一种面向Key‑Value存储系统的索引查询方法和系统与流程
本发明涉及数据索引查询技术领域,尤其涉及一种面向Key-Value存储系统的索引查询方法和系统。
背景技术:
随着互联网的快速发展,当今世界已经进入了“大数据”时代,国际数据公司IDC的最新报告预测,从2014年开始的十年内,全球每年产生的数据总量均将增加40%,即约每两年数据总量就将翻一番,到2020年全球数据总量将达到44ZB。伴随着数据量的飞速增长,数据的形式也由传统的结构化数据向着非结构化或半结构化的数据形式方向发展,传统的关系数据库对于这些数据的存储能力显得捉襟见肘,例如为海量文档建立索引、高流量网站的网页服务,以及发送流式媒体数据。除此之外,很多时候对于特定的系统,绝大部分的检索都是基于主键的查询,在这种情况下,关系数据库不能有效地建立索引,使得查询效率低下。在这样的大背景下,非关系型数据库对这些数据存储上的优势日益显现,越来越多应用选择采用非关系型数据库对数据进行存储。近年来,一种可用来管理非关系型数据、具有高可扩展性的数据索引系统:键值(Key-Value,即KV)数据库在众多的数据库系统中脱颖而出。
Key-Value数据库普遍采用树形结构对数据进行组织,随着大数据时代的到来,要在海量的数据中寻找特定的数据,如果采用传统的树的遍历形式无疑将会造成的巨大的时间开销,因此一种能够对特定数据进行快速索引的算法是必不可少的。
尽管当今计算机相关各领域都在飞速发展并取得了巨大的进步,但是不可否认的是高性能存储器的存储容量仍然是影响计算机系统性能的一个瓶颈,例如在基于DRAM内存的Cache缓存系统中,如果有限的存储空间能存储更多的数据,将能够大幅度的提高数据检索的命中率,减少系统到存取速度较慢的磁盘中检索数据,提高系统的整体性能。
为了更好的提高数据的存储空间效率,一种高效的策略是将数据分批的进行压缩处理,即将键值数据项(KV item)分批存放到多个block块中并以block为单位进行压缩处理,关于块间的组织,充分考虑到空间和时间效率,应该将其组织成前缀二叉树的形式。
技术实现要素:
基于背景技术存在的问题,本发明提出了一种面向Key-Value存储系统的索引查询方法和系统,通过将Key-Value数据项存入block中,并将根据block的节点生成前缀完全二叉树,在处理大规模Key-Value存储系统数据时,能够快速准确地通过给定的key值定位其所在的前缀完全二叉树的block节点序号,从而可以快速的从该block节点中获取该key对应的value值。
本发明提出的一种面向Key-Value存储系统的索引查询方法,所述方法包括以下步骤:
S1、获取Key-Value键值数据项存入block中,并根据所述block节点生成前缀完全二叉树,其中,所述前缀完全二叉树包含真实节点和虚拟节点;
S2、获取用户输入的需要检索的key值,并根据所述前缀完全二叉树高度确定所述key值需要运用的位数k,其中所述key值数制为二进制;
S3、获取所述key值的前k位,从所述key值前k位中第一位开始遍历,检索到所述key值前k位中第一个“1”,并记录所述第一个“1”前的位数j,其中j,k初始值均为1;
S4、判断j是否小于k,如果j小于k,则得到目标结果i,执行S5,其中其中i=2j,所述i表示block序号;如果j不小于k,则得到目标结果i,执行S6,其中i=2k-1-1,所述i表示block序号;
S5、从所述key值第j+2位即第一个“1”的后一位开始往后循环检索,当检索到“1”时,则将所述目标结果i值改变为2×(i+1);否则,将所述i值改变为2×i+1;直到位数j等于k时,停止检索并得到目标结果i,执行S6;
S6、通过所述目标结果i的值,在前缀完全二叉树中检索到对应的block序号block[i],判断所述block[i]是否为虚拟节点,当判断结果为否时输出所述目标结果i的值,当判断结果为是时则将所述k值减1后执行S3,直到k=0。
