一种基于非监督学习的运动估计方法与流程
本发明涉及一种基于非监督学习的运动估计方法,属于计算机视觉技术领域。
背景技术:
当AlexNet神经网络模型在ImageNet竞赛中取得前所未有的成绩之后,深度卷积神经网络受到广泛的关注,尤其在计算机视觉领域,卷积神经网络的应用,使计算机视觉领域的很多问题得到了解决,也使得计算机视觉的研究领域得到了扩展。但这一切进步与发展,都得益于卷积神经网络的深层次结构,以及大量参数和良好的训练数据。
目前对于运动估计大部分算法很少采用深度神经网络这一项新技术,由于深度神经网络适合点对点的学习,或者找到输入数据和目标数据间的关系。而在涉及到寻找不同输入数据间的不同和相关关系时,深度神经网络的表现便变得差强人意。FlowNet运用监督学习的方法训练了深度卷积神经网络,但是FlowNet中的神经网络包含了多个卷积层,这使得训练神经网络需要大量的包含真值的数据。现阶段并不存在能提供有大量真值的标准训练数据库来训练深度卷积神经网络。为了达到训练目的,FlowNet使用了一个能提供真值的开源动画数据库Sintel,和自己设计的数据库Flyingchair以及对这些数据库中的数据做了相应的数据增长技术(包括加入高斯噪声,适度旋转)来达到训练数据数量要求。而其中的数据增长技术的使用主要是为了应对过拟合问题。
深度神经网络中,训练数据及训练方法是关键。使用适当的训练方法可以降低对训练数据的要求,选择合适的训练方法还可以提高神经网络的准确度。在本发明中本发明使用非监督学习,课程学习的方法,以及特殊的网络结构来实现基于深度神经网络的运动估计。
技术实现要素:
本发明目的在于解决上述现有技术的不足,提出了一种基于非监督学习的运动估计的方法,该方法是以非监督学习用于训练卷积神经网络,从而在数据缺少真值的情况下,使卷积神经网络能够找到相邻两帧图像之间的运动区域。
本发明解决其技术问题所采取的技术方案是:一种基于非监督学习的运动估计的方法,该方法包括如下步骤:
步骤1:从UCF101视频数据库中选取数据,并对图像进行标准化;
步骤2:搭建一种非普遍形式的卷积神经网络;
步骤3:以非监督学习的方法训练卷积神经网络;
步骤4:以从粗糙到细化的方法逐步完成运动区域的计算。
进一步,在本发明步骤1中,具体包括如下步骤:
步骤1-1:随机从UCF101视频数据库中选取相邻两帧的图像共50000对,作为训练数据集的第一部分;
步骤1-2:随机从UCF101视频数据库中选50000对图像,每对图像中间隔一帧,作为训练数据集的第二部分;
步骤1-3:随机从UCF101视频数据库中选50000对图像,每对图像中间隔两帧,作为训练数据集的第三部分;
步骤1-4:计算以上150000对图像的RGB平均值,和RGB方差,并把所有图像归一化;
进一步,在本发明步骤2中,具体包括如下步骤:
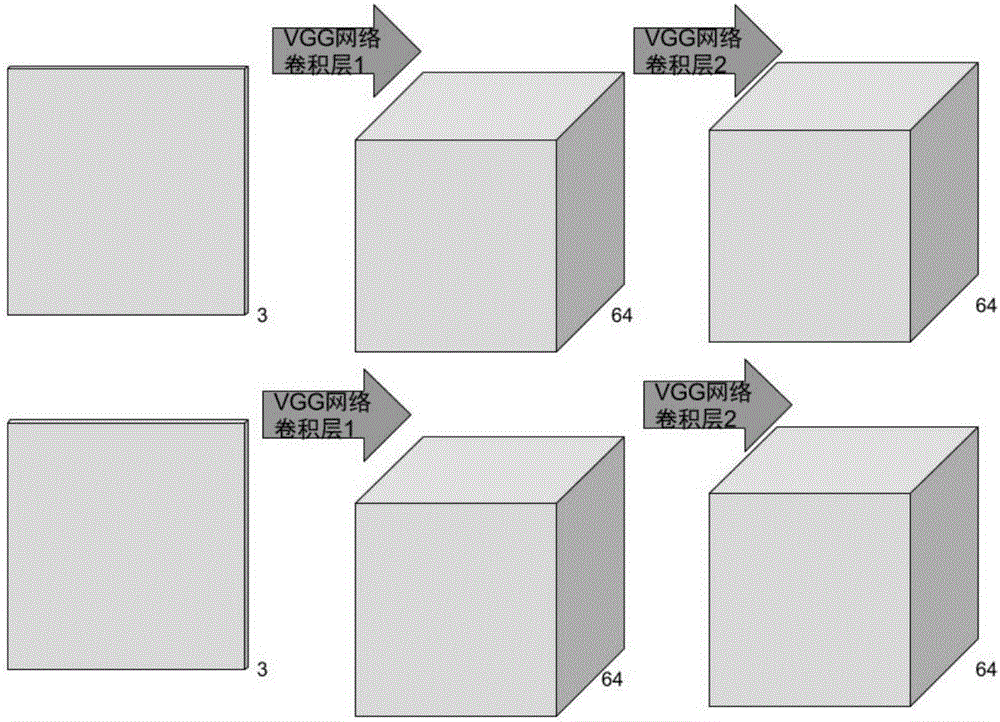
步骤2-1:引入VGG深度神经网络的前两层,包括此神经网络的结构和已经训练好的参数,搭建一种包含有两个输入层的非一般性神经网络,作为总神经网络的第一部分。此部分会将输入的两个图片分别处理;
步骤2-2:搭建运动区域识别神经网络,作为总体神经网络的第二部分;
步骤2-3:将神经网络中的连接层插入到神经网络第一部分和第二部分之间,并将神经网络第一部分输出的两部分特征图链接在一起;
步骤2-4:在链接层和神经网络第二部分之间加入一个卷积层,对合并后的特征图进行卷积处理。
进一步,在本发明步骤3中,具体包括如下步骤:
步骤3-1:如果训练数据的尺寸比较大,需要对训练图片进行缩小。先用训练数据集的第一部分作为新的训练数据集对神经网络进行训练,完成对神经网络的初步训练;
步骤3-2:向新训练数据集中逐步加入原训练数据集的第二部分和第三部分对神经网络进行训练。每加入一次新的数据后,都要基于前一次完成训练的网络再次进行训练;
步骤3-3:在以上训练过程中先固定VGG网络部分,完成所有数据引入之后,不再固定VGG部分,用较小的学习率基于之前的参数对整个神经网络进行重新微调。
进一步,在本发明步骤4中,具体包括如下步骤:
步骤4-1:将运动区域F初始化为0矩阵;设置循环次数n,默认值为4;将需要计算运动区域的两张图片进行缩小,缩小为原来的2/3,缩小的过程中保持长宽比例不变;
步骤4-2:将变形后的两张图片作为神经网络的输入,计算运动区域f,将f与F进行叠加,更新F;按照运动区域将第一张图片中的像素点进行移动,产生一张新的图片。此步骤重复t扭曲次,t扭曲为需要扭曲的次数,默认值为4;
步骤4-3:将新产生的第一张图片和之前的第二张图片进行放大,放大比例为将放大后的两张图片作为神经网络新的输入;将F也同比例放大;
步骤4-4:重复步骤4-2~步骤4-3n次,此时图片的大小恢复到图片的原始大小;
步骤4-5:输出最终结果F。
有益效果:
1、本发明为用深度卷积网络进行运动估计提出一种非监督学习的方法,该方法对训练数据的真值不再有要求,从而使得对训练数据的要求变低。
2、本发明对有较大运动幅度的两张图片可以进行有效地计算。
附图说明
图1为神经网络两个通道产生的特征图的合并过程。
图2为神经网络第一部分的结构示意图。
图3为神经网络的整体框架图。
图4为本发明的方法流程图。
具体实施方式
下面结合说明书附图对本发明的具体实施方式做进一步详细的说明。
如图4所示,本发明提供了一种基于非监督学习的运动估计的方法,该方法使用非监督学习的方法对卷积神经网络进行训练,采用此方法进行训练降低了对于训练数据中真值的要求。为了能达到训练目的本发明使用了课程学习的训练方法,并且建立了一种非一般性结构的深度卷积神经网络。最后为能使完成训练的网络模型完成针对运动幅度较大的运动区域进行计算,本发明采用了一种从粗糙到精细的模型来完成计算。具体的说,本发明是采用以下的技术方法来实现的:
步骤1:从UCF101视频数据库中选取数据,并对图像进行归一化。
步骤2:搭建一种非普遍形式的卷积神经网络。
步骤3:以非监督学习的方法训练卷积神经网络。
步骤4:基于完成训练的深度卷积神经网络,以从粗糙到细化的方法逐步完成运动区域的计算。
(1)卷积神经网络的搭建以及卷积神经网络结构说明
在现实生活中,本发明所见到的运动都是以物体为载体的。所以在运动估计的过程中,本发明假定物体运动区域所在的像素区域是物体区域的子集。所以,提取物体区域的特征对找到运动区域是有所帮助的。从而在神经网络的前两层,神经网络的第一部分,加入VGG网络(一种物体识别的神经网络)的前两层帮助提取图片中和物体相关的有效信息,以便为在之后的神经网络中提取运动信息和构建运动区域提供帮助。再一点,由hypercolumn理论中所提到,用于物体识别的深度神经网络中较靠前的卷积层所产生的特征图中会更多包含像素点所在位置的信息,而在深度神经网络中较靠后的卷积层所产生的特征图会包含更多的有利于分类的抽象信息并且很少包含像素点的位置信息。基于以上这几点本发明认为在此发明中引入了VGG神经网络的前两个卷积层是合理的。
