一种基于随机森林模型的人口数据空间化方法与流程
本发明涉及人口数据空间化的理论领域,更具体地,涉及一种基于随机森林模型的人口数据空间化方法;该方法可以应用于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策中所需的人口信息的精确快捷获取。
技术背景
作为生产力中最重要的因素,人口的集聚不仅会产生集聚效应,在降低人均生活成本的同时还能提高土地集约利用程度,但是如果人口的增长超过某一地区土地的负载能力,就会破坏环境和生态的良性循环,最后损害人类自身。而且随着人口密度的不断增加,城市在面临例如火灾、地震、台风、洪水等传统威胁的同时,也给城市管理带来了新的问题,如交通拥挤、公共设施承载量过大、城市部件大量增加等。这些问题与城市人口的分布都有着密切关系。
当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在以下三方面的不足:第一,时间分辨率低,全国人口普查每10年1次,数据更新周期长,难以准确揭示人口状况的。第二,空间分辨率低,以行政区为单元获得的人口数据在行政单元内是均匀分布的,不能体现人口数据的空间分布特征;第三,不利于多源数据融合和综合空间分析,以行政区为单元的统计数据与自然地理单元存在空间不匹配的问题,限制了人口统计数据在多学科领域的应用。所以非常有必要将人口数据网格化,利于实现人口数据与其它社会统计数据、资源数据、环境数据融合,提高人口、资源、环境综合管理能力。
随着科学技术的不断进步,特别是近年来地球信息科学的突飞猛进,遥感影像信息提取可以提供大量变量因子空间分布和变化的信息,遥感技术和GIS技术结合使用而进行人口数据空间化的方法发展迅速,取得了巨大成就,但还存在着精度较低、模型运行速度较慢、变量因子解释性差的不足。
随机森林模型指的是利用多棵树对样本进行训练并预测的一种分类器,该分类器可以输入大量变量,快速学习后输出高准确度的分类或回归结果,同时评估变量的重要性,不会产生过拟合的问题。随机森林以其上述优点非常适合用于人口数据的空间化,可快速学习变量因子与人口数据之间的关系并给出变量因子的重要性评价。
技术实现要素:
本发明所要解决的技术问题在于,提供一种快速且准确、能够大幅度提高人口数据空间化精度的基于随机森林模型的人口数据空间化方法。
为达到上述目的,本发明提供的基于随机森林模型的人口数据空间化方法,包括以下步骤:
(1)获取行政区的常住人口数、灯光数据以及其它对人口分布具有影响的自然和社会经济因素的原始数据,对数据进行预处理,得到变量因子距离数据、灯光数据、行政区人口密度的对数和二值化栅格转换后的变量因子数据;
(2)统计各个行政区内的每个变量因子的平均值或最常出现的值并匹配到行政区边界;
(3)将步骤(1)预处理后得到的变量因子距离数据、灯光数据和行政区人口密度的对数、二值化变量因子栅格数据、步骤(2)得到的变量因子的平均值或最常出现值作为随机森林模型的输入,来寻找变量因子与人口密度的对数之间的关系并输出变量因子重要性,基于这个关系反演出L×L米网格的人口数,得到人口数据空间化的初步结果;
