一种融合差分子空间与正交子空间的图像集分类方法与流程
本发明涉及图像处理与模式识别技术领域,具体涉及一种融合差分子空间与正交子空间的图像集分类方法。
技术背景
图像分类属于模式识别范畴,图像集分类作为图像分类的一个扩展,随着视频监控技术的快速发展和互联网的普及,受到了越来越多的重视。传统的图像分类方法大部分都以单幅图像为分析单元,或者在训练过程中对同类的一组图像进行分析提取判别特征,但这些方法在最终识别过程中都是以单幅图像为测试单元进行分类。图像集分类方法是指以多幅相同类别图像组成的图像集作为单元进行分析训练和最终的判别分类的方法。相比传统的基于单幅图像的图像分类方法,以图像集为分类单元的图像集分类方法具有较多的优势,特别在识别目标具有较大的变化时,如姿态、光照、不同场景等,由于图像集包含了物体多幅不同的图像,因此图像集往往具备更多的可提供判别的信息,因而能够有效提高识别能力。
目前图像集分类方法中,主要有两个需解决的重要问题:1)如何寻找有效的图像集表达方式;2)如何度量两个图像集之间的相似度(或距离)。在表达图像集的方式上,子空间是其中最受关注的表达图像集的一种方式,近十多年来,以子空间为基础进行图像集分类一直是图像集分类的主流方法。最近(2015年)出现了一种基于广义差分子空间(Generalized Difference Subspace,GDS)的图像集分类方法(Fukui K,Maki A.Difference Subspace and Its Generalization for Subspace-Based Methods[J].IEEE Trans.Pattern Anal.Machine Intell.(PAMI)2015,37(11):2164-2177.),实际上它是2003年提出的受限互子空间方法(Constrained Mutual Subspace Method,CMSM)的推广。基于广义差分子空间的图像集分类方法通过利用所有参考图像集的线性子空间建立了一个基于它们的差分子空间,并将所有原始子空间投影到该差分子空间上,从而获得更具判别力的新子空间,最后使用互子空间方法(Mutual Subspace Method,MSM)进行相似度度量并分类,因此该方法简写为GDS+MSM方法。该差分子空间是所有训练图像集子空间的公共子空间中,对应特征值较小的特征向量所组成的差分成分。GDS+MSM方法认为这些差分成分能够有效提取原来各个图像集子空间中具有差别的判别信息,从而有效区别不同类别的子空间。
早在2007年,一种基于白化互子空间(Whitened Mutual Subspace Method,WMSM)的图像集分类方法(Kawahara T,Nishiyama M,Kozakaya T,et al.Face recognition based on whitening transformation of distribution of subspaces[C].Proceedings of the Asian Conference on Computer Vision Workshops,Subspace2007,2007:97-103.)被提出,它的基本理论是通过一个白化矩阵将所有不同类别的子空间都变成互相正交的子空间。因此,如果两个子空间正交,那么它们之间的相似度最小;如果它们之间的夹角越小,相似度越大。通过白化矩阵的变换,使不用类别的图像集之间的相似度减至最小。因此该方法也叫做正交互子空间方法,于是在GDS+MSM方法的论文里WMSM也被称作为Orth+MSM方法,简称其白化矩阵为正交子空间。Orth+MSM的正交子空间是由所有训练图像集线性子空间的公共子空间的最大的特征值所对应的特征向量组成,并且对该部分特征空间进行白化处理而得到。
然而,可以看到GDS+MSM和Orth+MSM方法都存在着一个共同的问题,两种方法都舍弃了各自公共子空间中的部分特征空间。例如GDS+MSM只使用公共子空间中小的特征值所对应的特征空间,丢弃大的特征值所对应的特征空间。而Orth+MSM则只使用公共子空间中大的特征值所对应的特征空间,丢弃小的特征值所对应的特征空间。另外,可以发现这两种具有相似算法框架的方法却各自使用彼此被丢弃的特征空间用作子空间的判别分析,这实际上也说明了训练图像集的公共子空间的所有特征空间实际上都具有判别信息。因此本发明将使用公共子空间中所有的特征空间进行判别分析。本发明提出使用最优融合分割点的方法融合差分子空间与正交子空间,建立一个满秩的投影变换矩阵,从而提取更具有判别能力的子空间,用于图像集分类。
