一种基于代价敏感学习的联合知识嵌入方法与流程
本发明属于知识图谱技术领域,特别地涉及一种基于代价敏感学习的同时对知识库、知识图谱中的实体与关系同时嵌入到低维空间的联合知识嵌入方法。
背景技术:
在大数据时代,知识库中的知识表达和推理是十分关键同时又很有挑战性的工作。一般来说,知识库的基本组成是有名称、有确定含义的一元组单位,称为实体;而其语义结构则由实体之间的高阶交互单位来表达,称为关系。作为时下被经常使用的有力工具,知识嵌入在低维空间上建立了统计模型以量化表达和评估这些单位和它们之间的关系。
为了学习有效的嵌入结果,语义相似的单元应该在嵌入空间内彼此接近。未达成这一目的,最重要的参考因素是知识库中的上下文信息,如图1所示。在实体与关系两个层面上,都存在重要的上下文信息:在实体层面,上下文指的是连接实体的各种关联信息,这些信息决定了实体之间的相关结构,对于知识表达而言非常重要;在关系层面,上下文指的是各种关系之间的关联,相对于实体间的上下文而言,这种上下文更高级,主要是对知识推理更有帮助。知识嵌入应当学习一个模型,这个模型需要能同时考虑实体和关系层面的上下文信息,在使用向量表达知识库的同时有这保留知识库中主要的上下文信息的能力。
大部分相关工作主要关注实体层面的嵌入,而关系往往没有被显性地嵌入,导致了关系层面的高阶信息很难被利用到。事实上,关系层面的嵌入同样很重要,因为关系之间蕴含着丰富的语义信息,关系之间的相互关联反映着知识库中的内在拓扑结构。因此,寻找合适的嵌入空间,将知识库中的各种关系嵌入到其中以度量它们之间的结构信息是非常重要和有帮助的,这就是关系嵌入。
一般来说,实体嵌入和关系嵌入是知识嵌入的两个重要组成部分。知识库中的关联事实,也就是各条知识,是同时由实体和关系决定的。只有妥善地同时嵌入实体和关系,才能完整有效地表达知识库里的信息,因为知识库中的实体与关系在语义上也是高度相关的。在嵌入过程中,实体被关系所约束,而关系被实体所支撑。因而,实体嵌入和关系嵌入是相互关联、相互补充的。因此,知识嵌入应该是一个联合优化问题,通过链接实体嵌入和关系预测两个任务提出相应的嵌入模型。
技术实现要素:
为解决上述问题,本发明引入了代价敏感学习框架来进行联合知识嵌入。代价敏感的学习方法是机器学习领域中的一种常用方法,它主要考虑在训练过程中,当不同类型的损失产生导致不同的惩罚力度时如何训模型。在代价敏感学习框架中,各类损失项的权重不是人为确定的,而是在训练过程中通过自适应的方法进行更新,在学习模型的同时学习到合适的损失项权重。代价敏感学习框架可以应用在多种常用的有监督学习方法中,如决策树、boosting、支持向量机等,在特定应用场景下有很好的效果。
为实现本发明的技术目的,本发明采用的技术方案为:
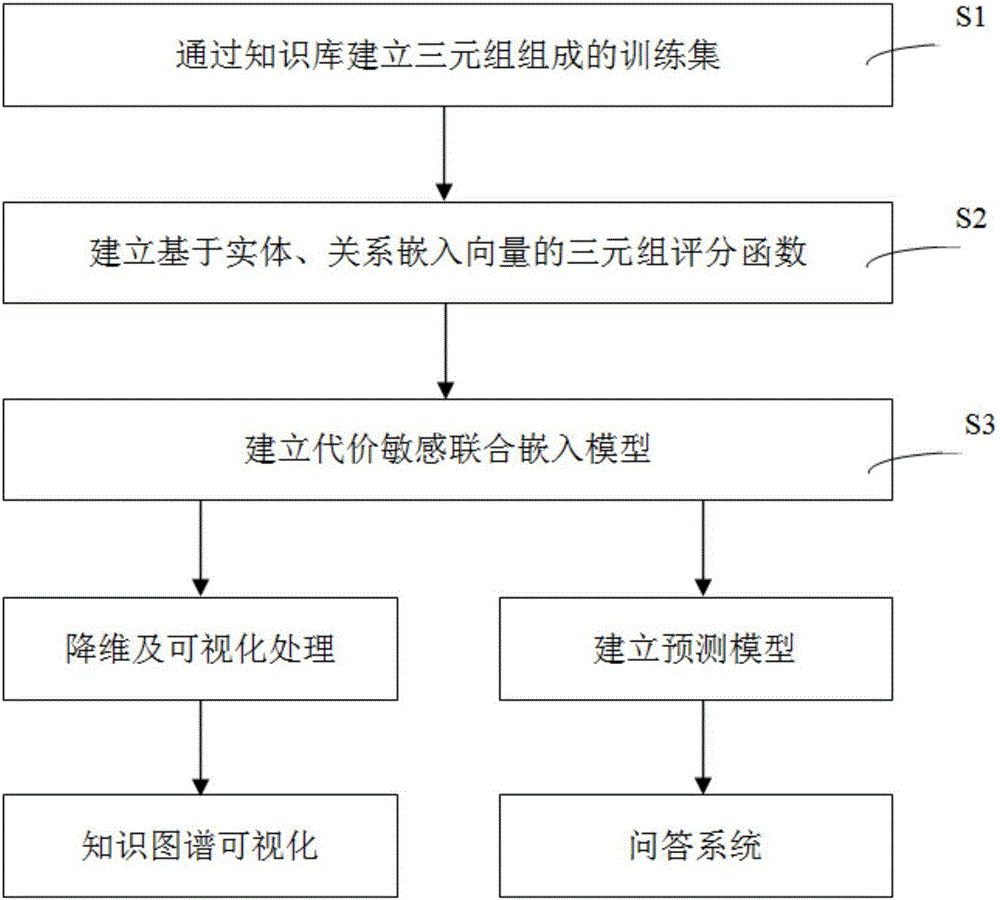
一种基于代价敏感学习的联合知识嵌入方法,包括以下步骤:
S1,通过知识库建立三元组组成的训练集;
