一种基于机器学习的安卓恶意软件动态检测方法与流程
本发明涉及恶意软件动态检测技术、信息安全技术、机器学习等多种领域,特别是一种基于机器学习的安卓恶意软件动态检测方案。
背景技术:
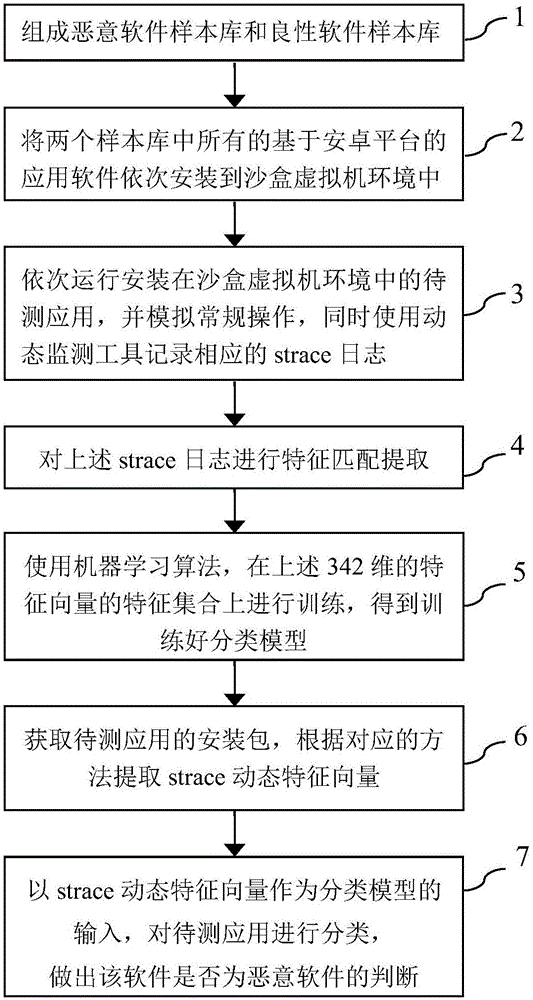
:Android的快速发展和急剧扩张,成就了其市场份额上的霸主地位,也使其成为了恶意软件首要攻击的目标平台。同时由于Android的开放性,使得恶意软件的开发成本和难度降低,厂家定制的ROM和第三方市场的大量存在也使得恶意软件的生态更加复杂。共同作用下,Android恶意软件的数量呈现爆炸性增长的态势。互联网协会总结了恶意软件的特征并给出定义,“恶意软件是指在未明确提示用户或未经用户许可的情况下,在用户计算机或其他终端上安装运行,侵害用户合法权益的软件”。恶意软件危害很多,轻则无法删除占用空间,更甚者窃取宿主隐私、消耗用户系统资源造成卡顿等,有些甚至可以直接造成用户的经济损失、破坏宿主的硬件。Android系统的运行底层是Linux内核,所有的Android应用对系统资源的使用,最终都反映在内核的系统调用上。Android平台的恶意软件检测,按照检测方法和检测目标划分,可以分为动态检测、静态检测以及基于云计算的检测等。所谓静态检测是指在不运行软件的情况下,将打包好的app安装文件(.apk)进行解包获取相应的文件,进而反编译得到原代码,检测恶意代码片段来确定恶意性。动态检测,就是在待测应用在沙盒系统运行中时去收集相关信息,利用相关监控工具监控其是否有联网、获取隐私等行为,进而判别软件是否有恶意性。基于云计算的检测是针对移动设备在电量和计算能力方面的局限性,把检测方案部署到具备海量存储和大量计算能力的云端服务器上,在被检测设备上只保留代理软件来采集基本信息,检测结果通过网络发回,从而提高检测表现。技术实现要素:基于现有技术,本发明提出了一种基于机器学习的安卓恶意软件动态检测方法,利用沙盒虚拟机环境,搜集基于安卓平台的待测应用的动态执行日志并进行机器学习,根据机器学习得到的分类模型,实现恶意软件检测。本发明的一种基于机器学习的安卓恶意软件动态检测方法,该方法包括以下步骤:步骤一,从不同来源收集两个样本库,分别组成恶意软件样本库和良性软件样本库;步骤二,将两个样本库中所有的基于安卓平台的应用软件依次安装到沙盒虚拟机环境中,这些基于安卓平台的应用软件作为待测应用;步骤三,使用自动化脚本依次运行安装在沙盒虚拟机环境中的待测应用,并模拟常规操作,同时使用动态监测工具记录相应的strace日志;步骤四,对上述strace日志进行特征匹配提取,统计342种systemcall每个出现的次数,这样每个待测应用生成一个与之对应的342维的统计特征向量,再标定良性或恶意的类别;步骤五,使用机器学习算法,在上述342维的特征向量的特征集合上进行训练,得到可以对未知应用进行分类判别的分类模型;步骤六,生成各个待测应用的对应的strace动态特征向量,这里是一个由自然数组成的分别代表对应系统调用出现次数的342维的特征向量;步骤七,以strace动态特征向量作为分类模型的输入数据,将此输入数据作为训练数据,对每组训练数据定义一个明确的标识及对应的分类结果,将分类结果与分类模型标准比较,进而判断出待测样本是否是恶意软件的判断。