一种基于优化手势库分布的DNN群手势识别方法与流程
本发明属于计算机领域,具体涉及一种基于优化手势库分布的DNN群手势识别方法。
背景技术:
裸手手势识别系统包括静态手势(指姿态、单个手形)识别和动态手势(指动作,由一系列姿态组成)识别,它为使用者提供了更加自然、直接的人机交互方式,已逐渐成为计算机视觉及人机交互领域的一个研究热点.学者提出Tortoise模型表征人手部基本特征,并据此训练自学习手势模式库,结合遗传算法中优胜劣汰的规则,在几何与纹理混合特征空间实现目标手形与模式库中手形匹配、识别手势,提高了实时性,但其只选用了10种区分度较大的手势进行实验;研究者又提取手势边缘特征像素点,利用Hausdorff距离模板匹配的思想实现中国手语字母识别,计算量小、适应性强,但未考虑手势旋转、缩放、肤色干扰时的手势识别;还有的研究者利用手势的形状特征进行手势识别,由于采用轮廓特征,该算法无法识别外形非常接近的手势;还有的研究利用图像的密度分布特征(density distribution feature,DDF)实现二值图像的检索识别,但无法识别区分度较小的手势。
技术实现要素:
本发明的目的在于解决上述现有技术中存在的难题,提供一种基于优化手势库分布的DNN群手势识别方法,确保手势识别率最高。
本发明是通过以下技术方案实现的:
一种基于优化手势库分布的DNN群手势识别方法,所述方法包括:
(1)采集手势,形成手势数据集;
(2)利用优化手势库分布把所述手势数据集重新分类成多个子数据库;
(3)在每个子数据库上,对DNN模型进行学习训练,得到DNN结构;
(4)输入待识别手势。用Kinect设备采集待识别手势,利用减背景方法芳实现手势分割,把人手从背景中分离出来;
(5)把待识别手势分别送往每个DNN结构进行识别,并用下式计算各个DNN识别结果的输出误差E:
E=希望输出-网络响应;
(6)返回输出误差E最小者所对应的输出结果,即为识别出的手势。
所述步骤(1)是这样实现的:
用Kinect设备采集M个手势,每个手势包括不同大小、不同方位的手势图像;
对每个手势图像利用减背景方法进行手势分割,将人手从背景中分离出来,所有这些图像构成手势数据集Big_DataSet。
所述步骤(2)是这样实现的:
(21)输入手势数据集Big_DataSet,利用Big_DataSet数据对DNN结构进行训练,把Big_DataSet分为M个类;初始化:Ψ和Ω表示手势集的集合,表示空集;
(22)计算手势距离矩阵D:在DNN结构的最后一层特征层中手势类型i的特征向量为FM(i)=(fmi,1,fmi,2,…,fmi,s),手势i与手势j之间的距离定义为:
其中,di,j表示两个手势之间的相似度距离,fmi,j在FM中定义FM(i)=(fmi,1,fmi,2,…,fmi,s);
手势距离矩阵定义为D={di,j}N×N;
(23)把矩阵D中的矩阵元素最大值所对应的手势(i,j)及其距离值保存到集合Ω中,并把与手势i和j有关信息从D中删除:
(24)转步骤(23),直到对所有i,j都满足di,j=0为止;
(25)计算Ω中各元素之间的最小距离矩阵H:
hi,j=Hausdorff(F(Ωi),F(Ωj)) (3)
其中,F(Ωi)表示Ω中元素Ωi所有手势所对应的向量FM所组成的集合,每个手势对应一个向量,Hausdorff(·,·)表示两个集合之间的Hausdorff距离;
最小距离矩阵H定义为H={hi,j}U×V;
(26)对最小距离矩阵H中最大值所对应的元素求并集,然后把并集结果放到集合Ψ中;
(27)转步骤(26),直到对所有i,j都满足hi,j=0为止;
