一种软件配置代码制品的层次分类方法与流程
本发明涉及一种软件配置代码制品的层次分类方法,尤其涉及一种面向多种软件配置工具的大量可重用脚本代码的层次化分类体系构造和基于该分类体系的配置代码制品的层次化分类,属于计算机软件技术领域。
背景技术:
配置管理工具(Configuration Management Tool,CMT)是实现开发运维一体化(Development and Operations,DevOps)的重要支撑工具,当前主流的CMT采用代码即基础设施(Infrastructure as Code,IaC)的方式,通过代码来描述目标系统配置,实现自动化的系统安装和配置,从而满足DevOps所倡导的持续交付、快速部署和高效运维。基于此,使用CMT已成为运维管理领域的主流趋势。软件配置代码制品(以下简称CMT制品)是CMT工具用以安装、配置和管理特定的软件系统的可复用执行脚本。在开源技术社区快速发展的背景下,CMT社区积累了大量的、并且持续快速增长的CMT制品,例如,Chef、Puppet、Ansible三个CMT社区已有4200多用户,贡献超过14000个CMT制品。
但是,大量的CMT制品给用户如何正确选择和使用带来了困难。仅仅基于制品列表和关键字搜索用户难以得到准确的结果,仍要花费大量时间对搜索结果进行浏览和细化。因此,软件运维管理领域迫切需要一种CMT制品的自动化层次分类机制,以满足用户快速检索和准确定位目标制品的需求。层次化分类将大规模数据按照特征逐级划分,细化范围,将层次分类应用于CMT制品,不仅能提高检索效率和准确度,还能够构建脚本制品间层次关联关系,有助于脚本制品的维护管理,提高CMT制品的利用率。
当前面向CMT制品的分类仍然需要人工进行,缺乏高效的分类和检索体系。同时,CMT制品的源代码、API信息等受领域特定语言限制难以抽取有效信息。因此本发明通过整合多个CMT制品资源库,分析CMT制品在线非结构化描述文档,实现CMT制品的层次分类。
技术实现要素:
本发明的技术解决问题:克服现有技术的不足,提供一种软件配置代码制品的层次分类方法。方法通过分析软件配置代码制品标签自动构建配置代码的层次分类体系,然后基于监督学习方法实现一组分类器,并通过这些分类器自动完成数量众多的CMT制品的层次化分类,从而有助于用户缩小对制品的搜索范围,提高搜索结果的准确性。
本发明的技术方案如图1所示:
一种软件配置代码制品的层次分类方法,包括了了以下几个步骤:
(1)构建软件配置代码制品的层次分类体系,从多个CMT代码库爬取CMT代码制品标签,经过标签过滤和处理得到CMT代码制品标签集合作为CMT配置代码制品的类别集合,然后通过挖掘CMT标签集合之间的隶属关系来构建层次分类Ctree;所述CMT表示配置管理工具;
(2)使用CMT软件代码库中的部分CMT代码制品为训练数据集,爬取训练数据集中每个CMT代码制品的名称和描述信息构成相应CMT代码制品的描述文档,采用TF-IDF(term frequency&inversed document frequency,词频和逆向文件频率)模型实现CMT代码制品的文本特征向量抽取;对训练数据集进行标注,将其中每个CMT代码制品划分到层次分类Ctree中对应的类别;最后基于二元分类器的自上而下(Top-down)分类方法,采用支持向量机算法(SVM)得到一组分类器,每个分类器实现对层次分类Ctree相应类别的CMT代码制品的划分;
(3)对于给定的待分类CMT制品m,采用逐步求精的方法,使用步骤(2)得到的分类器,对当前CMT代码制品m进行自动化的层次分类,最终将m划分到层次分类Ctree中某个类别。
所述步骤(1)具体实现如下:
(11)Tinitial={t1,t2,…,tm}表示爬取获得的CMT代码制品初始标签集合,对于任意标签ti∈Tinitial,1≦i≦m,ti表示集合中的某个CMT代码制品标签,ti=<name,occur>,其中name表示标签名称,occur表示该标签在所有爬取的CMT代码制品样本中出现的次数;
