一种融入时间和地理位置信息的地点推荐方法与流程
本发明是一种融入时间和地点位置信息的地点推荐方法,属于用户推荐系统
技术领域:
。
背景技术:
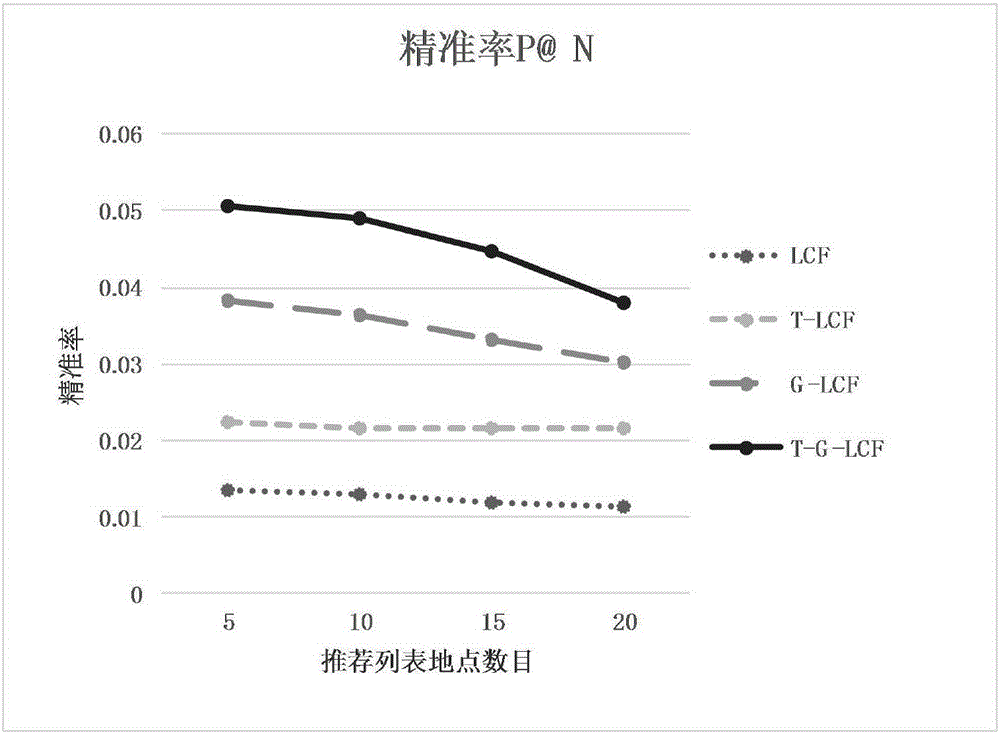
:近年来,随着新兴电子商务服务兴起,互联网信息爆炸式增长,信息种类多样复杂,用户具有更多的选择。但是,由于信息过载,降低了用户的满意度,用户从纷繁复杂的物品(产品和服务)中选择自己感兴趣的物品变得越来越困难。推荐系统是一种解决这种信息过载问题的有效工具。推荐系统一方面能够帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对它感兴趣的用户面前,使生产者和消费者达到共赢效果。协同过滤(CollaborativeFiltering)技术是个性化推荐应用最早和最为成功的技术之一,在地点推荐中,协同过滤的方法是基于用户在地点的签到记录来进行个性化推荐。地点推荐中,协同过滤算法的核心思想可以分为两部分:首先,利用用户的历史签到信息计算用户或地点之间的相似性;然后利用与目标用户相似性较高的邻居用户在特定地点的签到次数,或者利用与目标用户已签到地点相似性较高的特定地点,来预测目标用户对特定地点的喜好程度。最后,根据这一喜好程度来对目标用户进行推荐。目前,有学者发现,与传统的电子商务环境下的个性化推荐不同,在移动推荐环境下,用户和地点的地理位置直接影响个性化地点推荐的结果,用户与地点的距离越近,用户访问该地点的概率就越大,反之,概率越小,并将地理位置信息融入协同过滤中,提高了地点推荐的精度。现有理论虽然可以为个性化地点推荐系统的构建提供理论基础和实践指导,但是仍然存在诸多缺陷与不足:(1)地点推荐中,协同过滤算法只利用了用户在地点的签到次数来进行推荐,但由于用户签到数据稀疏性问题,推荐精度较差;(2)现有理论中计算基于地理位置信息下用户到未签到地点的概率时,无差别地利用了用户的所有已签到地点信息,这样一方面会增加计算的复杂度,另一方面,如果用户可能偶然到一些偏远地点并有低频次签到,但这些低频率的地点并不是用户经常访问的地点,无差别地考虑这些地点会影响概率计算的结果,降低推荐结果的精度。技术实现要素:本发明为了解决现有技术所存在的不足之处,提出融入时间和地理位置信息的地点推荐方法,以期能在综合考虑时间和地理位置因素的条件下实现地点推荐,从而提高推荐的精准率和召回率。为了达到上述目的,本发明所采用的技术方案为:本发明一种融入时间和地理位置信息的地点推荐方法的特点是按以下步骤进行:步骤1:获取用户地点签到数据,所述用户地点签到数据的属性包括:用户、地点、地点经度、地点纬度和用户签到时间段;令所述用户地点签到数据中的所有用户记为U={U1,...,Uu,…U|U|},所有地点记为L={L1,...,Ll,...,L|L|},所有用户签到时间段记为T={1,...,t,...,|T|};其中|U|为用户的总个数,Uu表示第u个用户;|L|为地点的总个数,Ll表示第l个地点;并有,Ll={latl,lonl},latl表示第l个地点Ll的经度,lonl表示第l个地点Ll纬度;|T|为时间的总个数,t为第t个用户签到时间段;定义第t个时间段内第u个用户Uu在第l个地点Ll的签到次