一种采用机器学习的社交媒体情感分析方法与流程
本发明涉及自然语言处理领域,尤其是涉及了一种采用机器学习的社交媒体情感分析方法。
背景技术:
社会媒体的情感分析是自然语言处理领域的重要研究方法。由于社交媒体是字符有限的,所以经常采用句子级分类来提取公众情绪。分类社交媒体是具有挑战性的,因为社交媒体的独特性质,它经常使用非正式和口语语言,包括俚语和表情符号。虽然有不同的方法来分类社交媒体,但没有达成一致的最佳解决方案。在社交媒体的自然语言处理中,工程语言特征和自动文本分类是两个重要的任务。
虽然在使用机器学习来进行情感分析的领域中已经开发出了功能技术,但是在本文中仍然存在三个问题。首先,在同一社交媒体分析环境中缺乏对各种机器学习方法的评估;第二,还没有人调查枪支暴力这个重要的社会问题,从而了解公众情绪;第三,使用机器学习技术来分析大型数据集一般仍然局限于计算机科学(CS)的学科。
本发明引入基于上述三个问题,采用一种采用机器学习的社交媒体情感分析方法,开发了一个框架来收集,预处理和分类社交媒体并进一步可视化的情绪。在对整个样本进行分类时,使用人工制作的黄金标准数据集。对多种机器学习方法进行评估,选择最大准确度的方法对整个社交媒体文本数据样本进行分类并通过显示系统可视化分类结果。
技术实现要素:
针对上述提到的三个问题,本发明的目的在于提供一种采用机器学习的社交媒体情感分析方法,首先收集社交媒体文本原始数据并且以适当的格式将其预处理成修整的数据集,其被进一步分为训练和测试数据集;在机器学习阶段,利用八种机器学习方法(支持向量机(SVM),最大熵(ME),树,装袋树,提升树,随机森林(RF),神经网络(NN)和朴素贝叶斯(NB))来构建分类器;评估出更准确的分类器用于对社交媒体文本数据进行分类;最后使用多种可视化技术来总结结果。
为解决上述问题,本发明提供一种采用机器学习的社交媒体情感分析方法,其主要内容包括:
(一)数据收集;
(二)预处理;
(三)分类;
(四)总结;
(五)可视化。
其中,所述的数据收集,采用从第三方购买的社交媒体文本数据,常用的社交软件如,微博、朋友圈等;社交媒体文本数据是由预定义规则确定的历史消息,该规则利用基于时间段,关键字和地理位置的过滤器;数据都是JSON格式的,每个JSON文件以10分钟为一周期组织的,包含社交媒体文本数据和大量与之有关的信息。
其中,所述的预处理,从JSON格式的文件中提取与研究最相关的数据,将其转换为CSV格式,并利用R语言在RStudio中编写程序,以执行自然语言处理方面的所有任务。
其中,所述的分类,包括构建分类器和分类;从被预处理成修整的数据集中选取5000条社交媒体文本数据作为训练集,剩余的社交媒体文本数据用于分类。
进一步地,所述的构建分类器,包括特征提取、建模和评估;在特征提取阶段,会在N元语法特征的领域中考虑一元语法,二元语法和三元语法,而使用一元语法的特征提取单独处理句子中的每个单词是文本分类中最常用的方法,本专利采用一元语法特征用于文本分类;使用二元语法和三元语法特征分别提取两个和三个词的短语作为对比。
进一步地,所述的建模,包括输入训练数据集并利用机器学习方法(即支持向量机(SVM),朴素贝叶斯(NB),最大熵(ME),树,装袋树,提升树,随机森林(RF),神经网络(NN))来建立对应的8个预测模型;使用用于文本分类的机器学习库或某种R语言包开发预测模型;
