一种基于交易数据的机器学习反欺诈监测系统的制作方法
本发明涉及金融领域,尤其是指一种基于交易数据的机器学习反欺诈监测系统。
背景技术:
互联网技术的蓬勃发展造就了新一轮的金融革命,但过快的增长也蕴藏着极大的盲目性,相伴而生的是日趋严重的欺诈风险。目前较为常见的欺诈监测模式包括基于大数据的风险政策、反欺诈体系以及精英风控团队等。虽然大多数支付机构都有欺诈监测系统,但多数仍依赖于精英团队在案例分析的基础上进行规则归纳。然而,欺诈手段层出不穷和交易行为的不一致给规则归纳带来了困难。同时,当前规则系统难以保持其鲁棒性,性能也将随着规则体系的扩大而下降,无法保证高查准率的同时有高查全率,从而降低用户体验。
机器学习由于其在非线性与代价敏感场景的优势,同时又较少依赖于人工分析,表现出了更优的鲁棒性与稳定性,所以逐渐成为一种新的欺诈检测方案。
技术实现要素:
本发明的目的在于针对现有技术存在的问题,提供一套面向金融领域的交易欺诈实时监测系统。通过对清洗后的历史交易数据进行分析和建模,在新交易发生时,将当前交易行为与历史交易行为进行比较,根据输出的评分对该笔交易风险进行实时判断,从而达到实时交易欺诈检测的目标。该系统可以在较低误报率情况下,达到较高的精准度和查全率,从而保证客户的交易安全。
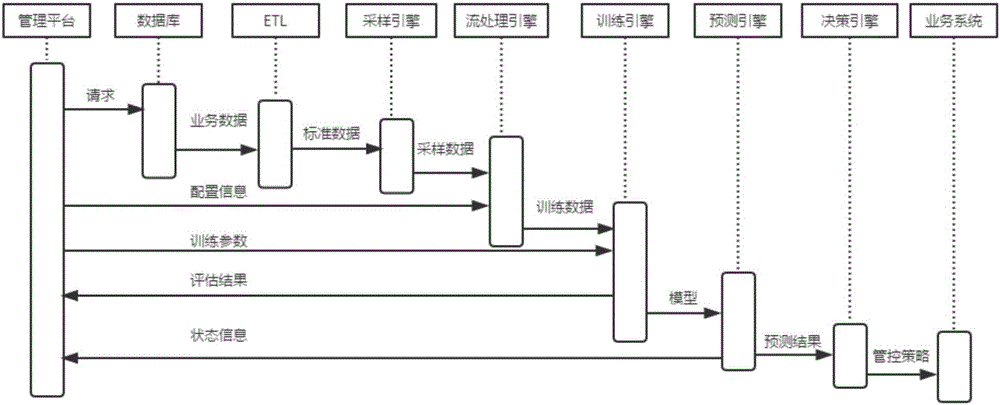
本发明的目的是通过以下技术方案来实现的:一种基于交易数据的机器学习反欺诈监测系统,该系统包括管理平台、ETL模块、采样引擎、流处理引擎、训练引擎、预测引擎和决策引擎;
所述管理平台提供每个模块的配置信息,并发起模型训练请求和预测请求,对模型进行管理和更新操作;所述配置信息包括ETL模块所需的数据时间区间,采样引擎所需的数据库字段,流处理引擎所需的特征名称和计算方式,训练引擎所需的算法名称和算法参数。
所述ETL模块根据管理平台的配置信息,提取原始数据库数据,进行数据抽取、转换、入库操作;所述数据转换操作主要对数据进行清洗和标准化,包括两部分:将原始数据库自定义的数据转化为标准数据;将机器学习模型无法处理的字段进行转化;数据入库操作将处理完毕的数据存入任意常用数据库。
所述采样引擎根据管理平台的配置信息对原始数据进行采样,从原始数据中提取流处理引擎需要的数据库字段。
所述流处理引擎根据管理平台配置的特征名称和计算方式,对采样数据进行特征提取和计算。
所述训练引擎包括数据清洗、模型训练、模型评估;所述数据清洗,对数据进行缺失值处理、归一化处理等标准数据清洗操作;所述模型训练,根据设定的模型参数,利用清洗后的特征数据进行训练,具体为:读取管理平台配置的算法名称和算法参数,调用常见的机器学习算法,包括有监督算法和无监督算法进行学习;有监督算法包括逻辑回归、线性回归、支持向量机、决策树算法等;无监督算法包括k‐means聚类等;所述模型评估,利用新的数据集对训练好的模型进行评价,根据输出的查全率、查准率,KS值,ROC曲线等指标对模型质量进行评价,如果质量符合要求即可进行模型部署和使用;所述模型训练模块通过预先设置的更新时间,自动获取最新数据并重新训练模型,从而使模型始终保持有效性。
所述预测引擎调用训练好的模型对依次流过ETL模块、采样引擎、流处理引擎的实际交易数据进行判别,输出属于正常交易的概率和属于欺诈交易的概率,将预测结果传给决策引擎。
所述决策引擎根据预测引擎的输出,对该笔交易的危险性进行决策。
