一种基于词典与文法分析的多语种分词方法与流程
本发明属于自然语言处理领域,具体涉及一种通过unicode(统一码、万国码、单一码)编码判别的基于词典与文法分析的多语种分词方法。
背景技术:
随着信息时代的到来,可供人查阅和检索的信息越来越多,搜索市场价值的不断增加,越来越多的企业正在寻找一种更强大的自然语言处理工具,诸如自动摘要、自动文本检索、自动文本分类等语言处理等工具,而自动分词技术就是这些工具的核心技术之一。分词,顾名思义,就是借助计算机自动给文本分词,使其在不丢失信息的情况下能够正确的表达所要表达的意思。只要是与语言理解相关的领域,都是需要用到分词技术的。因此对于多语言分词技术的研究,对于计算机的发展有着至关重要的作用。
各国语言语法、书写习惯的不同,决定了它们不同的分词方法,因此很难将各国语言用一种通用的分词方法来完成分词工作。对于现有的分词器,大多数只能支持单一语言(中文、英文),极少数的分词器能够支持多语言分词,但是也仅限于中、英、日、韩语种,而且分词的准确率也不是很高。对于西方屈折语的文本书写习惯把单词与单词之间用一个空格分开,所以可以依靠空格或标点符号来分解整篇文章,然而维文与英文却是用不同空格来切分单词,类似的,对于不同种语法,可能会有不同种标点符号作为词的分隔符,为此,本发明采用unicode编码识别各分隔符的编码,依此完成分解屈折语的功能;对于那些孤立语和黏着语(如汉语、日语、越南语、藏语等)的文本,词与词之间没有任何空格之类的显著标志指示词的边界,如果以字为单位来切分文本,处理起来比较容易,但是带来的空间消耗是非常大的,更重要的是一个字根本无法准确的表述一个意思,这样就会导致分词结果与用户原本意图不相符的问题。
技术实现要素:
本发明提供了一个基于词典与文法分析的多语种分词方法和系统,克服了只能对单一语种或个别语种进行分词的局限,采用基于词典匹配与文法分析相结合的分词技术实现对不同种语言进行分词的目的,确保能够高效的将文本分解成具有代表意义的词,对于一些用户会有这样的需求,就是要准确的将文本内容分解,即将一些存在歧义的词能够进行消岐处理,为此,本发明采用文法分析的方法对词典匹配出的那些具有歧义的词进行消岐意分析处理,另外待分词文本中还可能会出现一些乱码、或者是一些代表意义不大的停用词,本发明会将其过滤,保证文本的可读性、高效搜索性,同时还降低文本所需的存储空间。
根据本发明的第一方面,采用了一种新的分词框架体系。本发明提出的新的分词体系通过内嵌中日韩粤等语系子分词器、中文量子分词器和西方语系分词器,可以实现每类语种文本判断的准确分词;通过内置的语言片段编码识别机制字段对待分词文本片段进行切分,切分后的每种文本片段对应于一种语系,并使用相应的子分词器进行分词;含有扩展词典配置管理单元,用于实现中、日、韩、粤语等扩展词典以及各语种的停用词词典的管理;还含有分词器管理单元,主要包含字母处理、数字处理、中、日、韩语处理,通过识别个语种类型,然后分别进入不同的子分词器,对其进行分词处理;另外,还设有词典配置管理模块,该部分包含词典的加载管理、词典检索算法单元以及词典文件的处理,本发明中只含有一个词典,词典中设有主词典、停用词词典,在词典匹配的过程中通过单例实现词典的配置。加载词典过程中采用哈希算法,这样避免的词典中含有重复词的问题。可以看出,采用框架体系支持多语种分词,能够实现同时对多种语种混合的文件进行分词,并具有高效性、可扩展性。
根据本发明的第二方面,采用基于编码来识别文本中标点、空格等语言分隔符解决西方屈折语的分词问题。对于西方屈折语的文本书写习惯是以空格来把单词一个一个的分开,因此采用unicode编码来确定不同标点符号及空格的编码区间,构造分隔符集合。为了更好的解释屈折语的分词过程,我们以“Hello word!”为例。首先,将待分词文本以流的形式存入缓冲区;然后,启动字符与阿拉伯数字处理的分词器,使得该分词器接收“Hello word!”字符流,用指针扫描字符,并记录词首“H”的指针位置begin,移动指针,继续扫描下一字符,直到遇到分隔符,记录当前指针的位置end,这样就能够能得到“Hello”这个词的起始位置begin、以及词的长度end-begin,依此继续扫描,直至将缓存区中所有的词的起始位置与词长都识别出来即可;最后得到所有的词元信息(词的起始位置、词长、词所属类型)。然后缓存下一批字符,来完成分词功能,至此,完成了将屈折语文本分词的过程,并将分词结果存入词段队列。可以看出,采用unicode编码能够准确的识别不同语种词之间分割标点,高效的完成屈折语单文本、屈折语混合文本的分词功能。
