一种并行数据清洗系统的制作方法
本发明属于数据清洗领域,尤其涉及一种并行数据清洗系统。
背景技术:
互联网发展至今天,各大信息化领域企业的数据规模急剧扩大,有些甚至达到了PB级,用户和机器制造的越来越多的业务数据对I T系统带来了更大的挑战,数据的存储以及在未来访问和使用这些数据已成为难点,想从海量的数据里得到对自己有用的信息也变得倍加艰难。此外,由于不同的业务数据对信息的表述方式不尽相同,从而给信息整合带来了一定的困难。另外,同一条业务数据可能会出现不同的表现形式,其会产生很多重复数据,因此,针对来自不同数据源的、表述形式不一样的数据进行重复数据的清洗是非常有必要的。
基于上述诸多问题,现在亟需一种新的数据清洗系统,能够并行的作数据清洗,提高清洗速度,具备海量数据清洗能力,同时能够有效率的进行数据清洗涉及的各项操作。
技术实现要素:
为了解决现有技术中的上述问题,本发明提出了一种并行数据清洗系统,其特征在于,该系统包括多个数据源,多个数据采集装置,缓存服务器,数据清洗装置,数据库,业务机;其中每个数据采集装置用于对多个数据源进行数据采集,并将采集到的数据集合传送到缓存服务器中,数据清洗装置从缓存服务器获取待处理数据,数据清洗装置将清洗后的数据保存到数据库中,不同的业务机从数据库中获取所需的清洗后数据;
数据源散落于互联网中,数据采集装置针对数据源的采集策略通过互联网进行数据获取,每个数据采集装置用于固定的多个数据源的数据采集,多个数据采集装置可以并行采集,从而加快数据采集到效率,数据采集装置通过网络连接到数据清洗装置,从而可以通过缓存服务器与数据清洗装置进行通信,并接受其管理;特定数据采集装置采集到的数据除了需要标注数据源外,还需要标注采集单元的编号,数据清洗装置对该采集单元的采集质量进行评定,并基于该采集编号进行评定反馈;
采集后的数据被保存在缓存服务器中,数据清洗装置可以主动或者基于通知消息异步的进行数据获取,缓存服务器可以用于对采集到的原始数据进行保存,从而对待清洗数据起到一个备份的作用,在清洗发生错误或者产生清洗数据丢失时,数据清洗装置可以再次从缓存服务器获取原始数据,通过缓存服务器的设置减轻了数据清洗装置的存储压力,使得并行的数据采集成为可能;
数据清洗装置用于基于当前数据清洗规则对获取的待清洗数据进行清洗处理,管理用户可以登录数据清洗装置进行清洗规则的设置和修改,从而实现针对特定管理用户的个性化定制清洗;数据清洗装置通过网络对系统中的多个数据采集装置,缓存服务器,数据库进行管理;
数据库用于对清洗后的数据进行保存和管理,业务机可以主动的或者基于通知异步的从数据库中获取所需数据;业务机进行数据获取需要进行鉴权,从而保证了数据的安全性。
进一步的,数据清洗装置包括控制装置、本地缓存和多个处理装置。
进一步的,多个处理装置可以并行进行数据清洗,从而提高了清洗效率。
进一步的,控制装置用于进行任务分配,管理处理装置,任务调度,用户交互,业务机交互。
进一步的,系统包括多个业务机,不同的业务机面向不同的业务需求和不同的用户、面向相同业务需求的不同用户、或面向相同的业务需求和相同的用户。
进一步的,多个业务机可以进行并行的数据获取和任务下达。
进一步的,每个数据采集装置倍分配一个独立的标识。
进一步的,业务机基于自身的设备编号进行鉴权、或基于在网络中的地址进行鉴权、或基于两者的结合进行鉴权。
