一种句子相似度计算方法和系统与流程
本发明涉及自然语言处理领域,尤其涉及一种句子相似度计算方法和系统。
背景技术:
相似度计算是自然语言处理的基础工作。目前句子相似度计算方法主要有4类,分别是基于词重叠的方法、基于语料库统计的方法、基于语言学的方法和混合方法。
基于词重叠的方法是用一组通过两个句子所共有的一些词汇量来计算句子的相似度的度量方法。Jacob等[4]提出Jaccard相似系数法,该方法计算两个句子中词语交集与两句子中词语并集的比值来计算句子的相似度。Metzler等[5]使用逆文档频率(IDF)作为两个句子中均出现的词语的权重,改进计算结果。Banerjee等[6]基于短语的长度和它们的使用频率呈Zipfian分布的特点来设计基于短语的句子相似度计算方法。
基于语料库的方法将句子对中出现的词语集合用来作为特征集,将基于语料库的向量的余弦夹角值作为相似度。Landauer等[7]通过分析一个大型的自然语言语料库来统计关键词的TF-IDF值形成句子语义向量,用向量的余弦夹角来计算句子语义相似度。Lund等[8]统计词汇之间的共现性得到高维向量空间来计算句子或短文档相似度。
基于语言学的方法利用词汇间的语义关系及其语法成分来确定句子的相似度。Kashyap等[9]基于词语语义相似度度量句子间的相似度,考虑单词具有不同的区分能力来进行句子向量的相似度计算方法。Malik等[10]将组成句子对的词之间的相似度的总和的最大值被句子长度归一化所得值作为句子相似度值。
混合方法是基于以上方法的混合方法。Chukfong等[11-14]基于以上多种方法实现句子相似度计算。
现在基于结构化表示的句子相似度计算工作比较少,Aliaksei[15]提出了一种基于简单结构化表示的计算方法。
现有句子相似度计算专利:
一种基于语义的相似度计算方法和装置:此发明提供了一种基于语义的相似度计算方法和装置,其中方法包括:获取待比较的句子S1和S2;分别对所述S1和S2进行分词;对所述分词后得到的各词语中存在语义映射的词语映射为归一化的表述;计算经步骤C处理后的S1和S2之间的相似度Sim(S1,S2)。本发明通过将句子中存在语义映射的词语映射到归一化的表述,并将其融入相似度的计算,从而在语义上体现句子之间的相似度而不仅仅是字面上的相似程度,提高了计算句子之间相似度的准确性。
句子相似度计算方法及装置:此发明提供一种准确度高的句子相似度计算方法及装置。该句子相似度计算方法,包括:针对第一句子和第二句子确定重复词、第一孤存词和第二孤存词,其中,重复词既属于第一句子又属于第二句子,第一孤存词仅属于第一句子,第二孤存词仅属于第二句子;根据所有第一孤存词和所有第二孤存词,计算孤存词相似度总贡献值G总,其中,G总≥0,并且所有第一孤存词与所有第二孤存词之间的相似程度越高,G总数值越大;根据公式计算SIM(A,B),其中SIM(A,B)表示第一句子和第二句子的句子相似度,G总表示第一句子对应的第一句向量,G总表示第二句子对应的第二句向量。
一种句子相似度的计算方法及系统:此发明提供了一种句子相似度的计算方法及系统,通过利用word2vec算法,对预先建立的语料库进行训练,得到语料库中所有词语的向量;对待计算相似度的两个句子进行智能分词,并从语料库中查找出所述第一句子和第二句子中各个分词所对应的向量,依次计算第一句子每个分词与第二句子各个分词之间的相似度;获取分词之间的相似度超过预定阈值的两组分词集合,并根据所述每组分词位于句子位置的偏移量,计算每组分词在整个句子中相似度的贡献值;将两个句子中分词的贡献值相加,得到句子之间的相似度。
现存的大多数句子相似度计算方法使用大量平面相似性特征来表示一对句子的相似程度。仅使用平面特征向量代表句子对相似度的问题是其表征性较弱。
最新的一些相似度计算方法,依赖于词的搭配和从大数据中获得的知识(维基百科等)来进行相似度计算,不考虑句子句法等结构化信息。假设给定两个句子S1和S2,这些方法一般会做如下处理:第一步,S1中的每个单词将会与在S2中与它相似度最高的单词配对。第二步,所有的配对词间的相似度累加,并通过S1的句长对相似度进行规范化处理,进而得到句子S1与S2的相似度。
现分析一对句子S1:Tigers hit lions S2:Lions hit tigers。通过上述提到的方法,S1中的每个单词会在S2中找到相似度极高的单词(在本例中即为相同的单词)配对,从而相似度计算结果会认为则两句句子含义相同。如图1所示,分析S1、S2的依存关系树得出它们的施事者和受事者颠倒。虽然两句句子中出现的单词相同,但是通过分析其依存关系树,可以得出它们的含义并不同。
句法结构等结构化信息是自然语言处理应用里非常重要的信息。但是,如何在各种任务中利用结构化信息却是普遍存在的问题。在使用平面特征向量表示结构化特征时,当结构化特征转化为平面特征时,可能会丢失部分有效信息。
有鉴于上述的缺陷,本设计人,积极加以研究创新,在基于简单结构化表示的计算方法基础上,提出一种新的结构化表示方法,用于句子相似度计算,以体现句子语法、语义、依存关系。
术语解释:
皮尔逊相关系数(Pearson Correlation Coefficient):用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。在自然科学领域中,该系数广泛用于度量两个变量之间的相关程度。
支持向量回归模型(Support Vector Regression,简称SVR):主要是通过升维后,在高维空间中构造线性决策函数来实现线性回归,用e不敏感函数时,其基础主要是e不敏感函数和核函数算法。若将拟合的数学模型表达多维空间的某一曲线,则根据e不敏感函数所得的结果,就是包括该曲线和训练点的“e管道”。在所有样本点中,只有分布在“管壁”上的那一部分样本点决定管道的位置。这一部分训练样本称为“支持向量”。为适应训练样本集的非线性,传统的拟合方法通常是在线性方程后面加高阶项。此法诚然有效,但由此增加的可调参数未免增加了过拟合的风险。支持向量回归算法采用核函数解决这一矛盾。用核函数代替线性方程中的线性项可以使原来的线性算法“非线性化”,即能做非线性回归。与此同时,引进核函数达到了“升维”的目的,而增加的可调参数是过拟合依然能控制。
核方法(Kernel Methods):隐含着一个从低维空间到高维空间的映射,而这个映射可以把低维空间中线性不可分的两类点变成线性可分的。用于支持向量机。
树核方法(Tree Kernel Methods):通过直接计算两个实体关系对象(即句法树)的相同子树的个数来比较相似度。
命名实体识别(Named Entity Recognition,简称NER):又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。
WordNet:是由普林斯顿大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”。它是一个覆盖范围宽广的英语词汇语义网。名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接。