根据本发明的第三方面,采用基于词典的方法解决词与词之间没有任何空格之类的显著标志指示词的边界的语言分词问题。对于诸如中文、日文、韩文等语种的文本,只是字、句、段能通过明显的分解符来简单划划界,唯独词之间没有一个形式上的分解符,因此分词比西方屈折语要困难的多。本发明采用基于词典匹配的方法对其进行分词,词典包括内部词典以及外部扩展词典。词典的存储采用了前缀树数据结构,对应的数据结构除了根节点,任意一个子节点都包含两个数据项:nodeChar表示该节点对应的字符,nodeState表示从根节点到本节点是否是一个完整的词。为了能够更好的描述分词方法,以“这是一个多语种分词工具”为例。首先,将待分词文本以流的形式读入缓冲区;然后,启动处理中、日、韩语的分词器,使得该分词器接收“这是一个多语种分词工具”字符流,将其与词典中的词进行匹配,得到所有与词典匹配的词“这是”,“一个”,“多语种”,“多语”,“语种”,“分词”,“工具”的词元信息(字符起始位置、词长、词所属类型)存储到词段队列,对于未匹配的词,则以单字词的形式输出。另外,本发明还可内置及扩展停用词词典,用来过滤掉一些保留意义不大的词,如常用词“的”,“是”,“了”。可以看出,本发明的词典扩展性可以提高文本分词的灵活性,采用词典匹配方法能够准确的将文本中的词分解出来。
根据本发明的第四方面,本发明有两种分词模式,一种为smart模式,一种为非smart模式。例如:“结婚的和尚未结婚”这个词条,就会存在一个词段队列,分别为“结婚”,“的”,“和尚”,“尚未”,“未结”“结婚”,若采用非smart分词,则输出词段队列中的所有词,若采用smart,则需要采用文法分析方法解决词语歧义的问题,具体方法如下:
1、词典匹配得到词段队列:
其中,begin是每一词元的起始位置;end是start+词段队列的长度;词段路径是end-start。
2、找出歧义即词元路径有交叉的部分:
3、选出词段队列的候选集,即所有可能的组合:
4、根据词法分析,进行优先级判断排序,选出最佳分词队列,其中优先级由高到低排列顺序如下所示:
a、有效文本长度,越长越好。如“中华人民共和国”优于“共和国”
b、词元个数越少越好,单字词除外
c、词段路径跨度越大越好
d、词段队列的起始位置越靠后越好,原因是根据统计学结论,词元匹配逆向切分的正确率大于正向切分的正确率
e、词长越平均越好
f、词元位置权重越大越好
权重:其中pi是每一词元在词段队列中的序号,li是对应词元的词长。
根据本发明的第五方面,采用unicode编码方法解决文本间存在乱码的问题。有些待分词文本中含有乱码信息,这些乱码不仅没有实际的意义,而且还会占用文本的存储空间,因此在对文本分词过程中通过对unicode编码判断的控制,会过滤掉乱码信息,大大节省了文本的存储空间。
根据本发明的第六方面,采用文法分词解决在文本中存在着阿拉伯数字这样的信息,这类信息内部可能含有“,”,“。”,“—”等连接符号,按照西方屈折语的分词方法,会将连接符号作为词与词之间的分割符,从而将“21.54”分解成“21”,“54”,这样会影响分词的准确性,针对这种情况,采用特殊的处理方法,通过判断连接符的前一字符与后一字符的字符类型,判断词元的组合情况,达到分词的目的。
本发明采用词典匹配的方法,将待分词文本与词典进行匹配,这样不仅能够准确的将文本分解,还节省的文本所占用的存储空间。