技术实现要素:
本发明的目的在于提出一种融合差分子空间与正交子空间的图像集分类方法(Fusion of Difference subspace and Orthogonal subspace,FDO)。根据基于差分子空间的GDS+MSM方法和基于正交子空间的Orth+MSM方法,它们都使用了一个相似的投影变换矩阵来产生新的更具有判别力的图像集子空间来进行图像集的分类。本方法将整合这两种不同的投影变换矩阵,建立一个能充分利用所有判别特征空间的新的满秩投影变换矩阵。同时本方法使用最优融合分割点的方法来融合该两种投影变换矩阵。具体实施步骤包括了训练过程、测试过程和参数估计过程:
1.训练过程
(1)给定样本集合,生成各个图像集的子空间。
对于给定的C个d维不同类别的训练图像集的子空间的自相关矩阵(其中Φi是第i个子空间的标准正交基),所有样本子空间都在L个D(D≥d)维数据空间上的样本图像集k=1,...,C中生成。
(2)生成所有训练图像集子空间的公共子空间。
用奇异值分解(SVD)对矩阵进行分解得到Λ是一个对角元素为G的从大到小排列的特征值为的D×D对角阵;而H是矩阵G的一个D×D维标准正交基,即所有训练图像集的公共子空间。
(3)使用最优分割点方法在公共子空间上融合差分子空间与正交子空间。
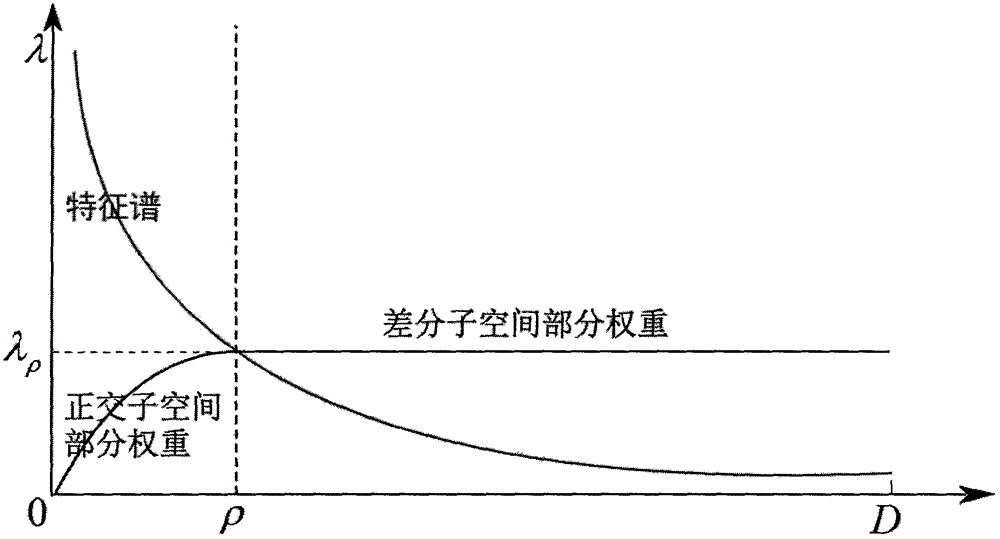
该步骤是本发明的重点,本发明将使用一个验证得到的最优分割点ρ*,将公共子空间,即标准正交基H,分成两个部分,参见图2,然后对两部分特征空间按照特征值大小分别进行处理。对于大的特征值部分所对应的特征空间,即正交子空间,本发明按照正交子空间方法,使用一个白化矩阵对其进行白化处理,用分割点ρ*将特征空间分为两个部分,H=[Ha Hb],分别对应特征值大的部分Λa和特征值小的部分Λb:Λ=[Λa Λb]。
那么,正交子空间为:其中Λa是由ρ*个最大特征值组成的对角阵,而ρ*是参数估计中得到的最优分割点。差分子空间使用固定的权值加权差分特征空间,因此本发明设定差分子空间的权重使用分割点所对应的特征值用以下公式得出差分子空间:为从大到小排列的第ρ*个特征值,也是正交子空间与差分子空间的分割点。
最后将两部分空间进行融合:Θ=[Θa Θb],得到最终新的满秩的投影变换矩阵。
(4)将第k类的一个图像集的所有样本投影到融合的投影变换矩阵Θ上,并得到投影后的样本这里τ(·)表示样本投影变换运算;
(5)对变换后的样本用主元分析方法(PCA)提取d维线性子空间Sk,并用其一个标准正交基Φk来表示。
2.测试过程
(1)对给定的一个测试图像集将其中的每个样本都投影到融合的投影变换矩阵Θ上,得到新的图像集
(2)采用PCA方法对变换后的样本集提取d维线性子空间Ste,用一个标准正交基Φte表示。
(3)采用互子空间方法(MSM)比较Φte和所有经过投影的训练图像集子空间的标准正交基的相似度。
(4)使用最近邻分类器(NN)进行分类。
3.参数估计过程
在训练过程当中,需要确定在所有维度的公共子空间中,差分子空间与正交子空间的分割点,在本发明中,通过建立实验评估,寻找最优的融合分割点。
(1)首先建立用于参数估计的训练集合和测试集合;
(2)根据所有训练图像集公共子空间的从大到小排列的特征谱,设定正交子空间与差分子空间在整个公共子空间中的初始分割点ρ1;
(3)使用融合差分子空间与正交子空间的图像集分类方法的训练过程和测试过程,进行图像集识别,从而得出识别率χ1;
(4)按照一定的步进,改变分割点在特征谱上的位置,设定一个新的分割点ρ2;
(5)重复第(3)-(4)步,得出对应不同分割点的不同识别率(可使用多次交叉试验得到的平均识别率争强泛化能力);
(6)建立识别率和对应分割点位置的曲线图,找出最优的识别率对应的分割点ρ*,最后使用该分割点为最优融合分割点。
本发明的优点在于找出了分别基于差分子空间和正交子空间的图像集分类方法都丢失公共子空间的部分信息而进行图像集分类的问题,从而对该问题进行分析和提出解决办法。本发明提出使用最优融合分割点的方法融合差分子空间与正交子空间技术,并组成一个满秩的投影变换矩阵,从而产生能够充分利用所有训练图像集子空间的公共子空间中的所有判别信息。使用最优分割点的方法解决差分子空间与正交子空间的融合点,可以得到最适合、识别率最优的融合方式。