S2,建立基于实体、关系嵌入向量的三元组评分函数,在只考虑实体层面上下文关系的条件下,建立基于最大边缘的优化目标;
S3,建立代价敏感联合嵌入模型。
进一步的,步骤S1具体包括:
S11,抽取知识库中所有的实体,建立实体集合E={e1,e2,…,en};
S12,抽取知识库中所有的实体,建立关系集合R={r1,r2,…,rm};
S13,对每一条关联事实,在实体集合E中寻找到关联事实的头实体与尾实体,在关系集合R中寻找到关联事实中的关系,建立三元组(ei1,ri1,ei2);
S14,通过抽取知识库中的所有关联事实,建立训练集
T={(e11,r11,e12),(e21,r21,e22),…,(et1,rt1,et2)}。
进一步的,步骤S2具体包括:
S21,规定实体嵌入空间和关系嵌入空间拥有相同的维度,建立基于实体、关系嵌入向量的三元组评分函数
其中,e1,r,e2分别是e1,r,e2的嵌入向量,diag(r)代表一个对角元素组成的向量恰为r的对角矩阵,公式中所有的向量都是列向量;
S22,建立基于边缘的排序模型,其训练目标为:
其中,C为用于调节关系嵌入向量的正则项权重的超参数,γ为边缘宽度,(e1,r′,e2)是一个不存在于知识库中的三元组;上述目标函数第一项是训练集中正样本与负样本所生成的损失函数,第二项则是关系嵌入向量作为参数在模型中的正则化项。
进一步的,步骤S3具体包括:
S31,建立代价敏感权重矩阵W,所述代价敏感权重矩阵W用于衡量每对关系之间同时出现的可能性,其中,W是一个维度与e和r相同的方阵,W中每一个元素都代表了一种关系出现在已有另一种关系的两个实体之间的合理性;
S32,将代价敏感学习框架应用于公式2中;当计算三元组(e1,r,e2)∈T和所形成的损失时,加入一个权重Wrr′,其中,Wrr′即是代价敏感权重矩阵中代表r和r′关系的元素;此时,训练目标为:
subject to:S(e1,r,e2)-S(e1,r',e2)≥γ-ξtrr',
ξtrr'≥0,Wrr'≥0,∑Wrr'=δ,δ>0
优选的,公式3求解过程中,采用小批量采样的方法对优化过程进行加速。
本发明还提供了上述的基于代价敏感学习的联合知识嵌入方法在知识图谱或知识库的可视化上的应用,包括如下步骤:
步骤1,通过公式1得到所有实体与关系嵌入值,即所有的e和r;
步骤2,分别在实体空间和关系空间内对e和r所表示的点进行t-SNE降维;
步骤3,将步骤2中的降维结果进行归一化,在2维平面上可视化。
本发明还提供了上述的基于代价敏感学习的联合知识嵌入方法在问答系统的构建上的应用,包括如下步骤:
步骤1,通过公式1得到所有实体与关系嵌入值,即所有的e和r;
步骤2,将需要解答的问题转换为已知(e1,r,e2)中的2个,预测第3个元素的形式;
步骤3,对与给定的问题,固定(e1,r,e2)中已知的2个,将知识库中所有可能的元素都当作备选答案,构成一组答案集合;
步骤4,对答案集合中的的所有三元组,通过公式1进行评分,并将得分进行排序.
