一种基于语境的社交场景构建方法和系统与流程
本发明属于h04l12/58(2006.01)i。
背景技术:
本发明属于一种基于语境的社交场景构建方法和系统,社交工具连接人与生活,主要代表性产品有微信、陌陌、qq、微博、易信、twitter、facebook、g+、whatsapp,yy、line、msn、阿里旺旺、米聊、微聚、贴吧、来往、抱抱、脉脉等,这些社交工具的场景构建采用的方法多样,除了微信和qq具有“”掉魔法表情“的情趣表情的构建场景的方法和系统之外,大多采用固定的主题背景图片的方式,而且现有社交工具的场景构建特点是聊天参与者构成场景的主体,对语言和图像类无法简单表达的知识性、抽象性、资讯性和行为性等内容缺乏表现力,例如如图4所示,会话的一方(301)提到牛顿,而另外一方(302)不知道牛顿是谁,现有的社交软件对此例中的知识性的会话内容没有表达能力;再例如如图5所示,会话双方一方(301)在东北哈尔滨,在会话到天气的时候,现有的社交工具无法把关切的某地的气象资讯表达给对方,对此资讯性的内容缺乏表现力;再例如如图6所示,会话的一方(301)询问球的位置,而另外一方(302)的回答是缺少主语成分,导致会话的方(301)无法理解抽象的空间分布,对此类抽象性的内容缺乏表现力。
与目前现有的2d社交工具的场景对比,下一代3d社交工具应用虚拟现实技术构建社交会话场景,使用什么内容构建场景,成为必须解决的切实需求,本发明针对2d社交工具的现存不足和下一代3d社交工具的切实需求提出一种基于语境的社交场景构建方法和系统。
聊天机器人是一个用来模拟人类对话或聊天的程序,它试图建立这样的程序:至少暂时性地让一个真正的人类认为他们正在和另一个人聊天,聊天的机器人技术也日趋成熟,国内已经出现了不少智能聊天机器人,比如赢思软件的小i,爱博的小a,小强,siri、小度机器人和爱情玩偶等等[1]。
另一方面,自然语言处理(naturallanguageunderstanding俗称人机对话)是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。目前开源工具主要有:哈工大ltp、中科院分词ictclas、微软分词moss、句法分析stanfordparser、中文自然语言处理工具包fudannlp、java自然语言处理lingpipe、自然语言处理工具opennlp、自然语言处理工具crf++、自然语言处理hanlp。
在自然语言处理应用于场景构建方面,空间概念建模是困扰文本到场景自动转化发展的一个基础问题,概念建模就是从高级描述生成二维或者三维的场景,并使场景展现的景象和高级描述表达的情景是一致的,例如”乌鸦站在大树上“的描述生成一个包含“乌鸦”和“大树”的图形,且乌鸦和树的空间关系是“上”的场景。这里高级描述包含自然语言和类自然语言。九十年代初期陆汝铃院士开发出“天鹅”系统,实现中文故事到动画片的自动生成;at&a实验室开发出wordseye系统,起能够根据文本的简单描述生产静态的三维场景[4]。wordseye系统在社交的应用中的缺陷也是明显,首先是社交软件的会话是两个主体以上,存在彼此描述参照系的差异,例如同一个苹果相对于会话双方的空间位置是不同的,因此双方的不同的相对描述如何转换到同一个空间位置的同一个苹果上是一个难题;其次是会话的语言习惯是精简的生活用语(例如主语和宾语因在上下文中而经常被省掉),对语境的理解需要参考上下文的内容等因素,即wordseye如何解决语法残缺的日常会话内容这一难题。
此外,语用学是语言学各分支中一个以语言意义为研究对象的新兴学科领域,在众多的语用学定义中,有两个概念是十分基本的,一个是意义,另一个是语境,是专门研究语言的理解和使用的学问,它研究在特定情景中的特定话语,研究如何通过语境来理解和使用。leech认为语境“就是被认为是交际双方互相明白的内容和各自了解的情况,对于理解说话人的话语意义有很大的作用”,这里所指的语境,不仅仅指上下文或话语发生的环境,还包括文化和科学知识,常识,或者说是交际双方的精神、社交和物质三个世界[2]。
