一种输出报表的方法及系统与流程
本发明涉及计算机领域,具体涉及输出报表的方法和系统。
背景技术:
京东图书近年的销售突飞猛进,而图书离不开出版。在出版图书的企业中,尤其是一些民族出版社,涉及到出版不同民族文字的图书。在图书出版的过程中,从约稿、编务处理、三审、送审、以及印务、发行的过程中会输出各种形式的报表,其中便涉及到不同民族文字的混排的报表显示。
在中国,汉字不但是汉族的文字,也是全国各个少数民族通用的文字,是在国际活动中代表中国的法定文字。全民族都通用汉语的几个少数民族,很自然地以汉字作为自己的文字,没有与自己语言相一致的文字的少数民族,大多也选择了汉字作为自己的文字。藏文和彝文等语言大部分已经有比较规范的习惯用法,使用范围较广,影响也较大。因此本文以常见的汉文、藏文、彝文作为报表混显设定的示例,选定的字体分别为常用的宋体(simsun.ttc),Microsoft喜马拉雅字体(himalaya.ttf),Microsoft YiBati字体(msyi.ttf)。
在Java领域,通常采用两种技术方案输出报表。
第一种是基于iReport来生成。iReport报表方案是一套集合,使用时用iReport Designer可视化工具来制作模板,定义相应的报表元素,如标题、页面头部、页面内容、页面底部等。最后该工具可生成.jrxml的模板文件或编译后的.jasper文件(模板文件),然后用JavaBean填充模板,最后输出报表。
第二种是基于微软Office word来生成。在word2007及其以上的版本中,后缀为.docx类型的文档的底层是基于XML构成的。在word中录入不同的文字后,如汉字、藏文还有彝文,word会检测文字类型然后指定一种默认的字体并予以显示。查看底层的XML文档后,发现是为每个同类型文字块都会应有到一种字体,默认情况下,如汉字为宋体,藏文为Microsoft Himalaya字体,彝文为Microsoft Yi Baiti字体等。所以在服务端可借助Freemarker或Velocity模板语言根据word的XML文档结构来制作报表模板,最后借用Jacob类库调用word应用程序把模板打开成word文档,最后另存为PDF文档。(先把数据源数据根据XML文档结构构建报表,然后将报表转换为PDF格式
但是这两种方案都有缺点。使用iReport方案的缺点是制作模板时不能动态的应用字体,不能根据不同的文字类型应用不同的字体,因为某些文字需要特定的字体才能显示,所以iReport只能用于输出预先知道内容的报表。使用word方案的缺点是很大程度依赖Office word软件,另外,word通过XML文件定义各种文字类型的输出字体,因此针对一种文字类型,只能以指定字体输出;word方案的另一个缺点是Web服务器不能并发的打开多个word进程来把文档转换成PDF报表。
技术实现要素:
有鉴于此,本发明提供一种输出报表的方法和系统,用于根据报表内容动态指定每种文字类型的输出字体,以解决现有技术中存在的问题。
根据本发明实施例的第一方面,本发明实施例提供一种输出报表的方法,包括:将报表内容中的字符转换为第一编码规则的字符;逐一检测所述第一编码规则的字符;根据检测结果将所述报表内容分割为多个文本块;为所述多个文本块中的每个文本块设定输出字体;以及将所述多个文本块组合成报表输出。
可选地,所述根据检测结果将所述报表内容分割为多个文本块包括:将相邻的属于同一编码范围的字符归属于同一文本块。
可选地,所述将所述多个文本块组合成报表输出包括:将所述多个文本块分别添加到多个段落中;以及按段落输出所述多个文本块。
可选地,所述报表为PDF格式的报表。
可选地,所述第一编码规则为UTF8。
根据本发明实施例的第二方面,本发明实施例提供一种输出报表的系统,包括:转换模块,用于将报表内容中的字符转换为第一编码规则的字符;检测模块,用于逐一检测所述第一编码规则的字符;分割模块,用于根据检测结果将所述报表内容分割为多个文本块;设定模块,用于为所述多个文本块中的每个文本块设定输出字体;输出模块,用于将所述多个文本块组合成报表输出。
可选地,所述分割模块包括:将相邻的属于同一编码范围的字符归属于同一文本块。
可选地,所所述输出模块包括:将所述多个文本块分别添加到多个段落中;以及按段落输出所述多个文本块。
可选地,所述报表为PDF格式的报表。
可选地,所述第一编码规则为UTF8。
本发明实施例提供的输出报表的方法适用于多种文字类型混排的报表输出,通过将不同文字类型的文本块分割出来,并针对每种文字类型的文本块设定字体,最后将文本块组合成报表文档输出。此种输出方法能够根据报表内容动态设定字体类型,保证了多个文字类型混排的报表内容能够正确输出。