(28)把集合Ψ的内容赋给集合Ω,即Ω的内容被Ψ的内容取而代之,然后转步骤(24),直到对所有i,j都满足为止,此时,Ω把所有手势分为不同集合,与这些集合相对应,Big_DataSet中的所有手势被分到不同的子集中,每个子集就是一个所述的子数据库Mix_DataSet(r);其中,表示:Ω中任意两个元素之间的距离都小于某一个经验阈值;
(29),返回子数据库Mix_DataSet(r)。
所述步骤(21)中的利用Big_DataSet数据对DNN结构进行训练,把Big_DataSet分为M个类是这样实现的:
计算:
{Mix_DataSet(k)|k=1,2,...M},
满足
所述步骤(5)是这样实现的:
在DNN结构的软最大层中,用BP神经网络进行识别,一旦BP结构训练完成,对每个输入手势,能够得到由公式E=希望输出-网络响应所定义的输出误差E。
与现有技术相比,本发明的有益效果是:
从本质上讲,本发明通过反复训练数据库的分布,使得不同子集之间的类间距最大,类内距离最小,这样就从机理上确保手势识别率最高。本发明以手势为基本单位分布手势集,同一个手势的不同图片(这些图像显然非常相似)不会被分拆放到不同的子库中,同一类手势可能放到不同的子库中,识别混淆(即识别错误)的手势会放到不同的子库中。
附图说明
图1 手势数据库的优化分布方案。
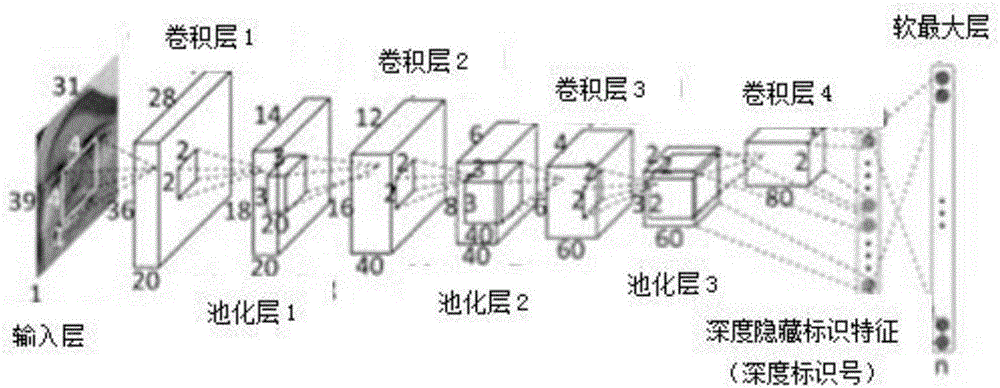
图2 DNN结构图。
图3 手势识别算法。
具体实施方式
下面结合附图对本发明作进一步详细描述:
深度学习神经网络能够非常有效地从大量有标签数据中深度提取数据的特征信息,充分挖掘数据的内在属性和有价值的表征数据。传统算法无法直接有效地从图像中提取出对目标有用的信息。而深度学习的学习能力却异常强大,即使是复杂低分辨率图像也能够很好的提取出目标深度特征。基于卷积神经网络DNN(即深度学习神经网络)的手势识别所需的图像背景并不需要固定,算法甚至在一定范围内允许运动背景的存在,从而提高了识别的环境耐受力和精细度。
手部有非常多的关节,需要非常强的识别能力才可以准确的识别每个精细动作,而深度学习模型的多隐藏层结构使得模型能有效利用海量数据进行训练,所使用数据越多模型性能越高。
在同一个手势库中,如果手势类型比较多,无论是基于传统特征检测的手势识别方法还是基于DNN机器学习算法,识别率的提高都极具挑战性。主要原因是:(1)存在大量相似性手势;(2)手势本身具有柔性,使得即使是同一个手势往往也会有差别比较大的图像特征;(3)受光线的影响,手势图像本身噪声干扰往往比较大,使得手势图像的分割误差比较大。这些原因导致手势识别率的提高极具挑战性,尤其是在手势类型多的条件下。为了解决这些问题,将庞大的手势库分布在不同的子库中,将区别特征大的手势放在同一个子库中,将区别特征小的手势放在同不同的子库中。通过反复训练每个深度神经网络,使得每个DNN对于相应子库的识别率达到最高。
以类内和类间识别率最高为目标,提出手势数据库优化分布方法。该方法的主要任务是把手势数据集Big_DataSet分布到不同的混合子数据库Mix_DataSet集合中,即将M个手势类分布到N个集合中,进而在每个子集上训练DNN模型,使得在每个子集上的手势识别率达到最高。
本发明方法如图3所示,包括:
(1)形成大型手势数据库。用Kinect设备采集M个手势,每个手势包括不同大小、不同方位的手势图片;每个手势图像利用减背景技术实现手势分割,把人手从复杂背景中分离出来,所有这些图像就构成Big_DataSet;
(2)用手势数据库的优化分布算法把大型手势数据库重新分类子数据库;
(3)在每个子数据库上,对DNN模型进行学习训练,得到DNN结构,如图2所示;
(4)输入待识别手势。用Kinect设备采集待识别手势,利用减背景技术实现手势分割,把人手从复杂背景中分离出来;
