hitnum为表名,在规则ID映射实例中查询,获取ruleid;
4)以ruleid为表名,在规则信息实例中查询,获取ruleinfo信息;
5)根据ruleinfo信息,对数据进行相对应的处理操作。
本发明中,对于相关的涉及参数,描述如下:
本发明能够做到1)实时性:面向实时数据流,规则实时生效;2)可扩展:能够由业务人员单独进行规则的编写管理;3)可定制:可支持多个业务系统;4)可靠性。能够满足需求。
- 还没有人留言评论。精彩留言会获得点赞!