一种基于好友圈子的动态微博转发行为预测系统及方法与流程
本发明涉及社交网络信息分析领域,主要涉及根据社交网络用户行为分析,构建一种动态微博转发行为预测模型。
背景技术:
随着WEB2.0理念的普及与相关技术的日益成熟,社交网站如Twitter、Facebook、新浪微博等对人们的生活产生了巨大影响。人们在社交网站中更新状态或发送广播,以此来展现自己的生活状态、发表感想或与朋友们分享信息。社交网站为用户相互交流、发表意见和观点提供了非常便利的平台。对社交网站的用户行为进行建模和预测对于安全、商业等多个领域具有十分重要的社会意义和应用价值,近年来逐渐得到研究者的重视。
新浪微博是一款为大众提供娱乐休闲生活服务的信息分享和交流平台,于2009年8月14日开始内测。截至2014年6月底,我国微博用户规模为2.75亿,用户之间组成复杂的关注网络,平均每天发送微博近1亿条,信息沿着用户间的关注关系传播,形成传播扩散网络。用户转发是微博中最有效的信息传播机制,当前转发预测的研究主要集中在兴趣特征、用户影响力以及用户属性等对转发行为预测结果的影响。所使用的方法包括基于文本的分析、基于用户影响力的分析和基于网络结构的分析等。其中,基于文本的分析主要利用概率主题模型分析文本,根据文本主题与用户兴趣的相似度预测用户的转发行为。例如:Xuning Tang等人在《接下来谁将参与?预测黑色网络社区的参与》(Who will be Participating Next?Predicting the Participation of Dark Web Community)中构建了一个用户兴趣和话题检测模型(UTD)。在给定已有部分用户对某个帖子进行回复的条件下,UTD模型通过获取话题内容和发展趋势预测哪些用户会对新的帖子产生兴趣;基于用户影响力分析主要研究用户在社交网络中对于其他用户的影响力,并与影响用户转发、评论的行为因素相结合,从而达到预测用户转发概率的目的。例如:Weng J等人在《基于主题找到影响力用户》(TwitterRank:Finding Topic-sensitive Influential Twitterers)中通过用户影响力评价,帮助用户迅速找出自己感兴趣的信息,从而解决了“微博网络中朋友过多所导致的信息过载问题”;基于网络结构的分析主要利用小世界理论、用户出入度等理论,构建因子图模型预测用户的转发行为。例如:Jing Zhang等人在《谁影响了你?通过社会影响力预测转发行为》(Who Influenced You?Predicting Re-tweet via social Influence Locality)中研究了基于用户好友圈子,结合因子图模型和社会影响力分析的转发预测方法。
用户的信息转发行为是多因素共同作用的结果,但上述现有技术未考虑到用户行为的复杂性,仅仅集中于一方面预测用户转发行为,预测结果并不准确,而且无法评估影响用户行为的各个特征的重要性。另外,当前的研究主要集中在网络静态特征对信息传播的影响,但却忽视了网络动态特性的重要作用,造成动态网络静态化问题。例如,用户活跃度具有动态特性,用户的活跃度随时间不断变化,其信息扩散速度和范围也将随之改变。因此,在网络静态特征的基础上,应充分考虑动态因素对信息传播的影响。由于社交网络中充斥着海量的信息,挖掘用户兴趣是提高信息转发预测效果的主要途径之一,利用LDA主题模型在大文本处理和特征降维方面的巨大优势,可以帮助用户迅速找出自己感兴趣的信息。本文重点针对网络动态特性、用户行为表征以及用户特征重要性评定等问题,引入并优化LDA主题模型,对用户行为进行建模分析,并采用时间离散化及时间切片方法,增强LDA模型对动态用户特征的处理能力,动态监测用户活跃度,提高转发预测的准确度。
