基于公共字典对和类依赖字典对的细粒度图像分类方法与流程
本发明属于数字图像处理领域,具体涉及一种基于公共字典对和类依赖字典对的细粒度图像分类方法。
背景技术:
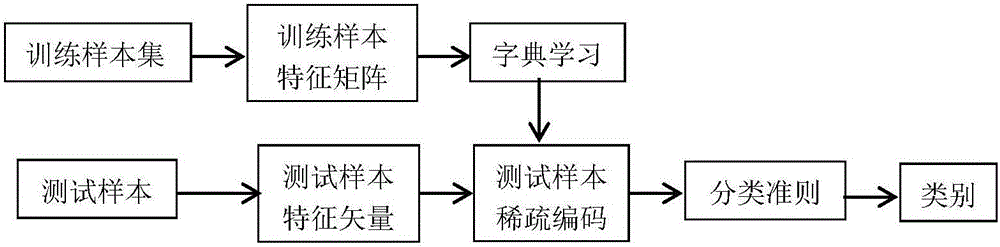
:传统的图像分类主要是指粗粒度图像分类,此时是对语义差别比较大的不同种类的图像进行分类。例如Caltech-101图像库中102类不同种类的图像,其中包括人造工具、动物、植物等,这些图像间的差异性较明显因此分类较容易,图1(a)所示是鸽子和海马的对比图。近年来细粒度图像分类在计算机视觉研究中的意义越来越明显,与粗粒度图像分类相比,它采用的图像库往往包含多种语义近似的物体图像,例如StanfordDogs图像库包含了120种不同种类的狗的图片,OxfordFlower-17图像库包含了17种不同种类的花的图片,图1(b)所示是向日葵和蒲公英的对比图。细粒度图像分类的图像间差异性较弱,因此对细粒度图像进行分类更加具有挑战性。随着稀疏表示技术的发展,研究者们逐渐发现字典性能的好坏直接关系到最后的分类结果。在基于稀疏表示的分类方法中字典既要被用来对样本进行稀疏编码,又要被用于执行最后的分类判别,因此本文将重点讨论如何从训练样本中学习到一个同时具有良好的表示能力和判别能力的字典。技术实现要素:为克服现有技术的不足,本发明旨在实现字典具有更强的判别性,避免对标准稀疏编码问题的求解,大大缩短分类用时,使系数具有一定的判别性。为此,本发明采用的技术方案是,基于公共字典对和类依赖字典对的细粒度图像分类方法,步骤如下:(1)提取图像库训练样本的SIFT特征矩阵,然后通过K-奇异值分解方法K-SVD得到初始化字典;(2)建立基于公共字典对和类依赖字典对的字典学习模型,字典学习模型中包含数据保真项,字典判别性约束项和系数判别性约束项,通过以上各项使字典具有更好的判别性;(3)采用迭代方法求解第2步中建立的字典模型,得到综合字典D和解析字典P,然后通过解析字典求解测试样本的稀疏表示矩阵;(4)根据最小化重建误差的方法确定图像所属类别。步骤1,提取数据集中图像的SIFT特征具体是:(1.1)将每幅图像以6像素为间隔,划分为16×16的图像块,提取出图像的原始稠密SIFT特征;(1.2)然后对原始特征在1×1、2×2、4×4三种尺度下进行空间金字塔最大池化,得到SIFT池化特征;(1.3)通过K-means方法对池化特征进行稀疏编码,对每幅图像的所有稀疏编码运用空间金字塔最大化池方法,得到21个1024维的稀疏编码的池化特征,连接这21个稀疏编码的池化特征得到一个21504维的图像描述向量;(1.4)通过PCA降维得到3000维的特征。步骤(2)建立字典学习模型具体是,字典模型的目标函数J(D,P,X)表示为下式,其中r(Yi,Di,Pi,Xi)是数据保真项,h(Di,Pi)是字典判别性约束项,f(Xi)是系数判别性约束项;其中D、P、X分别是综合字典、解析字典和样本的稀疏系数矩阵,Yi是第i类样本的特征矩阵,Xi是第i类样本对应的稀疏系数矩阵,K是样本的类别数,τ、ω是各项的权重系数;将每类的综合字典分成两部分其中D0是公共字典,是类依赖字典,最后得到K类的结构化综合字典为将每类的解析字典也分成两部分结构化解析字典为Xi是样本的稀疏系数矩阵;(2.1)采用结构化表示的重建误差项:(2.2)求取模型的字典判别性约束项,通过训练得到每类的子字典对{Di,Pi},将最小化作为解析字典Pi的判别性约束项,上式写成其中是在Y中删除第i类样本Yi后的剩余矩阵;(2.3)对系数添加Fisher判别性约束项,最后获得的字典模型为:其中μ、τ、ω、σ是各项的权重系数;dj是综合字典中第j个字典原子;t是每类的字典原子个数,即j的取值是j=1,…,t;设单位列向量n是每类样本的个数,则mi=Xi·1/n;Mi=mi·1T;M=m·1T。步骤3,采用迭代优化的方法求解字典学习模型,具体是将优化求解分为固定字典对{D,P}更新系数X和固定系数X更新字典对{D,P}两个子问题。步骤4,根据最小化重建误差的方法确定图像所属类别。