两路及多路文件块合并的方法与流程
本发明涉及两路及多路文件块合并的方法。
背景技术:
在很多的应用场景(例如组播数据)中,需要把一个大文件拆分为很多个文件块,用文件偏移量(从文件指定位置向前或向后移动的字节数)来标识文件块在文件中的位置,而同时又往往涉及到把其中的一些文件块进行合并。例如,根据UDP协议组播大文件时,组播方会把一个大文件拆分为多个较小的文件块,将文件块和文件偏移量等信息组成数据包(UDP包)组播。组播过程中丢包很多时候难以避免,接收方发现有丢包,会将丢失的数据包的信息通知组播方。通常,组播方收到接收方的丢包信息后不会立即响应,而是将丢包信息涉及到的文件块进行合并,累积到一定程度后再统一重发。由于组播方面向多个接收方,组播方需要进行多路数据的合并,每路数据都包含了若干个文件块。
对于多路文件块的合并,可以选择位图(bitmap)、平衡数等算法,但这些算法各自有缺点。bitmap占用的内存大、遍历效率低。平衡树的节点会频繁的调整,合并的时间复杂度高。目前时间复杂度较优的算法尚未见报道。
在说明书“背景技术”部分公开的内容,有助于本领域技术人员理解本发明的技术方案,但不应据此认为这些内容一定属于现有技术或公知常识。
技术实现要素:
为了克服“背景技术”部分所反映的缺陷,本发明提供两路及多路文件块合并的方法。
两路文件块合并的方法,包括:
1)分别将每路数据中的文件块按照文件偏移量排序,在每路数据中设置一个指针指向排序第一的文件块;
2)如果两路数据指针指向的两个文件块在文件中的范围不重叠,则将文件偏移量为最值的文件块放入合并数据结构,原指向文件偏移量为最值的文件块的指针指向该路数据按照排序的下一个文件块;
如果两路数据指针指向的两个文件块在文件中的范围重叠,则将两个文件块合并为一个新文件块,新文件块位于一路数据中,原指向合并前文件块的指针一个指向新文件块另一个指向该路数据按照排序的下一个文件块;
如果两路数据指针指向的两个文件块中的一个文件块在文件中的范围被另一个文件块覆盖,则将在文件中的范围被另一个文件块覆盖的文件块删除,原指向被删除文件块的指针指向该路数据按照排序的下一个文件块;
3)重复2)直到遍历完两路数据的所有文件块。
进一步的,2)中所述的合并数据结构为链表。
进一步的,2)中所述将两个文件块合并为一个新文件块,新文件块位于一路数据中时,新文件块在文件中的范围与该路数据按照排序的下一个文件块不重叠。
多路文件块合并的方法,包括:
1)将多路数据中的各路数据按照两路文件块合并的方法进行两两合并,直到未进行合并的数据路数不超过一;
2)重复1)直到多路数据合并为一路数据。
本发明技术方案中,“包括”、“用于”等词语应按照开放式表达方式理解。本领域技术人员通过阅读本说明书并结合现有技术或公知常识能够获知的内容,本说明书中不再赘述。
本发明提供的两路及多路文件块合并的方法,对于两路及多路数据每路数据都包含了多个文件块的情形,合并文件块的算法达到了最优或较优的时间复杂度。
附图说明
图1为具体实施方式中两路文件块合并的方法的流程图。
图2为具体实施方式中两路文件块合并的方法一个理想化示例的示意图。
