一种基于RNNs的短信自动安全审核的方法与流程
本发明涉及一种基于RNNs的短信自动安全审核的方法,属于自然语言处理、深度学习以及命名实体识别等
技术领域:
。
背景技术:
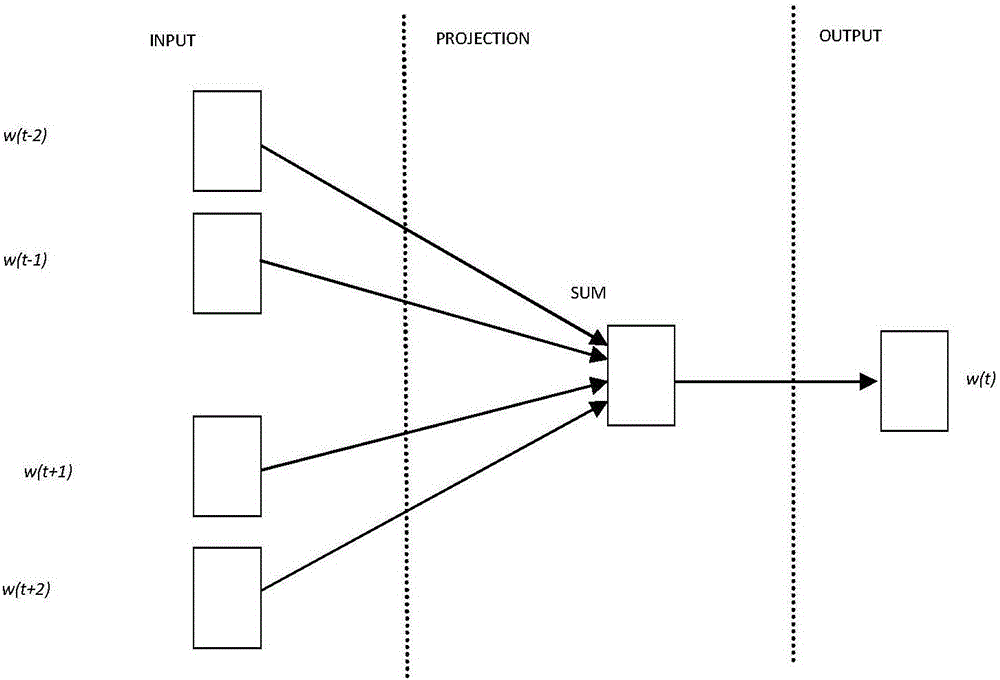
:随着互联网和信息技术的发展,为了提升对服刑人员的关爱服务,很多监狱已经开通了短信服务内容,服刑人员可以通过特定设备发送短信(文本内容)给家属,提升了犯人与家属的亲情联系,提升了改造质量水平。目前短信业务很受犯人欢迎,因此发送数量很大,特别是节假日期间短信数量更是巨大,这些短信都需要干警进行人工审核,耗时耗力,给干警工作带来很大的负担。有些地方采用了一些技术手段进行辅助审核,例如:关键字和规则审核,但是由于短信文本内容的复杂性,使用效果都不理想。因此需要通过大数据机器学习的手段找到合适的解决措施。文本分类用电脑对文本集(或其他实体或物件)按照一定的分类体系或标准进行自动分类标记,它是一种有监督的机器学习。文本分类的传统方法是一个句子表示为“词袋”(bagofwords)模型,映射为特征向量,然后通过机器学习的技术进行分类,比如:朴素贝叶斯(NaiveBayes)、支持向量机(supportvectormachines)、最大熵(maximumentropy)等。但是这些分类方法没有考虑文本的序列顺序,而文本的序列性对分析文本具有很重要的作用。由于监狱短信文本内容的复杂性和特殊性,基于关键词和规则的方法效果都不理想。比如“最近家里怎么样?想死你们了”和“到现在都不回我短信,你们想死啊”,同样的词在不同的语境下意义是不同的,而关键词仅局限于字面匹配、缺乏语义理解。虽然制定规则有时候是有效的,但是手工编写需要消耗大量的时间,而且很难扩展,并且每个监狱的规则也不统一,有些不合理的句型无法用规则进行判别。技术实现要素:针对现有技术的不足,本发明提供了一种基于RNNs的短信自动安全审核的方法;RNNs是指循环神经网络(recurrentneutralnetworks,RNNs),本发明基于RNNs的一个模型来自动对短信进行分类。从现有的安全/非安全的短信中提取有代表性的特征,通过深度学习方式,训练一个机器模型,在这个模型中,通过GloVe模型对短信文本进行特征提取,然后用循环神经网络(RNNs)对短信分类,实现短消息的自动安全审核,准确率达到92.7%,为干警的审核提供辅助支持,减轻干警的工作量,提升监狱安全性。术语解释1、word2vec,是Google在2013年年中开源的一款将词表征为实数值向量的高效工具,其利用深度学习的思想,可以通过训练,把对文本内容的处理简化为K维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。2、GloVe,即GloveVector,GloVe模型是一种“词-词”矩阵进行分解从而得到词表示的方法。本发明的技术方案为:一种基于RNNs的短信自动安全审核的方法,具体步骤包括:(1)对历史短信数据进行预处理,预处理包括去除噪音、中文分词;词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。我们根据句子中每个词词性的不同对词进行标注。例如:“我们组合成一个团队”,词性标注为:我们ad/组合v/成v/一个m/团队n/,中文分词的结果为“我们组合成一个团队”。(2)对步骤(1)预处理后的历史短信数据提取特征,生成词向量;(3)用RNNs与朴素贝叶斯相集成的分类模型实时对短信文本进行分类。