技术实现要素:
本发明针对现有技术存在的问题:针对信息传播中网络动态特性、用户行为表征以及用户特征重要性评定等问题,提出了一种有效估计消息是否能获得转发及其转发规模、及早发现可能引发大规模爆发的微博的基于好友圈子的动态微博转发行为预测系统及方法。本发明的技术方案如下:
一种基于好友圈子的动态微博转发行为预测系统,包括用户行为数据源获取模块,用于获取社交网络中的用户关系和用户行为数据,将发文用户的粉丝作为备选用户,其还包括属性提取模块、模型构建模块及预测分析模块,其中,所述属性提取模块分别从用户间兴趣差异、备选用户的活跃度以及发文用户的影响力三方面提取相关属性向量作为预测模型的输入;微博转发行为预测模型构建模块,用于对备选用户构建微博转发行为预测模型,转发行为主要受备选用户与其好友的兴趣差异τ、备选用户在文章发布时段的活跃度s和其好友的网络影响力r参数决定,并对以上模型参数进行拟合;预测分析模块用于将拟合后获得的参数和任一时刻t的用户发文情况进行备选用户是否会转发该条微博的预测。
进一步的,所述属性提取模块针对用户间兴趣差异,提取用户兴趣向量包括:利用用户的关注行为属性,获取每个用户的关注列表,定义用户v的兴趣向量为其中,ev,u表示用户v关注列表中的用户,u=1,2......|Ev|,|Ev|表示用户v关注列表中的用户总数。
进一步的,所述属性提取模块针对备选用户的活跃度,提取用户状态向量包括:利用用户的交互行为属性和时间属性,获取每个用户在一段时间内的用户发布微博活跃度及转发微博活跃度,定义用户v的活跃度状态向量为其中,表示用户v在时间片t上的发布微博活跃度,表示用户v在时间片t上的转发微博活跃度,和分别代表用户v在时间片t上的发布微博数、转发微博数以及用户v平均每天发布微博数。
进一步的,所述属性提取模块针对发文用户的影响力,提取用户特征向量包括:利用网络拓扑结构属性,获取每个用户节点的出度、入度和局部聚集系数,定义用户v的影响力特征向量为其中,dv,1表示用户v的粉丝数,dv,2表示用户v的好友数,表示用户v的局部聚集系数,Ngv是节点v的邻居节点集合,edgij是它的相邻结点之间的连接。
进一步的,所述微博转发行为预测模型从用户间兴趣差异、备选用户活跃度以及发文用户影响力三方面,对于用户间兴趣差异方面,从用户行为和用户关系信息中提取用户的兴趣向量,利用LDA模型训练所有用户,获取用户的兴趣主题分布;对于备选用户活跃度方面,从用户行为和时间信息中提取各个时间片上的用户的状态向量,针对用户状态向量中的元素是连续值,使用高斯分布改进LDA,再利用改进的LDA模型训练所有用户,获取用户在各个时间片上的活跃状态分布;对于发文用户影响力方面,从网络结构信息中提取用户的特征向量,同上述用户状态向量一样,使用高斯分布改进LDA,再利用改进的LDA模型训练所有用户,获取用户的网络角色分布;最后根据用户间兴趣是否一致、备选用户在各个时间片上所处的活跃状态、发文用户的网络角色以及用户的历史转发数据训练整个预测模型,得到用户转发行为的多项分布。
进一步的,所述微博转发行为预测模型获取用户的兴趣主题分布还包括:在用户关系网络的基础上再利用用户之间的交互行为,对用户的兴趣向量I(v)进行加权得到加权用户兴趣向量为其中,wv,n表示用户v发生第n次交互行为的交互对象,n=1,2......Nv,Nv为用户v交互总次数,再利用LDA模型训练所有用户,便可得到用户的兴趣主题分布。
进一步的,所述获取用户在各个时间片上的活跃状态分布还包括:针对用户发布活跃度xv,t,1和转发活跃度xv,t,2是连续变量,使用高斯分布改进LDA模型,使得发布活跃度和转发活跃度的取值分别服从不同的高斯分布:其中,xv,t,m表示用户v在时间片t上的第m个属性值,μs,m和σs,m分别是用户活跃状态为s时第m个属性的均值和标准差。