随机森林是一种集成学习算法,RF控制要搜索的特征的数量,以寻求每个树的最佳分割,而不是每个二叉树完全成长;
装袋树也称为自助聚合,是一种在机器学习中使用的集成算法,以提高现有模型的准确性和稳定性;
提升树目的在于通过对错误分类的数据迭代地添加权重来在弱分类器上构建强分类器,从而减少对不正确分类的数据的预测模型的偏差;
支持向量机使用内核找到一个超平面,将数据分成具有最大边际的不同类别。
进一步地,所述的评估,包括比较在不同训练数据大小和使用一元语法特征的不同算法情况下的模型性能,通过10折交叉验证方法得出不同情况下的精度输出结果;分析结果可知,除最大熵算法外,其他算法得到的模型性能随训练数据集增大而增强;除不能代表总体趋势的特殊情况外,增加N元语法特征并没有改善模型性能,因为针对这项研究而言,一元语法特征是最有效的而且可以覆盖更多的数据;因此基于该数据集表现性能排名前四的机器学习方法分别是随机森林(RF),装袋树,提升树和支持向量机(SVM)。
其中,所述的总结,包括除了数据最初包含的时间戳和坐标之外,还使用用于计算支持持枪的公共情绪分数(PGPSS)的一系列方法来进行比较;由g定义地理区域和t定义时间帧;其中,考虑到地理位置和对应人口的校正的PGPSS是积极性的最佳指标,该基线PGPSS表示为
基线PGPSS从一组源自一个在给定时间帧中的省的社交媒体文本数据中测量支持持枪社交媒体文本数据数量与反对持枪社交媒体文本数据数量的比值;它给出了在所选社交媒体文本数据中的积极程度作为衡量正面社交媒体文本数据与负面社交媒体文本数据的指标。
其中,所述的可视化,在Shiny框架下开发了一个Web应用程序,用于可视化(四)得到的计算数据;使用显示系统生成运动图表,线图和地理地图;这三种图表提供了国家级和省级结果,以及每小时和每日分析。
附图说明
图1是本发明一种采用机器学习的社交媒体情感分析方法的系统流程图。
图2是本发明一种采用机器学习的社交媒体情感分析方法的分析和可视化公众情感的方法图。
图3是本发明一种采用机器学习的社交媒体情感分析方法的评估机器学习方法准确度示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
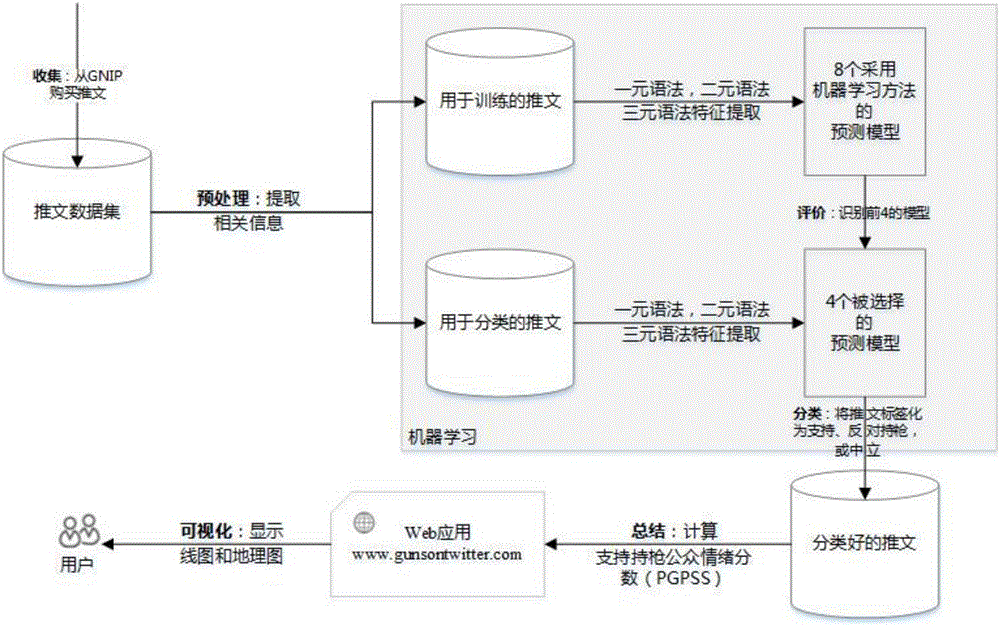
图1是本发明一种采用机器学习的社交媒体情感分析方法的系统流程图。主要包括数据收集;预处理;分类;总结;可视化。
首先收集社交媒体文本原始数据并且以适当的格式将其预处理成修整的数据集,其被进一步分为训练和测试数据集;在机器学习阶段,利用八种机器学习方法(支持向量机(SVM),最大熵(ME),树,装袋树,提升树,随机森林(RF),神经网络(NN)和朴素贝叶斯(NB))来构建分类器;评估出更准确的分类器用于对社交媒体文本数据进行分类;最后使用多种可视化技术来总结结果。
图2是本发明一种采用机器学习的社交媒体情感分析方法的分析和可视化公众情感的方法图。
其中,采用从第三方购买的社交媒体文本数据,常用的社交软件如,微博、朋友圈等;社交媒体文本数据是由预定义规则确定的历史消息,该规则利用基于时间段,关键字和地理位置的过滤器;数据都是JSON格式的,每个JSON文件以10分钟为一周期组织的,包含社交媒体文本数据和大量与之有关的信息。