数为若第t个时间段内第u个用户Uu在第l个地点Ll未签到,则令否则令μ表示第t个时间段内第u个用户Uu在第l个地点Ll的签到总次数;从而得到第u个用户Uu在所有已签到地点的集合和第u个用户Uu在所有未签到地点的集合,并令Lu,a表示第u个用户Uu的第a个已签到地点;令Lu,b表示第u个用户Uu的第b个未签到地点;步骤2:计算基于地理位置因素的用户到每个未签到地点的概率;步骤2.1:利用式(1)计算第u个用户Uu在第a个已签到地点Lu,a的签到总次数Cu,a:步骤2.2:利用多中心聚类算法对第u个用户Uu的所有已签到地点进行聚类,得到K个聚类结果,其中,第k个聚类结果包括:第u个用户Uu的聚类中心,记为Cenu={cenu,k};cenu,k表示第u个用户Uu的第k个聚类中心,且第u个用户Uu在第k个聚类中心cenu,k所在类别的签到总次数记为allu,k;1≤k≤K;步骤2.3:根据聚类结果计算用户到未签到地点的概率;步骤2.3.1:计算第u个用户的第b个未签到地点Lu,b和第k个聚类中心之间的距离步骤2.3.2:利用式(2)计算在第k个聚类结果条件下,第u个用户Uu到第b个未签到地点Lu,b的条件概率P(Lu,b|cenu,k):步骤2.3.3:利用式(3)计算在所有聚类结果条件下,第u个用户Uu到第b个未签到地点Lu,b的概率Pro(Uu,Lu,b)步骤3:计算时间感知下地点之间的相似性:步骤3.1:利用式(4)计算第i个时间段和第j个时间段之间的间距Di,j:步骤3.2:对于第l个地点Ll,利用式(5)计算第i个时间段和第j个时间段之间的余弦相似度cosl(i,j):步骤3.3:结合时间段之间的间距和时间段之间的余弦相似度,利用式(6)计算第i个时间段和第j个时间段之间的相似性sim(i,j):式(6)中,λ为调整参数;步骤3.4:根据各时间段之间的相似性,利用式(7)对第t个时间段内第u个用户Uu在第b个未签到地点Lu,b的签到次数进行填补,得到填补后的签到次数式(7)中,h表示所有用户签到时间段T中,除第t个时间段之外的任一时间段;对于第a个已签到的地点Lu,a,令赋值给步骤3.5:根据填补后的签到数据,利用式(8)计算时间感知下第m个地点Lm和第n个地点Ln之间的相似性sim(Lm,Ln),1≤m,n≤|L|:步骤4:综合考虑时间和地理位置信息,预测用户在未签到地点的签到次数;步骤4.1:设定每个地点的邻近地点数目K;对于第u个用户Uu的第b个未签到地点Lu,b,根据地点Lu,b与其它地点的时间感知下的相似性,将相似性排名前K位的地点依次放入地点Lu,b的邻近集合NLu,b中,得到邻近集合表示第u个用户Uu在第b个未签到地点Lu,b的第d个邻近地点,令第u个用户Uu在第d个邻近地点的签到次数为步骤4.2:利用式(9)预测第u个用户Uu在第b个未签到地点Lu,b的可能签到次数Pre(Uu,Lu,b);步骤5:设定用户推荐的地点数目为N;将第u个用户Uu在所有未签到地点的可能签到次数进行降序排序,并选取排名前N个地点推荐给第u个用户Uu。与已有技术相比,本发明的有益效果体现在:1、本发明综合考虑了时间和地理位置因素,将时间信息和地理位置信息融入基于地点的推荐算法中,相对于传统基于地点的推荐算法,具有较高的准确率和召回率;2、本发明将时间因素融入地点推荐中,将一天划分成不同的时间段,考虑用户在不同时间段的签到来计算地点之间的相似性。