图3为具体实施方式中多路文件块合并的方法的流程图。
具体实施方式
下面对本发明的实施方式进行进一步的具体说明。但应注意,本发明的范围并不局限于所描述的具体技术方案。任何对所描述的具体技术方案中的技术要素进行相同或等同替换获得的技术方案或本领域技术人员在所描述的具体技术方案的基础上不经过创造性劳动就可以获得的技术方案,都应当视为落入本发明的保护范围。
在本发明技术方案中,两路或多路(多路指超过两路)数据中任何一路数据的文件块都来源于同一个原始文件(这样进行合并才有意义),这些文件块都有与其对应的文件偏移量,这样根据文件偏移量和文件块本身的大小(也称为文件块的长度)可以确定文件块在文件(原始文件)中的范围。例如,一个大小2K的文件块来自一个大小10K的文件,该文件块的文件偏移量(从文件起始位置计算)为6K,则该文件块在文件中的范围为6K-8K。
两路文件块合并的方法,其流程如图1所示,包括:
S101:分别将每路数据中的文件块按照文件偏移量排序,在每路数据中设置一个指针指向排序第一的文件块。
具体的,本步骤中,分别将每路数据中的文件块按照文件偏移量排序。如果文件偏移量是从文件起始位置计算的,可以按照文件偏移量从小到大的顺序排序;如果文件偏移量是从文件结束位置计算的,可以按照文件偏移量从大到小的顺序排序。每路数据的文件块按照文件偏移量排序后,在每路数据中都设置一个指针。初始时指针指向排序第一的文件块,后续指针会不断移动遍历该路数据中的所有文件块。
S102:如果两路数据指针指向的两个文件块在文件中的范围不重叠,则将文件偏移量为最值的文件块放入合并数据结构,原指向文件偏移量为最值的文件块的指针指向该路数据按照排序的下一个文件块;
如果两路数据指针指向的两个文件块在文件中的范围重叠,则将两个文件块合并为一个新文件块,新文件块位于一路数据中,原指向合并前文件块的指针一个指向新文件块另一个指向该路数据按照排序的下一个文件块;
如果两路数据指针指向的两个文件块中的一个文件块在文件中的范围被另一个文件块覆盖,则将在文件中的范围被另一个文件块覆盖的文件块删除,原指向被删除文件块的指针指向该路数据按照排序的下一个文件块。
具体的,本步骤中,设置一个专用的合并数据结构来存储两路文件块合并后获得的文件块,合并数据结构常选取为链表。
本步骤对指针指向的文件块在文件中的范围进行比较,不同情况进行不同的处理。步骤S101中,两路数据的指针都已经指向了一个文件块,这两个文件块的文件偏移量相对于本路数据排序在后的其他文件块都是极值(极大或极小),将两个极值比较可以找到文件偏移量的最值(在两个极值中是最大或最小的)。比较两个文件块在文件中的范围是否重叠。重叠指两个文件块在文件中的范围存在相同的部分,也有各自不同的部分,两个文件块有相同的数据,但任何一个文件块都有另一个文件块没有的数据。还有一种特殊的情况,两个文件块没有相同的数据,但它们在文件中的范围紧密连接,中间没有任何空隙,例如一个文件块在文件中的范围6K-8K,另一个文件块在文件中的范围8K-10K,从节约存储空间等角度考虑,这种特殊情况也视为文件块重叠。