(4)利用分区密度制图修正人口数据空间化的初步结果,最终实现基于随机森林模型的L米网格的人口数据空间化。
所述的步骤(1)中的预处理进一步包括:
步骤S11,将所有空间数据转换成统一投影坐标系以及参考椭球体。
步骤S12,将行政区的常住人口数除以行政区面积得到行政区的人口密度,并对人口密度取对数;
步骤S13,对灯光数据进行双线性的重采样成L×L米的栅格;
步骤S14,对建成区、河流、水体、道路等其它对人口分布具有影响的自然和社会经济变量因子进行欧氏距离计算。
步骤S15,对其它矢量格式的对人口分布具有影响的自然和社会经济变量因子进行二值化栅格转换。
所述的步骤(1)中步骤S15的二值化栅格转换是将矢量格式的变量因子转换成栅格格式,并和行政区范围进行合并,0表示变量因子为空,1表示变量因子不为空。
上述的一种基于随机森林模型的L米网格的人口分布的估算方法,其特征在于:所述的步骤(2)中的统计各个行政区内的每个变量因子的平均值或最常出现的值具体是指对于变量因子的距离数据及其他连续变量因子进行平均值的统计,对于二值化的变量因子栅格数据进行最常出现值的统计。
上述的一种基于随机森林模型的L米网格的人口分布的估算方法,其特征在于:所述的步骤(4)中的分区密度制图法是按照随机森林得到的每个网格的人口占一个行政区的所有网格的总人口的比例重新分配每个网格的人口数,计算公式如下:
Pi=Sj×Di/Dj
式中,Pi为每个网格内的人口数,Sj为该网格所在的行政区的人口总数,Di为该网格根据随机森林模型估计得到的人口数,Dj为该网格所在的行政区的所有网格的根据随机森林模型估计得到的人口总数。
与现有技术相比,本发明克服了传统方法对人口数据空间化建模精度低、模型运行速度慢、变量因子解释性差的缺点,利用地表覆盖数据以及灯光数据作为人口分布的变量因子,运用随机森林模型建立人口密度与变量因子之间的关系,并利用生成的随机森林树对每个L×L米栅格的人口密度进行估算,最后通过分区密度制图修正模型结果成功实现L×L米网格的人口分布估算。
附图说明
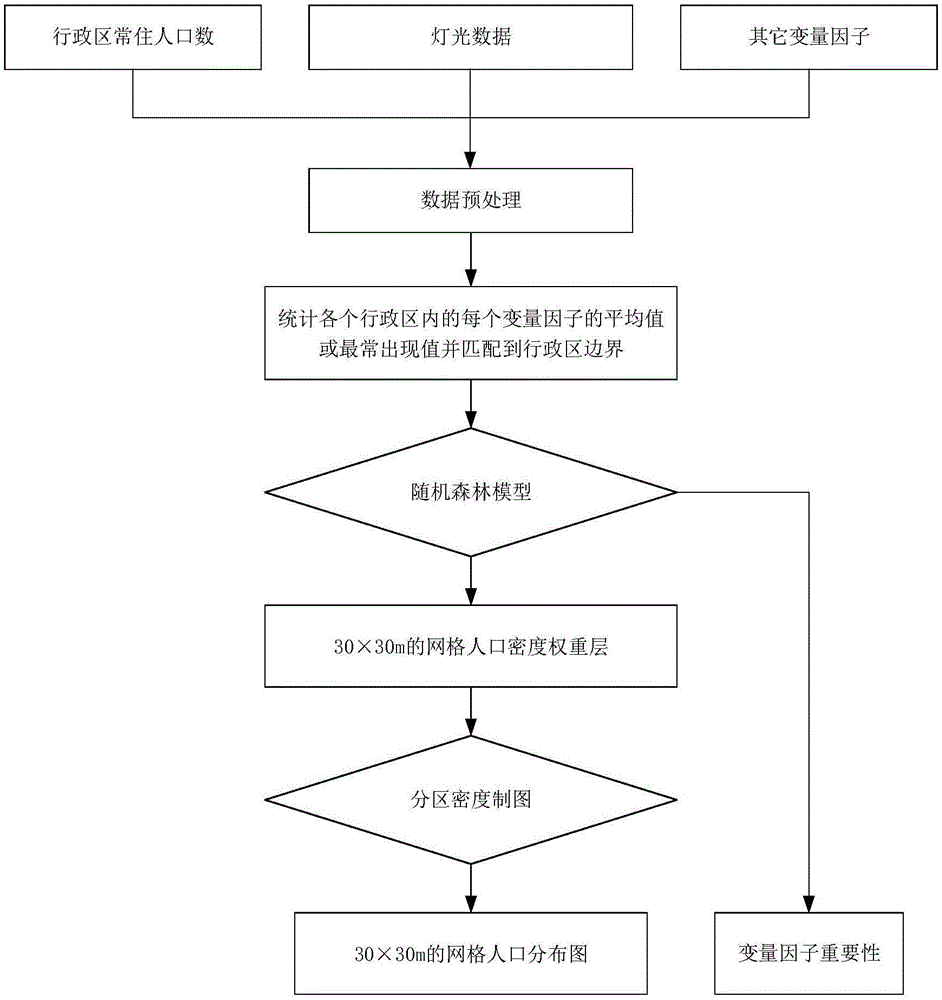
图1为本发明的一种基于随机森林模型的人口数据空间化方法的流程图;
图2为本发明中的数据预处理的框架图;
图3为本发明实施例中将矢量数据二值化栅格转换的结果;
图4为本发明实施例中变量因子的重要性;
图5为本发明实施例中随机森林模型反演得到的珠三角2010年30m网格的人口数据空间化初步结果图;
图6为本发明实施例中珠三角2010年30m网格人口分布示意图。
具体实施方式
图1出示了一个实例中的基于随机森林模型的人口数据空间化方法的实施方式,包括以下步骤:
(1)获取行政区的常住人口数、灯光数据以及其它对人口分布具有影响的自然和社会经济因素的原始数据,对数据进行预处理,得到变量因子距离数据、灯光数据、行政区人口密度的对数和二值化栅格转换后的变量因子数据;
(2)统计各个行政区内的每个变量因子的平均值或最常出现的值并匹配到行政区边界;