其中,在S1中,根据所述block节点生成前缀完全二叉树,具体包括:
S11、初始生成一个block节点作为根节点,并设置该block前缀为0;将获取的键值数据项逐个存入所述节点;
S12、将获取的键值数据项逐个存入所述节点,当所述节点容量达到上限时,将所述节点分裂为两个子block节点,并根据前缀树规则为所述两个子block节点设置相应的前缀,然后将所述两个子block节点的父节点内的键值数据项逐个取相应位数的前缀与所述两个block子节点前缀匹配,若匹配成功,则将所述键值数据项存入所述两个block子节点中,重复该操作,直到将父节点所有键值数据项存入到相应的子节点中,此时父节点变空,继续向前缀树中添加键值数据项,直到所有键值数据项存入所述前缀树中;
S13、通过使用虚拟节点补全所述前缀树使其成为一棵前缀完全二叉树。
一种面向Key-Value存储系统的索引查询系统,所述系统包括:
生成模块,用于将获取的Key-Value键值数据项存入block中,并根据所述block节点生成前缀完全二叉树,其中,所述前缀完全二叉树包含真实节点和虚拟节点;
获取模块,用于获取用户输入的需要检索的key值,并根据生成模块生成的前缀完全二叉树高度确定所述key值需要运用的位数k,其中所述key值数制为二进制;
遍历模块,用于获取所述key值的前k位,从所述key值前k位中第一位开始遍历,检索到所述key值前k位中第一个“1”,并记录所述第一个“1”前的位数j,其中j,k初始值均为1;
第一判断模块,用于判断j是否小于k,如果j小于k,则得到目标结果i并将所述目标结果i发送到循环检索模块,其中i=2j,所述i表示block序号;如果j不小于k,则得到目标结果i并将所述目标结果i发送到第二判断模块,其中i=2k-1-1,所述i表示block序号;
循环检索模块,用于从所述key值第j+2位即第一个“1”的后一位开始往后循环检索,当检索到“1”时,则将所述i值改变为2×(i+1);否则,将所述i值改变为2×i+1;直到位数j等于k时,停止检索并得到目标结果i,将目标结果i发送到第二判断模块;
第二判断模块,用于通过所述目标结果i的值,在前缀完全二叉树中检索到对应的block序号blcok[i],判断所述block[i]是否为虚拟节点,当判断结果为否时输出所述目标结果i的值,当判断结果为是时则将所述k值减1后,将k值发送到遍历模块,直到k=0。
其中,所述生成模块,具体包括:根节点生成子模块、父节点分裂子模块、虚拟节点补全子模块;
根节点生成子模块,用于初始生成一个block节点作为根节点,并设置该block前缀为“0”;
父节点分裂子模块,用于将获取的键值数据项逐个存入所述节点,当所述节点容量达到上限时,将所述节点分裂为两个子block节点,并根据前缀树规则为所述两个子block节点设置相应的前缀,然后将所述两个子block节点的父节点内的键值数据项逐个取相应位数的前缀与所述两个block子节点前缀匹配,若匹配成功,则将所述键值数据项存入所述两个block子节点中,重复该操作,直到将父节点所有键值数据项存入到相应的子节点中,此时父节点变空,继续向前缀树中添加键值数据项,直到所有键值数据项存入所述前缀树中;
虚拟节点补全子模块,用于通过使用虚拟节点补全所述前缀树使其成为一棵前缀完全二叉树。
本发明中,通过将Key-Value键值数据项存入block中,并将根据block的节点生成前缀完全二叉树,在处理大规模Key-Value存储系统数据时,能够快速准确地通过给定的key值定位其所在的前缀完全二叉树的block节点序号,从而可以快速的从该block节点中获取该key对应的value值,大大提高数据查询速度及系统的存取性能,减少了不必要的查找,进一步降低了系统的读写延迟。
附图说明