如果两个文件块不重叠,则将文件偏移量为最值的文件块放入合并数据结构,原指向文件偏移量为最值的文件块的指针指向该路数据按照S101排序确定的下一个文件块。如果两个文件块重叠,则进行文件块的合并,将两个文件块合并为一个新文件块。合并的方法是将两个文件块中的一个删除,另一个文件块加入被删除的文件块所包含的其没有的数据。对于特殊的文件块,文件块只用起始处和结尾处的文件偏移量表示,并不包含具体的数据,则合并的方法将两个文件块中的一个删除,另一个文件块修改起始处或结尾处的文件偏移量即可。合并操作的结果新文件块位于一路数据中,原指向合并前文件块的指针一个指向新文件块另一个指向该路数据按照S101排序确定的下一个文件块。
对于将两个文件块合并为一个新文件块的操作,新文件块具体位于那一路数据,需要满足以下约束条件,即新文件块在文件中的范围与该路数据按照S101排序确定的下一个文件块不重叠。这样可以保证任何一路数据的指针都会按照S101确定的顺序,一个文件块一个文件块的移动,在移动时不会跳过某一个文件块。实现该约束条件,可以采用如下方法:如果文件块对应的文件偏移量是从文件起始位置计算的,则比较两个文件块结尾处的文件偏移量,保留结尾处文件偏移量较大的文件块,删除结尾处文件偏移量较小的文件块,在删除前将待删除的文件块中从其起始处到保留的文件块的起始处(通过文件偏移量可以知道保留的文件块的起始处在待删除的文件块中的位置)的数据加入保留的文件块。对于特殊的文件块,文件块只用起始处和结尾处的文件偏移量表示,并不包含具体的数据,则将保留的文件块起始处的文件偏移量修改为删除的文件块起始处的文件偏移量即可。
还有一种情况,两路数据指针指向的文件块中的一个文件块在文件中的范围被另一个文件块覆盖。覆盖指一个文件块在在文件中的范围被另一个文件块完全包含,一个文件块的所有数据另一个文件块都有。此时可以直接将在文件中的范围被另一个文件块覆盖的文件块删除,原指向被删除文件块的指针指向该路数据按照S101排序确定的下一个文件块。
S103:重复S102直到遍历完两路数据的所有文件块。
具体的,本步骤中,不断重复步骤S102直到遍历完两路数据的所有文件块,这样两路数据中的所有文件块都执行了步骤S102中相应的操作,合并数据结构中存储了最终合并结果。
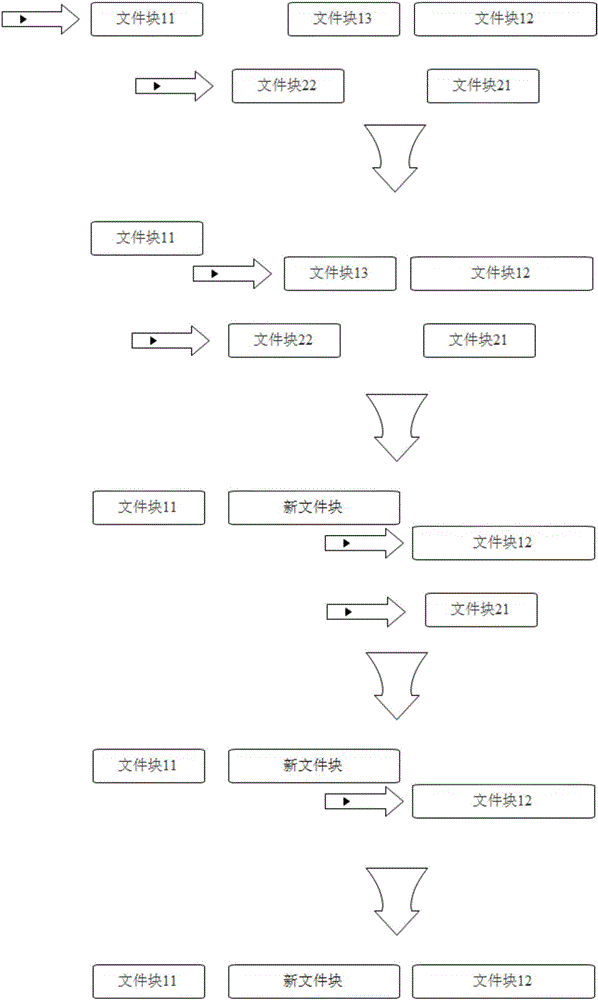
下面通过一个简单的理想化示例对两路文件块合并的方法进行进一步的说明,该理想化示例如图2所示,图中内置黑色三角形的箭头表示指针。为了简单起见,假设第一路数据只有文件块11、12、13三个文件块,第二路数据只有文件块21、22两个文件块。这些文件块在文件中的范围图2中已经画出,不再使用具体的数值表示。假设文件块对应的文件偏移量是从文件起始位置计算的,两路数据的文件块按照文件偏移量从小到大的顺序排序,第一路数据的排序结果为文件块11、13、12,第二路数据的排序结果为文件块22、21。每路数据中设置一个指针,初始时第一路数据的指针指向文件块11,第二路数据的指针指向文件块22。比较文件块11和文件块22在文件中的范围,发现两个文件块不重叠,而文件块11的文件偏移量最小,此时将文件块11放入合并数据结构,第一路数据的指针指向文件块13,第二路数据的指针仍指向文件块22。文件块11放入合并数据结构后,其在第一路数据中的对应数据被删除。