本发明的有益效果包括:能够并行的作数据清洗,提高了清洗速度,具备了海量数据清洗能力,通过提高清洗装置的处理能力,可以进一步的提升清洗的效率,能够同时为多个业务机和/或多个用户服务,满足不同用户不同的业务需求。
【附图说明】
此处所说明的附图是用来提供对本发明的进一步理解,构成本申请的一部分,但并不构成对本发明的不当限定,在附图中:
图1是本发明数据清洗装置结构图。
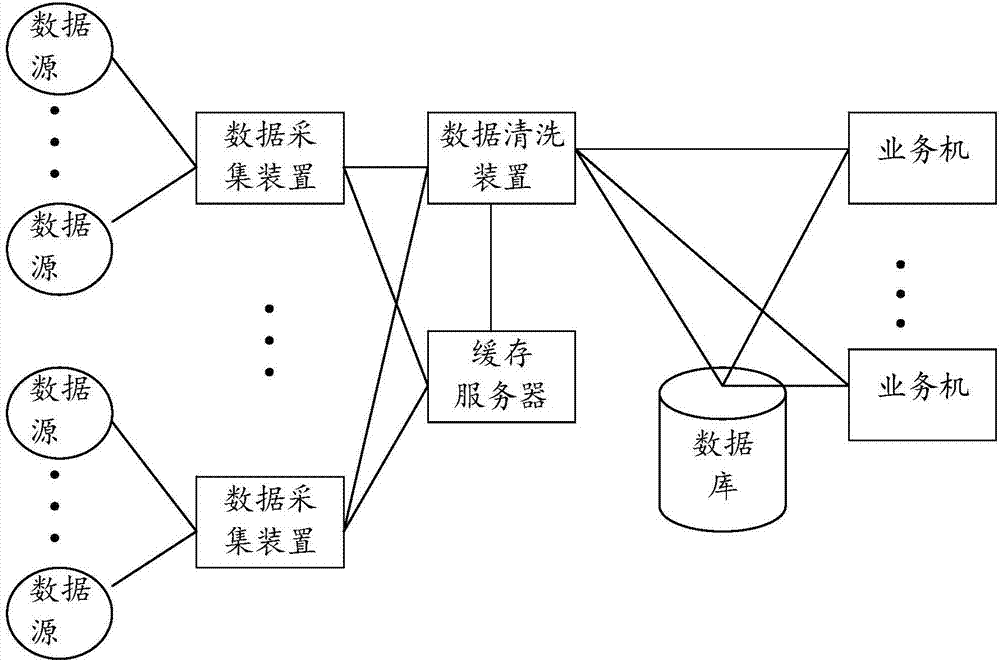
图2是本发明并行数据清洗系统结构图。
【具体实施方式】
下面将结合附图以及具体实施例来详细说明本发明,其中的示意性实施例以及说明仅用来解释本发明,但并不作为对本发明的限定。
参见附图1,是本发明所应用的一种并行数据清洗系统,该系统包括多数据源,多个数据采集装置,缓存服务器,数据清洗装置,数据库,业务机,其中每个数据采集装置用于对多个数据源进行数据采集,并将采集到的数据集合传送到缓存服务器中,数据清洗装置从缓存服务器获取待处理数据,数据清洗装置将清洗后的数据保存到数据库中,不同的业务机从数据库中获取所需的清洗后数据;
数据清洗装置包括控制装置、本地缓存和多个处理装置,多个处理装置可以并行进行数据清洗,从而提高了清洗效率;控制装置用于进行任务分配,管理处理装置,任务调度,用户交互,业务机交互等;
数据源散落于互联网中,数据采集装置针对数据源的采集策略通过互联网进行数据获取,每个数据采集装置用于固定的多个数据源的数据采集,多个数据采集装置可以并行采集,从而加快数据采集到效率,数据采集装置通过网络连接到数据清洗装置,从而可以通过缓存服务器与数据清洗装置进行通信,并接受其管理。特定数据采集装置采集到的数据除了需要标注数据源外,还需要标注采集单元的编号,数据清洗装置对该采集单元的采集质量进行评定,并基于该采集编号进行评定反馈;
采集后的数据被保存在缓存服务器中,数据清洗装置可以主动或者基于通知消息异步的进行数据获取,缓存服务器可以用于对采集到的原始数据进行保存,从而起到一个备份的作用,在清洗发生错误或者产生清洗数据丢失时,数据清洗装置可以再次从缓存服务器获取原始数据,通过缓存服务器的设置减轻了数据清洗装置的存储压力,使得并行的数据采集成为可能;
数据清洗装置用于基于当前数据清洗规则对获取的待清洗数据进行清洗处理,管理用户可以登录数据清洗装置进行清洗规则的设置和修改,从而实现针对特定管理用户的个性化定制清洗;数据清洗装置通过网络对系统中的多个数据采集装置,缓存服务器,数据库进行管理;
数据库用于对清洗后的数据进行保存和管理,业务机可以主动的或者基于通知异步的从数据库中获取所需数据;业务机进行数据获取需要进行鉴权,从而保证了数据的安全性;
基于上述系统,下面对本发明的一种并行数据清洗方法进行详细说明。
(1)数据采集装置基于针对数据源的采集策略通过互联网进行数据获取,为采集到的数据设置来源属性和时间戳,将数据集合关联于本次采集的序列编号保存到缓存服务器中相应的位置,然后发送采集完成指令给数据清洗装置,采集完成指令中携带有本次采集的序列编号;
