一种基于CUDA的双目深度信息恢复加速方法与流程
本发明属于计算机视觉领域,涉及双目深度信息恢复的加速方法。
背景技术:
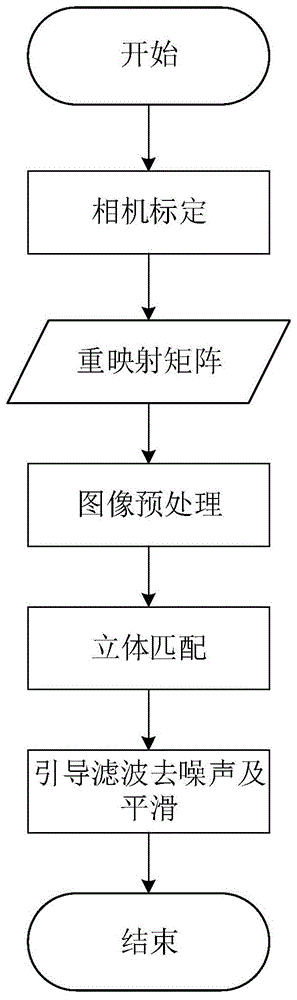
:在计算机视觉领域,立体视觉的深度信息恢复一直是一个重要的问题。近来,由于大量专家对人工智能的研究,立体视觉的深度信息恢复更是成为热点。深度信息恢复包括基于单目的深度信息恢复、基于双目的深度信息恢复和基于多目的深度信息恢复。基于单目的算法必须借助额外的信息才能完成,基于双目的深度信息恢复模仿人类双眼的结构,基于多目的算法增加了更多的信息来估计。目前存在的深度相机是根据光的反射时间和反射光的接受时间的时间差,通过采用雷达测量的原理进行三维场景深度的测量。然而目前算法速度上还是一个问题,CUDA(ComputeUnifiedDeviceArchitecture,统一计算架构)可以用来最大并行化计算,提高计算效率,用来辅助进行科学计算,在图像处理领域广泛应用。目前基于双目深度信息恢复方法即给定两幅二维图像,通过三角测量计算图像像素的视差,得到三维信息。基于双目深度信息恢复方法的步骤包含相机标定、图像预处理、立体匹配和深度插值滤波等部分。由于相机标定是离线部分,所以不对这部分进行加速,对于图像预处理、立体匹配和深度插值方面进行加速。技术实现要素:本发明要克服现有技术的上述缺点,针对基于立体视觉深度信息恢复问题,提供一种加速双目深度信息恢复的方法。在保证准确的深度信息恢复情况下,加速深度信息恢复的效率,进而达到实时性。本发明的一种基于CUDA的双目深度信息恢复加速方法,包括以下步骤:1)在图像预处理阶段,通过并行计算加速;2)在立体匹配阶段,通过并行设计和内存访问设计加速;3)并行计算滤波过程对图像边缘进行平滑操作;所述的图像预处理对输入图像进行校正处理,校正包含去除透镜带来的畸变效应和去除两个相机相对位置不理想带来的极线对不准问题。便于后序步骤的计算。首先,将输入图像进行resize操作,得到分辨率为320×240。然后将RGB图像转换为灰度图像,为了匹配的可靠性,根据人眼对色彩感知程度转换,转换公式如下:Grayscale=0.299×Red+0.587×Green+0.114×Blue然后将两个原始图像和四个重映射矩阵映射到输出图像上。为了解决原始图像中的多个点映射到同一个点在输出图像上的点问题。我们采用反向查询的方法解决。对于输出图像中的每个像素,根据重映射矩阵查询其在原始图像中的坐标。对于映射到图像外部点的问题,通过设置位于图像外的像素点,对其填充0。在该部分,我们通过并行化计算加速效率,每一个GPUThread用来处理图像中的一个像素,最大化并行化,有效提高速率。所述的立体匹配及其优化算法。在该部分我们采用窗口匹配的方法来寻找左右视图中的对应点。输入包括windowSize,numberOfDisparities,rows和cols。其中windowSize是匹配窗口的大小,numberOfDisparities是最大视差级数,rows和cols是图像的高度和宽度。输出是一个矩阵M,大小与输入图像一样。默认最小视差是0并设定一个阈值,当两个点计算出来的值小于该阈值时,认为其是匹配点。在后序的加速方面,设定并行单位是输出图像的像素点,每个GPUThread对一个像素进行并行处理。每个像素的视差范围在[0,numberOfDisparities]中。所述的利用滤波对图像边缘进行平滑是深度恢复以后,输出图像的边缘会出现锐利的情况,我们利用引导滤波减少噪音和平滑边缘。同样设定每个GPUThread负责处理输出图像中的单个像素以及该像素为中心的半径为γ的窗口内的线性滤波计算。本发明的优点是:通过对立体匹配进行并行计算和内存访问机制的设计,实现了快速的双目深度信息恢复方法。附图说明图1是本发明的基于双目深度信息恢复流程图。图2是本发明的并行归约示意图。图3是本发明的深度信息恢复的结果示意图。具体实施方式下面结合本发明中的附图,对本发明的技术方案进行清晰、完整地描述。基于本发明的实施例,本领域普通技术人员在没有做创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明提供了一种加速双目深度信息恢复的方法,图1展示了该方法的流程图。该方法具体实施步骤如下:步骤1,使用标定棋盘对相机进行标定,调整棋盘以不同的角度和位置出现在两个相机内,同时保持出现在左右视图中的指示方向的斜线一致。为了提高准确率总共录入10个姿态的样例,通过棋盘上显著特征点进行匹配。输入图像resize成分辨率为320×240;然后将resize之后的图像转换成灰度图像;利用重映射矩阵计算去畸变和极线校正的图像。步骤2,通过左右视图的立体匹配找到左右视差,即深度恢复的结果。该部分在计算时,需要对每个像素的视差均进行计算。该优化方法包含两步,预计算匹配代价和根据预计算匹配代价寻找最小匹配代价的视差。在计算时,先把每个像素的每种视差的匹配代价存储在一块单独的内存中,该快内存大小为rows×cols×numbeOfDisparities×sizeof(uchar),其中每个元素的值通过以下公式计算:Data(disp,r,c)=IL(r,c)-IR(r-disp,c)通过这种方式,我们把复杂度从O(rows×cols×numberOfDisparities×windowArea)降低到了O(rows×cols×numberOfDisparities)。在预计算匹配代价中,我们选择每个像素的每种视差作为最小并行单位,每个Block尽可能填充更多的Thread。然后通过归约算法寻找所有匹配代价中的最小值如图2。在该步骤设置立体匹配的窗口大小为5×5,最大视差为32。下面给出增加了预计算之后我们方法与以往方法消耗时间对比表。预处理预计算匹配滤波合计原始方法(ms)46.6352.227.8426.6我们方法(ms)3.687344.99141314.1104983.75908723.229732步骤3,原始的深度图中存在很多的噪声,并且会存在误匹配带来的亮斑和黑块,我们利用引导滤波来去除这些噪声,滤波对于偏差较小的匹配有一定的纠错能力。在该方法中我们设置引导滤波的参数(γ,∈)=(2,(255×0.01)2)。图3左图为左相机视图,右图为视差分布图。最后,以上所述仅为本发明较有代表性的实施例。本领域的普通技术人员可在不脱离本发明的发明思想情况下,对上述实施例做出种种修改或变化,因而本发明的保护范围并不被上述实施例所限,而应该是符合权利要求数提到的创新性特征的最大范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1