进一步地,所述训练引擎中的机器学习算法,针对黑样本查全率进行改造,具体为:给黑样本损失函数赋以比白样本大的权重,使其更倾向于找出更多的黑样本;或者,对黑样本进行过采样,白样本进行欠采样;或者,在损失函数后增加正则项,降低模型复杂度,提高模型范化能力;或者,采用集成学习框架,克服单模型的过拟合。
针对资金损失率进行改造,对高金额样本赋以低金额大的权重,使模型更倾向于少分错高金额样本;或者,根据单笔交易金额动态调整概率阈值,使对高金额的交易更难被判别为白样本;
针对算法性能做优化,使用GPU加速算法中可以并行化执行的函数,大大降低训练和预测时间;或者,使用线性代数库实现算法底层的计算操作;或者,使用多线程技术并行化实现算法。
进一步地,流处理引擎通过流式大数据处理对庞大的交易原始数据进行特征的快速提取和计算,可以获取某个时间区间内某个维度下某用户历史交易量累计、占比、方差、均值、求和、计数、最小数统计、标准差统计计算、偏度、峰度、去重等特征量。
整个系统使用流程上可以分为训练和预测两个部分。
训练时,使用管理平台对各个模块的信息进行配置,并发起训练请求,ETL模块根据配置信息,提取原始数据库数据,进行数据抽取、转换、入库操作。采样引擎根据配置对原始数据进行采样,得到需要的数据库字段。流处理引擎对采样数据进行特征提取和计算,训练引擎首先对数据进行清洗,根据设定的模型参数,利用特征数据进行训练,然后利用新的数据集对模型进行评估,根据多重指标判断模型质量,如果质量符合要求即可进行模型部署和使用,至此训练部分结束,否则重复上述操作过程。
预测时,ETL模块根据训练时采集数据的配置实时获取交易数据,采样引擎和流处理引擎通过采样操作和流式计算,得到特征数据并输入模型,预测引擎获取模型输出,决策引擎根据输出概率进行实时决策。
本系统对比现有技术和系统有明显的优势,系统可以在维持较好稳定性/健壮性的同时,保证较高的查全率和较低的误报率。上述特性主要由以下几点保证:流处理引擎通过流式大数据处理对庞大的交易原始数据进行特征的快速提取和计算,从海量原始数据中得到有代表性的特征,充分提取数据中的信息。模型训练模块使用多种针对资金损失率、黑样本查全率优化过的机器学习模型和集成学习框架,得到的是针对某个指标优化的复合模型,克服了单个模型带来的过拟合、不稳定的缺陷,提高了模型的稳定性和泛化能力;模型训练模块通过预先设置的更新时间,自动获取最新数据并重新训练模型,从而使模型始终保持有效性,避免欺诈变异带来的模型失效问题。
附图说明
图1是本发明之较佳实施例的结构框图。
图2是本发明之较佳实施例中典型时序图。
具体实施方式
为更清楚地阐述本发明的结构特征和功效,下面结合附图与具体实施例来对本发明进行详细说明。
如图1、2所示,本发明提供的一种基于交易数据的机器学习反欺诈监测系统,包括管理平台、ETL模块、采样引擎、流处理引擎、训练引擎、预测引擎和决策引擎;
管理平台提供系统管理的可视化界面,用户可以将每个模块需要的信息在管理平台上进行配置,每个模块将自动从管理平台获取配置信息并进行对应操作。管理平台还可以发起模型训练请求和预测请求,对模型进行管理和更新操作。
在收到训练请求后,ETL模块获取金融系统前端触发的交易行为数据,进行数据抽取、转换、入库操作。具体而言,该ETL模块主要获取金融系统交易行为的数据,包括交易时间、交易地点、交易IP、终端类型(移动、PC端、操作系统类别等)、交易金额、交易账号等,这些数据主要可分为以下大类:
1、交易环境:包括交易时间、交易IP、交易终端等。
2、交易内容:包括交易金额、交易帐号、交易密码等。
3、帐号特征:包括地域特征、时空特征、性别特征、年龄特征等。
4、聚合数据:指数据的聚合量,包括3小时内交易次数等。