步骤5,选取排序结果中最靠前的作为结果输出。
进一步的,上述的基于代价敏感学习的联合知识嵌入方法在问答系统的构建上的应用中,
当问题被转化为已知e1,r预测e2的问题时,答案集合为{(e1,r,e*)|e*∈E};
当问题被转化为已知e1,e2预测r的问题,答案集合为{(e1,r*,e2)|r*∈R}。
本发明定义了实体-关系-实体打分函数以评估每条关联事实并在代价敏感学习框架中优化实体嵌入向量和关系嵌入向量。并且,为了更好地利用关系之间的上下文信息,本发明用最大边界方法建立了关系权重相关的评价函数。该函数在反映实体间的拓扑信息的同时,通过代价敏感框架反映了关系间的拓扑信息,从而达到了对实体嵌入向量和关系嵌入向量的联合优化。因而,本发明利用了知识库中各层次的上下文信息,从而可以学习到在语义上更有意义和代表性的嵌入结果。
本发明实施例所提出的联合知识嵌入方法,相比于目前的知识嵌入方法,具有以下有益效果:
1)本发明提出的方法不仅对知识库中的实体进行了嵌入,而且对知识库中的关系也进行了嵌入。该方法将实体与关系嵌入不同的低维空间,使得两种不同的元素分别在对应的嵌入空间中满足各自的语义结构,更好地反映了知识库、知识图谱的内在拓扑结构。
2)本发明提出的方法有效地利用了知识库中各个层次的上下文信息,不仅包括直观的实体层面的上下文信息,也包括现有方法中通常忽略的关系层面的高阶上下文信息,使得嵌入结果更加复合知识库、知识图谱的实际结构。
3)本发明提出的方法将丰富了知识库未能覆盖的潜在正确的三元组。与现有的未考虑高阶上下文信息的嵌入方法相比,代价敏感函数可以识别出可能与正确的关系同时出现的那些关系,从而降低了把一个可能正确的三元组错判为完全不正确的风险。
5)本发明的嵌入结果应用于知识库、知识图谱的可视化表达时,所表达出的各元素分布相对于现存的嵌入方法能表达出更强的语义信息。
6)本发明的嵌入结果与评分函数应用于问答系统时,如果需要预测知识库中未曾出现过的关系结构,准确率更高,且具有更强的鲁棒性。
附图说明
图1为本发明基于代价敏感学习的联合知识嵌入方法实施例的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
参考图1,所示为本发明实施例的基于代价敏感学习的联合知识嵌入方法的流程图,包括以下步骤:
步骤S1,通过知识库建立三元组组成的训练集,具体包括以下子步骤:
步骤S11,抽取知识库中所有的实体,建立实体集合E={e1,e2,…,en}.
步骤S12,抽取知识库中所有的实体,建立关系集合R={r1,r2,…,rm}.
步骤S13,对每一条关联事实,在E中寻找到关联事实的头实体与尾实体,在R中寻找到关联事实中的关系,建立三元组(ei1,ri1,ei2)。通过抽取知识库中的所有关联事实,建立训练集T={(e11,r11,e12),(e21,r21,e22),…,(et1,rt1,et2)}.