根据本发明优选的,所述步骤(2),基于HierarchicalSoftmax的CBOW模型提取特征,具体包括:最大化基于HierarchicalSoftmax的CBOW模型的优化函数,训练得到每个中文分词的词向量;基于HierarchicalSoftmax的CBOW模型的优化函数如式(Ⅰ)所示:C为语料库,w是指步骤(1)中文分词后得到的任意词;Context(w)是w的上下文。每个词的词向量都是通过最大化这个似然函数训练得到的,当训练收敛以后,意思相似的词会被映射到向量空间的相似的位置。在我们的模型里,通过搜狗语料、微博语料和监狱的短信来训练词向量。根据本发明优选的,所述步骤(2),通过GloVe模型生成词向量,具体包括:最小化式(Ⅱ),在矩阵分解步骤,GloVe模型借鉴了推荐系统中基于隐因子分解(LatentFactorModel)的方法,在计算重构误差时,只考虑共现次数非零的矩阵元素,同时对矩阵中的行和列加入偏移项。所述式(Ⅱ)如下所示:式(Ⅱ)中,矩阵第i行第j列的值为词vi与词vj在与语料库中的出现次数xij的对数;pi为词vi作为目标词时的词向量,一句话中中间的词作为目标词;qi为词vj作为上下文时的词向量,目标词左右的词为其上下文,b(1)、b(2)为针对词表中各词的偏移向量,语料库中不重复的词组成了词表,f(x)是一个加权函数,f(x)的定义为:当x<xmax时,f(x)=(x/xmax)α;否则,f(x)=1;xmax是指两个词共同出现的最大次数,GloVe模型中xmax的取值为100。f(x)对低频的共现词对进行衰减,减少低频噪声带来的误差;GloVe模型是Jeffrey和Richard在2014年提出的,相比其他矩阵分解的模型(比如潜在语义分析Latentsemanticanalysis,LAS)和word2vec,GloVe在充分利用了语料库的全局统计信息的同时,也提高了词向量在大语料上的训练速度(一个共现矩阵的遍历要比整个语料库的遍历容易的多)。同时,GloVe得到的词向量更能把握住词与词之间的线性关系。根据本发明优选的,所述步骤(3),将含有的敏感词的短信通过朴素贝叶斯训练分类,不含敏感词的短信通过RNNs训练分类;敏感词包括{w1,w2,…,wn},所述敏感词根据监狱规定人工提取的敏感词。根据本发明优选的,将含有的敏感词的短信通过朴素贝叶斯训练分类,具体步骤包括:a、训练过程:敏感词{w1,w2,…,wn}作为朴素贝叶斯x的特征属性,即a1:{w1,w2,…,wn},a1为敏感词{w1,w2,…,wn}组成的集合,类别集合C={y0=0(安全),y1=1(非安全)};假设各敏感词之间相互独立,根据贝叶斯概率公式,某条短信里有m个敏感词,wi∈{w1,w2,…,wm},通过式(Ⅲ)求取其包含的敏感词在非安全短信和安全的短信里出现的概率的比值,式(Ⅲ)如下所示:式(Ⅲ)中,P(C=y1|wi)为短信中包含敏感词wi时此条短信不安全的概率;P(C=y0|wi)为短信中包含敏感词wi时此条短信不安全的概率;P(y1),P(y0)为先验概率;例如,训练集短信数据为3500条安全短信,500条非安全短信,则:P(wi|C=y1)是在非安全的短信里包含敏感词wi的概率;P(wi|C=y0)是在安全的短信里包含敏感词wi的概率;例如,有N条非安全短信包含敏感词wi,M条安全短信包含敏感词wi,则α为训练参数,α为1.138;b、测试过程:测试集包括安全短信和非安全短信,根据安全短信和非安全短信中包含的敏感词计算出式(Ⅴ)的概率比值,当这个比值大于或者等于α时,此短信被判为非安全,否则就是安全的。根据本发明优选的,不含敏感词的短信通过RNNs训练分类,所述RNNs模型包括输入单元(Inputunits)、输出单元(Outputunits)、隐藏单元(Hiddenunits),输入单元的输入集标记为{x0,x1,…xt,xt+1…},输出单元的输出集标记为{o0,o1,…ot,ot+1…},隐藏单元标记为{s0,s1,…st,st+1…},st为隐藏单元的第t步的状态,是网络的记忆单元。