与传统协同过滤方法相比,寻找出的邻近地点相似度更高;3、本发明基于用户已签到数据,利用时间段之间的相似性对用户的签到数据进行了填补,有助于缓解用户签到数据的稀疏性问题;4、本发明利用了多中心聚类方法寻找用户活动区域,去掉了一些低频次的地点聚类集合,相对于现有考虑所有已签到地点的方法,减少了不重要地点对推荐结果的影响;5、本发明在计算基于地理位置因素下用户到未签到地点的概率时,不仅考虑了未签到地点与各聚类中心的距离,还融入了用户在各个活跃区域的签到频次,相对于现有方法,计算结果更能反映用户对未签到地点的地理位置偏好;6、本发明可用于餐馆、旅馆和旅游地点等关于地点推荐的个性化推荐系统,可以在电脑和手机的网页、App等平台进行使用,应用范围广泛。附图说明图1为本发明结合地点和时间因素推荐的流程图;图2为本发明实验精准率结果;图3为本发明实验召回率结果;图4为本发明实验F值结果。具体实施方式本发明方法首先利用获取的用户地点签到数据,对用户的历史签到地点进行多中心聚类,得到用户活跃区域,利用用户活跃区域中心与各未签到地点之间的距离以及用户在活跃区域的签到频次,计算用户去每个未签到地点的概率;再计算各个时间段之间的相似性,利用时间段之间的相似性对用户签到数据进行填补,并根据填补后的签到数据计算时间感知下的地点相似性;再结合用户到未签到地点的概率与时间感知下的地点相似性,预测用户在未签到地点的签到次数,并根据预测值,选取签到次数排名前N个进行推荐,生成最终的推荐结果;最后,在标准数据集上与基础算法进行比较。具体的说,如图1所示,包括以下步骤:步骤1:获取用户地点签到数据,所述用户地点签到数据的属性包括:用户、地点、地点经度、地点纬度和用户签到时间段;令所述用户地点签到数据中的所有用户记为U={U1,...,Uu,...U|U|},所有地点记为L={L1,…,Ll,…,L|L|},所有用户签到时间段记为T={1,…,t,…,|T|};其中|U|为用户的总个数,Uu表示第u个用户;|L|为地点的总个数,Ll表示第l个地点;并有,Ll={latl,lonl},latl表示第l个地点Ll的经度,lonl表示第l个地点Ll纬度;|T|为时间的总个数,t为第t个用户签到时间段;定义第t个时间段内第u个用户Uu在第l个地点Ll的签到次数为若第t个时间段内第u个用户Uu在第l个地点Ll未签到,则令否则令μ表示第t个时间段内第u个用户Uu在第l个地点Ll的签到总次数;从而得到第u个用户Uu在所有已签到地点的集合和第u个用户Uu在所有未签到地点的集合,并令Lu,a表示第u个用户Uu的第a个已签到地点;令Lu,b表示第u个用户Uu的第b个未签到地点;本实施例中,使用的是Foursquare公开数据集,该数据集中有2321个用户,5596个地点,194108个签到记录。