一种快速精确的粒球近邻分类算法的制作方法
本发明属于计算机技术领域,涉及一种快速精确的粒球近邻分类算法。
背景技术:
k近邻分类算法(k Nearest Neighbors’Algorithm,kNN)是机器学习领域最为经典和常用的分类算法之一。当前,该算法已经广泛应用于特征选择,模式识别,聚类,噪音检测分类等诸多领域。最基本的全搜索k近邻算法(Full Searching algorithm,FSA)算法是通过计算待分类点到各已知类别点的欧式距离以确定k个最近邻点,因此其时间复杂度较高(O(n2)),算法效率很低。另外,现有的k近邻算法在不平衡数据集中的分类精度无法保证。现有的改进的近邻算法主要在于提高k近邻算法的效率,这些算法大体可以分为两类:第一类,创建搜索树以降低时间复杂度。比如,Kim和Park使用有序分拆方法来创建一个多分支搜索树以提高搜索效率;Wang和Gan将投射聚类和主轴搜索树算法相结合以减少运算时间。Chen等使用赢家更新搜索方法和下界树来改善算法效率。以上改进算法的不足之处在于,随着数据维数增加,其时间复杂度急剧变坏,且失去稳定性,所以算法的时间复杂度在(O(nlogn)~O(n2))。第二类,近似k最近邻算法。该类算法通过搜索近似的k最近邻样本代替精确的最近邻样本,来避免所有样本之间距离的直接计算,以提高搜索效率。譬如,Ra和Kim通过计算待分类点到各已知类别点的平均值的差异来除去不可能数据点;Lai使用三角不等式和投影值以降低计算复杂度;Xia在研究数据维度对最近邻搜索算法影响后提出了LDMDBA算法;还有一些算法通过聚类来提高算法效率。这些算法虽然在效率上得到了提升,但是都在不同程度上牺牲了算法的精度,要低于精确最近邻算法(即FSA或是其他基于树索引结构的算法)。总结来说,两类算法无法在保证算法精度的情况下,将算法在包括高维数据集上的各种数据上的时间复杂度降低到O(nlogn)。另外,这些改进算法都无法解决k近邻算法在不平衡数据集上精度下降的问题。
技术实现要素:
有鉴于此,发明提出了一种新的分类算法,粒球近邻搜索算法(Granular Ball k nearest neigbhors algorithm,GBkNN)。该近邻搜索算法与现有k近邻算法不同的是,其不再通过比较最近邻的k个样本用来决策分类,而是使用最近的粒球体。该特性使GBkNN的运行效率远快于现有精确k近邻算法,并突破现有的最近邻分类算法在处理不平衡数据低精度的局限 性,使得GBkNN具有更好的分类预测精度。GBkNN算法不需要进行k值得选择,也是现有k近邻算法所没有的特性。另外,相比现有基于树的精确最近邻算法,RPkN算法不依赖任何树索引结构,所以能够更高效地处理高维数据,并且保留了现有最近邻查询算法的优势:在线、多分类、不依赖训练等。
为达到上述目的,本发明提供如下技术方案:
算法给定数据集D∈Rd,基于实验经验,如果算法在三次迭代后也没有得到一个更好的精度,则算法收敛。这也是本算法的收敛条件。算法具体步骤为:
1.选取两类样本点作为两个粒球;
2.计算所有粒球的标签;
3.计算每个样本点到各粒球的距离;
4.每个样本的标签等于其距离最近的粒球的标签;
5.如果训练精度达到截至条件则算法终止;否则转向步骤6;
6.生成更多的粒球数,并转向步骤2。
本技术方案中的步骤3中,样本点到粒球的距离计算如图1所示,其值等于样本点到粒球球心的距离减去粒球的半径。
在技术方案中的步骤6中,因为k-means算法容易产生球类簇,所以粒球的分裂考虑使用k-means聚类算法。k-means的时间复杂度为O(Nkt)。在大小为几百到上亿的数据集中,GBkNN中k-means球体的生成总数没有超过50,所以GBkNN算法中的球体生成步骤的时间复杂度可基本认为是近线性的。当所有粒球生成后,由于粒球的半径和球心构成的数据量很小,使用粒球进行分类或是回归预测的时间基本是可以忽略的。因此,GBkNN的时间复杂度可看成近线性的,这种时间复杂度远低于现有的精度k近邻算法。