树:树状图是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:每个节点有零个或多个子节点;没有父节点的节点称为根节点;每一个非根节点有且只有一个父节点;除了根节点外,每个子节点可以分为多个不相交的子树。
N-gram模型:N-Gram是大词汇连续识别中常用的一种语言模型,模型利用上下文中相邻词间的搭配信息,可以计算出具有最大概率的句子。
参考文献
[1]Culotta A,Sorensen J.Dependency tree kernels for relation extraction[C]//Meeting of the Association for Computational Linguistics,21-26July,2004,Barcelona,Spain.2010:423--429.
[2]Bunescu R C,Mooney R J.A shortest path dependency kernel for relation extraction[C]//Conference on Human Language Technology and Empirical Methods in Natural Language Processing.Association for Computational Linguistics,2005:724-731.
[3]Zhang M,Zhang J,Su J,et al.A Composite Kernel to Extract Relations between Entities with Both Flat and Structured Features.[C]//International Conference on Computational Linguistics and Meeting of the Association for Computational Linguistics,17-21 July.2006,Sydney,Australia.
[4]Jacob B,Benjamin C.Calculating the Jaccard Similarity Coefficient with Map Reduce for Entity Pairs in Wikipedia[OL].http://www.infosci.cornell.edu/weblab/papers/Bank2008.pdf,2008
[5]Metzler D,Bernstein Y,Croft W B,et al.Similarity measures for tracking information flow[C]//ACM CIKM International Conference on Information and Knowledge Management,Bremen,Germany,October 31-November.2005:517-524.
[6]Banerjee S,Pedersen T.Extended gloss overlap as a measure of semantic relatedness[c]∥Proceedings of International Joint Conference on Artificial Intelligence.2003:805-810
[7]Landauer T K,Foltz P W,Laham D.Introduction to Latent Semantic Analysis[J].Discourse Processes,1998,25(2/3):259-284
[8]Lund K,Burgess C.Producing high-dimensional semantic spaces from lexical co-occurrence[J].Behavior Research Methods,Instruments&Computers,1996,28(2):203-208
[9]Kashyap A,Han L,Yus R,et al.Robust semantic text similarity using LSA,machine learning,and linguistic resources[J].Language Resources&Evaluation,2016,50(1):125-161.
[10]Malik R,Subramaniam L V,Kaushik S.Automatically Selecting Answer Templates to Respond to Customer Emails.[C]//IJCAI 2007,Proceedings of the,International Joint Conference on Artificial Intelligence,Hyderabad,India,January.2007:1659-1664.
[11]Jaffe E,Jin L,King D,et al.AZMAT:Sentence Similarity Using Associative Matrices[C]//International Workshop on Semantic Evaluation.2015.
[12]Haque R,Naskar S K,Way A,et al.Sentence Similarity-Based Source Context Modelling in PBSMT[C]//International Conference on Asian Language Processing,Ialp 2010,Harbin,Heilongjiang,China,28-30December.2010:257-260.
[13]Li R,Li S,Zhang Z.The Semantic Computing Model of Sentence Similarity Based on Chinese FrameNet[C]//2009IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology.IEEE Computer Society,2009:255-258.
[14]Liu Y,Liu Q.Chinese Sentence Similarity Based on Multi-feature Combination[C]//Intelligent Systems,2009.GCIS'09.WRI Global Congress on.2009:14-19.
Severyn A,Nicosia M,Moschitti A.Learning Semantic Textual Similarity with Structural Representations[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics.Sofia,2013:714-718.