具体步骤包括:①通过误差向后传播算法(ErrorBackPropagation,BP算法)训练,将输入矩阵N×d×M输入至RNNs模型,N是指批量处理历史短信的个数,d是指步骤(2)得到的词向量的维数,M是指批量处理历史短信中最长的短信的词的个数;②st根据当前步输入单元的输出xt与上一步隐藏单元的状态st-1进行计算,如式(Ⅳ)所示:st=f(Uxt+Wst-1)(Ⅳ)式(Ⅳ)中,f为非线性的激活函数,如tanh或ReLU,s0为0向量,W是指隐藏单元的权重,U是指输入单元的权重,需要通过训练网络得到;在计算s0时,即第一个单词的隐藏层状态,需要用到st-1,但是其并不存在,在实现中一般置为0向量。③ot是输出单元第t步的输出,计算公式如式(Ⅴ)所示:ot=softmax(Vst)(Ⅴ)式(Ⅳ)中,softmax()是指归一化的激活函数,V是输出单元的权重,隐藏单元第t步的状态st是网络的记忆单元,包含前面所有步的隐藏单元状态,输出单位的输出ot只与当前步的st有关。在实践中,为了降低网络的复杂度,往往st只包含前面若干步而不是所有步的隐藏层状态。在传统神经网络中,每一个网络层的参数是不共享的。而在RNNs中,每输入一步,每一层各自都共享参数U,V,W。其反应者RNNs中的每一步都在做相同的事,只是输入不同,因此大大地降低了网络中需要学习的参数;也就是说,传统神经网络的参数是不共享的,并不是表示对于每个输入有不同的参数,而是将RNN是进行展开,这样变成了多层的网络,如果这是一个多层的传统神经网络,那么xt到st之间的U矩阵与xt+1到st+1之间的U是不同的,而RNNs中的却是一样的,同理对于s与s层之间的W、s层与o层之间的V也是一样的。④将步骤(3)的实际输出ot与预期输出进行比较,产生误差;⑤将步骤(4)得到的误差通过隐藏单元向输入单元逐层反传,修改网络的权重U,V,W和网络参数,直到训练达到预先设定的训练次数30-50次停止训练。根据本发明优选的,所述步骤(1),所述去除噪音包括去除短信中的标点符号、剔除字数小于3的短信;所述中文分词为使用ANSJ研发工具进行中文分词。ANSJ研发工具由中科院研发。根据本发明优选的,所述步骤⑤,将步骤(4)得到的误差通过隐藏单元向输入单元逐层反传,修改网络的权重U,V,W和网络参数,直到训练达到预先设定的训练次数30次停止训练。本发明的有益效果为:1、本发明实现了短信安全性的自动审核,提供了一个相对严格的审核模型,尤其是对非安全短信,辅助了干警的审核工作,使得短信审核工作更加严谨高效。2、本发明根据监狱短信的特殊性及其特点,利用两种方式相结合来对短信的安全性经分类,单纯的以敏感词并不能完全确定其安全与否,需根据此敏感词在安全/非安全的概率的比值来确定此条短信是否安全,这种方法相对于只通过是否包含敏感词来判定短信的安全性更加合理化。3、本发明不包含敏感词的短信,需要通过整句话的语义的短信需要通过RNNs来判定,因为RNNs的结构模型擅长处理序列数据,而一句话恰好就是一个有顺序的序列。附图说明图1为本发明所述一种基于RNNs的短信自动安全审核的方法的流程框图;图2为CBOW模型的结构框图;图3为RNNs模型的结构框图;图4为本发明反向传播算法流程示意图;图5为RNNs模型训练流程图;图6为学习速率η对损失函数的影响示意图。具体实施方式下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。实施例1一种基于RNNs的短信自动安全审核的方法,如图1所示,具体步骤包括:(1)对历史短信数据进行预处理,预处理包括去除噪音、中文分词;所述去除噪音包括去除短信中的标点符号、剔除字数小于3的短信;所述中文分词为使用ANSJ研发工具进行中文分词。