由于不同的数据源其数据的产生都有一定的规律性,其产生的数据都有一定的特点;同一个数据采集装置并行负责多个数据源的数据采集,不能对多个数据源进行并行的实时采集,这样采集效率会很低,数据清洗装置进行数据获取和处理的效率也会很低,需要结合不同数据源的数据产生规律来更新针对该数据源的数据采集策略;针对不同的数据源其采集策略是不同的;针对数据源的采集策略可以设置为:为不同的数据源设置不同的数据采集周期;还可设置为,通过监控获取针对数据源的数据产生高峰时间段,在高峰时间段过去后进行数据采集;还可设置为:数据源在满足预设条件后,进行主动的数据推送,预设条件是:在数据量达到预设值后,或预设的时间周期达到后等;
(2)缓存服务器保存来自不同数据源的数据,并基于数据清洗装置的请求将特定数据采集装置采集的匹配所请求序列编号的数据集合发送给数据清洗装置;缓存服务器中为每个数据采集装置分配独立的存储区域,同一数据采集装置采集的数据集合按照采集序列编号的顺序保存在同一存储区域中;在数据采集装置对其对应存储区域进行存储时,如果该存储区域用尽,则判断位于存储区域头部的数据集合对应的序列编码是否已经无效,如果是,则直接从该头部区域开始存储,覆盖该无效序列编码对应的数据集合,如果否,则向缓存服务器申请临时存储区域进行存储,在申请临时存储区域失败的情况下,暂停针对当次序列编号的数据集合的存储;
优选的:当序列编码对应的数据集合过了保留时间期限后则标记为无效;
优选的:序列编号随着采集次数的增加而增加;
优选的:该临时存储区域在物理上邻接该存储区域;
(3)数据清洗装置接收来自于缓存服务器的数据集合并将该数据集合存放到本地缓存中;在本地缓存中数据为空的时候,数据清洗装置向缓存服务器发送数据获取请求;请求时携带所请求数据集合的序列编号,该请求的序列编号大于已处理的数据集合对应的序列编号;
优选的:数据清洗装置中包含多个并行处理设备,多个并行处理设备可以并行的对多个采集单元采集的数据集合进行处理,也可以同时处理同一采集单元采集的数据集合;
数据清洗装置可以一次性获取多个序列编号的数据集合,并同时对该多个序列编号的数据集合进行处理;
(4)数据清洗装置获取当前待处理的数据集合的数据签名Sig,将该数据签名Sig和历史数据签名表作对比,如果该数据签名已经保存于历史数据签名表中,则表示该数据集合已经被处理过,丢弃该数据集合,继续下一数据集合的处理;
当数据集合处理完毕后,将该数据集合的数据签名保存到历史数据签名表中;
数据签名基于该数据集合的数据值获取,可以采用常见的签名算法,此处不再详述;
(5)数据清洗装置对数据集合中的所有数据进行格式内容的标准化处理;由于不同的业务机可能有不同的格式要求,需要针对不同的业务机基于不同的标准化规则进行数据的标准化;如果标准化过程中发现字段值错误,则判断是不是发生字段值错位,如果是,则将字段值存放到正确的字段中;
数据格式内容的不一致和输入端有关,在整合多来源数据时也有可能遇到,将其处理成一致的某种格式即可;但由于不同的业务机对数据格式的要求可能不同,允许业务机设置自己要求的标准化规则;
检查每条数据记录,如果一条数据记录中的某个数据值是正确的,但是其格式不正确,则根据业务机要求的标准化规则中针对数据值对应的字段的标准化要求对该字段值进行修改;例如:日期填写格式不正确,民族填写方式不符合要求等。