本发明提出的词典与词法分析的方法对多语种语言进行分词,采用一种新的分词框架体系,通过词典匹配方法,可以实现中、日、韩、粤语的等文本高效准确的处理,并且对于不同时段、不同专业的词可以实现灵活词库扩展,有效更新词库信息,实现准确、高效的多语种语言文本分词;通过文法分析可以实现西方屈折语的分词、中、日、韩、粤语的smart模式分词,可以处理含有阿拉伯数字信息的文本;同时,本发明还可以实现多种语言混合的文本分词,脱离了分词工具只能对单一语种、个别几个语种分词的局限性,保证文本分词的安全性、准确性、高效性、灵活性。通过本发明的提出的多语言分词,在增强海量数据文本分类、文本信息提取、自动摘要等文本分词领域具有广泛的应用前景。
附图说明
图1为本发明结构设计图;
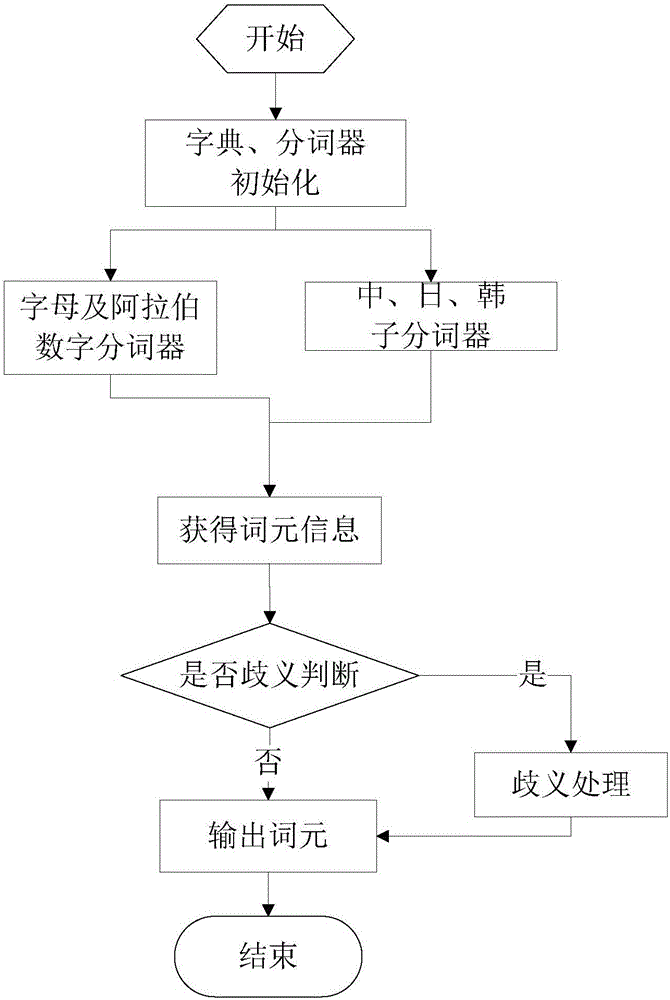
图2为本发明对多语种文本处理流程图;
图3为本发明前缀树数据结构的词典树;
图4为本发明基于词典匹配的词元获取流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明的技术方案进行详细说明。
如图1所示,根据本发明的第一方面,采用了一种新的分词框架体系。本发明提出的新的分词体系通过内嵌中日韩粤等语系子分词器、中文量子分词器和西方语系分词器,可以实现每类语种文本判断的准确分词;通过内置的语言片段编码识别机制字段对待分词文本片段进行切分,切分后的每种文本片段对应于一种语系,并使用相应的子分词器进行分词;其中含有扩展词典配置管理单元,用于实现中、日、韩、粤语等扩展词典以及各语种的停用词词典的管理;还含有分词器管理单元,主要包含字母处理、数字处理、中、日、韩语处理,通过识别各语种类型,然后分别进入不同的子分词器,对其进行分词处理;另外,还设有词典配置管理模块,该部分包含词典的加载管理、词典检索算法单元以及词典文件的处理,本发明中只含有一个词典,词典中设有主词典、停用词词典,在词典匹配的过程中通过单例实现词典的配置。加载词典过程中采用哈希算法,这样避免的词典中含有重复词的问题。可以看出,采用框架体系支持多语种分词,能够实现同时对多种语种混合的文件进行分词,并具有高效性、可扩展性。
根据本发明的第二方面,采用基于编码来识别文本中标点、空格等语言分隔符解决西方屈折语的分词问题。对于西方屈折语的文本书写习惯是以空格来把单词一个一个的分开,因此采用unicode编码来确定不同标点符号及空格的编码区间,构造分隔符集合。为了更好的解释屈折语的分词过程,我们以“Hello word!”为例。首先,将待分词文本以流的形式存入缓冲区;然后,启动字符与阿拉伯数字处理的分词器,使得该分词器接收“Hello word!”字符流,用指针扫描字符,并记录词首“H”的指针位置begin,移动指针,继续扫描下一字符,直到遇到分隔符,记录当前指针的位置end,这样就能够能得到“Hello”这个词的起始位置begin、以及词的长度end-begin,依此继续扫描,直至将缓存区中所有的词的起始位置与词长都识别出来即可;最后得到所有的词元信息(词的起始位置、词长、词所属类型)。然后缓存下一批字符,来完成分词功能,至此,完成了将屈折语文本分词的过程,并将分词结果存入词段队列。可以看出,采用unicode编码能够准确的识别不同语种词之间分割标点,高效的完成屈折语单文本、屈折语混合文本的分词功能。
如图2所示,根据本发明的第三方面,采用基于词典的方法解决词与词之间没有任何空格之类的显著标志指示词的边界的语言分词问题。对于诸如中文、日文、韩文等语种的文本,只是字、句、段能通过明显的分解符来简单划划界,唯独词之间没有一个形式上的分解符,因此分词比西方屈折语要困难的多。本发明采用基于词典匹配的方法对其进行分词,词典包括内部词典以及外部扩展词典。如图3所示,词典的存储采用了前缀树数据结构,对应的数据结构除了根节点,任意一个子节点都包含两个数据项:nodeChar表示该节点对应的字符,nodeState表示从根节点到本节点是否是一个完整的词。