(3)将步骤(1)预处理后得到的变量因子距离数据、灯光数据和行政区人口密度的对数、二值化变量因子栅格数据、步骤(2)得到的变量因子的平均值或最常出现值作为随机森林模型的输入,来寻找变量因子与人口密度的对数之间的关系并输出变量因子重要性,基于这个关系反演出L×L米网格的人口数,得到人口数据空间化的初步结果;
(4)利用分区密度制图修正人口数据空间化的初步结果,最终实现基于随机森林模型的L米网格的人口数据空间化的初步结果。
步骤(1)中的预处理进一步包括:
步骤S11,将所有空间数据转换成统一投影坐标系以及参考椭球体。
步骤S12,将行政区的常住人口数除以行政区面积得到行政区的人口密度,并对人口密度取对数;
步骤S13,对灯光数据进行双线性的重采样成L×L米的栅格;
步骤S14,对建成区、河流、水体、道路等其它对人口分布具有影响的自然和社会经济变量因子进行欧氏距离计算。
步骤S15,对其它矢量格式的对人口分布具有影响的自然和社会经济变量因子进行二值化栅格转换。
步骤(1)中步骤S15的二值化栅格转换是将矢量格式的变量因子转换成栅格格式,并和行政区范围进行合并,0表示变量因子为空,1表示变量因子不为空。
步骤(2)中的统计各个行政区内的每个变量因子的平均值或最常出现的值具体是指对于变量因子的距离数据及其他连续变量因子进行平均值的统计,对于二值化的变量因子栅格数据进行最常出现值的统计。
步骤(4)中的分区密度制图法是按照随机森林得到的每个网格的人口占一个行政区的所有网格的总人口的比例重新分配每个网格的人口数,计算公式如下:
Pi=Sj×Di/Dj
式中,Pi为每个网格内的人口数,Sj为该网格所在的行政区的人口总数,Di为该网格根据随机森林模型估计得到的人口数,Dj为该网格所在的行政区的所有网格的根据随机森林模型估计得到的人口总数。
下面结合一个实施例和附图来具体阐述基于随机森林模型的人口数据空间化方法,以进一步了解本案的目的、方案和功能,但并非作为对本案后附权利要求保护范围的限制。图1为本发明的一种基于随机森林模型的30m网格的人口分布的估算方法的流程图,参考图1,该人口数据空间化方法包括:
(1)获取珠三角43个区县级行政区2010年的常住人口数、灯光数据以及其它对人口分布具有影响的自然和社会经济因素的原始数据如道路、河流、水体、高程、坡度、建成区,对数据进行预处理,得到建成区、河流、水体、道路的距离数据、灯光数据、行政区人口密度的对数和二值化栅格转换后的建成区、河流、水体、道路数据;
图2为数据预处理的框架图,参考图2,预处理进一步包括:
步骤S11,将所有空间数据转换成统一的Albers投影,中央经线东经105°,起始纬度为0°,标准线为北纬25°和北纬47°,参考椭球选择Krasovsky_1940椭球体。
步骤S12,将人口数据与珠三角区县级行政区划边界根据区县名称相匹配,保存为ESRI shapefile格式文件,其中的属性表字段包括行政区域名称和相应的人口数。利用ArcGIS属性表的地理计算工具统计各个区县的面积,将珠三角43个区县级行政区2010年的常住人口数除以行政区面积得到行政区的人口密度,并对人口密度取对数;