步骤S2,建立基于实体、关系嵌入向量的三元组评分函数,即在只考虑实体层面上下文关系的条件下,建立基本的优化目标,具体包括以下子步骤:
步骤S21,假设已知各实体与各关系的嵌入向量情况下,建立评估各条三元组的可能性的评分函数。为此,我们定义了评估三元组(e1,r,e2)合理性的嵌入向量评分函数S(e1,r,e2),其中e1,r,e2分别是e1,r,e2的嵌入向量。为了连接实体嵌入空间和关系嵌入空间,我们规定这两个空间拥有相同的维度,并且将评分函数定义为三元组中三个元素的嵌入向量的一个向量积:该向量积被定义为两个实体嵌入向量的加权内积,关系的嵌入向量作为权重。这样,评分函数将被写为以下形式:
其中r代表关系嵌入向量,而diag(r)代表一个对角元素组成的向量恰为r的对角矩阵。公式中所有的向量都是列向量。
步骤S22,建立基于最大边缘的优化目标。为了尽量满足训练集中已有的三元组,对于两个给定的实体,正确的关系所组成的三元组的得分应该比所有不正确的关系都高。也就是:S(e1,r,e2)>S(e1,r′,e2),其中(e1,r′,e2)是一个不存在于知识库中的三元组。为了提高嵌入效果,我们在优化时引入了边缘宽度γ,令优化结果满足S(e1,r,e2)-S(e1,r′,e2)≥γ以激励正确和不正确三元组的可判别性。这样,我们建立了一个基于边缘的排序模型,其训练目标为:
其中E和R分别是训练集中包含的实体与关系的集合,C是用来调节关系嵌入向量的正则项权重的超参数。该目标函数第一项是训练集中正样本与负样本所生成的损失函数,第二项则是关系嵌入向量作为参数在模型中的正则化项。在优化过程中,实体嵌入向量被归一化为单位向量,所以优化目标中没有关于实体嵌入向量的正则项。
步骤S3,建立代价敏感联合嵌入模型,具体包括以下子步骤:
步骤S31,建立代价敏感权重矩阵W来衡量每对关系之间同时出现的可能性,以利用关系之间的高阶上下文信息。W是一个方阵,其维度与e和r相同。W中每一个元素都代表了一种关系出现在已有另一种关系的两个实体之间的合理性。
步骤32,将代价敏感学习框架应用于公式2中。当计算三元组(e1,r,e2)∈T和所形成的损失时,我们为其加入一个权重Wrr′。其中,Wrr′即是代价敏感权重矩阵中代表r和r′关系的元素。如果r和r′经常同时出现,Wrr′的值应应该比较小。否则,Wrr′应该是一个比较大的值。通过加入代价敏感学习系统,优化目标被改写成如下形式:
subject to:S(e1,r,e2)-S(e1,r',e2)≥γ-ξtrr',
ξtrr'≥0,Wrr'≥0,∑Wrr'=δ,δ>0
与公式2相比,该目标函数的第一项损失函数加入了代价敏感学习系统,利用了知识库中的高阶信息,并且丰富了知识库未能覆盖的潜在正确的三元组。与未考虑高阶上下文信息的目标优化函数相比,代价敏感函数可以识别出可能与正确的关系同时出现的那些关系,从而降低了把一个可能正确的三元组错判为完全不正确的风险。
最后,公式3的优化求解采用了目前非常成熟的技术随机梯度下降法(stochastic gradient descent method)。求解过程中,利用小批量采样的方法,可以有效地对优化过程进行加速。
上述的方法应用于知识图谱、知识库的可视化及问答系统的构建时,其应用方式如下:
应用1,知识图谱、知识库的可视化,其步骤如下:
步骤1,通过1、所表达的方法得到所有实体与关系嵌入值,即所有的e和r;
步骤2,分别在实体空间和关系空间内对e和r所表示的点进行t-SNE降维;
步骤3,将步骤2中的降维结果进行归一化,在2维平面上可视化。
应用2,问答系统的构建,其应用方式如下:
步骤1,通过1、所表达的方法得到所有实体与关系嵌入值,即所有的e和r;
步骤2,将需要解答的问题转换为已知(e1,r,e2)中的2个,预测第3个元素的形式。举例来说,问A的B是什么时,将A作为e1,将B作为r,问题被转化为已知e1,r预测e2的问题;问A与B的关系是什么时,将A作为e1,B作为e2,问题被转化为已知e1,e2预测r的问题;
步骤3,对与给定的问题,固定(e1,r,e2)中已知的2个,将知识库中所有可能的元素都当作备选答案,构成一组答案集合。如问题被转化为已知e1,r预测e2的问题时,答案集合为{(e1,r,e*)|e*∈E};问题被转化为已知e1,e2预测r的问题,答案集合为{(e1,r*,e2)|r*∈R};
步骤4,对答案集合中的的所有三元组,通过公式1进行评分,并将得分进行排序;
步骤5,选取排序结果中最靠前的作为结果输出。
综上所述,本发明实施例首先基于知识库或者知识图谱的内容建立实体、关系集合,并基于关联事实建立三元组集合。在得到这些基本数据之后,定义基于实体、关系嵌入向量的评分函数,并基于此评分函数建立基于边缘的优化目标。最后,将代价敏感学习系统融合到到该优化目标中,建立代价敏感的综合损失函数作为优化目标并优化求解。
通过以上技术方案,本发明实施例在基于代价敏感学习框架的基础上展开了同时嵌入知识库中的实体与关系的联合知识嵌入方法。本发明可以同时和有效地利用各个层次上下文信息,去完成知识库中元素的嵌入工作,并且丰富了知识库未能覆盖的潜在正确的三元组,因而具有更高的鲁棒性。在应用中,本方法对于知识库、知识图谱的可视化结果,相对于现有其他方法,更能反映出知识库、知识图谱中各元素的语义结构;在应用于问答系统时,在预测知识库中未曾出现过的关系结构时,准确率更高,且具有更强的鲁棒性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!