附图说明
图1为融合差分子空间与正交子空间的图像集分类方法实现流程图。
图2为差分子空间与正交子空间的融合方式示意图。
图3为差分子空间与正交子空间的最优融合分割点选择方法曲线图。
具体实施方式
下面以本发明在YouTube Celebrities人脸数据集中进行图像集分类为例,说明本发明的具体实施过程。
YouTube Celebrities人脸数据集是一个大型的名人网络视频数据库,视频数据都取自YouTube网站。它包含了47个人共1910个视频序列。实施过程挑选了其中的453个视频序列作为验证数据;同时为了实现参数的估计,抽取了其中341个视频序列用于估计最优融合分割点。对于每个视频序列抽取其中的视频帧,由此建立一个图像集。而对于每个人的参考(训练)图像集包含1-3个图像集,而测试集则包含有0-12个图像集,每个图像集都包含了在视频帧中选取的较好的50幅人脸图像。而每幅人脸图像都使用一个级联的人脸分类器检测并切割成只包含人脸区域的图像,最后得到20×20像素大小的灰度人脸图像。
本发明的具体实施过程分为两个部分:
1.参数估计
实施过程首先要建立评估最优分割点的实验。本实施例选取所有图像集中的341个图像集用作最优分割点的估计基础数据。其中每个类别都选取1-3个图像集作为训练集或参考集,建立包含122个图像集的训练集,剩余的219个图像集用作测试。为了使参数估计的泛化性和鲁棒性,参数估计过程进行重复随机抽取交叉验证的方法,随机交叉抽取10组以上的训练集与测试集进行实验。
按照发明内容的参数估计步骤,需要重复执行如图1所示的训练过程和测试过程多次以得到最终最优参数。首先根据从大到小排列特征谱对应的公共子空间,使用初始的差分子空间与正交子空间分割点ρ1建立训练过程,如选择ρ1=10,即分割整个公共子空间为10维度的正交子空间和390维度的差分子空间。根据所有训练图像集,合并所有相同类别的图像集为单一图像集,得到1-C个图像集,采用主元成分分析得到每个图像集的线性子空间,每个线性子空间的维度选择为16。根据所有训练子空间,用奇异值分解计算它们的公共子空间H=[Ha Hb]。然后参见图2,根据分割点ρ1,对公共子空间的不同部分进行加权,得到不同大小的正交子空间和差分子空间,并将它们进行合并,得到融合的满秩投影变换矩阵Θ=[Θa Θb]。
接着将所有训练和测试图像集都投影到满秩的投影变换矩阵上,并使用主元分析方法(PCA)重新建立能够整体代表图像集的线性子空间,然后使用互子空间方法(MSM)进行不同子空间之间的相似度度量,最后采用最近邻分类器进行分类得到识别率χ1。
为了得到具有泛化能力和鲁棒的最优融合分割点,实施过程在341个用于参数估计的图像集中重新进行随机交叉分配训练集和测试集,并再次执行上述的图像集分类过程,得到新的识别率χ2。在整个参数估计过程中,建立了10次这样的识别过程,这样就得到了10个对应分割点ρ1的识别率对这10个识别率计算其均值,记为
根据从大到小排列特征谱对应的公共子空间,采用步进法(本发明采用10个维度的步进)更改差分子空间与正交子空间在整个公共子空间中的分割点位置为ρ2=20,重复以上的图像集分类过程,得到对应m个不同分割点上的m个平均识别率建立对应分割点和平均识别率之间关系的曲线图,参见图3,其中横坐标是不同分割点在从大到小排列的特征谱上的位置,纵坐标是对应的平均识别率。根据曲线图关系,最终得到最优平均识别率对应的最优融合分割点ρ*,在本次具体实施过程中,参见图3所示,可以看到,对应YouTube Celebrities人脸数据集得到的最优融合分割点为ρ*=60。
2.使用估计的最优融合分割点验证本发明的有益效果
为验证本发明的有益效果,验证过程将在整个选出的数据集中进行图像集分类。总共包含453个图像集,其中选择47个不同类别的122个图像集作为训练图像集,而剩下的331个图像集作为测试集。为了得到更泛化的结果,实施过程将重复随机抽取不同的训练集和测试集的组合10次,最后取10次的平均值和标准差作为最终的分类结果。
