一种基于GPU的光线跟踪方法与流程
本发明属于计算机图形学领域,特别涉及一种基于GPU的光线跟踪方法。
背景技术:
光线跟踪方法用于生成逼真的三维虚拟场景,是计算机图形学核心之一。自提出之日起发展至今,已经被广泛应用于影视制作、三维仿真、计算机辅助设计等领域,并且极大的促进了虚拟现实技术的进步。该方法是一项基于几何光学的通用技术,它通过跟踪与物体发生交互作用的光线,从而得到光线在物体表面产生的反射、散射等现象的路径,用以模拟生成真实的虚拟场景,被认为是图形处理的未来方向。光线跟踪方法需要跟踪场景中的每一条光线,由此涉及到每一条光线的折射、反射,并最后完成投影、可见面判定和着色三方面的任务,这导致了成像过程中计算开销的增大。尤其在大型复杂场景中,光线与物体相交次数多,并且由于物体表面材质的不同使得光线传播路线复杂,这都导致了计算开销的剧增。因此,计算密集且费时费力成为光线跟踪发展的重大障碍。
提高光线跟踪的效率一直是该领域研究的重点。目前,这类问题的研究主要分为两个方向:一是改进空间加速结构,提高光线在场景中求交的速度;二是利用计算机硬件的并行原理,加快光线跟踪算法的执行速度。文献“启发式探查最佳分割平面的快速KD—Tree构建方法”,提出了一种基于分区(binning)算法的快速构建方法,该方法首先通过分析kd—tree的成本函数,启发式地定位了当前节点的分割平面所在的子区间;其次,对探查到的子区间进行进一步的细化采样(sub-sampling),使得到的分削平面更好地逼近最优分割位置,但是文章实现的是算法的单线程版本,未对内存管理进行优化,未充分利用计算机并行处理的优势,还有很大的提高空间。文献“基于物理的分布并行光线跟踪算法”针对斯坦福大学经典的多线程光线跟踪引擎——PBRT,提出了动态自适应分布式并行光线跟踪方法,首先利用裁剪窗口概念设计了为每个计算节点分配任务的方法,为计算机集群分布并行光线跟踪提供了粗粒度渲染单元;然后过分析比较分布式光线跟踪方法中静态和动态任务调度策略的优缺点,提出了一种静态和动态相结合的任务分配策略,提高了节点间的负载均衡度,该方法具有良好的效率和扩展性,提高了光线跟踪方法的并行度,但是算法单纯利用CPU集群,未考虑使用GPU提高渲染效率。
可见上述方法中虽然对很大程度上提升了传统光线跟踪的效率,但在当今计算机架构下,未能充分发挥计算机的性能,在实际的应用过程中却存在着渲染效率低的问题,不能满足现实需求。
技术实现要素:
针对现有技术存在的问题,本发明提供一种基于GPU的光线跟踪方法。
本发明的技术方案如下:
一种基于GPU的光线跟踪方法,包括:
步骤1:CPU端加载场景模型,解析得到三角片元信息、材质信息、光源信息后打包发送给GPU端;
步骤2:GPU端得到三角片元信息、材质信息、光源信息,分别存储到对应的全局存储器和常量存储器;
步骤3:GPU端建立以整个3D场景的场景模型为根节点的Kd-Tree;
步骤4:GPU端进行光线跟踪操作;
步骤5:CPU端进行后期图像处理:CPU端读取图像缓存区的像素信息,显示到屏幕,完成渲染。
所述步骤1,包括:
步骤1.1:CPU端开辟内存或显存空间,将场景模型加载到内存或显存空间中;
步骤1.2:CPU端对场景模型进行解析,得到三角片元信息、材质信息、光源信息;
步骤1.3:将解析好的三角片元信息、材质信息、光源信息分别打包发送到GPU端。