词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。我们根据句子中每个词词性的不同对词进行标注。例如:“我们组合成一个团队”,词性标注为:我们ad/组合v/成v/一个m/团队n/,中文分词的结果为“我们组合成一个团队”。(2)通过GloVe模型生成词向量,具体包括:最小化式(Ⅱ),在矩阵分解步骤,GloVe模型借鉴了推荐系统中基于隐因子分解(LatentFactorModel)的方法,在计算重构误差时,只考虑共现次数非零的矩阵元素,同时对矩阵中的行和列加入偏移项。所述式(Ⅱ)如下所示:式(Ⅱ)中,矩阵第i行第j列的值为词vi与词vj在与语料库中的出现次数xij的对数;pi为词vi作为目标词时的词向量,一句话中中间的词作为目标词;qi为词vj作为上下文时的词向量,目标词左右的词为其上下文,b(1)、b(2)为针对词表中各词的偏移向量,语料库中不重复的词组成了词表,f(x)是一个加权函数,f(x)的定义为:当x<xmax时,f(x)=(x/xmax)α;否则,f(x)=1;xmax是指两个词共同出现的最大次数,GloVe模型中xmax的取值为100。f(x)对低频的共现词对进行衰减,减少低频噪声带来的误差;GloVe模型是Jeffrey和Richard在2014年提出的,相比其他矩阵分解的模型(比如潜在语义分析Latentsemanticanalysis,LAS)和word2vec,GloVe在充分利用了语料库的全局统计信息的同时,也提高了词向量在大语料上的训练速度(一个共现矩阵的遍历要比整个语料库的遍历容易的多)。同时,GloVe得到的词向量更能把握住词与词之间的线性关系。(3)用RNNs与朴素贝叶斯相集成的分类模型实时对短信文本进行分类。将含有的敏感词的短信通过朴素贝叶斯训练分类,不含敏感词的短信通过RNNs训练分类;敏感词包括{w1,w2,…,wn},所述敏感词根据监狱规定人工提取的敏感词。将含有的敏感词的短信通过朴素贝叶斯训练分类,具体步骤包括:a、训练过程:敏感词{w1,w2,…,wn}作为朴素贝叶斯x的特征属性,即a1:{w1,w2,…,wn},a1为敏感词{w1,w2,…,wn}组成的集合,类别集合C={y0=0(安全),y1=1(非安全)};如图6所示,在训练模型时,应选择合适的学习速率η,η太小会导致收敛太慢,太大会造成损失函数的振荡。本模型中η设为0.001。学习速率实际和信号分析里的时间常数是一样的,学习速率越小学习会越精细,但同时学习时间也会增加,因为现实中很多模型都是非线性的,犹如一条曲线,梯度下降采用很多小直线迭代去逼近非线性的曲线,如果每一步跨度太大(学习速率)就会失去很多曲线的扭曲信息,局部直线化过严重,跨度太小你要到达曲线的尽头就需要很多很多步,增加学习的时间,导致收敛太慢。假设各敏感词之间相互独立,根据贝叶斯概率公式,某条短信里有m个敏感词,wi∈{w1,w2,…,wm},通过式(Ⅲ)求取其包含的敏感词在非安全短信和安全的短信里出现的概率的比值,式(Ⅲ)如下所示:式(Ⅲ)中,P(C=y1|wi)为短信中包含敏感词wi时此条短信不安全的概率;P(C=y0|wi)为短信中包含敏感词wi时此条短信不安全的概率;P(y1),P(y0)为先验概率;例如,训练集短信数据为3500条安全短信,500条非安全短信,则:P(wi|C=y1)是在非安全的短信里包含敏感词wi的概率;P(wi|C=y0)是在安全的短信里包含敏感词wi的概率;例如,有N条非安全短信包含敏感词wi,M条安全短信包含敏感词wi,则α为训练参数,α为1.138;b、测试过程:测试集包括安全短信和非安全短信,根据安全短信和非安全短信中包含的敏感词计算出式(Ⅴ)的概率比值,当这个比值大于或者等于α时,此短信被判为非安全,否则就是安全的。