且将时间划分为24个时间段,例如:第一个时间段为0:00到0:59,第二个时间段为1:00到1:59等;数据集表结构如表一、表二所示:表一表二地点经度纬度L1lat1lon1………Lllatllonl………L|L|lat|L|lon|L|步骤2:计算基于地理位置因素的用户到每个未签到地点的概率;步骤2.1:利用式(1)计算第u个用户Uu在第a个已签到地点Lu,a的签到总次数Cu,a:步骤2.2:利用多中心聚类算法对第u个用户Uu的所有已签到地点进行聚类,得到K个聚类结果,其中,第k个聚类结果包括:第u个用户Uu的聚类中心,记为Cenu={cenu,k};cenu,k表示第u个用户Uu的第k个聚类中心,且第u个用户Uu在第k个聚类中心cenu,k所在类别的签到总次数记为allu,k;1≤k≤K;多中心聚类算法具体方法可以参考论文《FusedMatrixFactorizationwithGeographicalandSocialInfluenceinLocation-BasedSocialNetworks》,其具体的实施步骤如下:1)对于第u个用户Uu,按已签到地点的签到次数,将已签到地点降序排列,放入第u个用户Uu的签到地点集合CLu中;2)选取集合CLu中的第一个地点,将它作为当前聚类的聚类中心,设定距离阈值,计算集合CLu中其他地点与聚类重心的距离,如果该距离小于距离阈值,则将它放入当前聚类集合中,并将它从集合CLu中移除。直到计算完集合CLu中所有地点;3)如果集合CLu为空,则转到下一步;否则,返回到2),进行下次聚类;4)设定签到比例阈值,对于用户Uu的所有聚类集合,若存在聚类集合,使得用户Uu在该集合中的地点的签到总次数与用户Uu的总签到次数的比值小于比例阈值,则去掉该聚类集合。最后得到的即为最终的聚类集合;本实施例中,距离阈值取75Km,比例阈值取0.05;步骤2.3:根据聚类结果计算用户到未签到地点的概率;步骤2.3.1:计算第u个用户的第b个未签到地点Lu,b和第k个聚类中心之间的距离计算距离的公式参考现有的根据两地点的经度和纬度计算公式。本实施例中使用的公式为:步骤2.3.2:利用式(2)计算在第k个聚类结果条件下,第u个用户Uu到第b个未签到地点Lu,b的条件概率P(Lu,b|cenu,k):步骤2.3.3:利用式(3)在所有聚类结果条件下,计算在第u个用户Uu到第b个未签到地点Lu,b的概率Pro(Uu,Lu,b)步骤3:计算时间感知下地点之间的相似性:步骤3.1:利用式(4)计算第i个时间段和第j个时间段之间的间距Di,j:本实施例中,将一天划分为24个时间段,|T|为24,例如,计算第1个时间段(0:00到0:59)和第15个时间段(14:00到)之间的间距,由于|15-1|=13>12,则D1,15=24-13=11;步骤3.2:对于第l个地点Ll,利用式(5)计算第i个时间段和第j个时间段之间的余弦相似度cosl(i,j):步骤3.3:结合时间段之间的间距和时间段之间的余弦相似度,利用式(6)计算第i个时间段和第j个时间段之间的相似性sim(i,j):式(6)中,λ为调整参数;本实施例中,λ取1;步骤3.4:根据各时间段之间的相似性,利用式(7)对第t个时间段内第u个用户Uu在第b个未签到地点Lu,b的签到次数进行填补,得到填补后的签到次数式(7)中,h表示所有用户签到时间段T中,除第t个时间段之外的任一时间段;对于第a个已签到的地点Lu,a,令赋值给步骤3.5:根据填补后的签到数据,利用式(8)计算时间感知下第m个地点Lm和第n个地点Ln之间的相似性sim(Lm,Ln),1≤m