已证明在FlowNet中,针对特定问题如果能够设计出针对该问题的神经网络即在结构上非一般化的结构会对解决问题提供更好的帮助。所以在本发明的发明中由于有两张图片作为输入,本发明为两张图片分别设计了入口和处理通道。两个通道均为引入的部分VGG网络。
在图片通过两条通道之后需要对卷积层所产生的特征图合并。从VGG网络卷积层产生的特征图为一个三维矩阵(x,y,z),(x,y)为输入图片的大小由输入图片决定,这里的z为64由VGG网络中卷基层的核矩阵数量决定。合并过的特征图的z为128。合并的过程中采用交叉合并的方法,将第一条通道产生的特征图的第一张图片作为合并后矩阵的第一张图片,第二条通道产生的特征图的第一张图片作为合并后矩阵的第二张图片,第一个特征图的第二张图片作为合并后特征图的第三张,第二个特征图的第二张图片作为合并后特征图的第四张,以此方法完成特征图的合并。从而在VGG网络中从同一个核矩阵不同通道中产生的特征图就能进行配对。
在合并层之后再加入一个卷积层,在此卷积层中使用三维的核矩阵并且设置每次核矩阵沿z方向移动,移动的距离为两张图片。这样核矩阵就是在寻找每一对特征图间的关系。
神经网络的最后一部分的主要功能为提取图片间的运动特征和构建出运动区域。这一部分神经网络包含12个卷积层和5个池化层以及4个反池化层。前7个卷积层和5个池化层负责从图片间提取运动特征,后5个卷积层和反池化层是为了构建出运动区域。在提取特征的过程中,池化层在从特征图中提取特征的同时会缩小特征图。而在运动区域构建的过程中,反池化层会将特征图进行逐步扩充,以构建和输入图片大小相同的特征图也就是最终的运动区域。
(2)基于光流的非监督学习
为了能够让卷积神经网络完成针对运动估计的非监督学习,本发明引入光流这一概念。而基于传统光流方程,本发明设计了深度神经网络训练过程中需要优化的成本方程。不同于一般神经网络的成本方程,此成本方程对输入数据的真值不再有要求。这一改变使原来的监督学习变成非监督学习,并且每次成本函数基于神经网络输出所产生的差值会像传统的神经网络一样作为模型优化的依据。而大量的数据是此模型最终具有一般性的保证。具体解释如下。
本发明使用光流的方法来计算两张图片的运动区域。大部分基于光流的方法可以被分成两类,基于全局的方法计算光流和基于局部的方法计算光流。在本发明中本发明使用基于全局的方法来计算光流。
在使用光流前,本发明必须提出两条假设。第一条为,在一段图像序列中或者一段视频中,两张相邻的图片中两个对应的点的光亮强度是不变的,此假设被称之为光强恒定假设。公式如下。
I(x+u,y+v,t+Δt)=I(x,y,t) (1)
公式(1)中I(x,y,t)表示第一张图片中某一点的光亮强度,I(x+u,y+v,t+Δt)表示第一张图片中的点对应到第二张图片中对应的点的光亮强度。(x,y)为该点在第一张图片中所在的位置。(x+u,y+v)为该点在第二张图片中的新的位置。u表示该点的水平方向上的位移,v表示该点垂直方向上的位移,Δt是两张图片在图片序列或者视频中的时间间隔。
借助于泰勒公式对公式(1)中的左边部分进行变形:
I(x+u,y+v,t+Δt)≈I(x,y,t)+uIx+vIy+It (2)
将公式(1)和公式(2)进行结合推导出公式(3):
uIx+vIy+It≈0 (3)
在公式(2)和公式(3)中,为光强在水平方向上的偏导,为光强在竖直方向上的偏导。It为两张图片对应位置的光强差值。具体的说,It为在第一张图片(x,y)位置像素点的光强值和第二张图片(x,y)位置的像素点的光强值的差值。而公式(2)的成立条件为u和v均为较小的值,否则泰勒公式不能成立。从而第二条假设为,两张图片间的运动幅度都比较小。