比较文件块13和文件块22在文件中的范围,发现两个文件块重叠,需要把文件块13和文件块22合并为新文件块。具体的合并方法可以是删除文件块22,修改文件块13加入文件块22中与文件块13不相同的数据形成新文件块。新文件块位于第一路数据,其在文件中的范围与文件块12不重叠,符合要求。第一路数据的指针指向新文件块,第二路数据的指针指向文件块21。比较新文件块和文件块21,发现两个文件块不重叠,新文件块的文件偏移量最小,则将新文件块放入合并数据结构,第一路数据的指针指向文件块12,第二路数据的指针仍指向文件块21。新文件块放入合并数据结构后,其在第一路数据中的对应数据被删除。
比较文件块12和文件块21在文件中的范围,发现文件块21在文件中的范围被文件块12覆盖,则直接删除文件块21。删除文件块21后,第二路数据的所有文件块已经遍历完毕,此时第二路数据的指针可以视为指向了文件结尾。比较文件块12和第二路数据指针的指向在文件中的范围,显然不重叠并且文件块12的文件偏移量最小,则将文件块12放入合并数据结构,删除其在第一路数据中的对应数据。此时第一路数据的所有文件块也已经遍历完毕。
至此,两路文件块的合并完成,合并数据结构中存储了五个文件块的最终合并结果,而原第一路数据和第二路数据的存储空间也都被释放出来。
按照以上方法,如果第一路数据中有M个文件块,第二路数据中有N个文件块,则算法的时间复杂度为O(M+N),这已经是最优的时间复杂度。
在两路文件块合并的方法的基础上,可以实现多路文件块合并的方法。多路文件块合并的方法的流程如图3所示,包括:
S301:将多路数据中的各路数据按照两路文件块合并的方法进行两两合并,直到未进行合并的数据路数不超过一;
S302:重复S301直到多路数据合并为一路数据。
多路文件块合并的方法的本质,是基于两路文件块合并的方法进行多轮次的两两合并,降低多路数据的路数,最终合并为一路数据。
下面通过一个理想化的简单示例对多路文件块合并的方法进行说明。假设一共5路数据进行合并,各路数据直接标记为1路、2路、3路、4路、5路。
第一轮两两合并,利用两路文件块合并的方法将1路和2路合并为新1路,3路和4路合并为新3路。由于总的数据路数是单数,5路数据无法进行合并,但已经满足未进行合并的数据路数不超过1的条件,第一轮两两合并结束。
第二轮两两合并,利用两路文件块合并的方法将新3路和5路合并为贰新5路。由于总的数据路数是单数,新1路数据无法进行合并,但已经满足未进行合并的数据路数不超过1的条件,第二轮两两合并结束。
第三轮两两合并,利用两路文件块合并的方法将新1路和贰新5路合并为一路数据。至此多路文件块的合并结束。
本发明提供多路文件块合并的方法的时间复杂度为O(N*logK),其中N为多路数据中文件块的总个数,K为总的数据路数。这也是较优的时间复杂度。
本领域技术人员在以上所描述的具体技术方案的基础上,完全可以构造出其他方案,在此不一一列举。
- 还没有人留言评论。精彩留言会获得点赞!