5、其它数据:指与该账号关联的其它方面的数据。
数据转换操作主要对数据进行清洗和标准化,主要包括两部分:将原始数据库自定义的数据转化为标准数据,如将时间转化为标准时间;将机器学习模型无法处理的字段进行转化,如比如电话号码转换为归属地。
数据入库操作就是将处理完毕的数据存入任意常用数据库,如Oracle。
采样引擎通过管理平台的配置文件从上述数据库中取需要的数据,配置文件包括所需数据的时间段、所需字段的名称等信息,相当于一份所需数据清单,取到的数据存放在内存中。
流处理引擎对采样引擎取到的数据进行计算,根据管理平台上需要的特征信息,引擎将原始数据转化为特征数据,如某特征是计算每个用户在过去24小时的累计交易金额,流处理引擎就会查找每个用户过去24小时的交易记录并将交易金额进行累加。最终计算好的结果存放在文件中,文件可以是任意标准格式,如CSV,txt。
训练引擎包括数据清洗、模型训练、模型评估。首先对数据进行缺失值处理、归一化处理等标准数据清洗操作。然后读取管理平台界面上配置的算法名称和算法参数,调用常见的机器学习算法,包括有监督算法和无监督算法进行学习。有监督算法包括逻辑回归、线性回归、支持向量机、决策树算法等;无监督算法包括k‐means聚类等。
这些算法针对黑样本查全率进行改造,具体为:给黑样本损失函数赋以比白样本大的权重,使其更倾向于找出更多的黑样本;或者,对黑样本进行过采样,白样本进行欠采样;或者,在损失函数后增加正则项,降低模型复杂度,提高模型范化能力;或者,采用集成学习框架,克服单模型的过拟合。
针对资金损失率进行改造,对高金额样本赋以低金额大的权重,使模型更倾向于少分错高金额样本;或者,根据单笔交易金额动态调整概率阈值,使对高金额的交易更难被判别为白样本;
针对算法性能做优化,使用GPU加速算法中可以并行化执行的函数,大大降低训练和预测时间;或者,使用线性代数库实现算法底层的计算操作;或者,使用多线程技术并行化实现算法。
经过调整参数,获取符合准确率、召回率等指标要求的模型,并使用测试集对模型进行评估,观察模型是否可以泛化至其它数据集。训练过程中的信息反馈给管理平台。最终训练完毕的模型写入文件进行永久保存。对于合适的模型将进行生产环境部署,使真实交易数据流过整个系统并对可能的风险进行实时拦截。与此同时,模型训练模块还可以通过预先设置的更新时间,自动获取最新数据并重新训练合适的模型,从而使模型始终保持有效性。
预测引擎和决策引擎在模型实际部署后发挥作用,实际交易数据以条为单位依次流过ETL模块,采样引擎,流处理引擎并进行上述训练过程中相同操作后,得到处理好的交易数据直接输入预测引擎,预测引擎调用训练好的模型对这条数据进行判别,输出属于正常交易的概率和属于欺诈交易的概率,将预测结果传给决策引擎。决策引擎根据预测引擎的输出,对当笔交易进行实时决策。
本发明的设计重点在于:通过管理平台提供整体GUI界面和管理配置信息,通过ETL模块对数据进行快速的转换、入库,使用采样模块获取大规模原始数据集,通过流式大数据处理对庞大的交易原始数据进行特征的快速提取和计算,从海量原始数据中得到有代表性的特征。机器学习算法均经过多种针对资金损失率、黑样本查全率优化,通过设置合理的算法参数,训练出优秀的模型,并对此模型进行多个数据集的评估。通过以上设计,该系统可以实时对交易进行较为准确的决策。
以上所述,仅是本发明的较佳实施例而已,并非对本发明的技术范围作任何限制,故凡是依据本发明的技术实质对以上实施例所作的任何细微修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!