进一步的,通过时间切片方法,将每天从夜间0点开始切割成4个时段,即t=1,2,3,4,将用户的活跃状态分为三个等级,即非常活跃、一般活跃和不活跃,利用改进的LDA模型训练所有用户,便可得到用户在各个时间片上的活跃状态分布。
进一步的,基于网络拓扑结构将用户节点分为三种角色类型,即意见领袖、信息传播者和普通用户,同样,使用高斯分布改进LDA模型后,利用此模型训练所有用户,便可得到用户的网络角色分布。
一种基于所述系统的好友圈子的动态微博转发行为预测方法,其包括以下步骤:
获取社交网络中的用户关系和用户行为数据,将发文用户的粉丝作为备选用户;分别从用户间兴趣差异、备选用户的活跃度以及发文用户的影响力三方面获取三个用户向量作为预测模型的输入;
构建微博转发行为预测模型,并对模型参数进行拟合;
将拟合后获得的参数和任一时刻t的用户发文情况输入到预测模型进行备选用户是否会转发该条微博的预测。
本发明的优点及有益效果如下:
本发明提出了一种基于好友圈子的动态微博转发行为预测方法。首先,针对单个用户兴趣、活跃度和影响力的多样性,利用LDA主题模型可解决“一词多义,多词一义”的基础思想和方法,对用户行为进行建模分析,得到关于用户行为的主题分布;其次,考虑到用户状态向量和用户特征向量中的元素是连续值,使用高斯分布改进LDA,以发现用户的活跃度和影响力;最后,针对用户的活跃度随时间的变化,利用时间离散化及时间切片方法,提出一种改进的LDA动态微博转发行为预测模型,动态监测用户的活跃度,提高预测模型的准确度。
本发明针对信息传播中网络动态特性、用户行为表征以及用户特征重要性评定等问题,提出了一种基于好友圈子的动态微博转发行为预测方法,能够对用户转发行为做出准确的预测。根据预测结果,能够有效估计消息是否能获得转发及其转发规模,及早发现可能引发大规模爆发的微博,对微博突发性检测和微博影响力评估具有重要意义。
附图说明
图1是本发明提供优选实施例基于好友圈子的动态微博转发行为预测方法总体流程图;
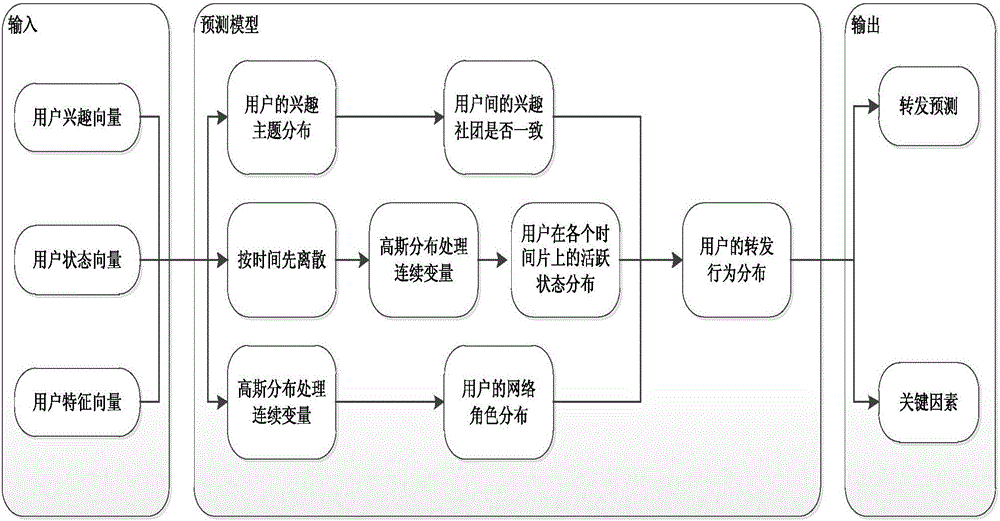
图2是本发明的预测模型框图;
图3是本发明的预测模型流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是,
由于社交网络中的信息传播主要受兴趣差异、用户历史行为和网络结构推动,因此本发明分别从用户兴趣、活跃度和影响力三个方面出发,利用LDA主题模型的基础思想和方法,对用户行为进行建模分析,得到关于用户行为的主题分布;其次,针对用户属性中存在连续变量的问题,使用高斯分布改进LDA,以发现用户的活跃度和影响力;最后,针对用户的活跃度随时间的变化,利用时间离散化及时间切片方法,提出一种改进的LDA动态微博转发行为预测模型,使其能够动态监测用户的活跃度,准确的预测用户的转发行为并发现影响用户转发的关键因素。
具体表述为:给定一个社交关系网络G=(V,E,Y)。其中,V表示网络中的所有用户,|V|=N表示用户的数量;E表示所有用户之间的关系,是一个N×N维的矩阵;Y表示用户的一系列过往行为,|Y|=I表示用户行为数据总数。设计一个概率生成模型,利用社交网络中的用户关系和用户行为信息,并加入时效性因素的影响,对每个用户进行分析,通过4个概率生成过程得到每个用户的兴趣分布、活跃等级分布、网络角色分布以及用户转发行为的分布,依据这4个分布对一段时间内用户对其关注好友微博的转发行为进行预测。
如图1所示为本发明的总体流程图,主要包括:获取数据模块,提取属性模块,构建模型模块,预测分析模块共四大模块。
以下具体说明本发明的详细实施过程。