为了能够更好的描述分词方法,以“这是一个多语种分词工具”为例。首先,将待分词文本以流的形式读入缓冲区;然后,启动处理中、日、韩语的分词器,使得该分词器接收“这是一个多语种分词工具”字符流,将其与词典中的词进行匹配,得到所有与词典匹配的词“这是”,“一个”,“多语种”,“多语”,“语种”,“分词”,“工具”的词元信息(字符起始位置、词长、词所属类型)存储到词段队列,对于未匹配的词,则以单字词的形式输出。另外,本发明还可内置及扩展停用词词典,用来过滤掉一些保留意义不大的词,如常用词“的”,“是”,“了”。可以看出,本发明的词典扩展性可以提高文本分词的灵活性,采用词典匹配方法能够准确的将文本中的词分解出来。
如图4所示,根据本发明的第四方面,本发明有两种分词模式,一种为smart模式,一种为非smart模式。例如:“结婚的和尚未结婚”这个词条,就会存在一个词段队列,分别为“结婚”,“的”,“和尚”,“尚未”,“未结”“结婚”,若采用非smart分词,则输出词段队列中的所有词,若采用smart,则需要采用文法分析方法解决词语歧义的问题,具体方法如下:
1、词典匹配得到词段队列:
其中,begin是每一词元的起始位置;end是start+词段队列的长度;词段路径是end-start。
2、找出歧义即词元路径有交叉的部分:
3、选出词段队列的候选集,即所有可能的组合:
4、根据词法分析,进行优先级判断排序,选出最佳分词队列,其中优先级由高到低排列顺序如下所示:
b、有效文本长度,越长越好。如“中华人民共和国”优于“共和国”
b、词元个数越少越好,单字词除外
c、词段路径跨度越大越好
d、词段队列的起始位置越靠后越好,原因是根据统计学结论,词元匹配逆向切分的
正确率大于正向切分的正确率
e、词长越平均越好
f、词元位置权重越大越好
权重:其中pi是每一词元在词段队列中的序号,li是对应词元的词长。
根据本发明的第五方面,采用unicode编码方法解决文本间存在乱码的问题。有些待分词文本中含有乱码信息,这些乱码不仅没有实际的意义,而且还会占用文本的存储空间,因此在对文本分词过程中通过对unicode编码判断的控制,会过滤掉乱码信息,大大节省了文本的存储空间。
根据本发明的第六方面,采用文法分词解决在文本中存在着阿拉伯数字这样的信息,这类信息内部可能含有“,”,“。”,“—”等连接符号,按照西方屈折语的分词方法,会将连接符号作为词与词之间的分割符,从而将“21.54”分解成“21”,“54”,这样会影响分词的准确性,针对这种情况,采用特殊的处理方法,通过判断连接符的前一字符与后一字符的字符类型,判断词元的组合情况,达到分词的目的。
本发明提供的基于词典与文法分析的多语言文本分词,首先配置扩展词典及其相应的配置文件,配置文件格式如下所示,其中,ext.dic是用户的扩展词典,可以同时扩展多个词典,词典之间以“;”符号间隔,stopword.dic是用户的扩展停用词词典,也可以同时扩展多个词典,词典之间同样以“;”符号间隔。扩展词典的路径可以是绝对路径亦或是相对路径,配置文件设置完成后,将配置文件路径(绝对或相对路径)作为参数传到分词器即可。
<?xml version="1.0"encoding="UTF-8"?>
<properties>
<dict type="ext_dict">
<!--用户可以在此处添加扩展词典-->
<ext_dict>ext.dic;ext1.dic</ext_dict>
</dict>
<dict type="ext_stopwords">
<!--用户可以在此处添加扩展停用词词典-->
<ext_stopwords>stopword.dic</ext_stopwords>
</dict>
</properties>
应该注意到并理解,在不脱离后附的权利要求所要求的本发明的精神和范围的情况下,能够对上述详细描述的本发明做出各种修改和改进。因此,要求保护的技术方案的范围不受所给出的任何特定示范教导的限制。
- 还没有人留言评论。精彩留言会获得点赞!