附图说明
通过参照以下附图对本发明实施例的描述,本发明的上述以及其它目的、特征和优点将更为清楚,在附图中:
图1是根据本发明实施例的输出报表的方法流程图;
图2是根据本发明实施例的将报表内容分割成多个文本块的示意图;
图3是根据本发明另一实施例的输出报表的方法的流程图;
图4是根据本发明实施例的输出报表的系统的结构图。
具体实施方式
以下基于实施例对本发明进行描述,但是本发明并不仅仅限于这些实施例。在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。为了避免混淆本发明的实质,公知的方法、过程、流程没有详细叙述。另外附图不一定是按比例绘制的。
附图中的流程图、框图图示了本发明实施例的系统、方法、装置的可能的体系框架、功能和操作,流程图和框图上的方框可以代表一个模块、程序段或仅仅是一段代码,所述模块、程序段和代码都是用来实现规定逻辑功能的可执行指令。也应当注意,所述实现规定逻辑功能的可执行指令可以重新组合,从而生成新的模块和程序段。因此附图的方框以及方框顺序只是用来更好的图示实施例的过程和步骤,而不应以此作为对发明本身的限制。
图1是根据本发明实施例的输出报表的方法流程图。所述方法包括以下步骤。
在步骤101中,将报表内容中的字符转换为第一编码规则的字符。
报表内容可以来自关系型数据库或非关系型数据库,从数据库中获取报表内容后,将其转换为第一编码规则的字符以便于后续的检测。报表内容里可以含有多种文字类型,如中文、英文、俄文、藏文、彝文等,所有文字类型可以采用同一编码规则,例如,均采用UTF8格式,或者中文采用GBK2312格式,彝文采用UTF8格式。例如,均转换为UTF8格式字符。
在步骤102中,逐一检测第一编码规则的字符。
在本步骤中,逐一检测转换后的每个字符,以确定每个字符所在的编码范围。第一编码规则为每个文字类型定义了编码范围,例如,UTF8的中文编码范围为0x4E00-0x9FA5,藏文编码范围为0x0F00-0x0FFF,彝文编码范围0xA000-0xA4C6等,判断每个字符所在的编码范围,即能确定每个字符的文字类型。
在步骤103中,根据检测结果将报表内容分割为多个文本块。
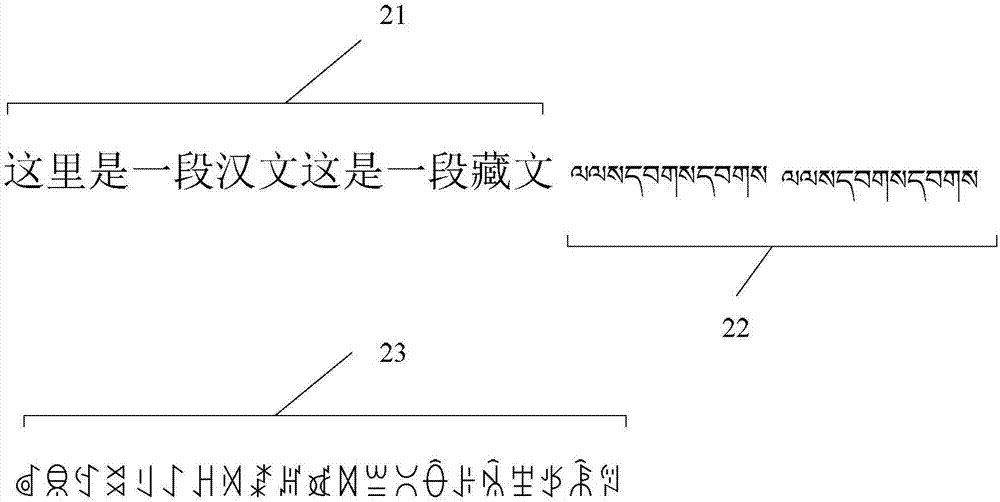
在本步骤中,根据上述的文字类型或编码范围将报表内容分割为多个文本块。如图2所示,将报表内容中分割为汉文的文本块(标记21)、藏文的文本块(标记22)和彝文的文本块(标记23)。也就是说,将相邻的同属于同一个编码范围的字符归属于同一文本块中。
在步骤104中,为多个文本块中的每个文本块设定输出字体。
设定每个文本块在报表输出时的输出字体,例如,如前所述,汉文采用常用的宋体(simsun.ttc),藏文采用Microsoft喜马拉雅字体(himalaya.ttf),彝文采用Microsoft YiBati字体(msyi.ttf)。
在步骤105中,将多个文本块组合成报表输出。
在本步骤中,确定了每个文本块的字体后可以将文本块组合成报表文档输出。在报表输出之前,可以继续定义报表的前景色、背景色、题目、边框、页眉、页脚等特征。
本发明实施例提供的输出报表的方法适用于多种文字类型混排的报表输出,通过将不同文字类型的文本块分割出来,并针对每种文字类型的文本块设定字体,最后将文本块组合成报表文档输出。此种输出方法能够根据报表内容动态设定字体类型,保证了多个文字类型混排的报表内容能够正确输出。
图3是根据本发明另一实施例的输出报表的方法的流程图。所述方法包括步骤301-306。其中,步骤301-304和步骤101-104相同,这里就不再赘述。
在步骤305中,将多个文本块分别添加到多个段落中。
创建多个空的段落,根据报表内容将每个文本块分别归属于不同的段落中。
在步骤306中,按段落输出多个文本块。
多个文本块进行分段设置,将不同的文本块存放在不同的段落中,并按照段落顺序输出文本块,从而使报表符合阅读规范。
在图1的实施例中,报表内容被分割为多个文本块并依次将文本块输出,在图2的实施例中,将每个文本块归属于不同的段落,按照段落输出文本块,从而进一步保证输出的报表符合阅读规范。
下面以JAVA的组件iText为例具体描一个PDF格式的报表的输出过程。
iText是用于生成PDF文档的一个java类库。通过iText不仅可以生成PDF或rtf的文档,而且可以将XML、Html文件转化为PDF文件。iText的安装非常方便,下载iText.jar文件后,只需要在系统的CLASSPATH中加入iText.jar的路径,在程序中就可以使用iText类库了。