如果一条数据记录中的某个字段值是错误的,不能进行标准化,通过错误字段值的重填,可以最快速的做数据记录的更改,同时这种更改的可靠性也是比较高的;例如:姓名写了性别,身份证号写了手机号等等,均属这种问题;当一个数据记录中的一个字段值和其字段不符时,确定字段值是错误的,确定一条记录中的所有错误字段值,针对每个错误字段值,遍历该数据记录中的其它错误字段值对应的字段,如果该个错误字段值满足该其它错误字段值对应的字段中的一个字段要求,则将该个错误字段值填写到该一个字段中,将该一个字段中的字段值回写到该该个错误字段值对应的字段中,直到该一条数据记录中的每个错误字段值均处理完毕;
(6)数据清洗装置去除数据记录中存在的明显不合理字段值和一条数据记录中存在明显矛盾的字段值;具体的:遍历所有的数据字段值,根据数据字段的取值范围确定明显不合理字段值,将该不合理字段值删除;删除后该字段的字段值设置为缺失值;对于一条数据记录中存在明显的矛盾的一对字段值,根据一个字段值对另一字段值进行修改;
优选的:根据关键字段值对另一字段值做修改;例如:根据身份证字段值对年龄字段值作修改;关键字段值可以有数据清洗装置设置或者由用户设置;例如:设置身份证号码、手机号码、姓名字段为关键字段;
例如:有人填表时候瞎填,年龄200岁,年收入100000万,这些值都可以明确的判定为不合理值;有些字段是可以互相验证的,如:身份证号是1101031980XXXXXXXX,然后年龄填18岁,这明显是矛盾的;
(7)数据清洗装置对数据集合进行缺失补全;具体的:数据清洗装置对数据集合中的所有数据记录做遍历,找出其中存在字段缺失的数据记录,针对存在字段缺失的数据记录先进行计算补全,对于经过计算补全后仍然存在字段缺失的数据记录,将其保存在补全缓存中;对于补全缓存中的每条数据记录,根据当前数据记录中的关键字段值到本地缓存中进行全部数据集合的查找,根据查找到的数据记录对当前数据记录中的缺失字段进行补全,如果查找到多个匹配的数据字段,则根据时间戳的先后选择数据记录进行补全;如果在本地缓存中没有找到匹配的数据记录,则根据将该关键字段值发送到缓存服务器中,缓存服务器接收该关键数据字段值并查找匹配的数据记录,将匹配的数据记录发送给数据清洗装置用于对当前数据记录进行补全;如果在缓存服务器中没有找到匹配的数据记录,在允许人工补全的情况下,将该数据记录发送给业务机进行人工补全;如果不允许人工补全,判断该当前数据记录中字段值的缺失率,如果缺失率大于第一缺失阈值,则将该条数据记录做删除处理,同时更新数据删除计数值,如果缺失率小于等于第一缺失阈值,则对缺失字段填充默认字段值;
例如:对于生日字段,可以通过身份证号码字段进行计算补全;还可以当前数据记录中的所有数据记录的该字段值的均值、中位数、众数等填充缺失值;
优选的:关键字段值可以为一个或者多个,关键字段值可以由数据清洗装置、数据采集单元或用户来设置;
优选的:数据清洗装置可以将关键字段值发送到一个或者多个缓存服务器中进行查找;
优选的:将所有需要进行人工补全的数据集合统一发送到业务机进行人工补全;
(8)数据清洗装置找出相似重复的数据以便去重;具体的:数据清洗装置计算两条数据记录之间的相似度,如果相似度S小于第一相似度阈值TS,则认为该两条数据记录是重复数据,根据该两条数据记录的置信度B选择一条数据记录进行删除;采用公式(1)计算两条数据记录之间的相似度;
其中,第一相似度阈值TS可以由不同的用户根据需求来设置;
B=w1×(当前时间-数据记录获取时间)+w2×数据来源置信度+w3*(1-字段值缺失率) 公式(2)