在知识库方面,cyc是一个致力于将各个领域的本体及常识知识综合地集成在一起,并在此基础上实现知识推理的人工智能项目。其目标是使人工智能的应用能够以类似人类推理的方式工作。cyc知识库中表示的知识一般形如“每棵树都是植物”、“植物最终都会死亡”。当提出“树是否会死亡”的问题时,推理引擎可以得到正确的结论,并回答该问题。这个项目是由douglaslenat在1984年设立的,由cycorp公司开发并维护。该项目的一部分以opencyc形式发布,opencyc项目以开源许可的形式向开发者和使用者提供api,可下载的数据集(特别是为语义万维网实践者提供了owl版本的数据集)等。
现有的社交软件的场景构建方法和系统具有以下缺点:1.场景的构成主体是聊天的参与者,对语言和图像类无法简单表达的知识性、抽象性和语言行为性的内容缺乏表现力。2.仅仅分析会话某一方的会话内容,通过预设关键词匹配等方法生成社交场景,未能分析上下文内容获取语境信息。
针对现有语社交软件的场景构建方法和系统的不足,应用自然语言处理(nlu)分析会话的内容获取语境信息,再关联数据库、知识库获取数据,其通过应用媒体或者虚拟现实技术或现实增强技术,构建社交软件的场景,实现从语境到场景的转换,并可使场景与会话融合\或在时空中关联依赖存在,增强人对社交语言语义的理解,提高会话内容的表现力和情趣,而提出本发明,即一种基于语境的社交软件场景构建方法和系统。
技术实现要素:
为了解决现有社交软件场景构建方法和系统的不足的技术缺陷,而提出一种基于语境的社交软件场景构建方法和系统,本发明是通过以下技术方案实现的。
1.一种基于语境的社交场景构建方法,主体(101)和(102)之间通过社交工具会话,使用场景机器人(103)监听社交会话内容,其特征在于:场景机器人(103)对会话主体(101)和(102)之间的会话内容进行自然语言处理(105)输出语境信息,关联语境进行数据获取(106),其输出数据经场景构建(107)生成场景,实现从语境到场景的构建。
2.根据权利1所述的基于语境的社交场景构建方法,其特征在于:所述的生成场景与会话融合\或在时空中关联依赖存在。
3.根据权利1所述的基于语境的社交场景构建方法,其特征在于:所述的场景机器人(103)包括自然语言处理(105)、数据获取(106)、场景构建(107),其工作方式包括不以主体角色参与其他主体间的会话。
4.根据权利1所述的基于语境的社交场景构建方法,其特征在于:所述数据获取(106)的数据信息来源包括数据库(104)、\或lbs(109)、\或传感器(108)的任一或组合,其中所述的数据库(104)包括历史、地理、文化、人物、气候、物产、旅游、新闻等人类已知的知识、知识库和资讯信息的任一种或组合。
5.根据权利4所述的基于语境的社交场景构建方法,其特征在于:所述的知识库包括推理引擎。
6.根据权利1所述的基于语境的社交场景构建方法,其特征在于:所述的场景构建(107)的方法包括媒体\或虚拟现实技术\或现实增强技术的任一或组合。
7.根据权利6所述的基于语境的社交场景构建方法,其特征在于:所述的媒体包括文字、图片、照片、声音、动画和影片,以及程式所提供的互动功能的任一种或组合。
8.根据权利1所述的基于语境的社交场景构建方法,其特征在于:所述的会话的形式包括文字、语音、图形和表情的任一种或组合。
9.一种基于语境的社交场景构建系统,包括传感器模块(205)、lbs模块(206)、数据库(104),其特征在于:所述一种基于语境的社交场景构建系统采用了如权利要求1至8任意一项所述的一种基于语境的社交场景构建方法。
10.根据权利9所述的基于语境的社交场景构建系统,其特征在于:包括会话场景融合模块(201)。
本发明方法和系统的原理
众所周知,社交会话的内容包括时间、地点、人物和事件(语言行为)等要素,句法结构包括陈述、疑问、惊叹、祈使等若干种类型,在结构特点和使用习惯上,主语和宾语等语法要素因在上下文中提及或隐含而经常被省略。
依据现有的自然语言处理的技术能力,包括词性标注、命名实体、句法分析、语义角色标注、语义依存分析和情感分析等,自然语音处理可以准确处理出时间、地点、人物,由于语言本身的复杂性,虽然在人类尚未明了大脑是如何进行语言的模糊识别和逻辑判断的情况下,对会话事件(语言行为)的准确处理在一定的边界范围内是可以满足使用要求的。