上步求解字典模型后可以得到公共字典对{D0,P0}、第i类的类依赖字典对第i类的综合字典第i类的解析字典以及每个类别对应的字典对{Di,Pi},其中第i类解析型子字典只对与它同类别的样本具有很好的表示能力,同时第i类的综合型子字典Di可以根据编码系数PiYi对第i类的样本进行重构,测试阶段如果待分类样本y属于第i类,得到根据重构误差确定测试样本的类别具体表示为:步骤3具体过程为:(3.1)固定字典对{D,P}更新系数X,此时字典模型简化为:上式为标准最小二乘问题,通过解析方法求得其闭式解;(3.2)固定系数X更新解析字典此时字典模型简化为:上式也是标准最小二乘问题,通过解析方法求得其闭式解;(3.3)固定系数X更新综合字典此时字典模型简化为:上式采用交替方向乘子法进行求解。本发明的特点及有益效果是:1.本文方法中通过样本在解析字典P上的映射直接求解稀疏系数矩阵,避免了对标准稀疏编码问题的求解,大大减少了计算复杂度。2.本文方法对综合字典和解析字典均采用两部分的表示方式,即字典由公共字典原子和类依赖字典原子两部分组成,这种方法更加适用于对相似性较强的细粒度图像进行分类。3.本文方法在对字典采用判别约束的基础上,还采用Fisher判别准则编码系数使系数也具有一定的判别性。附图说明:图1是两种图像分类的示例图;(a)是粗粒度图像分类,(b)是细粒度图像分类。图2是本发明基于公共字典对和类依赖字典对的图像分类方法的流程图。图3是本发明实验数据库的部分图像及其公共特征和类依赖特征。具体实施方式传统的图像分类方法在细粒度图像分类问题中效果很差,主要原因在于细粒度图像的类间差异较小,传统图像分类方法的特征分辨力不够;其次是各个子类的图像在语义上相近,往往具有共同的结构特征有待挖掘。为了解决上述问题,本文提出了以下解决方法:一是将字典分成两部分进行学习的思路:由公共字典原子组成公共字典和由类依赖字典原子组成类依赖字典,公共字典和类依赖字典分别用于学习各类图像间的公共特征和类依赖特征,这样使得学到的字典具有更强的判别性;二是采用字典对学习模型,联合学习结构化综合字典对和结构化解析字典对,通过样本在解析字典上的映射直接求解稀疏系数矩阵,避免了对标准稀疏编码问题的求解,大大缩短了分类用时;三是采用Fisher判别准则编码系数使系数具有一定的判别性。本发明提出了一种基于公共字典对和类依赖字典对的细粒度图像分类方法,本方法的基本思路是:将字典分成公共字典对和类依赖字典对两部分进行学习,同时采用Fisher判别准则编码系数使系数具有一定的判别性。具体的方法步骤如下:(1)提取图像库训练样本的SIFT特征矩阵,然后通过K-奇异值分解方法得到初始化字典。(2)建立基于公共字典对和类依赖字典对的字典学习模型,字典学习模型中包含数据保真项,字典判别性约束项和系数判别性约束项,通过以上各项使字典具有更好的判别性。(3)采用迭代方法求解第2步中建立的字典模型,得到综合字典D和解析字典P,然后通过解析字典求解测试样本的稀疏表示矩阵。(4)根据最小化重建误差准则确定图像所属类别。本文实验采用OxfordFlower-17图像库,图像库中包含17类花,每类80张图像。每类随机选择60张图像作为训练样本,剩余图像作为测试样本,实验数据为多次实验结果的平均值。用本文方法与其他方法在OxfordFlower-17图像库上的结果进行对比如表1所示。表1本文方法与其他方法在OxfordFlower-17数据集上比较结果采用方法分类准确率(%)字典训练阶段用时(s)分类阶段用时(s)ScSPM52.356394.274259.51LC-KSVD61.0156.18296.27FDDL66.1915167.2314641.94本文方法70.45558.421.48衡量分类模型性能好坏时既要考虑其分类准确率又要考虑其时间消耗,因此对比内容包括在不同分类方法下的分类准确率、字典训练阶段用时和分类阶段用时。在同样的实验设置下为了证明本文算法的有效性,首先比较分类准确率,本文方法在OxfordFlower-17图像库上的分类准确率比ScSPM、LC-KSCD、FDDL方法分别高出18.1%、9.44%、4.26%;然后比较时间消耗,从表中数据可以看出不论是字典训练阶段还是分类阶段,本文方法在时间消耗方面占有明显的优势。