公式(3)也被称为光流方程。基于这样的方程本发明设计在非监督学习中需要的成本方程如下:
在公式(4)中u,v为神经网络计算出的运动区域中的水平位移和垂直位移。采用适当的矩阵可以很容易的算出Ix和Iy。计算It最简单的方法为将两张图片光强矩阵相减。∈为一个数值很小的正数,为公式的规范项,为了减少一些图片中的非常规点对成本函数的影响。公式(4)作为成本函数计算图片中每一个点产生的误差。深度神经网络的主要工作就是找到图片间的联系来计算运动区域即图片中每一个点运动情况。训练过程中,需要让神经网络不断将公式(4)最小化。
(3)神经网络模型的训练方式及训练数据的采集
为了应对图片间较大的运动,本发明在选取图片数据时做了相应的处理。本发明的训练数据从UCF101当中采集。UCF101包含了101种人类运动的视频,主要可以分为5大类,人类-物体交互,身体,人类间交互,运动和乐器演奏。
在采集数据时本发明每次都基于UCF101进行数据选取,在每个大类中随机选取10000对图片,根据图片间的间隔不同进行三次不同的选取。第一次只从视频中选取相邻帧的图片,选取数量为50000对图片。第二次选取图片对为视频中相隔一帧的图片,选取数量为50000对图片。第三次选取的图片为视频中相隔两帧的图片,选取的数量为50000对图片。基于这样的数据选取,训练数据集可以包含静止不动区域,小幅度运动,和较大幅度的运功,从而在深度卷积神经网络完成训练的之后可以处理多种情况并避免过拟合。
(4)处理图像间的大幅度运动
在之前本发明提到过,采用光流的运动估计基于两个假设。第二个假设为图片间的运动幅度都比较小。这个假设也意味着采用光流直接计算大幅度运算是不可能的。在此项发明中本发明采用一种从粗糙到细致的模型来处理较大幅度的运动。
在完成神经网络的训练之后该神经网络已经可以完成对较小运动幅度的运动进行计算。为了避免在两张图片间出现较大的运动幅度在一开始获得两张输入图片的时候先对两张图片进行缩小,原始图片表示为P1,P2。缩小后的图片保留原始图片的长宽比例,并表示为p1,p2。将缩小后的图片p1,p2作为神经网络的输入,得到计算出的运动区域f0。由于本发明中的神经网络是全卷积神经网络,所以计算出的区域f0的大小和p1,p2的大小是相同的。将p1和f0结合进行图像扭曲变换计算出一张新的图片p1′。将p1′,p2,f0同时放大,保持原来的长宽比例,并将p1′,p2作为神经网络新的输入计算新的运动区域f1。重复之前的操作直到输入图片的大小恢复成原始图片的大小。将所有运动区域叠加计算出最终的运动区域。
本发明算法过程包括如下:
1:t扭曲←需要扭曲的次数(默认为4次),n←需要放大的次数(默认为4次),
F运动区域←0矩阵
2:设P1,P2为两张原始输入图片
3:将第一张图片缩小为原来大小的2/3赋给p1
4:将第二张图片缩小为原来大小的2/3赋给p2
5:Do while(p1,p2的大小不等于P1,P2的大小)
6:t←0
7:Do while(t<t扭曲)
8:f运动区域←CNN(p1,p2):通过神经网络计算出的运动区域9:p1′←warp(p1,f运动区域):基于p1和f运动区域进行扭曲变换10:F运动区域←F运动区域+f运动区域
11:t←t+1
12:p1←p1
13:将p1,p2,F运动区域进行放大,放大为原来的
14:return F运动区域
表1
- 还没有人留言评论。精彩留言会获得点赞!