不含敏感词的短信通过RNNs训练分类,所述RNNs模型包括输入单元(Inputunits)、输出单元(Outputunits)、隐藏单元(Hiddenunits),输入单元的输入集标记为{x0,x1,…xt,xt+1…},输出单元的输出集标记为{o0,o1,…ot,ot+1…},隐藏单元标记为{s0,s1,…st,st+1…},st为隐藏单元的第t步的状态,是网络的记忆单元。如图3所示,RNNs训练流程图如图5所示,具体步骤包括:①通过误差向后传播算法(ErrorBackPropagation,BP算法)训练,反向传播算法流程示意图如图4所示,将输入矩阵N×d×M输入至RNNs模型,N是指批量处理历史短信的个数,d是指步骤(2)得到的词向量的维数,M是指批量处理历史短信中最长的短信的词的个数;②st根据当前步输入单元的输出xt与上一步隐藏单元的状态st-1进行计算,如式(Ⅳ)所示:st=f(Uxt+Wst-1)(Ⅳ)式(Ⅳ)中,f为非线性的激活函数,如tanh或ReLU,s0为0向量,W是指隐藏单元的权重,U是指输入单元的权重,需要通过训练网络得到;在计算s0时,即第一个单词的隐藏层状态,需要用到st-1,但是其并不存在,在实现中一般置为0向量。③ot是输出单元第t步的输出,计算公式如式(Ⅴ)所示:ot=softmax(Vst)(Ⅴ)式(Ⅴ)中,softmax()是指归一化的激活函数,V是输出单元的权重,隐藏单元第t步的状态st是网络的记忆单元,包含前面所有步的隐藏单元状态,输出单位的输出ot只与当前步的st有关。在实践中,为了降低网络的复杂度,往往st只包含前面若干步而不是所有步的隐藏层状态。在传统神经网络中,每一个网络层的参数是不共享的。而在RNNs中,每输入一步,每一层各自都共享参数U,V,W。其反应者RNNs中的每一步都在做相同的事,只是输入不同,因此大大地降低了网络中需要学习的参数;也就是说,传统神经网络的参数是不共享的,并不是表示对于每个输入有不同的参数,而是将RNN是进行展开,这样变成了多层的网络,如果这是一个多层的传统神经网络,那么xt到st之间的U矩阵与xt+1到st+1之间的U是不同的,而RNNs中的却是一样的,同理对于s与s层之间的W、s层与o层之间的V也是一样的。④将步骤(3)的实际输出ot与预期输出进行比较,产生误差;⑤将步骤(4)得到的误差通过隐藏单元向输入单元逐层反传,修改网络的权重U,V,W和网络参数,直到训练达到预先设定的训练次数30次停止训练。本实施例得到的分类结果与现有的支持向量机(SVM)的分类结果相比,如表1所示:准确率F1分数本实施例方法92.7%92.5%支持向量机(SVM)81.3%80.5%实施例2根据实施例1所述的一种基于RNNs的短信自动安全审核的方法,其区别在于:所述步骤(2),基于HierarchicalSoftmax的CBOW模型提取特征,CBOW模型的结构框图如图2所示,具体包括:最大化基于HierarchicalSoftmax的CBOW模型的优化函数,训练得到每个中文分词的词向量;基于HierarchicalSoftmax的CBOW模型的优化函数如式(Ⅰ)所示:C为语料库,w是指步骤(1)中文分词后得到的任意词;Context(w)是w的上下文。每个词的词向量都是通过最大化这个似然函数训练得到的,当训练收敛以后,意思相似的词会被映射到向量空间的相似的位置。在我们的模型里,通过搜狗语料、微博语料和监狱的短信来训练词向量。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1