(5)把待识别手势分别送往每个DNN结构进行识别,并计算各个DNN识别结果的输出误差:
E=希望输出-网络响应 (5)
(6)返回输出误差E最小者所对应的输出结果。
在DNN结构的“软最大层”中,用公知的BP(误差逆传播网络)神经网络进行识别。一旦BP结构训练完成,对每个输入手势,总可以得到由式子(5)所定义的输出误差。
手势数据库的优化分布算法如图1所示,包括:
输入:
(a)M个手势类构成的手势数据集Big_DataSet;
(b)在Big_DataSet上训练出的DNN模型:采用图3所示的DNN结构,利用Big_DataSet数据对DNN结构进行训练,把Big_DataSet分为M个类:
计算
{Mix_DataSet(k)|k=1,2,...M},
满足
(1)初始化:Ψ和Ω表示手势集的集合,表示空集。
(2)计算手势距离矩阵D:
在所有M个手势组成的大数据集Big_DataSet上训练DNN模型,该模型最后一层特征层(Feature Map)(该特征层是DNN模型中最后一个池化层)中手势类型i的特征向量为FM(i)=(fmi,1,fmi,2,…,fmi,s)(DNN模型中最后一个池化层实际上是一个图像,把该图像按照从上到下、从左到右的顺序把各个像素值组装为一个一维向量,就是FM),手势i与手势j之间的距离定义为:
其中,di,j表示两个手势之间的相似度距离,fmi,j在FM中定义FM(i)=(fmi,1,fmi,2,…,fmi,s))
手势距离矩阵定义为D={di,j}N×N。
(3)把矩阵D中矩阵元素最大值的值(矩阵D中共有N2个元素,求找其最大元素的方法是公知方法)对应的手势(i,j)及其距离值保存到集合Ω中,并把与手势i和j有关信息从D中删除:
其中,表示矩阵D中的最大值大于一个经验值,设置经验阈值的主要目的是确保不同手势之间有足够的区分度;di,j表示两个手势之间的“距离”,该距离越大,则两个手势之间的区分度就越大。Ω是一个集合,其元素是由手势编号组成的集合。{i,j}表示手势i和手势j所组成的集合;
(4)转步骤(3),直到对所有i,j都满足di,j=0为止;(反复步骤3和4,直到所有手势都被放到Ω中为止。)
(5)计算Ω中各元素之间的最小距离矩阵H:
hi,j=Hausdorff(F(Ωi),F(Ωj)) (3)
其中,F(Ωi)表示Ω中元素Ωi所有手势所对应的向量FM所组成的集合,每个手势对应一个向量,Hausdorff(·,·)表示两个集合之间的Hausdorff距离。最小距离矩阵H定义为H={hi,j}U×V。
(6)把最小距离矩阵H中最大值所对应的元素求并集(元素求并集,把并集结果放到集合Ψ中):
(7)转步骤(6),直到对所有i,j都满足hi,j=0为止。
(8)Ω←Ψ(此公式表示把集合Ψ的内容赋给集合Ω,即Ω的内容被Ψ的内容取而代之,为下一轮循环做好准备),转步骤(4),直到对所有i,j都满足(此公式表示:如果Ω中任意两个元素之间的距离都小于某一个经验阈值,对Ω的反复合并过程就结束)为止。
(9)返回Mix_DataSet(r)
在步骤8结束循环而最后得到的Ω中,每个元素是一个集合,每个集合是一个不同手势编号集合,把该集合中在Big_DataSet中的手势组成一个集合,就是Mix_DataSet,r是手势集合序号。也就是说,Big_DataSet中的所有手势图像根据Ω中的结果被分布到不同的集合中了。这也是手势数据库优化分布的内涵。
上述技术方案只是本发明的一种实施方式,对于本领域内的技术人员而言,在本发明公开了应用方法和原理的基础上,很容易做出各种类型的改进或变形,而不仅限于本发明上述具体实施方式所描述的方法,因此前面描述的方式只是优选的,而并不具有限制性的意义。
- 还没有人留言评论。精彩留言会获得点赞!