(12)对Tinitial中的标签进行过滤,确保得到的为常用标签,当ti.occur≥30,保留ti,否则从Tinitial中删除ti,过滤后得到常用标签集合Tfilter={t1,t2,…,tn}n≤m,即常用标签集合包含的标签数小于等于上一步骤中得到的CMT代码制品标签集合中的标签数;遍历Tfilter,对其中的标签进行同义词合并,假定tj,tk为Tfilter中的两个标签,即tj,tk∈Tfilter,且tj.name与tk.name为同义词,将tj,tk合并为新的标签tl,且tl.name=tj.name或tk.name,tl.occur=tj.occur+tk.occur,将tl加入常用标签集合Tfilter,并从中删除tj,tk,经过同义词处理后得到CMT代码制品标签集合Tfinal={t1,t2,…,tq},q≤n,即CMT代码制品标签集合包含的标签数量小于或等于常用标签集合包含的标签数量;
(13)根据Tfinal中标签共同出现的情况推断两两标签之间是否存在隶属关系,对于任意两个标签tA,tB∈Tfinal,如果tA是tB的子类,即tA包含tB,则必须满足:(1)被tA标注的CMT代码制品存在很大的概率被tB标注,并且,(2)tA.occur<tB.occur,即标签tA出现的次数少于标签tB,表示或者除了与tA一起出现外,tB还与其他标签一起出现;经过上述分析处理,得到所有CMT制品Tpair={<t1,t2>,…,<tx,ty>}(tx,ty∈Tfinal);
(14)遍历标签对集合Tpair,根据其中所有CMT制品之间的隶属关系创建层次分类Ctree。
所述步骤(2)具体实现如下:
(21)以建立的层次分类树Ctree和CMT代码制品的标签为依据,通过标签匹配的方法对样本配置代码制品进行标注;
(22)作为训练数据集的CMT代码制品配置的名称和描述信息构成CMT代码制品属性文档d=<name,description>,name表示标签名称,description表示CMT代码制品描述信息,对属性文档d进行预处理,采用自然语言处理技术进行分词、剔除停用词和同义词处理,最后得到包括所有CMT代码制品的属性文档构成的集合D,作为训练数据集;
(23)采用TF-IDF对D中的每个属性文档d进行计算,得到属性文档d的特征向量vd,最终得到CMT代码制品属性文档集合D对应的向量矩阵MD;
(24)以MD作为训练数据集的属性文档特征,采用SVM算法对层次分类Ctree的每个类别训练分类器,得到分类器集合C={c1,c2,…,cq},c1,c2,…,cq分别对应为层次分类Ctree中的q个类别的分类器。
所述步骤(3)具体实现如下:
(31)对于给定的待分类CMT制品p,抽取p的名称和描述作为对应的属性文档d,并计算属性文档d的TF-IDF特征向量vdp,将特征向量作为分类器预测的依据;
(32)采用逐步求精的方法,对当前CMT代码制品p进行自动化的层次分类,从层次分类Ctree的根节点Root开始,采用深度优先遍历策略,递归的搜索p的目标类别,如果给定p属于当前节点类别t,那么p将继续在t的n个子类别(t1,t2,…,tn)中继续划分,直到p不属于t的任何子类别或搜索到达叶子节点;对于第一种情况,当前的节点类别t即是CMT代码制品p的目标类别;第二种情况下,所到达的叶子节点类别是CMT代码制品p的目标类别。
本发明与现有技术相比的积极效果为:采用本发明的方法,能够方便用户查找和使用软件配置代码制品,层次化分类通过逐步求精的思想为用户缩小目标制品的查找范围,同时还能够提高CMT代码制品分类的准确性,从而有效减少用户浏览确认的时间和代价,能够更快更准的找到期望的目标制品。
附图说明
图1为本发明的实现框图;
图2为本发明的分类结果示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步说明。