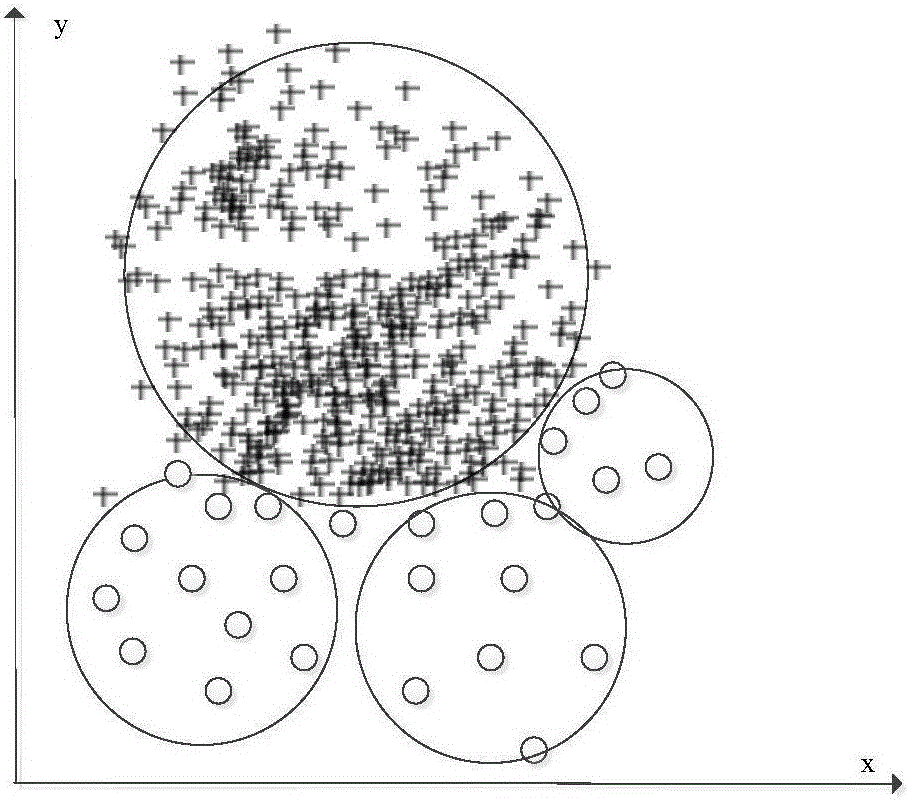
本发明的有益效果在于:本发明的粒球近邻分类算法—GBkNN构思合理,本GBkNN算法通过被查询样本点最近的粒球的标签对被查询点进行分类。该算法的时间复杂度可以保持在近似线性,远小于现有的精确kNN算法,这使得其算法效率要远快于现有的精确k近邻算法。GBkNN算法能够保留产生分类边界,从而有效地处理现有kNN算法在不平衡数据集精度失效的问题,该问题如图2所示:现有的kNN算法对对图中所示的不平衡数据,很容易将边界上稀疏的样本划归到分布密集的样本中,这种问题是现有的kNN算法所无法避免的。但是GBkNN算法通过粒球产生了简单的边界,从而能很好的应对该问题,获得更好的分类精度表现。GBkNN算法不需要进行k值的选择,这是现有k近邻算法所没有的特性。
另外,相比现有基于树的精确最近邻算法,GBkNN算法不依赖任何树索引结构,所以能 够更高效地处理高维数据。并且,GBkNN仍然保留了现有最近邻查询算法的优势:在线,多分类,不依赖训练等。
附图说明
图1为点到粒球距离的示意图;
图2为GBkNN算法产生边缘的示意图。
具体实施方式
下面将结合图表,对本发明的优选实施例进行详细的描述。
1.本发明涉及一种快速精确近邻分类算法,该算法使用被查询点到少量的粒球的距离来替代样本点之间的距离的直接计算,使得该算法的算法效率远高于现有的精确k最近算法,并且还能够获得更好的算法分类精度,算法给定数据集D∈Rd,基于实验经验,如果算法在三次迭代后也没有得到一个更好的精度,则算法收敛。这也是本算法的收敛条件。
算法具体步骤为:
1)选取两类样本点作为两个粒球;
2)计算所有粒球的标签;
3)计算每个样本点到各粒球的距离;
4)每个样本的标签等于其距离最近的粒球的标签;
5)如果训练精度达到截至条件则算法终止;否则转向步骤6;
6)生成更多的粒球数,并转向步骤2。
在算法的步骤6中,粒球的分裂考虑使用k-means聚类算法,因为k-means算法容易产生球类簇。k-means的时间复杂度为O(Nkt)。在大小为几百到上亿的数据集中,GBkNN中k-means球体的生成总数没有超过50,所以GBkNN算法中的球体生成步骤的时间复杂度可基本认为是近线性的。当所有粒球生成后,由于粒球的半径和球心构成的数据量很小,使用粒球进行分类或是回归预测的时间基本是可以忽略的。因此,GBkNN的时间复杂度可看成近线性的,这种时间复杂度远低于现有的精度k近邻算法。GBkNN算法中通过使用粒球产生分类边界,从而有效地处理现有kNN算法在不平衡数据集精度失效的问题。另外,GBkNN算法不需要进行k值的选择,也是现有k近邻算法所没有的特性。。
下面从算法的有效性和算法的效率两方面进行分析验证。
一、算法的有效性验证
本发明在表1中来自UCI上的八个公开标准数据集上进行有效性验证,将提出的算法在 精度上与精确k近邻算法进行比较。数据集中的20%用来进行预测。由于没有使用随机算法,所以所有的实验结果都是可以再现的。仿真实验环境:Intel I5-3470处理器、8GB内存、windows7操作系统、matlab2014。在表1中的数据集分别是Breast cancer,Diabetes,Fourclass,Svmguide1,Svmguide3and Cod-RNA。表中的黑色字体表示分类预测的最高精度。
表1实验数据表
