基于深度学习SSD框架的道路车辆实时检测方法与流程
本发明属于图像识别技术领域,主要涉及道路车辆实时检测方法,可用于对行驶车辆的检测。
背景技术:
随着现代社会生活水平不断提高,汽车作为一种重要的交通工具,其数量呈现高速增长的趋势,给交通监管带来了巨大的挑战。汽车数量的高速增长,虽然给人们的生活带来了很多便利,但同时也带来了诸如乱闯红灯、交通拥堵、超速、交通事故等一系列的交通问题。传统的依靠人力或者基础交通设施的道路交通管理方法己经无法满足目前的发展需求,而近年来计算机技术、人工智能和模式识别等技术得到了大力发展以及广泛应用,这些技术也渗透到了交通服务行业,在这种背景下,基于深度学习卷积神经网络的交通监测技术应运而生。
目前,基于深度卷积神经网络的车型识别研究中,西南交通大学邓柳的《基于深度卷积神经网络的车型识别》,该研究主要区分的车型类别包括诸如小汽车、货车和客车,但是该研究是以车辆图像小块作为输入,简单卷积神经网络与SVM结合进行的分类识别,并且不包含雨天、雾天、雪天及拥堵等恶劣环境情况的车型识别研究。这种以图像小块作为输入不能很好的结合背景信息,而且抓取整个车辆信息使得深度网络抓取了很多与分类识别无关的冗余信息,再加上分类识别网络不能实现端对端的检测,不仅其检测准确率不高,而且也造成了检测时间的浪费,不能达到实时检测的要求。
技术实现要素:
本发明的目的在于针对上述已有的道路车辆检测技术的不足,提出一种基于深度学习SSD框架的道路车辆实时统计方法,以提高检测准确率,减小时间的浪费,达到实时检测的要求。
本发明的技术方案是:将车窗信息作为区别道路车辆与周围背景的最为显著性的特征,通过这一主要特征来标识车辆,以排除其他无关特征对检测准确率的干扰,使得更多的神经元集中于车窗特征的学习,更加易于区分车辆与背景信息。搭建多尺度目标检测器SSD网络框架,这种框架以16层深卷积网络VGG-16为基础网络,同时对该网络的最后几层加以改进,使之可以提取到不同尺度下的分类及位置信息。将这些信息连接整合,并用于对原网络的反馈调节,以此来提高车辆检测的速度和准确率。其实现步骤包括如下:
1)构建训练数据集:
1a)在交通要道拍摄若干个行驶车辆的视频,将这些视频每隔10帧保存为图片,并存放到JPEGImages文件夹下作为训练数据;
1b)对(1a)的每张图片中车窗部分进行标注,生成txt格式的标注文件并进行xml格式转换,将转换为xml格式的文件均分成两部分,其中将一部分图片的图片名写入到trainval.txt文件中,另一部分则将图片名写入到test.txt文件中,得到训练网络所需的trainval.txt文件、test.txt文件和与图片相对应的xml文件;
1c)将(1b)中的所有xml文件进行合并后存放到Annotations文件夹下,并将生成的trainval.txt文件和test.txt文件存放到ImageSet/Main文件夹下;
2)搭建SSD训练网络架构:
2a)下载并安装caffe-ssd平台;
2b)在caffe-ssd平台中下载并打开VGG-16网络结构的deploy.prototxt文件,修改其卷积层及全链接层的层类别,以此作为基础网络base_network;
2c)在基础网络base_network的末尾添加卷积层及池化层,作为额外的特征提取层;
2d)创建mbox_layers层,并根据基础网络base_network,设定mbox_layers层的相关参数;
3)转换数据格式开始训练:
3a)修改caffe_ssd平台下的标签字典,该标签字典的文件名为labelmap_voc.prototxt;
3b)将1)中准备好的数据集存放到data文件夹下,修改并运行相应程序生成lmdb格式文件;
3c)将3a)中修改过的标签字典文件和3b)生成的lmdb文件输入到搭建好的SSD训练网络进行训练,得到最终的训练模型;
4)利用训练模型进行视频车辆检测:
4a)将任意待测行驶车辆视频按帧输入到训练好的模型中;
4b)对于输入的每一帧图像,该模型将随机地选取整幅图像的多个区域,并采用卷积算法对每个区域进行打分;
4c)设定一个阈值δ=0.2,将每一个区域的得分分别与δ比较,将得分高于δ的区域,判断为包含汽车车窗,并调用绘图命令对这个区域进行标注;将得分值低于δ的区域,判断为不包含车窗或包含不完全车窗,直到图像上所有被判断为包含汽车车窗的区域均标注完成;