技术实现要素:
为解决上述技术问题,本发明的目的是提供一种句子相似度计算方法和系统,是基于浅层句法树,提出的新的句法树结构,使结构化特征更能表现句子的句法语义等信息,并把该句法树应用于句子相似度计算,以获得良好的性能。
本发明的句子相似度计算方法,其特征在于,包括步骤:
S10、对句子对训练文本和句子对测试文本中所有句子调用词性标注、句法分析、命名实体识别、WordNet识别工具分别进行词性标注、句法分析、命名实体识别、WordNet识别获得词性标注训练文本、短语训练文本、命名实体训练文本、WordNet训练文本和词性标注测试文本、短语测试文本、命名实体测试文本、WordNet测试文本,
其中,所述句子对训练文本和句子对测试文本为每行含有两句需要计算相似度的句子的文本;
S20、基于词性标注训练文本、短语训练文本、命名实体训练文本、WordNet训练文本获得浅层句法树训练文本,
基于词性标注测试文本、短语测试文本、命名实体测试文本、WordNet测试文本获得浅层句法树测试文本;
S30、基于句子对训练文本对每行一对句子获得多个平面特征,得到平面特征训练文本,将平面特征训练文本,浅层句法树训练文本与句子对人工评分训练文本结合得到浅层句法树特征训练文本,
基于句子对测试文本对每行一对句子获得多个平面特征,得到平面特征测试文本,将平面特征测试文本与浅层句法树测试文本结合得到浅层句法树特征测试文本;
S40、使用SVR模型基于浅层句法树特征训练文本进行训练,得到训练模型,由训练模型和浅层句法树特征测试文本获得相似度计算结果文本。
进一步的,所述步骤S10的具体过程如下:
S101、对句子对训练文本中所有句子使用词性标注工具(如:Stanford postagger)获得句子中每个单词的词性,获得对应的词性标注训练文本;
对句子对测试文本进行相同处理获得词性标注测试文本;
S102、对句子对训练文本中所有句子使用句法分析工具(如:Stanford parser)获得每个单词所属的短语,获得短语训练文本;
对句子对测试文本进行相同处理获得短语测试文本;
S103、基于句子对训练文本使用命名实体识别工具(如SST-light tagger)得到单词所属的命名实体识别结果,获得命名实体训练文本;
对句子对测试文本进行相同处理获得命名实体测试文本;
S104、基于句子对训练文本使用WordNet识别工具(如:SST-light tagger)获得单词所属的WordNet上义(WNSS),如果没有WordNet上义用空格表示,得到WordNet训练文本;
对句子对测试文本进行相同处理获得WordNet测试文本。
进一步的,所述步骤S20的具体过程如下:
S201、根据词性标注训练文本,为句子对训练文本中的每个句子构造浅层句法树,得到基本浅层句法树训练文本;由句子对测试文本和词性标注测试文本得到基本浅层句法树测试文本;
其中,浅层句法树是是深度为3的树,构造方法如下:把一个句子中的词语生成为最底层的叶子节点;把每个叶子节点对应词的词性作为每个叶子节点的父节点;最后,设置所有的词性节点的父节点为根节点;
S202、根据短语训练文本,为基本浅层句法树训练文本中的每个句子构造更深一层的浅层句法树获得短语浅层句法树训练文本;基于短语测试文本和基本浅层句法树测试文本获得短语浅层句法树测试文本;
其中,更深一层的浅层句法树是深度为4的树,构造方法如下:由句子短语识别结果,获得属于同一短语单词的信息;将属于同一短语的单词叶节点的词性父节点上连接到同一chunker节点;断开根节点与词性节点之间的联系,将chunker节点连接到对应的词性节点;最后,设置所有的词性节点的父节点为根节点;
S203、基于短语浅层句法树训练文本、命名实体训练文本和WordNet训练文本获得语义浅层句法树训练文本;基于短语浅层句法树测试文本、命名实体测试文本和WordNet测试文本获得语义浅层句法树测试文本;
语义浅层句法树训练文本是在短语浅层句法树训练文本上加入语义信息,具体方法如下:如果短语浅层句法树训练文本中的一个单词在命名实体训练文本和WordNet训练文本中有NER或WNSS信息,将包含该单词的chunker节点的句法信息修改成NER或WNSS信息;如果一个词组节点中含有多个单词符合上述情况,使用词组内最后一个单词的NER和WNSS信息;
S204、基于语义浅层句法树训练文本删除定冠词和连词相关节点,获得修剪浅层句法树训练文本;基于语义浅层句法树测试文本删除定冠词和连词相关节点,获得修剪浅层句法树测试文本;
本发明在结构化表示中裁减掉定冠词和连词以及他们的父亲节点(词性节点),减少非重要信息对计算结果的影响,在浅层句法树中如果某叶子节点代表的单词是冠词或者连词,删除该叶子节点,及其父亲节点(词性节点)和父亲的父亲节点(chunker节点);
S205、基于修剪浅层句法树训练文本,将一对句子的浅层句法树相关部分关联起来获得浅层句法树训练文本;基于修剪浅层句法树测试文本,将一对句子的浅层句法树相关部分关联起来获得浅层句法树测试文本;
其中,将一对句子对应的浅层句法树关联起来的方法:两个句子中某个单词如果相同(叶子节点相同),得到它们的父亲节点(词性节点)、祖父节点且为非终节点,标记上REL。
进一步的,所述步骤S30的具体过程如下:
S301、基于句子对训练文本获得平面特征训练文本,基于句子对测试文本获得平面特征测试文本;
其中,平面特征训练文本和平面特征测试文本分别为句子对训练文本和句子对测试文本中每行一对句子的相似度计算平面特征;
本发明提供11个平面特征:
1、最长公共子串方法计算结果:计算最长连续字符序列的长度;
2、最长公共子序列方法计算结果:相比最长公共子串方法没有连续性的要求,并允许在单词的插入或缺失的情况下计算相似度;
3、贪婪的字符串拼接方法计算结果:允许文本乱序来计算共同的相似子串的部分,每个子串匹配的最大长度;
4、5、6、7基于字符n-gram的句子编辑距离计算结果:假设有一个句子s,那么该字符串的N-Gram就表示按长度N切分原词得到的词段,也就是s中所有长度为N的子字符串;设想如果有两个字符串,然后分别求它们的N-Gram,那么就从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram距离,N=1,2,3,4,共四个特征;
8,9,10,11基于单词n-gram的句子编辑距离计算结果:与特征4,5,6,7相似,将以字符为切分单位换成以单词为切分单位;
S302、由平面特征训练文本与浅层句法树训练文本获得浅层句法树特征训练文本;由平面特征测试文本与浅层句法树测试文本获得浅层句法树特征测试文本;
其中,浅层句法树特征训练文本和浅层句法树特征测试文本每行包含对应的句子对的十个平面特征和一对浅层句法树特征。
进一步的,所述步骤S40的具体过程如下:
S401、使用SVR获得相似度计算模型,由浅层句法树特征训练文本在SVR模型中进行训练获得训练模型;
S402、把训练模型以及浅层句法树特征测试文本作为输入,利用SVR工具获得相似度计算结果文本;
其中,相似度计算结果文本每行的数值对应于句子对测试文本每行一对句子的相似度计算结果。
本发明的句子相似度计算系统,包括:
-预处理模块,对句子对训练文本和句子对测试文本中所有句子调用词性标注、句法分析、命名实体识别、WordNet识别工具分别进行词性标注、句法分析、命名实体识别、WordNet识别获得词性标注训练文本、短语训练文本、命名实体训练文本、WordNet训练文本和词性标注测试文本、短语测试文本、命名实体测试文本、WordNet测试文本;
-基于浅层句法树的结构化特征模块,基于词性标注训练文本、短语训练文本、命名实体训练文本、WordNet训练文本获得浅层句法树训练文本;
基于词性标注测试文本、短语测试文本、命名实体测试文本、WordNet测试文本获得浅层句法树测试文本;
-基于浅层句法树的相似度计算的特征集模块,基于句子对训练文本对每行一对句子获得多个平面特征,得到平面特征训练文本,将平面特征训练文本、浅层句法树训练文本与句子对人工评分训练文本结合得到浅层句法树特征训练文本;
基于句子对测试文本对每行一对句子获得多个平面特征,得到平面特征测试文本,将平面特征测试文本与浅层句法树测试文本结合得到浅层句法树特征测试文本;
-基于浅层句法树的相似度计算模块,使用SVR模型基于浅层句法树特征训练文本进行训练,得到训练模型,由训练模型和浅层句法树特征测试文本获得相似度计算结果文本。
进一步的,所述预处理模块具体包括:
-词性标注单元,对句子对训练文本中所有句子使用词性标注工具(如:Stanford postagger)获得句子中每个单词的词性,获得对应的词性标注训练文本;
对句子对测试文本进行相同处理获得词性标注测试文本;
-短语标注单元,对句子对训练文本中所有句子使用句法分析工具(如:Stanford parser)获得每个单词所属的短语,获得短语测试文本;对句子对测试文本进行相同处理获得短语测试文本;
-命名实体识别单元,基于句子对训练文本使用命名实体识别工具(如SST-light tagger)得到单词所属的命名实体识别结果,获得命名实体训练文本,对句子对测试文本进行相同处理获得命名实体测试文本;
-WordNet识别单元,基于句子对训练文本使用WordNet识别工具(如:SST-light tagger)获得单词所属的WordNet上义(WNSS),如果没有WordNet上义用空格表示,得到WordNet训练文本,对句子对测试文本进行相同处理获得WordNet测试文本。
进一步的,所述基于浅层句法树的结构化特征模块具体包括:
-基本浅层句法树单元,根据词性标注训练文本,为句子对训练文本中的每个句子构造浅层句法树,得到基本浅层句法树训练文本;由句子对测试文本和词性标注测试文本得到基本浅层句法树测试文本;
其中,浅层句法树是是深度为3的树,构造方法如下:把一个句子中的词语生成为最底层的叶子节点;把每个叶子节点对应词的词性作为每个叶子节点的父节点;最后,设置所有的词性节点的父节点为根节点;
-加入短语级句法结构的浅层句法树单元,根据短语训练文本,为基本浅层句法树训练文本中的每个句子构造更深一层的浅层句法树获得短语浅层句法树训练文本;基于短语测试文本和基本浅层句法树测试文本获得短语浅层句法树测试文本;
其中,更深一层的浅层句法树是深度为4的树,构造方法如下:由句子短语识别结果,获得属于同一短语单词的信息;将属于同一短语的单词叶节点的词性父节点上连接到同一chunker节点;断开根节点与词性节点之间的联系,将chunker节点连接到对应的词性节点;最后,设置所有的词性节点的父节点为根节点;
-加入语义的浅层句法树单元,基于短语浅层句法树训练文本,命名实体训练文本和WordNet训练文本获得语义浅层句法树训练文本;基于短语浅层句法树测试文本、命名实体测试文本和WordNet测试文本获得语义浅层句法树测试文本;
