服务器的硬件监控装置的制作方法
本发明涉及服务器技术领域,具体来说,涉及一种服务器的硬件监控装置。
背景技术:
在现代数据中心(Internet DataCenter,IDC)中,服务器节点的数量越来越多,相应的运维工作负担也越来越重,如何能够更早更准确的发现服务器存在的硬件问题,成为了保证数据中心业务正常运转的首要问题。
现有的对服务器进行监控的方法是,IDC的运维人员需要每隔一段时间到机房去巡检一次,以便于及时的发现问题,但是,机房巡检也只能通过服务器的指示灯去观察硬件的状态,一些隐藏的问题(例如,内存可修正错误导致CPU性能下降)是无法发现的。
现有技术中的另外一种对服务器进行监控的方法是,为服务器统一提供一种BMC(Baseboard Management Controller,基板管理控制器)机制去获取硬件健康状态,但是BMC无法获取服务器所有硬件的状态。
针对相关技术中的上述问题,目前尚未提出有效的解决方案。
技术实现要素:
针对相关技术中的上述问题,本发明提出一种服务器的硬件监控装置,能够远程对服务器的硬件状态进行监控,从而有效降低人工巡检强度。
本发明的技术方案是这样实现的:
根据本发明的一个方面,提供了一种服务器的硬件监控装置,包括:第一获取模块,用于通过服务器的操作系统获取CPU的状态数据、内存的状态数据、硬盘的状态数据;第二获取模块,用于通过BMC获取主板状态数据、风扇状态数据、电源状态数据、和温度状态数据;以及处理及报警模块,连接于第一获取模块和第二获取模块,用于根据需要对CPU的状态数据、内存的状态数据、硬盘的状态数据、主板状态数据、风扇状态数据、电源状态数据、和温度状态数据进行监控,还用于当其中的任意一种超出相应的设定阈值时判断对应的硬件出现故障并进行报警。
根据本发明的一个实施例,第一获取模块包括:CPU及内存数据获取单元,用于通过MCE机制获取CPU的状态数据和内存的状态数据。
根据本发明的一个实施例,CPU的状态数据包括TLB状态数据、Cache状态数据、和总线状态数据;当TLB状态数据、Cache状态数据、和总线状态数据之中的任意一种发生故障时,处理及报警模块进行报警。
根据本发明的一个实施例,第一获取模块包括硬盘数据获取单元;其中,硬盘的状态数据包括SMART信息。
根据本发明的一个实施例,硬盘包括RAID卡;以及硬盘的状态数据包括RAID卡的芯片状态数据、RAID卡的缓存状态数据、RAID卡的温度状态数据、和RAID卡的链路状态数据;其中,硬盘数据获取单元通过RAID卡工具获取RAID卡的芯片状态数据、RAID卡的缓存状态数据、RAID卡的温度状态数据、和RAID卡的链路状态数据。
根据本发明的一个实施例,RAID卡的链路状态数据包括Invalid DWORD count指标,当Invalid DWORD count指标在运行期间出现上涨时,处理及报警模块进行报警。
根据本发明的一个实施例,温度状态数据包括:CPU温度数据、内存温度数据、服务器环境温度数据、服务器出风口温度数据、和BMC温度数据。
根据本发明的一个实施例,内存的状态数据包括内存可修正错误发生的次数和内存不可修正错误发生的次数;当内存不可修正错误发生的次数在1次以上时,处理及报警模块进行报警;当24小时内内存可修正错误发生的次数在1次以上时,处理及报警模块进行报警。
根据本发明的一个实施例,RAID卡的缓存状态数据包括缓存可修正错误发生的次数和缓存不可修正错误发生的次数;当缓存不可修正错误发生的次数在1次以上时,处理及报警模块进行报警;当24小时内缓存可修正错误发生的次数在1次以上时,处理及报警模块进行报警。