与现有技术相比,本发明的一种基于机器学习的安卓恶意软件动态检测方法具有以下积极的技术效果:(1)通用性强、适用范围广的特点,没有如静态检测技术中面对混淆和加密防护时无法完成反编译提取源文件和代码的问题,只要是可以运行的应用,均可以是用该方法实行检测;(2)可以取得良好的准确率,适于作为各个安卓应用市场的应用审核工具和云端检测方案的实时云端检测中枢。附图说明图1为恶意软件检测流程实施例示意图图2为本发明的一种基于机器学习的安卓恶意软件动态检测方法整体流程图。具体实施方式下面结合附图对本发明作进一步详细描述。本发明的整体思路是采用基于机器学习的动态检测方法,首先通过大量样本进行训练,得出较好的分类模型,然后在沙盒中运行待检测的程序,提取起其strace动态特征,输入分类模型后得出检测结果。如图1所示,通过以下的具体实施例将本发明流程详细描述如下:步骤1,从VirusShare论坛中获取已经标定的恶意程序集M,从安卓官方市场GooglePlay采集正常程序集B,从中各选取300个样本,组成本发明的样本库;步骤2,开启运行在Linux系统环境下的Android虚拟机,使用adbconnect命令连接adb调试工具,遍历步骤一中收集到的样本库的安装包文件夹,依次使用adbinstall*.apk指令,将待测应用安装于沙盒虚拟机上;步骤3,使用脚本工具依次运行步骤二安装好的待测应用,这里使用的是python脚本和shellscript脚本。对每个待测应用,调用Monkey自动运行工具,对其进行模仿人类的日常操作,同时调用strace工具,对该应用启动的所有运行于Linux内核中的进程进行监控,获取相应的strace运行日志,记录应用对系统函数(systemcall)的调用情况,对于一个应用开启多个进程的情况,将运行日志合并;步骤4,对样本库中所有的程序对应的strace日志进行特征匹配提取,统计342种systemcall每种出现的次数,这样每个样本生成一个与之对应的342维的统计特征向量,再标定类别。这些系统调用的类型包括但不限于表1:表1、系统调用变量实例系统调用号函数名入口点0readsys_read1writesys_write2opensys_open3closesys_close4statsys_newstat5fstatsys_newfstat6lstatsys_newlstat7pollsys_poll8lseeksys_lseek9mmapsys_mmap10mprotectsys_mprotect11munmapsys_munmap12brksys_brk13rt_sigactionsys_rt_sigaction15rt_sigreturnstub_rt_sigreturn16ioctlsys_ioctl17pread64sys_pread6418pwrite64sys_pwrite6419readvsys_readv20writevsys_writev………步骤5,基于上述步骤获得的样本特征向量集,使用相关的机器学习分类算法进行训练,得到最佳的分类模型。在实施中,分别采用临近算法(kNN)、支持向量机(SVM)、朴素贝叶斯(Bayes)等算法,比较结果最终选取SVM为最佳算法;步骤6,对于待测软件,采用步骤2、步骤3和步骤4对其进行strace动态特征提取,生成其特征向量;步骤7,将待测软件的特征向量,作为步骤5生成训练模型的输入,得到最终的分类结果,即对该软件是否为恶意软件做出判断。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1