其中,所述的预处理,从JSON格式的文件中提取与研究最相关的数据,将其转换为CSV格式,并利用R语言在RStudio中编写程序,以执行自然语言处理方面的所有任务。
其中,所述的分类,包括构建分类器和分类;从被预处理成修整的数据集中选取5000条社交媒体文本数据作为训练集,剩余的社交媒体文本数据用于分类。
进一步地,所述的构建分类器,包括特征提取、建模和评估;在特征提取阶段,会在N元语法特征的领域中考虑一元语法,二元语法和三元语法,而使用一元语法的特征提取单独处理句子中的每个单词是文本分类中最常用的方法,本专利采用一元语法特征用于文本分类;使用二元语法和三元语法特征分别提取两个和三个词的短语作为对比。
进一步地,所述的建模,包括输入训练数据集并利用机器学习方法(即支持向量机(SVM),朴素贝叶斯(NB),最大熵(ME),树,装袋树,提升树,随机森林(RF),神经网络(NN))来建立对应的8个预测模型;使用用于文本分类的机器学习库或某种R语言包开发预测模型;
随机森林是一种集成学习算法,RF控制要搜索的特征的数量,以寻求每个树的最佳分割,而不是每个二叉树完全成长;
装袋树也称为自助聚合,是一种在机器学习中使用的集成算法,以提高现有模型的准确性和稳定性;
提升树目的在于通过对错误分类的数据迭代地添加权重来在弱分类器上构建强分类器,从而减少对不正确分类的数据的预测模型的偏差;
支持向量机使用内核找到一个超平面,将数据分成具有最大边际的不同类别。
进一步地,所述的评估,包括比较在不同训练数据大小和使用一元语法特征的不同算法情况下的模型性能,通过10折交叉验证方法得出不同情况下的精度输出结果;分析结果可知,基于该数据集表现性能排名前四的机器学习方法分别是随机森林(RF),装袋树,提升树和支持向量机(SVM)。
其中,所述的总结,包括除了数据最初包含的时间戳和坐标之外,还使用用于计算支持持枪的公共情绪分数(PGPSS)的一系列方法来进行比较;由g定义地理区域和t定义时间帧;其中,考虑到地理位置和对应人口的校正的PGPSS是积极性的最佳指标,该基线PGPSS表示为
基线PGPSS从一组源自一个在给定时间帧中的省的社交媒体文本数据中测量支持持枪社交媒体文本数据数量与反对持枪社交媒体文本数据数量的比值;它给出了在所选社交媒体文本数据中的积极程度作为衡量正面社交媒体文本数据与负面社交媒体文本数据的指标。
其中,所述的可视化,在Shiny框架下开发了一个Web应用程序,用于可视化(四)得到的计算数据;使用显示系统生成运动图表,线图和地理地图;这三种图表提供了国家级和省级结果,以及每小时和每日分析。
图3是本发明一种采用机器学习的社交媒体情感分析方法的评估机器学习方法准确度示意图。比较在不同训练数据大小和使用一元语法特征的不同算法情况下的模型性能,通过10折交叉验证方法得出不同情况下的精度输出结果;分析结果可知,除最大熵算法外,其他算法得到的模型性能随训练数据集增大而增强;除不能代表总体趋势的特殊情况外,增加N元语法特征并没有改善模型性能,因为针对这项研究而言,一元语法特征是最有效的而且可以覆盖更多的数据;因此基于该数据集表现性能排名前四的机器学习方法分别是随机森林(RF),装袋树,提升树和支持向量机(SVM)。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!