语义浅层句法树训练文本是在短语浅层句法树训练文本上加入语义信息,具体方法如下:如果短语浅层句法树训练文本中的一个单词在命名实体训练文本和WordNet训练文本中有NER或WNSS信息,将包含该单词的chunker节点的句法信息修改成NER或WNSS信息;如果一个词组节点中含有多个单词符合上述情况,使用词组内最后一个单词的NER和WNSS信息;
-删除非重要信息的浅层句法树单元,基于语义浅层句法树训练文本删除定冠词和连词相关节点,获得修剪浅层句法树训练文本;基于语义浅层句法树测试文本删除定冠词和连词相关节点,获得修剪浅层句法树测试文本;
本发明在结构化表示中裁减掉定冠词和连词以及他们的父亲节点(词性节点),减少非重要信息对计算结果的影响。在浅层句法树中如果某叶子节点代表的单词是冠词或者连词,删除该叶子节点,及其父亲节点(词性节点)和父亲的父亲节点(chunker节点);
-句子对联合表示单元,基于修剪浅层句法树训练文本,将一对句子的浅层句法树相关部分关联起来获得浅层句法树训练文本;基于修剪浅层句法树测试文本,将一对句子的浅层句法树相关部分关联起来获得浅层句法树测试文本;
其中,将一对句子对应的浅层句法树关联起来的方法:两个句子中某个单词如果相同,得到它们的父亲节点、祖父节点且为非终节点,标记上REL。
进一步的,所述基于浅层句法树的相似度计算的特征集模块具体包括:
-平面特征集单元,基于句子对训练文本获得平面特征训练文本,基于句子对测试文本获得平面特征测试文本;
其中,平面特征训练文本和平面特征测试文本分别为句子对训练文本和句子对测试文本中每行一对句子的相似度计算平面特征;
本发明提供11个平面特征。
1、最长公共子串方法计算结果:计算最长连续字符序列的长度;
2、最长公共子序列方法计算结果:相比最长公共子串方法没有连续性的要求,并允许在单词的插入或缺失的情况下计算相似度;
3、贪婪的字符串拼接方法计算结果:允许文本乱序来计算共同的相似子串的部分,每个子串匹配的最大长度;
4、5、6、7基于字符n-gram的句子编辑距离计算结果:假设有一个句子s,那么该字符串的N-Gram就表示按长度N切分原词得到的词段,也就是s中所有长度为N的子字符串;设想如果有两个字符串,然后分别求它们的N-Gram,那么就从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram距离,N=1,2,3,4,共四个特征;
8、9、10、11基于单词n-gram的句子编辑距离计算结果:与特征4、5、6、7相似,将以字符为切分单位换成以单词为切分单位;
-浅层句法树特征集单元,由平面特征训练文本与浅层句法树训练文本获得浅层句法树特征训练文本,由平面特征测试文本与浅层句法树测试文本获得浅层句法树特征测试文本;
其中,浅层句法树特征训练文本和浅层句法树特征测试文本每行包含对应的句子对的十个平面特征和一对浅层句法树特征。
进一步的,所述基于浅层句法树的相似度计算模块具体包括:
-训练单元,使用SVR获得相似度计算模型,由浅层句法树特征训练文本在SVR模型中进行训练获得训练模型;
-测试单元,把训练模型以及浅层句法树特征测试文本作为输入,利用SVR工具获得相似度计算结果文本;
其中,相似度计算结果文本每行的数值对应于句子对测试文本每行一对句子的相似度计算结果。
借由上述方案,本发明至少具有以下优点:
1、本发明提出的基于结构化表示的句子相似度计算方法和系统,解决了仅使用平面特征向量来代表句子对相似度的表征性较弱问题;
2、与基于特征向量的方法不同,本发明使用树核函数直接计算两个结构化特征(例如依存树)的相同子树个数来比较相似度,基于树核函数的方法不需要构造高维特征向量空间,树核函数方法以结构树为处理对象,通过直接计算两个离散对象(如语法结构树)之间的相似度来进行分类,这使得基于树核函数的方法理论上可探索隐含的高维特征空间,从而可以有效地利用句法树等结构化信息;
3、本发明基于浅层句法树,提出了一种新的句法树结构,使结构化特征更能表现句子的句法语义等信息,并把该句法树应用于句子相似度计算,获得了良好的性能。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
图1是背景技术中句子“Tigers hit lions”和“Lions hit tigers”的依存关系树示意图;
图2是是句子相似度计算系统结构图;
图3是预处理模块结构图;
图4是基于浅层句法树的结构化特征模块结构图;
图5是基于浅层句法树的相似度计算的特征集模块结构图;
图6是基于浅层句法树的相似度计算模块结构图`;
图7是句子相似度计算方法流程图;
图8是预处理模块流程图;
图9是基于浅层句法树的结构化特征模块流程图;
图10是基于浅层句法树的相似度计算的特征集模块流程图;
图11是基于浅层句法树的相似度计算模块流程图;
图12是基本浅层句法树的例子;
图13是短语浅层句法树的例子;
图14是语义浅层句法树的例子;
图15是修剪浅层句法树的例子;
图16是联合浅层句法的例子。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
本发明句子相似度计算的目标是学习一个得分系统,给定一对句子,该系统返回相似度得分,分数范围为0~5。0代表这对句子的含义完全无关,5代表这对句子含义相同。系统的性能由系统计算分数和人工评判分数的皮尔逊相关性系数评估。
为了简化说明流程,下面将结合例图说明本发明的实施过程。
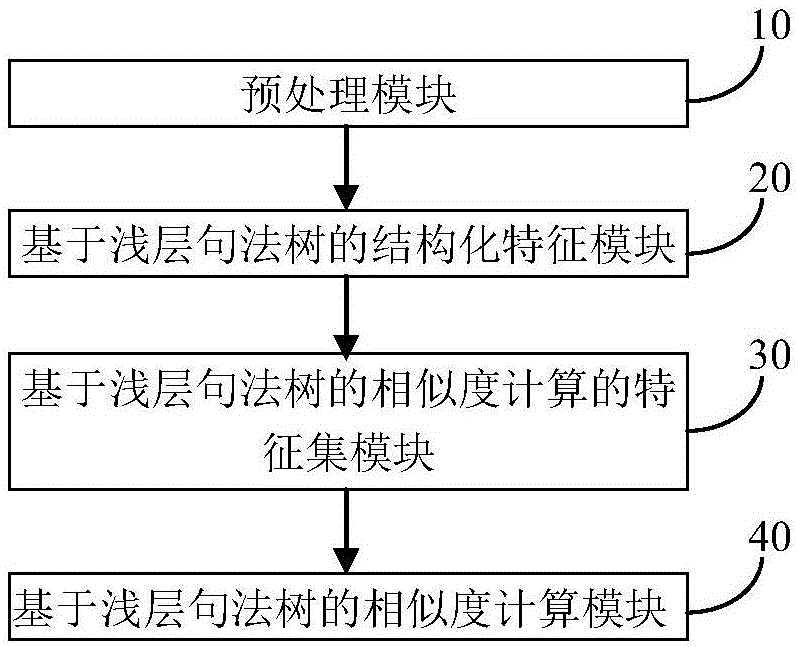
基于结构化特征的句子相似度计算系统,如图2所示,包括:
-预处理模块10,对句子对训练文本和句子对测试文本中所有句子调用词性标注、句法分析、命名实体识别、WordNet识别工具分别进行词性标注、句法分析、命名实体识别、WordNet识别获得词性标注训练文本、短语训练文本、命名实体训练文本、WordNet训练文本和词性标注测试文本、短语测试文本、命名实体测试文本、WordNet测试文本;
-基于浅层句法树的结构化特征模块20,基于词性标注训练文本、短语训练文本、命名实体训练文本、WordNet训练文本获得浅层句法树训练文本;
基于词性标注测试文本、短语测试文本、命名实体测试文本、WordNet测试文本获得浅层句法树测试文本;
-基于浅层句法树的相似度计算的特征集模块30,基于句子对训练文本对每行一对句子获得多个平面特征,得到平面特征训练文本,将平面特征训练文本、浅层句法树训练文本与句子对人工评分训练文本结合得到浅层句法树特征训练文本;
基于句子对测试文本对每行一对句子获得多个平面特征,得到平面特征测试文本,将平面特征测试文本与浅层句法树测试文本结合得到浅层句法树特征测试文本;
-基于浅层句法树的相似度计算模块40,使用SVR模型基于浅层句法树特征训练文本进行训练,得到训练模型,由训练模型和浅层句法树特征测试文本获得相似度计算结果文本。
如图3所示,预处理模块10具体包括:
-词性标注单元101,对句子对训练文本中所有句子使用词性标注工具获得句子中每个单词的词性,获得对应的词性标注训练文本;
对句子对测试文本进行相同处理获得词性标注测试文本;
-短语标注单元102,对句子对训练文本中所有句子使用句法分析工具获得每个单词所属的短语,获得短语测试文本;对句子对测试文本进行相同处理获得短语测试文本;
-命名实体识别单元103,基于句子对训练文本使用命名实体识别工具得到单词所属的命名实体识别结果,获得命名实体训练文本,对句子对测试文本进行相同处理获得命名实体测试文本;
-WordNet识别单元104,基于句子对训练文本使用WordNet识别工具获得单词所属的WordNet上义,如果没有WordNet上义用空格表示,得到WordNet训练文本,对句子对测试文本进行相同处理获得WordNet测试文本。
如图4所示,基于浅层句法树的结构化特征模块20具体包括:
-基本浅层句法树单元201,根据词性标注训练文本,为句子对训练文本中的每个句子构造浅层句法树,得到基本浅层句法树训练文本;由句子对测试文本和词性标注测试文本得到基本浅层句法树测试文本;
其中,浅层句法树构造方法如下:把一个句子中的词语生成为最底层的叶子节点;把每个叶子节点对应词的词性作为每个叶子节点的父节点;最后,设置所有的词性节点的父节点为根节点;
-加入短语级句法结构的浅层句法树单元202,根据短语训练文本,为基本浅层句法树训练文本中的每个句子构造更深一层的浅层句法树获得短语浅层句法树训练文本;基于短语测试文本和基本浅层句法树测试文本获得短语浅层句法树测试文本;
其中,更深一层的浅层句法树构造方法如下:由句子短语识别结果,获得属于同一短语单词的信息;将属于同一短语的单词叶节点的词性父节点上连接到同一chunker节点;断开根节点与词性节点之间的联系,将chunker节点连接到对应的词性节点;最后,设置所有的词性节点的父节点为根节点;
-加入语义的浅层句法树单元203,基于短语浅层句法树训练文本,命名实体训练文本和WordNet训练文本获得语义浅层句法树训练文本;基于短语浅层句法树测试文本、命名实体测试文本和WordNet测试文本获得语义浅层句法树测试文本;
语义浅层句法树训练文本是在短语浅层句法树训练文本上加入语义信息,具体方法如下:如果短语浅层句法树训练文本中的一个单词在命名实体训练文本和WordNet训练文本中有NER或WNSS信息,将包含该单词的chunker节点的句法信息修改成NER或WNSS信息;如果一个词组节点中含有多个单词符合上述情况,使用词组内最后一个单词的NER和WNSS信息;
-删除非重要信息的浅层句法树单元204,基于语义浅层句法树训练文本删除定冠词和连词相关节点,获得修剪浅层句法树训练文本;基于语义浅层句法树测试文本删除定冠词和连词相关节点,获得修剪浅层句法树测试文本;
-句子对联合表示单元205,基于修剪浅层句法树训练文本,将一对句子的浅层句法树相关部分关联起来获得浅层句法树训练文本;基于修剪浅层句法树测试文本,将一对句子的浅层句法树相关部分关联起来获得浅层句法树测试文本;
其中,将一对句子对应的浅层句法树关联起来的方法:两个句子中某个单词如果相同,得到它们的父亲节点、祖父节点且为非终节点,标记上REL。
如图5所示,所述基于浅层句法树的相似度计算的特征集模块30具体包括:
-平面特征集单元301,基于句子对训练文本获得平面特征训练文本,基于句子对测试文本获得平面特征测试文本;
其中,平面特征训练文本和平面特征测试文本分别为句子对训练文本和句子对测试文本中每行一对句子的相似度计算平面特征;
-浅层句法树特征集单元302,由平面特征训练文本与浅层句法树训练文本获得浅层句法树特征训练文本,由平面特征测试文本与浅层句法树测试文本获得浅层句法树特征测试文本。
如图6所示,所述基于浅层句法树的相似度计算模块40具体包括:
-训练单元401,使用SVR获得相似度计算模型,由浅层句法树特征训练文本在SVR模型中进行训练获得训练模型;
-测试单元402,把训练模型以及浅层句法树特征测试文本作为输入,利用SVR工具获得相似度计算结果文本;
其中,相似度计算结果文本每行的数值对应于句子对测试文本每行一对句子的相似度计算结果。
基于结构化特征的句子相似度计算方法,如图7所示,包括:
S10、对句子对训练文本和句子对测试文本中所有句子调用词性标注、句法分析、命名实体识别、WordNet识别工具分别进行词性标注、句法分析、命名实体识别、WordNet识别获得词性标注训练文本、短语训练文本、命名实体训练文本、WordNet训练文本和词性标注测试文本、短语测试文本、命名实体测试文本、WordNet测试文本;
所述句子对训练文本和句子对测试文本为每行含有两句需要计算相似度的句子的文本。
S20、基于词性标注训练文本、短语训练文本、命名实体训练文本、WordNet训练文本获得浅层句法树训练文本;
基于词性标注测试文本、短语测试文本、命名实体测试文本、WordNet测试文本获得浅层句法树测试文本。
S30、基于句子对训练文本对每行一对句子获得11个平面特征,得到平面特征训练文本,将平面特征训练文本、浅层句法树训练文本与句子对人工评分训练文本结合得到浅层句法树特征训练文本;
基于句子对测试文本对每行一对句子获得11个平面特征,得到平面特征测试文本,将平面特征测试文本与浅层句法树测试文本结合得到浅层句法树特征测试文本。
S40、使用SVR模型基于浅层句法树特征训练文本进行训练,得到训练模型,由训练模型和浅层句法树特征测试文本获得相似度计算结果文本。
其中,如图8所示,S10的具体过程如下:
S101、对句子对训练文本中所有句子使用词性标注工具(如:Stanford postagger)获得句子中每个单词的词性,获得对应的词性标注训练文本。
对句子对测试文本进行相同处理获得词性标注测试文本。
例1:“A woman and man are dancing in the rain”经过词性标注后得到:
例2:“DT NN CC NN VBP VBG IN DT NN”。
其中,DT表示定冠词,NN表示名词,CC表示连词,VBP表示动词第三人称单数,VBG表示动名词和现在分词,IN表示介词或从属连词。
S102、对句子对训练文本中所有句子使用句法分析工具(如:Stanford parser)获得每个单词所属的短语,获得短语测试文本;对句子对测试文本进行相同处理获得短语测试文本。
例1进行短语识别得到4个短语:
例3:“NP(a woman and man)VP(bedance)PP(in)NP(the rain)”
其中NP表示名词短语,VP表示动词短语,PP表示介词短语。
S103、基于句子对训练文本使用命名实体识别工具(如SST-light tagger)得到单词所属的命名实体识别结果,获得命名实体训练文本;对句子对测试文本进行相同处理获得命名实体测试文本。
例1进行命名实体识别得到两个实体:
例4:“E:PER_DESC woman E:PER_DESC man”
其中E:PER_DESC表示识别出实体类型是人。
S104、基于句子对训练文本使用WordNet识别工具(如:SST-light tagger)获得单词所属的WordNet上义(WNSS);如果没有WordNet上义用空格表示,得到WordNet训练文本;对句子对测试文本进行相同处理获得WordNet测试文本。
例1进行WNSS识别得到:
例5:“female woman male man weather rain”
其中female,male,weather分别为woman,man,rain的WordNet上义。
如图9所示,S20的具体过程如下:
S201、根据词性标注训练文本,为句子对训练文本中的每个句子构造浅层句法树,得到基本浅层句法树训练文本;由句子对测试文本和词性标注测试文本得到基本浅层句法树测试文本。
其中,浅层句法树是是深度为3的树,构造方法如下:把一个句子中的词语生成为最底层的叶子节点,如例1中9个词就是9个叶子节点;把每个叶子节点对应词的词性作为每个叶子节点的父节点;最后,设置所有的词性节点的父节点为根节点。
例1经过构造浅层句法树如图12所示。
S202、根据短语训练文本,为基本浅层句法树训练文本中的每个句子构造更深一层的浅层句法树获得短语浅层句法树训练文本;基于短语测试文本和基本浅层句法树测试文本获得短语浅层句法树测试文本。
其中,更深一层的浅层句法树是深度为4的树,构造方法如下:由句子短语识别结果,获得属于同一短语单词的信息。将属于同一短语的单词叶节点的词性父节点上连接到同一chunker节点。如例1中9个单词属于4个短语就是4个chunker节点;断开根节点与词性节点之间的联系,将chunker节点连接到对应的词性节点,最后,设置所有的词性节点的父节点为根节点。
图12加一层chunker节点后如图13所示。
S203、基于短语浅层句法树训练文本,命名实体训练文本和WordNet训练文本获得语义浅层句法树训练文本;基于短语浅层句法树测试文本,命名实体测试文本和WordNet测试文本获得语义浅层句法树测试文本。
语义浅层句法树训练文本是在短语浅层句法树训练文本上加入语义信息,具体方法如下:如果短语浅层句法树训练文本中的一个单词在命名实体训练文本和WordNet训练文本中有NER或WNSS信息,将包含该单词的chunker节点的句法信息修改成NER或WNSS信息;如果一个词组节点中含有多个单词符合上述情况,使用词组内最后一个单词的NER和WNSS信息。
图13加入语义信息后如图14所示。
S204,基于语义浅层句法树训练文本删除定冠词和连词相关节点,获得修剪浅层句法树训练文本;基于语义浅层句法树测试文本删除定冠词和连词相关节点,获得修剪浅层句法树测试文本。