根据本发明的一个实施例,服务器的操作系统为Linux操作系统。
本发明能够实现通过计算机远程获取服务器的硬件状态,从而有效降低人工巡检强度;同时能够更为即时地发现服务器故障,并可以准确的对故障硬件进行定位,进而提高了维修效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的服务器的硬件监控装置的框图;
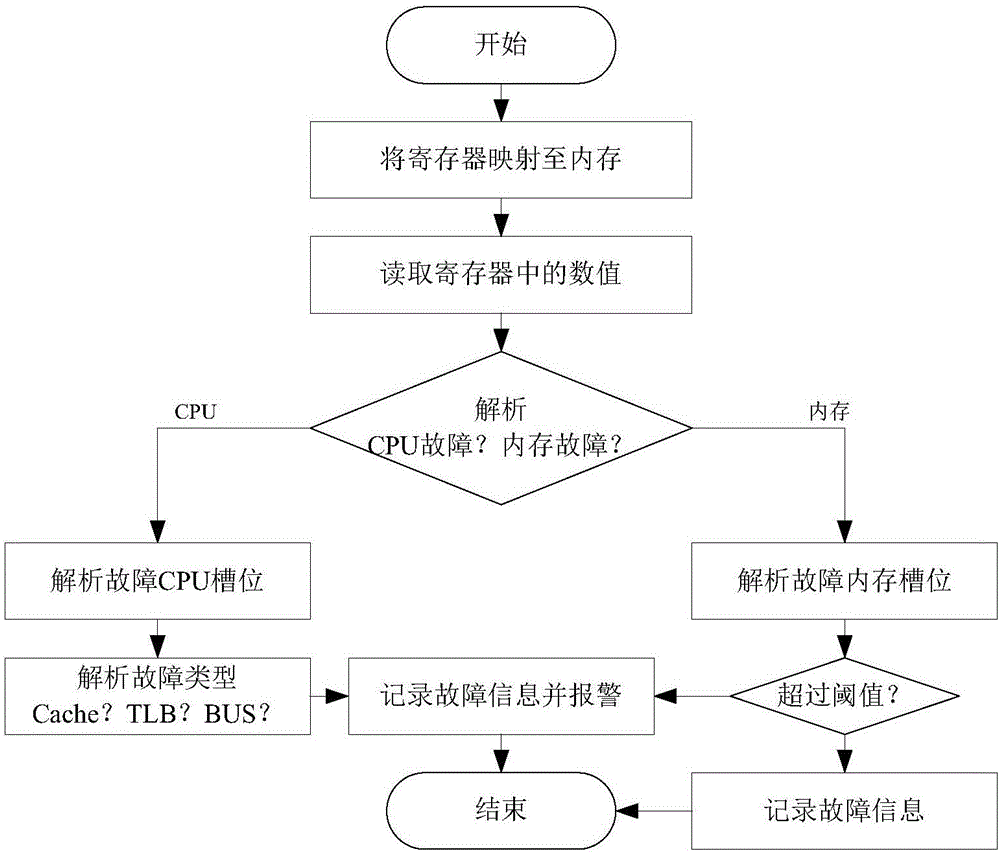
图2是根据本发明实施例的服务器的硬件监控装置对CPU和内存进行监控的流程图;
图3是根据本发明实施例的服务器的硬件监控装置对硬盘进行监控的流程图;
图4是根据本发明实施例的服务器的硬件监控装置的RAID卡工具获取RAID卡数据的示意图;
图5是根据本发明实施例的服务器的硬件监控装置的通过BMC进行监控的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
根据本发明的实施例,提供了一种服务器的硬件监控装置。
如图1所示,根据本发明实施例的服务器的硬件监控装置包括:第一获取模块10、第二获取模块20、和连接于所述第一获取模块10和所述第二获取模块20的处理及报警模块30;其中,第一获取模块10用于通过服务器的操作系统获取CPU的状态数据、内存的状态数据、硬盘的状态数据;第二获取模块20用于通过BMC(Baseboard Management Controller,基板管理控制器)获取主板状态数据、风扇状态数据、电源状态数据、和温度状态数据;处理及报警模块30用于根据需要对CPU的状态数据、内存的状态数据、硬盘的状态数据、主板状态数据、风扇状态数据、电源状态数据、和温度状态数据进行监控,当其中的任意一种超出相应的设定阈值时,则处理及报警模块30判断对应的硬件出现故障并进行报警。
通过本发明的上述技术方案,使得运维人员能够实现通过计算机远程获取服务器的硬件状态,从而有效降低人工巡检强度;同时能够更为即时地发现服务器故障,并可以准确的对故障硬件进行定位,进而提高了维修效率。
在一个实施例中,服务器的操作系统为Linux操作系统。
在一个实施例中,第一获取模块10可以包括CPU及内存数据获取单元11,用于通过MCE(Machine Check Exception)机制获取CPU的状态数据和内存的状态数据,MCE机制是英特尔CPU中用于获取CPU和内存健康状态的一种机制。具体地,结合图2所示,CPU及内存数据获取单元11可利用英特尔CPU提供的MCE机制,通过读取CPU中的一组寄存器的数值并对这些数值进行翻译,从而获得CPU和内存控制器的健康状态。
其中,CPU的状态数据包括TLB(Translation Lookaside Buffer,翻译后备缓冲器)状态数据、Cache(高速缓冲存储器)状态数据、和总线(BUS)状态数据;当TLB状态数据、Cache状态数据、和总线状态数据之中的任意一种发生故障时,处理及报警模块30进行报警。即本发明的服务器的硬件监控装置可以监控TLB、Cache、总线三类硬件故障,三类硬件故障报警的规则为只要发生一次,则立刻触发报警。
进一步地,内存的状态数据包括内存可修正错误发生的次数和内存不可修正错误发生的次数;当内存不可修正错误发生的次数在1次以上时,处理及报警模块30进行报警;当24小时内内存可修正错误发生的次数在1次以上时,处理及报警模块30进行报警。即本发明针对内存,主要监控内存可修正错误发生的次数和内存不可修正错误发生的次数。处理及报警模块30针对内存的故障报警规则为:内存可修正错误在24小时内如果发生的次数超过1次则触发报警,内存不可修正错误只要发生1次就触发报警。