参照图1,再次执行上述参数估计中的训练过程和测试过程,不同的是在这次有效性验证过程中不再改变分割点,而是使用估计的最优分割点。对于其中的一组数据,首先进行图像集的训练过程,根据参数估计过程得到的最优分割点ρ*=60,按照图1的步骤和图2的融合模式,建立所有类别的训练图像集的融合投影变换矩阵,然后将所有训练和测试图像集都投影到该满秩的融合投影变换矩阵上,并使用主元分析方法(PCA)重新建立所有图像集的线性子空间,接着使用互子空间方法(MSM)进行不同子空间之间的相似度度量,最后采用最近邻分类器进行分类得到最终识别率。
为了公平展示本发明相比其它方法的有益效果,本实施过程除了选取和本发明息息相关的Orth+MSM和GDS+MSM方法外,还选取了最经典和近期使用子空间技术来实现图像集分类的相关方法进行比较。其中包括了1998年提出的经典的互子空间方法(MSM)(Yamaguchi O,Fukui K,Maeda K I.Face recognition using temporal image sequence[C].Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition(FG),1998:318-323),2007年提出的典型相关判别分析方法(DCC)(Kim T K,Kittler J,Cipolla R.Discriminative learning and recognition of image set classes using canonical correlations[J].IEEE Trans.Pattern Anal.Machine Intell.(PAMI),2007,29(6):1005-1018),2008年提出的Grassmann流形判别分析方法(GDA)(Hamm J,Lee D D.Grassmann discriminant analysis:A unifying view on subspace-based learning[C].Proceedings of the International Conference on Machine Learning(ICML),2008:376-383),2011年提出的基于图理论的Grassmann流形判别分析方法(GGDA)(Harandi M T,Sanderson C,Shirazi S.et al.Graph Embedding Discriminant Analysis on Grassmannian Manifolds for Improved Image Set Matching[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2011:2705-2712),和2015年的Grassmann流形最近邻点方法(GNP)(Grassmann manifold for nearest points image set classification[J].Pattern Recognition Letters,2015,68:190-196)。这里给出以上所有方法在10组YouTube Celebrities人脸测试数据中的平均识别率和标准差,和本发明所提出的方法进行比较结果如表1所示。
表1图像集分类识别率比较
可以看出,本发明相比于2015年提出的广义差分子空间(GDS+MSM)方法和2007年的正交子空间方法(Orth+MSM)有更好的识别率,是因为GDS+MSM方法只使用了差分子空间作判别分析,而Orth+MSM方法只使用了正交子空间作判别分析;然而,本发明同时使用了差分子空间和正交子空间作判别分析,并采用最优融合分割点的方法得到参数最优的融合方式。因此本发明是前两种方法的进一步改进,从而获得了更好的判别能力。
另外,本发明相比于其它经典的、目前流行的基于子空间的图像集分类方法也具有更好的识别结果,如表1所示。因此,本发明所提出一种融合差分子空间与正交子空间的图像集分类方法在使用子空间技术进行图像集分类上体现出了更好的有益效果。
以上所述的具体实施例,仅为本发明的一个具体实施例,并非因此限制本发明的专利范围。凡根据本发明的发明内容,对本发明实施例进行简单修改、等同替换等不脱离本发明宗旨范围的变动,均应涵盖在本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!