S1:获取数据源。获取的数据具体包括用户关注关系网络和网络中所有用户的用户行为信息,用户行为包括用户过往发布和转发的微博,以及发布和转发微博的时间。具体可采用如下方法(也可采用现有技术的常规方法获取):
S11:获取原始数据。获取一个用户关注关系网络和该网络下的所有用户的过往行为数据。通过社交网络公共API或直接下载现有数据源都可以得到原始数据,也可结合网络爬虫等方法补充数据。
S12:简单的数据清洗。通过简单的数据清洗可以使大部分数据利于分析。例如,删除重复数据、清理无效节点等。
S13:对数据进行时间分片,确定用户在各个时间片上的属性。这里的用户属性具体指用户的发布活跃度和转发活跃度。由于用户的转发行为与其作息时间密切相关,根据用户的生活作息特点,将一天以预定时间(如6个小时)为一个时间段进行时间分片。在某个时间段t里,根据用户属性确定此时段内用户的活跃状态,以预测用户是否会转发其好友的微博。
S2:提取相关属性。考虑社交网络中的转发行为主要从兴趣差异、用户历史行为以及网络结构三方面,本发明分别从用户兴趣、活跃度和影响力三个方面出发来提取相关属性,如关注行为属性、交互行为属性、时间属性和网络结构属性。其属性可根据数据方面的特征对其进行适当修改。
提取完以上三方面的各个属性后,获取相应的用户向量。其具体方式如下。
S21:提取用户兴趣向量。考虑到用户对自己感兴趣的用户关注,利用用户的关注行为属性,获取每个用户的关注列表,定义用户v的兴趣向量为:
其中,ev,u(u=1,2......|Ev|)表示用户v关注列表中的用户,|Ev|表示用户v关注列表中的用户总数。例如:用户a关注列表中的用户有:b,c,d,e......,则用户a的兴趣向量为I(a)=[b,c,d,e......]。
S22:提取用户状态向量。根据用户的生活作息特点,将一天以预定时间(如6个小时)为一个时间段进行时间分片,利用用户的交互行为属性和时间属性,获取每个用户在各个时间片内的发布微博活跃度及转发微博活跃度,定义用户v的状态向量为:
其中,表示用户v在时间片t上的发布微博活跃度,表示用户v在时间片t上的转发微博活跃度。和分别代表用户v在时间片t上的发布微博数、转发微博数以及用户v平均每天发布微博数。例如:用户a在第1时间片上发布了3条微博,其中转发微博为2条,而用户a平均一天发布5条微博,则用户a的行为向量为
S23:提取用户特征向量。由于用户节点在网络中的位置对信息传播有重大影响,利用网络拓扑结构属性,获取每个用户节点的出度、入度和局部聚集系数,定义用户v的特征向量为:
其中,dv,1表示用户v的粉丝数,dv,2表示用户v的好友数,表示用户v的局部聚集系数。Ngv是节点v的邻居节点集合,edgij是它的相邻结点之间的连接。例如:用户a拥有30个粉丝,20个好友,邻居节点共有40个,其邻居节点之间存在200个连接边,则用户a的特征向量为
S3:建立预测模型,如图2所示为本发明的预测模型框图。备选用户是否会转发其好友的微博,主要受备选用户与其好友的兴趣差异τ、备选用户在文章发布时段的活跃度s和其好友的网络影响力r决定。
预测模型进行备选用户是否会转发其好友的某条微博的预测具体包括:对于兴趣差异方面,从用户行为和用户关系信息中提取用户的兴趣向量I(v),利用LDA模型训练所有用户,获取用户的兴趣社区分布其中,表示用户v的兴趣社区分布,N为用户总数;对于用户活跃度方面,从用户行为和时间信息中提取各个时间片上的用户的状态向量L(v,t),针对用户状态向量中的元素是连续值,先使用高斯分布改进LDA,再利用改进的LDA模型训练所有用户,获取用户在各个时间片上的活跃状态分布其中,表示用户v在t时间片上的活跃状态概率分布;对于用户的网络影响力方面,从网络结构信息中提取用户的特征向量F(v),同上述用户状态向量一样,使用高斯分布改进LDA,再利用改进的LDA模型训练所有用户,获取用户的网络角色分其中,表示用户v的网络角色概率分布;最后,根据用户的兴趣社区分布用户在各个时间片上的活跃状态分布用户的网络角色分布以及用户的历史转发数据Y训练整个预测模型,得到用户的转发行为分布其中,表示当用户间兴趣差异为τ,备选用户处于活跃状态s且发文用户扮演网络角色r时备选用户转发该条微博的概率,表示不转发的概率。