本发明实施例以当前广泛使用的自动化运维工具Puppet、Ansible和Chef的代码制品分类作为案例来解释说明本发明方法。
如图1所示,本发明的一种软件配置代码制品的层次分类方法,包括了了以下几个步骤:
(1)构建软件配置代码制品的层次分类体系,从多个CMT代码库爬取CMT代码制品标签,经过标签过滤和处理得到CMT代码制品标签集合作为CMT配置代码制品的类别集合,然后通过挖掘CMT标签集合之间的隶属关系来构建层次分类Ctree;所述CMT表示配置管理工具;
具体实现如下:
(11)Tinitial={t1,t2,…,tm}表示爬取获得的CMT代码制品初始标签集合,对于任意标签ti∈Tinitial,1≦i≦m,ti表示集合中的某个CMT代码制品标签,ti=<name,occur>,其中name表示标签名称,occur表示该标签在所有爬取的CMT代码制品样本中出现的次数;
(12)对Tinitial中的标签进行过滤,确保得到的为常用标签,当ti.occur≥30,保留ti,否则从Tinitial中删除ti,过滤后得到常用标签集合Tfilter={t1,t2,…,tn}n≤m,即常用标签集合包含的标签数小于等于上一步骤中得到的CMT代码制品标签集合中的标签数;遍历Tfilter,对其中的标签进行同义词合并,假定tj,tk为Tfilter中的两个标签,即tj,tk∈Tfilter,且tj.name与tk.name为同义词,将tj,tk合并为新的标签tl,且tl.name=tj.name或tk.name,tl.occur=tj.occur+tk.occur,将tl加入常用标签集合Tfilter,并从中删除tj,tk,经过同义词处理后得到CMT代码制品标签集合Tfinal={t1,t2,…,tq},q≤n,即CMT代码制品标签集合包含的标签数量小于或等于常用标签集合包含的标签数量;
(13)根据Tfinal中标签共同出现的情况推断两两标签之间是否存在隶属关系,对于任意两个标签tA,tB∈Tfinal,如果tA是tB的子类,即tA包含tB,则必须满足:(1)被tA标注的CMT代码制品存在很大的概率被tB标注,并且,(2)tA.occur<tB.occur,即标签tA出现的次数少于标签tB,表示或者除了与tA一起出现外,tB还与其他标签一起出现;首先统计Tfinal中所有标签出现的次数,表示为{t1.occur,t2.occur,…,tq.occur},然后对Tfinal中任意两个标签tx,ty(x≠y)计算共同出现的频度并进行条件(1)(2)的判断,保留同时满足两个条件的标签对<tx,ty>。经过上述分析处理,得到所有存在隶属关系的CMT制品标签对集合Tpair={<t1,t2>,…,<tx,ty>}(tx,ty∈Tfinal);以标签nosql和mongodb为例,tnosql.occur是214,tmongodb.occur是95,被两个标签同时同时出现的次数是51,那么可以认为软件配置代码制品在标注标签mongodb后,有54%(=51/95)的概率同时标注nosql,因此标签对<mongodb,nosql>被保留在具有隶属关系的标签对集合Tpair中。
(2)使用CMT软件代码库中的部分CMT代码制品为训练数据集,爬取训练数据集中每个CMT代码制品的名称和描述信息构成相应CMT代码制品的描述文档,采用TF-IDF(term frequency&inversed document frequency)模型实现CMT代码制品的文本特征向量抽取;对训练数据集进行标注,将其中每个CMT代码制品划分到层次分类Ctree中对应的类别;最后基于二元分类器的自上而下(Top-down)分类方法,采用支持向量机算法(SVM)得到一组分类器,每个分类器实现对层次分类Ctree相应类别的CMT代码制品的划分。
上述步骤(2)具体实现如下:
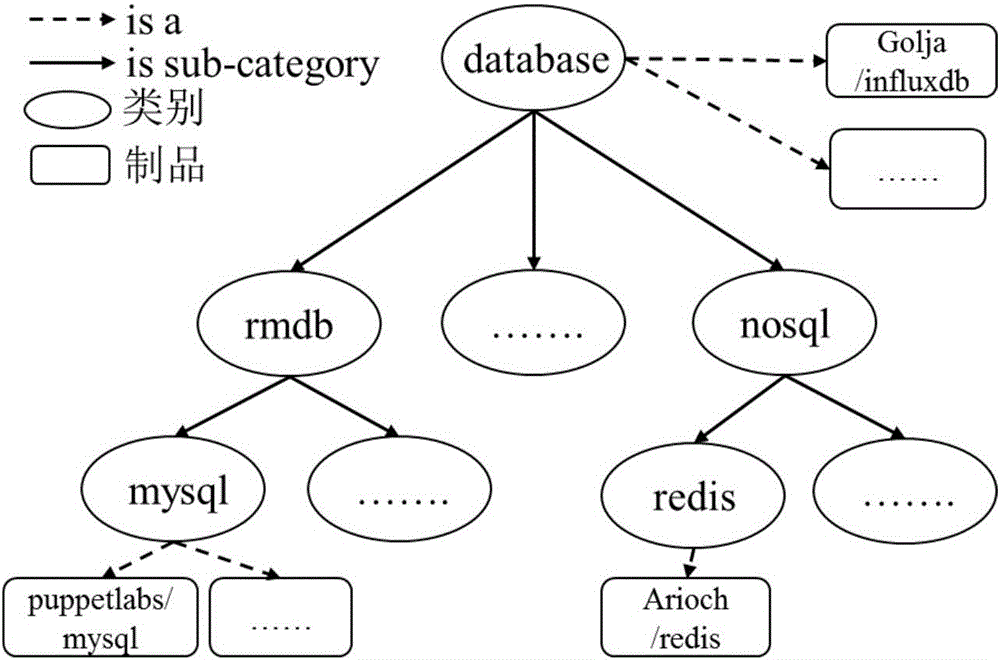
(21)以建立的层次分类树Ctree和CMT代码制品的标签为依据,通过标签匹配的方法对样本配置代码制品进行标注,将其中每个CMT代码制品划分到Ctree中对应的类别。层次类别是层次分类树Ctree中的节点,每个节点代表某一个标签类别,其层次分类为根节点到该节点的路径。例如,某制品dwerder.mongodb含有标签mongodb,通过匹配在Ctree中找到对应的类别节点“mongodb”,该节点的层次类别是database>nosql>mongodb,这样,就为制品dwerder.mongodb找到了对应的层次类别;需要注意的是,某类别的元素同时也是其层次分类树中父类别的元素,即制品dwerder.mongodb同时也属于类别database>nosql和database。
(22)作为训练数据集的CMT代码制品配置的名称和描述信息构成CMT代码制品制品属性文档d=<name,description>,name表示标签名称,description表示CMT代码制品描述信息,对属性文档d进行预处理,采用自然语言处理技术进行分词、剔除停用词和同义词处理,最后得到包括所有CMT代码制品的属性文档构成的集合D,作为训练数据集;以制品dwerder.mongodb为例,提取其描述文档<dwerder.mongodb,MongoDB module with sharding>,首先按照标点符号得到独立的词汇,去掉其中的停用词“with”,并将“sharding”通过词干还原为“shard”,从而得到文档结果为ddwerder.mongodb=<dwerder.mongodb,mongodb module shard>,对所有制品执行该处理过程形成训练数据集D。
(23)采用TF-IDF对D中的每个属性文档d进行计算,得到属性文档d的特征向量vd,最终得到CMT代码制品属性文档集合D对应的向量矩阵MD;公式(1)给出了TF-IDF的计算公式,其中w表示词项,d表示文档,nw,d表示词项w在文档d中出现的频率,nw表示含有词项w的文档个数,k∈词项w全集,|U|表示文档全集的个数。该计算方法通过词项w在不同文档中出现的频度差别来衡量词项w对于文档d的区分能力。对于某文档d,通过计算d中所有词项的TF-IDF值,形成d的特征向量vd,同时所有文档D的特征向量组成特征向量矩阵MD。
(24)以MD作为训练数据集的属性文档特征,采用SVM算法对层次分类Ctree的每个类别训练分类器,得到分类器集合C={c1,c2,…,cq},c1,c2,…,cq分别对应为层次分类Ctree中的q个类别的分类器。特征向量矩阵MD将CMT制品文档转换为量化的多维欧式空间点集,SVM算法通过计算不同类别点集的划分超平面实现对CMT制品的分类,调整算法的核函数及不同特征的权重值,得到最优分类效果的分类器。如database>nosql类别下,mongodb中的CMT制品与其他子类别的CMT制品可以使用SVM算法训练得到一个针对database>nosql>mongodb类别的二类分类器,该分类器可以区分属于nosql类别的CMT制品是否进一步属于mongodb类别;使用同样的方法为分类树Ctree中的每一个节点都训练一个二类分类器。
(3)对于给定的待分类CMT制品m,采用逐步求精的方法,使用步骤(3)得到的分类器,对当前CMT代码制品m进行自动化的层次分类,最终将m划分到层次分类Ctree中某个类别。
步骤(3)具体实现如下:
(31)对于给定的待分类CMT制品p,抽取p的名称和描述作为对应的属性文档d,并计算属性文档d的TF-IDF特征向量vdp,将特征向量作为分类器预测的依据;给定的待分类CMT制品由于没有标签属性,因此需要使用步骤(2)所得到的分类器模型进行分类预测。首先使用与步骤(22)(23)相同的方法,抽取属性文档,并利用公式(1)计算该文档的TF-IDF特征向量,以制品L7-mongo为例,其描述文档<L7-mongo,Installs/Configures mongodb,multi instance support>,经过处理得到dL7-mongo=<L7mongodb,install configure mongodb multi instance support>,并进一步计算TF-IDF向量值,作为该制品的量化特征。
(32)采用逐步求精的方法,对当前CMT代码制品p进行自动化的层次分类,从层次分类Ctree的根节点Root开始,采用深度优先遍历策略,递归的搜索p的目标类别,如果给定p属于当前节点类别t,那么p将继续在t的n个子类别(t1,t2,…,tn)中继续划分,直到p不属于t的任何子类别或搜索到达叶子节点;对于第一种情况,当前的节点类别t即是CMT代码制品p的目标类别;第二种情况下,所到达的叶子节点类别是CMT代码制品p的目标类别。对于制品L7-mongo,将其特征向量vdp依次作为分类器的输入进行预测,首先使用根节点下的顶级节点分类器预测,其被database类别分类器预测为接受,而被其他分类器拒绝,因此,判断该制品属于database类别;然后在database类别内部,分别使用nosql分类器等预测,该制品被nosql分类器接受,而被其他分类器拒绝,判断该制品属于database>nosql类别;最后进一步在nosql内部依次使用分类器预测,被mongodb类别预测为接受,而且mongodb并无子类别,因此分类器预测的结果是制品L7-mongo的层次类别是database>nosql>mongodb。
如图1所示,本发明具体的步骤如下:
1.采用本发明内容中步骤1所描述的方法进行层次分类体系的构建。本发明实施例首先以Puppet和Ansible的10790个代码制品为样本,从中抽取了263个具有隶属关系的标签对,并基于此建立了一个具有90个类别的、4层的分类体系,其中第一层类别下有包括system、server等9个分类,第二、三、四分别包含33、42、6个分类,如表1所示。
2.采用本发明内容中步骤2所描述的方法进行分类器的训练和构建。以拥有90个类别的层次分类树为依据,以10790个Puppet和Ansible的代码制品为训练数据集,采用SVM算法得到的正样本情况如表1所示。
3.采用本发明内容中步骤3所描述的方法,对1000例Chef的代码制品进行分类。图2展示了“database”类别下的“sql”“nosql”等子类以及其包含的CMT制品情况。步骤3将“puppetlabs/mysql”以及“arioch/redis”分别划分到mysql和redis类别下,然而,“golja/influxdb”在被划分到database类别后没有进一步找到子类别,因此将其直接划分到database类别下。
表1
实施例采用“mysql”作为关键词进行Puppet和Ansible制品库的搜索,搜索结果包含了Puppet的一个脚本制品“puppet/zabbix”,它是用来支持监控系统Zabbix的安装与管理操作,与mysql无关。采用本发明的分类方法则将该制品划分到类别下,显然更加合理。除此之外,Ansible脚本库中的一个mysql相关制品cranework.mysql被错误的标记为web,本发明的分类方法则能够正确的将其划分到类别下。上述案例分析证明本发明方法能够在制品分类的准确性和合理性方面提供有效的帮助。
总之,本发明通过分析软件配置代码制品标签自动构建配置代码的层次分类体系,然后基于监督学习方法实现一组分类器,并通过这些分类器自动完成数量众多的配置脚本代码制品的层次化分类。本发明能够方便用户查找和使用软件配置代码制品,提高制品分类的准确性,从而有效减少用户浏览确认的时间和代价。
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!