步骤S13,对灯光数据进行双线性的重采样成30×30m的栅格;
步骤S14,对于河流、水体、道路网和建成区的矢量格式数据,计算出珠三角范围内分别到河流、水体、道路网和建设用地的欧氏距离。
步骤S15,对变量因子数据进行二值化栅格转换。图3为本发明中将矢量数据二值化栅格转换的结果,二值化栅格转换是将矢量格式的变量因子如道路、建成区、水体、河流数据转换成栅格数据格式,栅格大小为30×30m,最后把栅格数据与行政区划边界叠加得到二值化栅格数据,即如果一个栅格的土地利用类型为河流或水体或道路网或建成区,则该栅格的值为1,否则为0。
(2)使用ArcGIS的zonal statistic工具的mean方式统计每个区县内分别到河流、水体、道路网和建成区的平均距离,把这四组平均距离添加到步骤S12中的属性表文件中;对于栅格数据格式的灯光数据、高程数据和坡度数据,使用ArcGIS的zonal statistic工具的mean方式统计得到每个区县内的平均灯光强度、平均高程和平均坡度,并把统计结果合并到步骤S12中的属性表文件中。对于二值化的栅格数据,使用ArcGIS的zonal statistic工具的majority方式统计每个区县内出现次数最多的值,并把统计结果合并到步骤S12中的属性表文件中。
(3)将步骤(1)预处理后得到的变量因子距离数据、灯光数据和行政区人口密度的对数、二值化变量因子栅格数据、步骤(2)得到的属性表文件作为随机森林模型的输入,来寻找变量因子与人口密度的对数之间的关系并输出变量因子重要性,图4为本发明实施例中变量因子的重要性,基于这个关系反演出30×30m网格的人口数。图5为本发明中随机森林模型反演得到的珠三角30m网格的人口数据空间化初步结果图。
(4)利用分区密度制图修正人口数据空间化初步结果,最终实现基于随机森林模型的30m网格的人口数据空间化,如图6所示。分区密度制图法是按照随机森林得到的每个网格的人口占一个行政区的所有网格的总人口的比例重新分配每个网格的人口数,计算公式如下:
Pi=Sj×Di/Dj
式中,Pi为每个网格内的人口数,Sj为该网格所在的行政区的人口总数,Di为该网格根据随机森林模型估计得到的人口数,Dj为该网格所在的行政区的所有网格的根据随机森林模型估计得到的人口总数。
在本发明提供的这种基于随机森林模型的人口数据空间化方法中,采用的随机森林模型可以同时输入大量与人口分布相关的变量,通过快速的机器学习后输出回归结果并且不会产生过拟合的问题,估算精度显著提高,同时可以评估影响人口分布的变量因子的重要性,在一定程度上解决了遥感技术和GIS技术结合使用而进行人口数据空间化的方法中精度较低、模型运行速度较慢、变量因子解释性差的问题。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详尽,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!