模型的求解和如何预测备选用户在各个时间片上的转发行为将在接下来的部分详细叙述。
如图3所示为本发明的预测模型流程图。
S31:获取用户的兴趣社区分布。
由于好友关系仅表示用户间具有交互的可能性,不能真实反映两者信息交互的强度,趋于静态。为了发现活跃的兴趣社区,我们在用户关系网络的基础上再利用用户之间的交互行为,对用户的兴趣向量I(v)进行交互加权,这里的交互行为具体指转发行为,得到加权用户兴趣向量为:
其中,wv,n(n=1,2......Nv)表示用户v发生第n次交互行为的交互对象,Nv为用户v交互总次数。例如:用户a与用户b发生2次交互,与用户c发生4次交互......,则用户a的加权兴趣向量为I'(a)=[b,b,c,c,c,c......]。
给定C作为兴趣社区数,采用LDA模型训练所有用户,具体生成过程如下:
对每一个用户v:
1、抽样一个边分布ξ~Dir(λ),λ是Dirichlet分布的参数;
2、抽样一个用户兴趣社区分布α是Dirichlet分布的参数;
3、对用户的每一条边ev,i:
1)抽样一个兴趣社区
2)抽样一条边
其中,表示用户v的兴趣社区分布,表示兴趣社区c的边分布。
在此概率生成模型中,对用户行为建模实际上是要计算用户的兴趣社区分布以及兴趣社区的边分布对于Φ和ξ的求解,采用Gibbs抽样,Gibbs抽样每次迭代估算Φ和ξ的公式如下:
其中,表示用户v在兴趣社区c的概率,C为兴趣社区总数,nv,c表示用户v与处于兴趣社区c的关注用户交互的次数,|Nv|为用户v与其好友的交互总次数;表示兴趣社区c中出现用户e的概率,|E|为网络中边的总数,nc,e表示兴趣社区c中用户e的交互次数,nc为兴趣社区c中的交互总次数。
S32:获取用户在各个时间片上的活跃状态分布。
用户的转发行为与其作息时间密切相关,每个用户都有自己相对固定的上网时间,在该时段内,用户较活跃,发帖转帖概率较大,而其他时间很少参与话题的传播。因此,通过时间切片方法,将每天从夜间0点开始切割成4个时段(t=1,2,3,4),对向量数据按时间先离散。其次,针对用户发布活跃度xv,t,1和转发活跃度xv,t,2是连续变量,使用高斯分布改进LDA模型,使得发布活跃度和转发活跃度的取值分别服从不同的高斯分布:
其中,xv,t,m表示用户v在时间片t上的第m个属性值,μs,m和σs,m分别是用户活跃状态为s时第m个属性的均值和标准差。
本发明将用户的活跃状态设为三个等级S=3,即非常活跃、一般活跃和不活跃。利用改进的LDA模型训练所有用户,具体生成过程如下:
对每一个用户v:
1、抽样一个用户在时间片t上的活跃状态分布β是Dirichlet分布的参数;
2、抽样一个活跃等级
3、对用户v的每一个属性:
1)抽样一个属性值
其中,表示用户v在时间片t上的活跃状态分布。
在此概率生成模型中,对用户状态属性建模实际上是要计算用户在各个时间片上的活跃状态分布以及用户各个属性取值服从的高斯分布N(μ,σ)。对于Θ(t)和μ,σ的求解,采用EM算法,EM迭代估算Θ(t)和μ,σ的过程分为两步:
E-step:更新
M-step:更新μs,m和σs,m。