4d)重复4b)-4c),将4a)中待测视频的所有帧图像处理后,得到相应的输出视频,此输出视频将会标注出每一个包含汽车前窗的区域,从而完成对一段视频中每一辆汽车的检测。
本发明与现有技术相比具有以下优点:
1.可实现实时检测:
现有的基于区域建议方法中检测最快、准确率最高的Faster-RCNN模型,检测速度只能达到5~7FPS,而本发明的检测模型的检测速度可以达到30FPS,达到了实时检测的效果;
2.检测准确率高:
传统的检测方法是通过扩增训练数据集的方法,使得训练模型对不同尺度、不同长宽比的车辆信息具有较强的泛化能力,而本发明只抓取车窗这一车辆显著性特征与背景进行区分,并且通过对输入图片不同尺度信息的提取与整合,大大降低了尺度因子对检测效果的影响,进一步提升了检测准确率,经实际测试,汽车检测准确率可以达到95%以上;
3.鲁棒性好,
现有的车辆检测算法只能在道路交通状况良好、天气状况优良的前提条件下有相对较好的检测效果,而本发明对各种道路状况及天气情况都有很好地迁移性,在复杂道路状况及天气情况下都能达到较高的检测准确率与检测速度。
附图说明
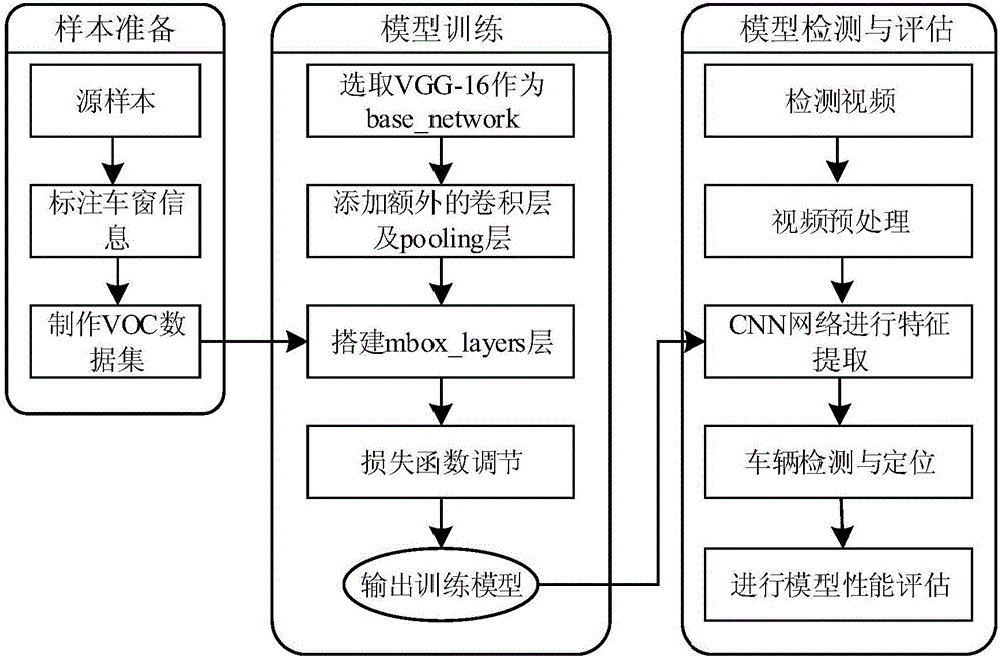
图1为本发明的实现流程图;
图2为本发明中的训练集数据格式生成图
图3为本发明中的图片标注效果图
图4为本发明中每一幅图片标注产生的xml文件格式图
图5为本发明中trainval.txt文件和test.txt文件格式图
图6为用本发明在不同道路状况和不同天气下对车辆的检测效果图。
具体实施方式
下面结合附图和实例对本发明进行详细说明。
参照图1,本发明的实现步骤如:
步骤1,构建训练数据集。
1a)在交通要道拍摄若干个行驶车辆的视频,将这些视频每隔10帧保存为一张图片,根据视频分辨率设置图片大小为1920*1080,放入JPEGImages文件夹中,本实例视频的视频图像为2300张;
1b)对训练图片进行重命名,使图片名从“000001.jpg”开始按从小到大顺序排列,如果图片较多,则可在MATLAB中调用imwrite函数进行批量重命名,调用格式如下
imwrite(img,strcat(save_path,newname)),
其中,img为需要修改名字的训练集图片,save_path为修改后图片的存储路径,newname为修改后的图片名;
1c)划定感兴趣区域,将每幅图片中感兴趣区域内车辆的车窗信息进行标注保存,保存为文档格式,如图2所示,每行内容依次是图片名,目标类别,和目标车窗的包围框的左上角横纵坐标和右下角横纵坐标;打开“图像标注.EXE”程序,按以下步骤对图片进行标注:
1c1)待图片显示到屏幕后,将输入法切换到英文;
1c2)选择车窗左上角按鼠标左键,拉一个包围框到当前车辆车窗的右下角,然后键盘按下“1”,表示该车窗的标签是“1”;
1c3)继续1c2)操作,直到框完该张图片上的车窗,如图3所示;
1c4)按N键进入下一张图片;
1c5)所有图片标注完成后,按ESC键退出;
1d)使用文档自带的查找替换命令,将(1c)中得到的文档文件中标签“1”替换为“car”。再使用MATLAB程序“VOC2007xml_new”将标注产生的文档文件转换为与之对应的xml文件,最终生成对应每一幅图片的xml文件格式,见图4;
1e)新建一个文件夹,名字为Annotations,将xml文件全部放到该文件夹里;新建另一个文件夹,名字为JPEGImages,将所有的训练图片放到该文件夹里;
1f)新建文件夹ImageSets,在ImageSets文件夹里再新建子文件夹Main,通过xml文件名,生成两个文档文件,文档文件中的内容如图3所示,其中test.txt是测试集,trainval.txt是训练和验证集,将这两个txt文件放在ImageSets下的Main文件夹中。
步骤2,搭建SSD训练网络架构。
本发明网络的搭建以及训练参数的设置均以python文件的方式编辑实现,其实现如下:
2a)在linux系统下打开终端,依次输入以下命令下载和安装caffe-ssd深度学习平台:
2a1)输入命令:git clone https://github.com/weiliu89/caffegit,下载平台源码;
2a2)输入命令:cd caffe,进入工作路径;
2a3)输入命令:git checkout ssd,验证文件的完整性;