iText提供各种API以实现PDF文档的抽象化,例如,iText的API中PdfPTable表示一个表格,PdfPCell表示表格中的单元格,Paragraph表示一个段落,Chunk表示一个文本块,Document表示一个文档。通过组合Paragraph、PdfPCell和Chunk,例如一个Paragraph可以添加多个Chunk,PdfPCell也可以添加Chunk,便可形成一份PDF文档。在iText中,Chunk的创建需要可以指定一种字体,然后赋予相应的字符内容,这样该Chunk就可以以指定的字体呈现在报表中。还可以为PDF文档设置相应的样式,如边框、Margin、背景,最后通过PdfWriter输出一份实际的PDF文档。结合本发明实施例的思想,首先将报表内容中的所有字符转换为指定编码规则的字符,然后检测报表内容的所有字符,如果在某一连续一段字符序列中都是同一编码范围,例如属于中文编码范围0x4E00-0x9FA5,或者藏文编码范围为0x0F00-0x0FFF,或者彝文编码范围0xA000-0xA4C6等,则可以将这段字符序列放在同一个文本块中,从而,通过判断每个字符的编码范围能获得多个文本块,同时构建多个Chunk对象以存储上述的多个文本块,并通过Chunk对象提供的API设定每个文本块的字体。将Chunk对象添加到Paragraph对象中,然后Paragraph对象添加到预先创建的Document对象中,并利用Document对象提供的API输出PDF格式的报表。
图4是根据本发明实施例的输出报表的系统的结构图。所述系统包括转换模块401、检测模块402、分割模块403、设定模块404和输出模块405。
转换模块401将报表内容中的字符转换为第一编码规则的字符。第一编码规则优选的是UTF8,因为UTF8作为通用的编码规则,囊括了目前大多数国家的文字类型,例如,英文,日文,韩文,中文,德文等。
检测模块402逐一检测第一编码规则的字符。检测模块402通过检测每个字符确定该字符所在的编码范围。
分割模块403根据检测结果将报表内容分割为多个文本块。分割模块403根据每个字符的编码范围,将相邻的同属于一个编码范围的字符归属于同一个文本块,从而将报表内容分割为多个文本块。注意,这里同一个段落可能被分割为多个文本块。
设定模块404为多个文本块中的每个文本块设定输出字体。针对分割模块403获得的多个文本块,根据每个文本块的文字类型设定字体,例如,中文设定宋体,彝文设定为Microsoft YiBati字体(msyi.ttf)。
输出模块405将多个文本块组合成报表输出。输出模块405以设定的字体将多个文本块组合成报表,并可同时规定了报表的排版格式。生成PDF报表后,可通过存储在服务器上,可以根据实际场景需求,输出到客户的浏览器中显示或作单独保存。
进一步地,在上述输出报表的系统中,输出模块405创建多个段落,将多个文本块分别添加到多个段落中,并按照段落输出多个文本块。
本发明实施例提供的输出报表的方法和系统,能够输出多个文字类型的报表内容,同时可根据请求的数量并发的生成报表,解决了iReport组件不能根据不同的文字类型应用不同的字体以及word不能并发的问题。
在一个实施场景中,本发明实施例提供的方法和系统应用于针对涉及到多民族文字进行信息处理或加工的企业、出版社,为其输出多民族文字混显的报表,例如,输出汉文、藏文、彝文等文字内容组合的报表,从而解决该场景下的用户需求。
系统的各个模块或模块可以通过硬件、固件或软件实现。软件例如包括采用JAVA、C/C++/C#、SQL等各种编程语言形成的编码程序。虽然在方法以及方法图例中给出本发明实施例的步骤以及步骤的顺序,但是所述步骤实现规定的逻辑功能的可执行指令可以重新组合,从而生成新的步骤。所述步骤的顺序也不应该仅仅局限于所述方法以及方法图例中的步骤顺序,可以根据功能的需要随时进行调整。例如将其中的某些步骤并行或按照相反顺序执行。
根据本发明的系统和方法可以部署在单个或多个服务器上。例如,可以将不同的模块分别部署在不同的服务器上,形成专用服务器。或者,可以在多个服务器上分布式部署相同的功能模块、模块或系统,以减轻负载压力。所述服务器包括但不限于在同一个局域网以及通过Internet连接的多个PC机、PC服务器、刀片机、超级计算机等。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!