本发明将在结构化表示中裁减掉定冠词和连词以及他们的父亲节点(词性节点),减少非重要信息对计算结果的影响。在浅层句法树中如果某叶子节点代表的单词是冠词或者连词,删除该叶子节点,及其父亲节点(词性节点)和父亲的父亲节点(chunker节点)。如例1中9个单词中3个单词是定冠词和连词,删除这3个节点,和它们各自上面的两个节点。
图14经过删除非重点信息后如图15所示。
S205、基于修剪浅层句法树训练文本,将一对句子的浅层句法树相关部分关联起来获得浅层句法树训练文本;基于修剪浅层句法树测试文本,将一对句子的浅层句法树相关部分关联起来获得浅层句法树测试文本。
其中,将一对句子对应的浅层句法树关联起来的方法:两个句子中某个单词如果相同(叶子节点相同),得到它们的父亲节点(词性节点)、祖父节点且为非终节点,标记上REL。如例8中,两个句子的浅层句法树修剪后都有6个单词,第一句句子有4个单词在第二个句子中出现,将这些叶子节点(即两个句子中相同单词的节点)的父节点和父节点的父节点的句法和语义信息前加入“REL-”标记。例8的浅层句法树进行关联后如图16所示。
例8:“the girl sing into a microphone”“the girl sing into the phone”
其中,如图10所示,S30的具体过程如下:
S301,基于句子对训练文本获得由获得平面特征训练文本,基于句子对测试文本获得平面特征测试文本。
其中,平面特征训练文本和平面特征测试文本为句子对训练文本和句子对测试文本中每行一对句子的相似度计算平面特征。本发明提供11个平面特征。
1、最长公共子串方法计算结果:计算最长连续字符序列的长度;
2、最长公共子序列方法计算结果:相比最长公共子串方法没有连续性的要求,并允许在单词的插入或缺失的情况下计算相似度;
3、贪婪的字符串拼接方法计算结果:允许文本乱序来计算共同的相似子串的部分,每个子串匹配的最大长度;
4、5、6、7基于字符n-gram的句子编辑距离计算结果:假设有一个句子s,那么该字符串的N-Gram就表示按长度N切分原词得到的词段,也就是s中所有长度为N的子字符串。设想如果有两个字符串,然后分别求它们的N-Gram,那么就从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram距离,N=1、2、3、4,共四个特征;
8、9、10、11基于单词n-gram的句子编辑距离计算结果:与特征4、5、6、7相似,将以字符为切分单位换成以单词为切分单位。
例8的10个平面特征为:
例10:1:1.000000000000697 2:0.9391768400811316 3:0.99999999999998314:0.503555802360086 5:0.5677922252084567 6:0.520906295824116 7:0.98:0.3333333333333333 9:0.910:0.2142857142857142711:0.07142857142857142
其中以1:1.000000000000697为例,“:”前面的数字表示特征编号,“:”后面的数字为特征值,调用专用的工具(如UKP)得到。
S302,由平面特征训练文本与浅层句法树训练文本获得浅层句法树特征训练文本;由平面特征测试文本与浅层句法树测试文本获得浅层句法树特征测试文本。
其中,浅层句法树特征训练文本和浅层句法树特征测试文本每行包含对应的句子对的十个平面特征和一对浅层句法树特征。
例8的特征集为:
例11:|BT|(ROOT(root(REL-dance(REL-nsubj(REL-woman(REL-det a)(REL-cc and)(REL-conj:and man)))(REL-nsubj man)(REL-cop be)(REL-nmod:in(REL-rain(REL-case in)(det the))))))|BT|(ROOT(root(REL-dance(REL-nsubj(REL-man(REL-det a)(REL-cc and)(REL-conj:and woman)))(REL-nsubj woman)(REL-cop be)(REL-nmod:in(REL-rain(REL-case in))))))|ET|1:1.000000000000697 2:0.9391768400811316 3:0.9999999999999831 4:0.503555802360086 5:0.5677922252084567 6:0.520906295824116 7:0.9 8:0.3333333333333333 9:0.9 10:0.2142857142857142711:0.07142857142857142
其中|BT|与|BT|和|BT|与|ET|之间的字符串表示例8两个句子对应的本发明提出的类似于图14的浅层句法树,root代表根节点,“(”表示孩子节点开始标志,“)”表示孩子节点结束标志。“(”与“)”之间的内容是节点的内容。最后拼接上例10的平面特征。
其中,如图11所示,S40的具体过程如下:
S401、使用SVR获得相似度计算模型,把浅层句法树特征训练文本作为输入利用SVR工具进行训练得到训练模型。
S402、把训练模型以及浅层句法树特征测试文本作为输入,利用SVR工具获得相似度计算结果文本。
其中,相似度计算结果文本每行的数值对应于句子对测试文本每行一对句子的相似度计算结果。如例8两个句子的相似度得分为3.8731014。
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!