2a4)修改Makefile文件中的工作路径为当前路径,再输入命令:make all,对平台进行编译,编译成功后,caffe-ssd平台安装完成;
2a5)输入命令:make pycaffe,生成caffe的python接口,以用于接下来的训练;
2b)下载并打开VGG-16网络结构文件deploy.prototxt,修改其中的VGGNetBody函数,即将其中的fully_conv参数修改为True,将dropout参数修改为False,将freeze_layers参数修改为[‘conv1_1’,’conv1_2’,’conv2_1’,’conv2_2’],将其他参数均选取默认值;再将修改后的网络作为基础网络base_network;
2c)在基础网络base_network的后面添加三组额外的卷积层以及一层池化层,即直接在网络末尾添加相应代码,并修改ssd_pascal.py文件中的AddExtraLayers函数,将添加的额外卷积层的范围设置为7-9;
2d)修改ssd_pascal.py文件中的训练参数solver_param,增加其最大迭代次数,并调整基础学习率,使其训练收敛;
2e)在ssd_pascal.py文件中,调用caffe.model的libs库中的CreateMultiboxHead函数,设置该函数的输入参数,以创建mbox_layers层,其参数设置步骤如下:
2e1)设置特征层参数from_layers,选取5个卷积层“conv4_3”层,“fc7”层,“conv6_2”层,“conv7_2”层,“conv8_2”层和一个池化层“pool6”层作为提取特征层;
2e2)设置尺度参数aspect_ratios,使模型能够分辨不同尺度下的汽车;
2e3)设置类别数num_classes为2,表示所要区分的车辆和背景这两种类别;
2e4)将卷积核大小设为3,表示以3x3的卷积核进行特征提取,汇聚局部特征。
步骤3,转换数据格式开始训练。
3a)修改caffe_ssd/data/VOC0712文件夹下的标签字典labelmap_voc.prototxt,将标签字典改为“汽车”和“背景”这两个类别;
3b)运行create_list.sh程序,生成训练所需的文件名列表文件,即trainval.txt文件和test.txt文件,文件内容如图5所示,其中,图5(a)为trainval.txt文件截图,图5(b)为test.txt的文件截图;再运行create_data.sh程序,根据文件名列表文件,产生相应的lmdb格式文件;
3c)执行相关文件,按如下步骤进行训练,得到最终的训练模型:
3c1)用K个随机取值的卷积核对图像进行卷积得到K个特征图;
3c2)从K个特征图中选取几个特征图,按不同的权重输入到损失函数中计算损失值,并采用梯度下降法更新卷积核的大小和权重的大小;
3c3)重复3c1)-3c2),直到损失函数达到最小,记录卷积核和权重的值。
步骤4,利用训练模型进行视频车辆检测。
4a)修改文件中的训练模型路径和待测视频路径,将待测视频输入到训练模型中;
4b)对待测视频进行预处理,即将视频转化为图片格式并将图片输入到训练模型中;
4c)对于输入的每一张图片,模型将随机的选取多个区域;
4d)使用卷积核与每个区域作二维卷积,并按如下步骤计算图片中各区域的得分:
4d1)用K个训练好的卷积核与一个区域进行二维卷积,得到K个卷积值;
4d2)将K个卷积值求加权平均,即得到该区域的打分。
4e)将阈值δ设为0.3,对于每一张图片,依次将图片上每个区域得分与δ进行比较,若得分高于δ,模型将判断该区域包含车窗,并调用绘图函数对其进行标注;若得分低于δ,模型将判断该区域不包含车窗,直到图像上所有被判断为包含汽车车窗的区域均标注完成;
4f)重复4c)-4e),直到4b)输入到模型中的图片均处理完成,再调用输出命令,将处理过的图片转化为视频格式,并输出到屏幕上完成测试,测试结果如图6所示,其中,图6(a)为雨天时的检测效果,图6(b)为拥堵时的检测效果,图6(c)为有阴影时的检测效果。
图6的检测结果可以明显的看出:本发明的检测框架对各种复杂的环境条件,如:拥堵、雨天、阴影下车辆的检测统计效果提升明显,并且能够达到实时检测,极大地降低了漏检、误检概率。
- 还没有人留言评论。精彩留言会获得点赞!