图1为本发明提出的一种面向Key-Value存储系统的索引查询方法实施例1的流程图;
图2为本发明提出的一种面向Key-Value存储系统的索引查询系统的结构图;
图3为本发明提出的一种面向Key-Value存储系统的索引查询系统的前缀完全二叉树的生成模块图;
图4为本发明提出的一种面向Key-Value存储系统的索引查询系统的block节点前缀完全二叉树结构示意图;
图5为本发明提出的一种面向Key-Value存储系统的索引查询方法的实施例2方法流程图;
图6为本发明提出的一种面向Key-Value存储系统的索引查询方法的实施例2实施图;
图7为本发明提出的一种面向Key-Value存储系统的索引查询方法的实验结果对比图。
具体实施方式
参照图1,图1为本发明提出的一种面向Key-Value存储系统的索引查询方法的流程图;
参照图4,图4为本发明提出的一种面向Key-Value存储系统的索引查询系统的block节点前缀完全二叉树结构示意图;
如图1所示,本发明提出的一种面向Key-Value存储系统的索引查询方法,该方法包括以下步骤:
步骤S1,获取Key-Value键值数据项存入block中,并根据所述block节点生成前缀完全二叉树,其中,所述前缀完全二叉树包含真实节点和虚拟节点;
如图4所示,步骤S1包括以下步骤:
S11、初始生成一个block节点作为根节点,并设置该block前缀为0;将获取的键值数据项逐个存入所述节点;
S12、将获取的键值数据项逐个存入所述节点,当所述节点容量达到上限时,将所述节点分裂为两个子block节点,并根据前缀树规则为所述两个子block节点设置相应的前缀,然后将所述两个子block节点的父节点内的键值数据项逐个取相应位数的前缀与所述两个block子节点前缀匹配,若匹配成功,则将所述键值数据项存入所述两个block子节点中,重复该操作,直到将父节点所有键值数据项存入到相应的子节点中,此时父节点变空,继续向前缀树中添加键值数据项,直到所有键值数据项存入所述前缀树中;
S13、通过使用虚拟节点补全所述前缀树使其成为一棵前缀完全二叉树;
在本发明实施例中,为了更好的提高数据的存储空间效率,一种高效的策略是将数据分批的进行压缩处理,即将键值数据项分批存放到多个block块中并以block为单位进行压缩处理,关于块间的组织,充分考虑到空间和时间效率,应该将其组织生成前缀完全二叉树的形式。
步骤S2,获取用户输入的需要检索的key值,并根据所述前缀完全二叉树高度确定所述key值需要运用的位数k,其中所述key值数制为二进制;
在本发明实施例中,所述的key值统一采用二进制数值,其中所述key若非二进制需首先通过hash函数将其转换为二进制,通过完全二叉树性质及该树最大节点序号计算得该树最大深度k。
步骤S3,获取所述key值的前k位,从所述key值前k位中第一位开始遍历,检索到所述key值前k位中第一个“1”,并记录所述第一个“1”前的位数j,其中j,k初始值均为1;
其中,所述key值中每一位上数值只有“1”或“0”,当检索到第一个“1”时,记录所述第一个“1”前的位数j。
步骤S4,判断j是否小于k,如果j小于k,则得到目标结果i,执行S5,其中其中i=2j,所述i表示block序号;如果j不小于k,则得到目标结果i,执行S6,其中i=2k-1-1,所述i表示block序号;
具体的,S4具体实施方式包括:
如果j小于k,即j<k,此时计算出i=2j。
如果j不小于k,说明key的前k位全为0,此时计算出i=2k-1-1;
步骤S5,从所述key值第j+2位即第一个“1”的后一位开始往后循环检索,当检索到“1”时,则将所述i值改变为2×(i+1);否则,就将所述i值改变为2×i+1;直到位数j等于k时,停止检索并得到目标结果i,执行S6;
在该步骤中,从第j+2位开始循环检索直到其位数等于k:
在此期间,若遇到的是“0”,则将i值改变为2×i+1;若遇到的是“1”,将i值改变为2×(i+1);通过循环检索直到key值前k位的值全部检索完,确定此时的i值,得到目标结果i的值。
步骤S6,通过所述目标结果i的值,在前缀完全二叉树中检索到对应的block序号block[i],判断所述block[i]是否为虚拟节点,当判断结果为否时输出所述目标结果i的值,当判断结果为是时则将所述k值减1后执行S3,直到k=0;
在该步骤中,最终的i值代表要检索的block的序号,在前缀完全二叉树中检索block序号,找到对应的block[i],由于在生成block节点的前缀完全二叉树过程中,使用了虚拟节点来补充叶子节点,所以block[i]有可能是虚拟节点,即值为空;当block[i]节点为虚拟节点时,将key值所用的位数k减1,重新进入S3,重新检索,直到k=0时,停止检索。
参照图2,图2为本发明提出的一种面向Key-Value存储系统的索引查询系统的结构图;
参照图3,图3为本发明提出的一种面向Key-Value存储系统的索引查询系统的前缀完全二叉树的生成模块图;
如图2所示,本发明提出的一种面向Key-Value存储系统的索引查询系统,该系统包括:
生成模块201,用于将获取的Key-Value键值数据项存入block中,并根据所述block节点生成前缀完全二叉树,其中,所述前缀完全二叉树包含真实节点和虚拟节点;
如图3所示,在本发明实施例中,生成模块201具体包括:根节点生成子模块、父节点分裂子模块、虚拟节点补全子模块;
根节点生成子模块,用于初始生成一个block节点作为根节点,并设置该block前缀为“0”;
父节点分裂子模块,用于将获取的键值数据项逐个存入所述节点,当所述节点容量达到上限时,将所述节点分裂为两个子block节点,并根据前缀树规则为所述两个子block节点设置相应的前缀,然后将所述两个子block节点的父节点内的键值数据项逐个取相应位数的前缀与所述两个block子节点前缀匹配,若匹配成功,则将所述键值数据项存入所述两个block子节点中,重复该操作,直到将父节点所有键值数据项存入到相应的子节点中,此时父节点变空,继续向前缀树中添加键值数据项,直到所有键值数据项存入所述前缀树中;
虚拟节点补全子模块,用于通过使用虚拟节点补全所述前缀树使其成为一棵前缀完全二叉树。
在本发明实施例中,为了更好的提高数据的存储空间效率,一种高效的策略是将数据分批的进行压缩处理,即将键值数据项分批存放到多个block块中并以block为单位进行压缩处理,关于块间的组织,充分考虑到空间和时间效率,应该将其组织生成前缀完全二叉树的形式。
获取模块202,与生成模块201连接,用于获取用户输入的需要检索的key值,并根据所述前缀完全二叉树高度确定所述key值需要运用的位数k,其中所述key值数制为二进制;
具体的,所述的key值统一采用二进制数值,其中所述key若非二进制需首先通过hash函数将其转换为二进制,通过完全二叉树性质及该树最大节点序号计算得该树最大深度k。
遍历模块203,与获取模块202连接,用于获取所述key值的前k位,从所述key值前k位中第一位开始遍历,检索到所述key值前k位中第一个“1”,并记录所述第一个“1”前的位数j,其中j,k初始值均为1;;
在本发明实施例中,遍历模块203具体用于:所述key值中每一位上数值只有“1”或“0”,当检索到第一个“1”时,记录所述第一个“1”前的位数j。
第一判断模块204,分别与遍历模块203、循环检索模块205、第二判断模块206连接,用于判断j是否小于k,如果j小于k,则得到目标结果i并将所述目标结果i发送到循环检索模块,其中i=2j,所述i表示block序号;如果j不小于k,则得到目标结果i并将所述目标结果i发送到第二判断模块,其中i=2k-1-1,所述i表示block序号;
其中,第一判断模块204具体用于:
如果j小于k,即j<k,此时计算出i=2j。
如果j不小于k,说明key的前k位全为0,此时计算出i=2k-1-1;
循环检索模块205,分别与第一判断模块204和第二判断模块206连接,用于从所述key值第j+2位即第一个“1”的后一位开始往后循环检索,当检索到“1”时,则将所述i值改变为2×(i+1);否则,将所述i值改变为2×i+1;直到位数j等于k时,停止检索并得到目标结果i,将目标结果i发送到第二判断模块;
具体的,循环检索模块,具体用于:
从第j+2位即第一个“1”的后一位开始循环检索直到其位数等于k:
在此期间,若遇到的是“0”,则将i值改变为2×i+1;若遇到的是“1”,将i值改变为2×(i+1);通过循环检索直到key值前k位的值全部检索完,确定此时的i值,得到目标结果i的值。
第二判断模块206,分别与第一判断模块204、循环检索模块205、遍历模块203连接,用于通过所述目标结果i的值,在前缀完全二叉树中检索到对应的block序号block[i],判断所述block[i]是否为虚拟节点,当判断结果为否时输出所述目标结果i的值,当判断结果为是时则将所述k值减1后,将k值发送到遍历模块,直到k=0。
具体的,在前缀完全二叉树中检索block序号,找到对应的block[i],由于在生成block节点的前缀完全二叉树过程中,使用了虚拟节点来补充叶子节点,所以block[i]有可能是虚拟节点,即值为空;当block[i]节点为虚拟节点时,将key值所用的位数k减1,将所述k值发送到遍历模块203,重新检索,直到k=0时,停止检索。
参照图5,图5为本发明提出的一种面向Key-Value存储系统的索引查询方法的实施例2方法流程图;
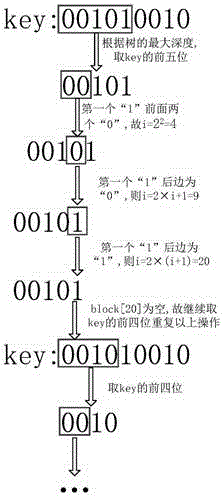
参照图6,图6为本发明提出的一种面向Key-Value存储系统的索引查询方法的实施例2实施图;
如图5和图6所示,本发明提出的实施例2的具体步骤为:
(1)首先检索最深一层block节点;
(1.1)获取要检索键值数据项的key值,假设要检索的key为:001010010...,通过完全二叉树性质及该树最大节点序号计算得该树最大深度k为5,故先取key的前五位00101;
(1.2)00101在第一次出现“1”前共有2个“0”,令个数j=2,故先设置一个变量i,通过公式2j计算出结果并赋值给i得i=4;
(1.3)观察“1”后边的第一个数字为“0”,故利用公式i×2+1计算并将结果赋值给i得i=9;
(1.4)继续观察到下一位数字为“1”,故利用公式2×(i+1)计算并将结果赋值给i得i=20,此时计算结束;
(2)通过上述过程发现该key要检索的数据存在20号block节点内,直接定位发现20号节点并不存在,故继续取key的前四位0010,继续步骤(1)操作,直到找到合适的节点。
参照图7,图7为本发明提出的一种面向Key-Value存储系统的索引查询方法的实验结果对比图;
如图7所示,将本发明提出的面向Key-Value存储系统的索引查询方法和普通检索方法进行检索对比实验,在850次不同数据检索实验中,本发明提出的面向Key-Value存储系统的索引查询方法有71%的次数所花费的数据检索时间低于普通检索方法所花费的数据检索时间。
本发明的技术方案中,通过将Key-Value键值数据项存入block中,并将根据block的节点生成前缀完全二叉树,在处理大规模Key-Value存储系统数据时,能够快速准确地通过给定的key值定位其所在的前缀完全二叉树的block节点序号,从而可以快速的从该block节点中获取该key对应的value值,大大提高数据查询速度及系统的存取性能,减少了不必要的查找,进一步降低了系统的读写延迟。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!