如图1所示,用户会话主体(101)和(102)进行社交会话,使用场景机器人(103)监视会话内容进行自然语言处理(105)得到会话的语境信息,再依据会话内容的知识性、抽象性、逻辑性、资讯性和语言行为等语境信息进行检索、过滤和关联等数据库(104)操作、传感器采集(108)和lbs(109)进行数据获取(106)相关信息和行为描述等数据,并且可使用数据库(104)包含的知识库的推理引擎,基于该知识库中包含的人类定义的断言、概念、谓词等,得到正确的结论,对所获取的数据再应用媒体\或虚拟现实技术\现实增强,经场景构建(107)生成场景实现从会话语境到场景的转换,并可使得场景与会话融合\或在时空中关联依赖存在,增强对会话内容的表现力,其中媒体方式包括文字、图片、照片、声音、动画和影片,以及程式所提供的互动功能。此外场景机器人可以不以主体角色参与会话,在后台运行仅仅监听分析其他主体的会话内容,构建会话的场景。凭借上诉原理,本发明的方法实现从语境到场景的转换,增强人对社交语言意义的理解,提高表现力和情趣。
例如如图4所示,会话的一方(301)提到牛顿,而另外一方(302)不知道牛顿是谁,场景机器人对会话内容进行自然语言理解处理得到语境信息“牛顿”,采用知识性关键词“牛顿”在数据库(104)中进行检索匹配,获取牛顿的资料(403)(404)、图像信息(405)等融合到会话的场景中,完成场景的构建,使得双方因知识性认知差异导致的会话理解的障碍得以消除,在本例中场景机器人增强了对知识性会话内容的表现力。
再例如如图5所示,会话双方(301)在东北哈尔滨,在会话到天气的时候,场景机器人处理上下文(501)和(503),理解为“哈尔滨的天气”这一语境内容,从数据库中获取“哈尔滨”的实时天气气候资讯(505)(温度、天气等)和雪花图案(507),融合在会话场景中,在本例中场景机器人增强了对资讯性的内容表现力。
再例如如图6所示,场景机器人处理上下文(601)和(602),理解为“球在桌子上”这一语境内容,从数据库中获取“球”和”桌子”的数据合成[4]表现“球”在”桌子”之“上”的空间逻辑抽象概念关系,融合在会话场景中,完成场景的构建,使得双方的会话中一系列的与位置和方向相关联的复杂的抽象性内容获得双方更加易于理解的表达,在本例中场景机器人增强了抽象性的内容表现力。
再例如如图7所示,场景机器人处理上下文(701)和(702),理解为“苹果+刀子”这一语境内容,下文(703)询问“语言行为“意图,根据知识库的判断出“语言行为“=“刀切苹果”,从数据库中获取匹配的“刀切苹果”的媒体信息,或者从数据库中获取“刀”和”苹果”的数据合成[4]表现出“切”(705),这一“语言行为“抽象概念,融合在会话场景中,完成场景的构建,在本例中场景机器人增强了抽象性的事件(“语言行为“)内容表现力。
再例如如图8所示,场景机器人处理上下文(804),根据知识库的人类断言“人类在低温时有冷的感觉“和”零下25度是低温“,推理引擎可以得到正确的结论“冷”,从数据库中获取(806)和(807)媒体信息,融合在会话场景中,完成场景的构建,在本例中场景机器人增强了抽象性的逻辑推理性的内容表现力,此外在这里场景机器人(103)可以不以主体角色参与其他主体间的会话,如图9所示。
上述示例中在表达形式和方式上有二维和三维等表现方式,对于平面类二维度社交软件(微信、陌陌等),场景机器人可以把构建的场景融合在社交软件的二维度会话背景平面内,对于三维度社交软件和设备(例如谷歌眼镜、oculusrift)场景机器人可以把构建的二维或者三维的场景融合在社交软件的三维度会话空间内,此外在上述示例中场景机器人可以不参与会话,在后台运行仅仅监听分析其他主体的会话内容,构建会话的场景。
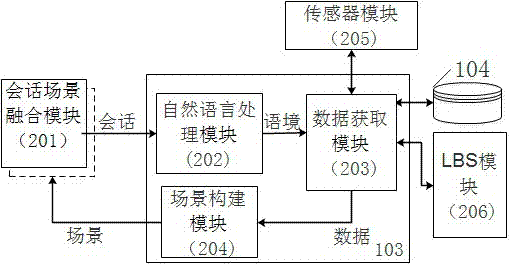
在系统结构上如图2所示,包括会话场景融合模块(201)、自然语言处理模块(202)、数据获取模块(203)、场景构建模块(204),在连接关系上会话场景融合模块(201)→自然语言处理模块(202)→数据获取模块(203)→场景构建模块(204)→会话场景融合模块(201)构成闭环的连接回路;数据获取模块(203)连接到传感器模块(205)、lbs模块(206)、数据库模块(104);场景融合模块(201)实现生成场景与会话融合\或在时空中关联依赖存在,即实现本发明的系统。
与现有方法和系统的区别
与现有的社交软件的场景构建方法相比,主要具有以下区别:
1.场景机器人应用自然语言处理(nlu)分析和理解会话的上下文,获取会话的语境信息实现从语境到场景的构建,而不是现有方法和系统对会话内容匹配关键词而构建场景。
与现有的qq和微信的掉表情大法相比,主要具有以下区别:
现有掉表情大法的方法和系统使用预设关键词匹配情景表情,在聊天记录中匹配预设关键词,再显示对应的预设表情,而本发明是根据对会话的上下文内容的语境理解去匹配数据库,再构建场景,不含预设关键词和对应的表情。
例如以下会话1:
a:我昨天去参观牛顿纪念馆了
b:牛顿是谁
会话2:
a:我昨天去参观牛顿纪念馆了
b:我也一直想去,可惜太忙了
对于现有的方法,假设“牛顿”是一个预设关键词,那么在这个两个会话中都会显示与该关键词对应的表情;而使用本发明的方法,场景机器人会根据会话理解判断会话1的主体b不知道牛顿是谁,于是场景机器人关联“牛顿”关键词到数据库,获取相关信息(例如牛顿的照片、文字或图像介绍等)后,在场景中融合显示,增强了对会话内容的表现力;对于会话2,场景机器人可以判断出主体双方都知道牛顿是谁,此时不需要场景机器人帮助构建场景。
2.现有方法和系统的预设关键词和情景表情是固定的对应关系,而本发明会话内容和场景之间不存在预设的确定性关系,突出的是会话内容和场景之间的逻辑关系。
例如会话3:
a:我昨天去参观牛顿纪念馆了
b:我也一直想去,但是不知道在哪里
对于现有的方法,假设“牛顿”是一个预设关键词,那么现有方法显示与该关键词对应的表情,预设关键词和情景表情是固定的对应关系;而使用本发明的方法,场景机器人可以判断出主体双方都知道牛顿是谁,只是b不知道“牛顿纪念馆在哪里”,于是场景机器人可以关联数据库查找到“牛顿纪念馆“的位置信息,也可以调用电子地图模块生成导航地图,用其构建会话的场景,因此本发明会话内容和场景之间不存在预设的确定性关系,因会话内容和场景之间的因果关系的变化,而产生出始料未及的结果。
3.现有方法和系统的预设表情不能自主更新,而本发明的方法可以随着人类知识库和资讯的更新而同步更新。
4.与现有的文本到3维图片的wordseye的场景构建方法相比,主要具有以下区别:
.a.wordseye表达构建的文本中的空间逻辑关系,无法依据会话内容的知识性(如图4、8)、抽象性(如图8)、逻辑性(如图8)、资讯性(如图5)和语言行为(如图7)去构建场景
b.wordseye面对的是一个主体的语言描述,而本发明面对的是多个主体的共同语言描述。
3.wordseye构建的是三维的静止的空间场景,而本发明可以构建动态的二维或者三维的静态或动态的场景。
有益效果
对比现有方法和系统对比,主要具有以下优点:
1.本发明的方法根据会话语境去构建场景,实现了语境到场景的转换,增强了人对会话内容意义的理解,避免了现有方法和系统的多余和单调重复的表情,增强了情趣和表现力。
2.本发明的方法可以随着人类知识库和资讯的更新而同步更新,而现有方法和系统的预设表情不能自主更新。
附图说明
图1是本发明方法原理图
图2是本发明系统图
图3是实施案例
图4是会话情景1
图5是会话情景2
图6是会话情景3
图7是会话情景4
图8是会话情景5-1
图9是会话情景5-2
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
实施例1
采用本发明方法,如图3所示,云端服务器(300)、数据库(304)、互联网(301)、智能手机(305)和(306)组成了本发明的系统,数据库(304)包含知识库系统(例如opencyc)、历史、地理、文化、人物、气候、物产、旅游、新闻等人类已知的各种知识和资讯,智能手机(305)和(306)含有一系列传感器和lbs模块,即实现本发明实施案例。
参考文献
[1]聊天机器人chatterbot.techtargetsoa[引用日期2015-08-19]
[2]语用学.百度百科
[3]王燚.基于场景化知识表示的自然语言处理及其在自动文本校对中的应用[d].西南交通大学2005
[4]李晗静.基于自然语言处理的空间概念建模研究[d].哈尔滨工业大学2007
[5]李新德,张秀龙.一种面向室内智能机器人导航的路径自然语言处理方法[j].自动化学报.2014(02)
- 还没有人留言评论。精彩留言会获得点赞!