,n≤|L|:步骤4:综合考虑时间和地理位置信息,预测用户在未签到地点的签到次数;步骤4.1:设定每个地点的邻近地点数目K,一方面K取值较小邻近地点数目较少,会降低了预测的准确性,但计算的复杂度较小;另一方面K取值较大时,地点之间的相似性不高,亦会降低算法预测的准确性,且计算的复杂度高,选择合理的K值,有利于得到较好的推荐结果,本实施例中K取[10,30]之间的值;对于第u个用户Uu的第b个未签到地点Lu,b,根据地点Lu,b与其它地点的时间感知下的相似性,将相似性排名前K位的地点依次放入地点Lu,b的邻近集合NLu,b中,得到邻近集合表示第u个用户Uu在第b个未签到地点Lu,b的第d个邻近地点,令第u个用户Uu在第d个邻近地点的签到次数为步骤4.2:利用式(9)预测第u个用户Uu在第b个未签到地点Lu,b的可能签到次数Pre(Uu,Lu,b);步骤5:设定用户推荐的地点数目为N,N表示推荐个数,可根据具体推荐场景设定;将第u个用户Uu在所有未签到地点的可能签到次数进行降序排序,并选取排名前N个地点推荐给第u个用户Uu。针对本发明方法进行实验论证,具体包括:1)准备标准数据集本发明使用Foursquare数据集作为标准数据集验证一种融入时间和地理位置信息的地点推荐方法的有效性,Foursquare数据集是应用广泛的地点推荐数据集。在Foursquare数据集中,用户对自己到过的地点进行签到,数据集中包含2321位独立用户,5596个独立地点,194,108个签到记录。训练集和测试集按80%/20%的规则进行分割,即随机选择155286个评分作为训练集,38822个评分作为测试集。2)评价指标分别采用精准率P@N、召回率R@N和F值F@N作为本实施例的评价指标,精准率、召回率和F值越高,表示推荐结果越好。用公式(10)、(11)和(12)分别计算用精准率、召回率和F值:其中,Tu为测试集中第u个用户Uu的地点列表,Ru为推荐给第u个用户Uu的地点列表;3)在标准数据集上进行实验为了验证本发明所提方法的有效性,以及证明同时融入时间和地理位置信息比只融入时间或地理位置信息的效果好,本文在Foursquare数据集进行五组交叉试验,对照算法选取了传统的基于地点的协同过滤算法LCF、融入时间信息的基于地点的协同过滤算法T-LCF和融入地理位置信息的基于地点的协同过滤算法G-LCF。其中,T-LCF是将本发明特征步骤里面的第三步与LCF结合得到的算法,相对于LCF,T-LCF可以找到更相近的邻近地点;G-LCF并将本发明特征步骤里面第二步与LCF结合得到的算法。实验得到的准确率、召回率和F值分别取平均值。实验结果如图2、图3、图4所示。其中,T-G-LCF为本发明提出的方法,横坐标为给每个用户推荐的地点数目N。本发明综合考虑了时间和地理位置信息,如图2、图3、图4所示,随着推荐地点数由5增加到20,四种算法的精确度会降低,召回率上升,F值先上升再下降,但本发明提出的方法的精准率、召回率与F值始终高于对照算法,从实验结果中可以看出本发明所提出的方法明显优于对照算法,且同时融入时间和地理位置信息的效果比只融入时间或地点位置信息的效果好。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1