其中,表示用户v在时间片t上活跃状态为s的概率,S为状态等级数,M为用户状态属性个数,xv,t,m表示用户v在时间片t上的第m个属性值,μs,m和σs,m分别是用户活跃状态为s时第m个属性的均值和标准差。
S33:获取用户的网络角色分布。
节点在网络中的位置及其所产生的影响对信息传播效果具有重要影响。本发明基于网络拓扑结构将用户节点分为三种角色类型R=3,即意见领袖、信息传播者和普通用户。意见领袖拥有较高的入度而信息传播者拥有较高的出度。
同样,由于角色属性中存在连续变量,使用高斯分布改进LDA模型后,利用改进的LDA模型训练所有用户,具体生成过程如下:
对每一个用户v:
1、抽样一个用户网络角色分布ε是Dirichlet分布的参数;
2、抽样一个网络角色
3、对用户v的每一个角色属性:
1)抽样一个角色属性值
其中,表示用户v的网络角色分布。
在此概率生成模型中,对用户角色属性建模实际上是要计算用户的网络角色分布以及用户各个角色属性取值服从的高斯分布N(μ',σ')。对于η和μ',σ'的求解,采用EM算法,EM迭代估算η和μ',σ'的过程分为两步:
E-step:更新
M-step:更新μ'r,h和σ'r,h。
其中,表示用户v扮演网络角色r的概率,R为网络角色个数,H为用户状态属性个数,dv,h表示用户v的第h个属性值,μ'r,h和σ'r,h分别是用户扮演网络角色r时第h个属性的均值和标准差。
S34:获取用户的转发行为分布。
根据用户的兴趣社区分布用户在各个时间片上的活跃状态分布用户的网络角色分布以及用户的历史转发数据Y训练整个预测模型,得到用户的转发行为分布具体生成过程如下:
对每一个用户转发行为yi:
1、抽样一个用户转发行为分布ρ~Dir(γ),γ是Dirichlet分布的参数;
2、为备选用户v抽样一个兴趣社区
3、为发文用户u抽样一个兴趣社区
4、为备选用户v抽样一个活跃状态
5、为发文用户u抽样一个网络角色
6、抽样一个用户转发行为
其中,表示用户的转发行为分布,表示当用户间兴趣差异为τ,备选用户处于活跃状态s且发文用户扮演网络角色r时备选用户转发该条微博的概率,表示不转发的概率。τ为指示函数,定义如下:
其中,zu,zv分别表示用户u、v所在的兴趣社区。τ=1表示兴趣一致,τ=0表示兴趣不一致。
在此概率生成模型中,对用户转发行为建模实际上是要计算用户的转发行为分布对于的求解,采用Gibbs抽样,Gibbs抽样每次迭代估算的公式如下:
其中,ni,τ,s,r表示兴趣差异为τ、备选用户活跃状态为s、发文用户扮演网络角色r时,用户行为yi=1(转发)或yi=0(不转发)的次数;I为用户行为总数,包括不转发行为;M为用户状态属性个数,H为用户角色属性个数。
S4:通过拟合出来的Φ、Θ(t)、η、和用户好友的任意一条微博,根据拟合的预测模型,计算其转发概率即可得到预测结果。通过预测到的结果即可分析出用户会转发哪些好友的微博,以及影响用户转发微博的关键因素。
本发明利用社交网络中的用户关系和用户行为数据,将发文用户的粉丝作为备选用户,预测备选用户是否会在一段时间内转发其好友的微博。首先,针对单个用户兴趣、活跃度和影响力的多样性,利用LDA主题模型可解决“一词多义,多词一义”的基础思想和方法,对用户行为进行建模分析,得到关于用户行为的主题分布;其次,考虑到用户状态向量和用户特征向量中的元素是连续值,使用高斯分布改进LDA,以发现用户的活跃度和用户影响力;最后,针对用户的活跃度随时间的变化,利用时间离散化及时间切片方法,提出一种改进的LDA动态微博转发行为预测模型,动态监测用户的活跃度,使其能够准确预测用户的转发行为,并分析影响用户转发的关键因素。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!