算法精度的比较结果表现在表2到表3中。从表2和表3中可以看出GBkNN算法相比,除了在Svmguide1中,在大多数数据集中都具有更高的分类精度。在Svmguide3中,分类精度增加了超过30%。在Sonar中,分类精度增加超过了5%。这种提高都是非常显著的。其原因即在于GBkNN中考虑数据的整体特征并且通过粒球的边缘产生了简单的边界,如图2所示的:现有的kNN算法对对图中所示的不平衡数据,很容易将边界上稀疏的样本划归到分布密集的样本中,这种问题是现有的kNN算法所无法避免的。但是GBkNN算法通过粒球产生了简单的边界,从而能很好的应对该问题,获得更好的分类精度表现。可能是粒球数量设置的方法不够,GBkNN的精度在少量数据集上有一点点的小于FSA,如Svmguide1。
表3中另外一个现象就是细粒度的粒球并不一定意味着更高的预测精度。表3中,除了Svmguide1,其他数据集的最高预测精度都没有出现在最后一列。因此,因此,可以推断小粒度不一定有助于获得高精度,并且实际上可能是有害的。如在Svmguide3中,当粒状球的数量增加到五个时,获得最好的预测精度。随着数量进一步增加,预测精度降低。当数量达到50时,预测精度降低到0.5366。这种现象在一定程度上也是来自于噪声的影响,大的粒度可以忽略噪声数据的影响,并实现更高效的对整体数据集的识别。
与FSA代表的精确kNN相比,GBkNN的更高精度可以从另一个角度来解释:FSA和其他精确kNN可以被看作是具有最小尺寸的粒状球的GBkNN算法。如上所述,更精细的颗 粒球不意味着更高的预测,这也已经在实验结果中证明,最细的颗粒球(即FSA和其他精确的kNN)不太可能具有最高的精度。
表2
FSA的算法精度(%)
表3
GBKNN的算法精度(%)
表4
FSA的算法执行时间(MS)
表5
GBKNN的算法执行时间(MS)
执行时间的比较结果如表4和表5所示。当数据集不大时,不同结果之间的差异较小。然而,在最大数据集Codrna中,GBkNN具有比FSA低得多的执行时间,这表明GBkNN具有比FSA低得多的时间复杂度。这与第6.3节中的分析一致。本节体现了GBkNN算法的有效性,并初步体现了GBkNN算法的效率。在下一节中,将显示在大数据集上的颠覆性的效率改进。
2、算法效率分析
现有的算法在这种类型的硬件环境运行得太慢,并且可能花费数百小时来处理几百万个数据点,而超过几百万的数据点则是难以想象的。因此,本节仅用GBkNN算法在大数据集上进行实验。
A.公共数据集
为了显示GBkNN在处理大数据时的性能,在本节中选择用于UCI上的用于二分类的最大数据集HIGGS和SUZY。实验结果显示在表6和表7中。为了处理数据集HIGGS,2015年提出的libsvm增强算法使用16个进程运行,大约需要两天时间完成。相比之下,我们提出的算法的收敛时间是68.47s,这只是在一个普通的笔记本电脑上完成的。这个时间大大低于libsvm增强算法。在我们的实验中,FSA和基于ball树的快速精确近邻在7天内也没有运行完成。
在我们的硬件环境中使用GBkNN处理数据集SUZY只需要68.47秒;相反,FSA和基于ball树的快速精确近邻也没有在七天内完成任务。
B.人工数据集
在该示例中,为了生成最大数据集以证明所提出的算法的效率,使用高斯分布产生维度为2的数据集,并且大小从一百万增加到一亿。首先从[0,1]的范围内均匀分布生成十个聚类中心。它们是:0.5358,0.4451,0.239,0.4903,0.8529,0.8739,0.2702,0.2084,0.5649和0.6403。这些中心是每个簇的平均值,并且每个簇含有所有数据点的1/10。比较结果如表8和9所示。粗体字表示GBkNN算法收敛。可以看出,处理包含1亿个数据点的数据集只需要十分钟。这在我们的硬件环境中,使用FSA和基于ball树的快速精确近邻算法也没有一周内完成运行。
表6
GBKNN的预测精度(%)
表7
GBKNN的执行时间(MS)
表8
GAUSSION分布上的预测精度(%)
表9
分布上的执行时间(MS)
- 还没有人留言评论。精彩留言会获得点赞!