在一个实施例中,第一获取模块10包括硬盘数据获取单元12;其中硬盘的状态数据包括SMART信息。结合图3所示,硬盘的健康状态获取主要来源于硬盘内部的SMART信息。SMART信息能够提供一组数据来表明硬盘的当前状态。本发明通过解析SMART信息来确定硬盘是否存在故障。
在一个实施例中,硬盘包括RAID(Redundant Arrays of Independent Disks,磁盘阵列)卡;以及硬盘的状态数据包括RAID卡的芯片状态数据、RAID卡的缓存状态数据、RAID卡的温度状态数据、和RAID卡的链路状态数据;其中,硬盘数据获取单元12通过RAID卡工具获取RAID卡的芯片状态数据、RAID卡的缓存状态数据、RAID卡的温度状态数据、和RAID卡的链路状态数据。
进一步地,RAID卡的链路状态数据包括Invalid DWORD count指标,当Invalid DWORD count指标在运行期间出现上涨时,处理及报警模块30进行报警。如图4所示,对于RAID卡,可以使用RAID卡厂商提供的RAID卡监控工具(例如storcli工具)来获取RAID卡的状态数据。使用本发明可以监控RAID卡的芯片状态、缓存状态、温度状态以及链路状态。其中,RAID卡的链路状态数据包括SMART信息中用于监控链路状态的4个指标:Invalid DWORD count,Running disparity error count,Loss of DWORD synchronization,Phy reset problem,该4个指标若出现上涨则存在链路故障的风险。其中Invalid DWORD count为最重要指标,在本发明中其阈值为:从监控运行开始到当前时间该指标不能出现上涨。
在一个实施例中,RAID卡的缓存状态数据包括缓存可修正错误发生的次数和缓存不可修正错误发生的次数;当缓存不可修正错误发生的次数在1次以上时,处理及报警模块30进行报警;当24小时缓存可修正错误发生的次数在1次以上时,处理及报警模块30进行报警。具体地,可通过RAID卡厂商提供的RAID卡监控工具获取到RAID卡的缓存状态数据出错类型和相应的次数。出错类型分为可修正错误和不可修正错误。可以通过设定阈值的方式来出发故障报警。对于可修正错误,阈值为每24小时超过1次报警。对于不可修正错误,阈值为只要发生就立刻报警。
另外,还可以通过RAID卡监控工具获取RAID卡的温度状态数据,进而通过将RAID卡的温度状态数据与其对应的阈值进行比较,并在超出其对应的阈值时进行报警。在本实施例中,RAID卡的温度状态数据对应的阈值设定为100℃。
如图1和图5所示,可以通过BMC获取主板状态数据、风扇状态数据、电源状态数据、和温度状态数据。可以使用BMC监控工具,例如ipmitool工具(一种可用在Linux系统下的管理工具),来获取BMC各个传感器的数值。通过对这些传感器数值进行分析,从而确定主板、风扇、电源等硬件是否正常工作。其中,第二获取模块20可以包括用于获取主板状态数据的主板数据获取单元21、用于获取风扇状态数据的风扇数据获取单元22、用于获取温度状态数据的温度数据获取单元23、和用于获取电源状态数据的电源数据获取单元24。
具体地,温度状态数据可以包括:CPU温度数据、内存温度数据、服务器环境温度数据、服务器出风口温度数据、和BMC温度数据。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!