分析上述结果的原因主要有以下几点:一是本文方法不仅对字典添加了判别性约束项,而且对系数也添加了Fisher判别性约束项,因此通过本文方法学到的字典具有更强的判别性;二是本文中对将字典分成公共字典和类依赖字典两部分,因此在对相似性很强的图像库如OxfordFlower-17图像库进行分类时能够获得明显的提高;三是本文中采用字典对的表示方法,即最终获得的结构化字典由公共字典对和类依赖字典对组成,样本在字典对的解析字典上的映射可以用来直接求解稀疏系数,避免了对标准稀疏编码问题的求解,使得模型的时间消耗大大减少。本方法不仅在分类准确率方面得到了提升,而且大大缩短了分类问题的时间消耗,说明了本方法的有效性和可行性。为了使本方法的方案及优点更加清楚明白,对本方法进行具体的说明:步骤1,提取数据集中图像的SIFT特征。(1.1)将每幅图像以6像素为间隔,划分为16×16的图像块,提取出图像的原始稠密SIFT特征;(1.2)然后对原始特征在1×1、2×2、4×4三种尺度下进行空间金字塔最大池化,得到SIFT池化特征;(1.3)通过K-means方法对池化特征进行稀疏编码,其中k设置为1024,对每幅图像的所有稀疏编码运用空间金字塔最大化池方法,得到21个1024维的稀疏编码的池化特征,连接这21个稀疏编码的池化特征得到一个21504维的图像描述向量;(1.4)通过PCA降维得到3000维的特征。步骤2,建立字典学习模型。字典模型可以表示为下式:其中r(Yi,Di,Pi,Xi)是数据保真项,h(Di,Pi)是字典判别性约束项,f(Xi)是系数判别性约束项。其中Yi是第i类的训练样本,Xi是该类样本对应的稀疏系数矩阵,D,P分别是综合字典和解析字典,K是样本的类别数;将每类的综合字典分成两部分其中D0是公共字典,是类依赖字典,最后得到的结构化综合字典为将每类的解析字典也分成两部分结构化解析字典为(2.1)采用结构化表示的重建误差项:(2.2)求取模型的字典判别性约束项。通过训练得到每类的子字典对{Di,Pi},因此解析子字典Pi对第i类的训练样本有很好的表示能力,而对不是第i类的训练样本表示能力则较差,即PiYi<<PiYj(j≠i),因此可以将最小化作为解析字典Pi的判别性约束项。因为所以上式也可以写成(2.3)求取模型的系数判别性约束项。采用Fisher约束来衡量不同类别信号间的相似性信息,具体是通过最小化类内散度SW(X)和最大化类间散度SB(X)来实现的。综上所述最后获得的字典模型为:其中μ、τ、ω、σ是各项的权重系数;dj是综合字典中第j个字典原子;t是每类的字典原子个数,即j的取值可以是j=1,…,t;设单位列向量n是每类样本的个数。则mi=Xi·1/n;Mi=mi·1T;M=m·1T;步骤3,求解字典学习模型。可以采用迭代优化的方法,将优化求解分为固定字典对{D,P}更新系数X和固定系数X更新字典对{D,P}两个子问题。具体步骤为:(3.1)固定字典对{D,P}更新系数X,此时字典模型简化为:上式为标准最小二乘问题,可以通过解析方法求得其闭式解。(3.2)固定系数X更新解析字典此时字典模型简化为:上式为标准最小二乘问题,可以通过解析方法求得其闭式解。(3.3)固定系数X更新综合字典此时字典模型简化为:上式可以采用交替方向乘子法进行求解。步骤4,根据最小化重建误差的方法确定图像所属类别。上步求解字典模型得到公共字典对{D0,P0}、第i类的类依赖字典对第i类的综合字典第i类的解析字典以及每个类别对应的字典对{Di,Pi}。其中第i类解析型子字典只对与它同类别的样本具有很好的表示能力,同时第i类的综合型子字典Di可以根据编码系数PiYi对第i类的样本进行重构,此时的重构误差较小,但当j≠i时的值较大,因此第i类的字典对第k类样本的重构误差将远大于对第i类样本的重构误差。在测试阶段如果待测试样本y属于第i类,根据上述分析可以得到显然根据重构误差可以用来确定测试样本的类别,具体表示为:当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1