其中,数据源的置信度可以根据该数据源历史清洗处理中问题数据记录比率来设置;问题数据记录比率是指同一数据源中经过(5)~(8)中任一步骤处理的数据记录数目占总的数据记录的数目的比值;字段值缺失率是指该条数据记录中存在缺失的字段占总字段数的比率;w1~w3为权重值,由数据清洗装置来预设;
优选的,删除置信度较低的一条数据记录;
(9)在从一业务机所要求的数据源获取的数据集合均处理完毕后,将处理后的数据集合保存到数据库中,生成异常数据报告,并将该处理后的数据集合的保存位置以及异常数据报告发送给该业务机;
异常数据报告中包括所处理的数据集合及其获取数据源,数据采集装置的采集时间,被丢弃的数据集合及其丢弃原因,明显不合理和明显矛盾的数据记录条数,缺失补全的数据记录条数,标准化处理的数据记录条数,重复删除的数据记录条数,总的数据字段缺失率等;
(10)业务机访问数据库获取所需数据;数据库对业务机身份进行验证,当验证通过后,允许业务机基于获取的保存位置进行处理后的数据集合的获取;
该并行数据清洗方法还包括如下步骤:
(11)在数据处理过程中,数据清洗系统支持增量数据清洗导入;具体的:在数据处理过程中,如果业务机下达增量数据清洗导入的消息,数据清洗装置向数据采集装置发送增量数据获取的请求,数据采集装置将增量数据发送到数据清洗装置,数据清洗装置将该增量数据保存到本地缓存中最后一数据集合后,等待数据清洗装置对该增量数据的处理;如果数据处理已经完成,业务机下达增量数据清洗导入的消息,数据清洗装置向数据采集装置发送增量数据获取的请求,数据采集装置将增量数据发送到数据清洗装置,数据清洗装置将该增量数据保存到本地缓存中,针对该增量数据执行步骤(4)~(8)的一个或者多个的处理;处理完毕后将该处理后的数据集合发送到数据库中,并通知下达消息的业务机获取增量数据处理结果,同时将该处理后的数据集合的保存位置以及针对该增量数据集合处理的异常数据报告发送给该业务机;
(12)数据清洗系统支持大数据文件的清洗导入;用户可以直接将大数据文件发送给数据清洗装置,业务机也可以直接向数据清洗装置发送大数据文件,数据清洗装置在接收到大数据文件后,将文件内的数据记录保存到本地缓存中,执行步骤(4)~(8)中的一个或者多个,并将处理结果发送给用户或者业务机;
(13)数据清洗系统支持自定义数据的清洗规则;用户可以通过数据清洗装置设置或修改清洗规则,还可以通过业务机下发数据清洗规则;数据清洗装置按照用户设置的规则对目标数据集合进行清洗;通过清洗规则的设置不仅可以提供用户所需的标准化格式,还可以设置清洗的深度,清洗过程中的各项阈值,清洗必选或跳过的步骤,是否允许人工补全等;设置深度清洗时,清洗规则较为严格,可以设置较高的阈值要求,并完成完整的清洗步骤等;而对于宽松的清洗规则,则对应于浅度清洗,设置较低的阈值要求同时可以选择完成部分清洗步骤等;
本发明的并行数据清洗系统,能够找出相似重复的数据以便去重、对不同来源的数据进行匹配、进行数据集合的去矛盾、补全和标准化、支持全量数和增量数据清洗,支持大数据文件的清洗导入、支持自定义数据的清洗规则、支持并行的数据采集和处理。
以上所述仅是本发明的较佳实施方式,故凡依本发明专利申请范围所述的构造、特征及原理所做的等效变化或修饰,均包括于本发明专利申请范围内。
- 还没有人留言评论。精彩留言会获得点赞!