所述步骤3,包括:
步骤3.1:建立3D场景中的各个场景模型的包围盒及整个3D场景模型的包围盒;
步骤3.2:以整个3D场景模型的包围盒为根节点,自上而下进行分割,建立以Kd-Tree。
所述步骤3.2,包括:
步骤3.2.1:分别将整个3D场景模型的包围盒沿着不同轴向分割成两个子空间即得到左孩子节点、右孩子节点,分别划入左子树、右子树;
步骤3.2.2:计算不同轴向的分割成本C(V)≈Kt+Ki(PL Nl+ PR Nr),Nl,Nr为左孩子节点、右孩子节点中的场景模型包围盒数量,Kt、Ki为常数,PL、PR为光线进入左子树、右子树的概率,PL=SA(VL)/SA(V),SA(VL)表示左孩子节点中的场景模型包围盒的表面积和,SA(V) 表示3D场景中的所有场景模型包围盒的表面积和,PR=SA(VR)/SA(V),SA(VR)表示右孩子节点中的场景模型包围盒的表面积和;
步骤3.2.3:选择最小的分割成本对应的轴向分割平面,将整个3D场景模型的包围盒分割为左孩子节点、右孩子节点;
步骤3.2.4:对步骤3.2.3中分割得到的左孩子节点、右孩子节点均执行步骤3.2.1~3.2.3;
步骤3.2.5:判断是否到达最大分割深度或左孩子节点、右孩子节点内部三角片元数均小于指定阈值,是则停止继续分割,当前的分割结果即建立的Kd-Tree;否则执行步骤3.2.1。
所述步骤4,包括:
步骤4.1:初始化光线簇:根据3D场景中的相机位置生成光线,作为光线簇,存储在光线簇缓存区;
步骤4.2:判定当前光线是否与Kd-Tree的包围盒相交:如果相交,则进行包围盒内部的场景模型与当前光线的相交测试,执行步骤4.3;否则当前光线不与Kd-Tree的包围盒内部的场景模型相交,将该场景模型作为背景信息填充到图像缓存区;
步骤4.3:如果当前光线与包围盒内部的场景模型相交,则根据光源位置判断交点的可见性:如果光源被遮挡,则交点不可见,如果光源未被遮挡,则记录该交点处为光照处,并将该交点填充到图像缓存区;如果当前光线与包围盒内部的场景模型不相交,则将该场景模型作为背景信息填充到图像缓存区;
步骤4.4:根据交点处场景模型的光线信息计算反射光线,并将反射光线设为当前光线,继续追踪;
步骤4.5:当前光线簇缓存区非空且未到达最大遍历深度,返回步骤4.2,对光线簇缓存区中的下一条光线进行追踪;否则停止追踪。
有益效果:
本发明中CPU端加载场景模型,解析得到三角片元信息、材质信息、光源信息后打包发送给GPU端,分别存储到对应的全局存储器和常量存储器;GPU端建立以整个3D场景的场景模型为根节点的Kd-Tree;进行光线跟踪操作;CPU端进行后期图像处理。通过合理调用CPU和GPU协同工作提高光线跟踪效率。与传统的CPU渲染相比,渲染效率有明显提高,能够在较短时间内完成相同效果的模型渲染工作。Kd-Tree的应用能够提高光线跟踪时光线求交的效率,而GPU的使用,是利用其大规模并行执行的优势,在光线跟踪时能够多条光线并行执行,提高光线跟踪效率。
附图说明
图1是光线跟踪原理示意图;
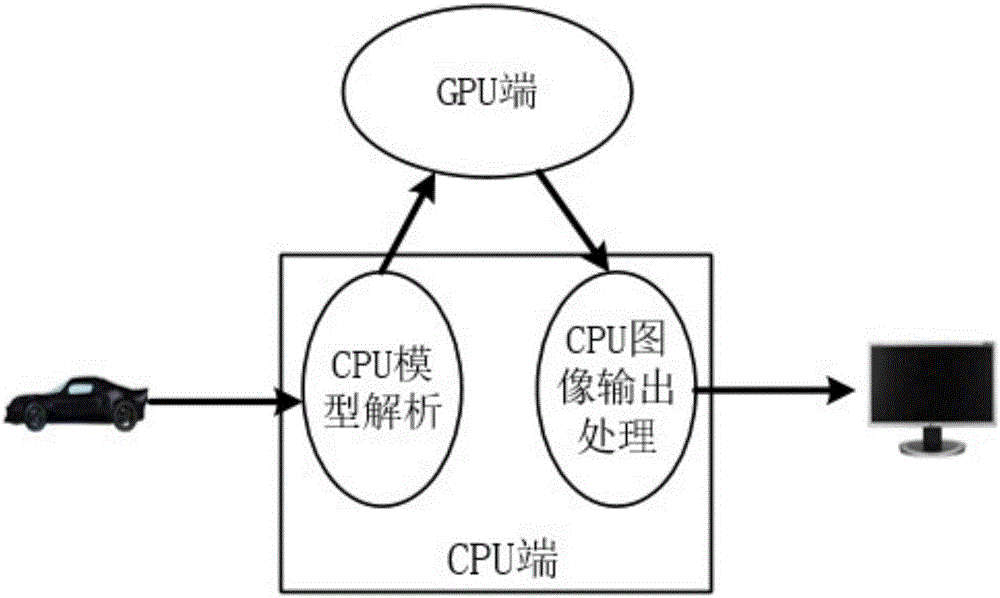
图2是本发明具体实施方式中所采用的系统框架图;
图3是本发明具体实施方式中基于GPU的光线跟踪方法流程图;
图4是本发明具体实施方式中的场景模型Dragon;
图5是本发明具体实施方式中Kd-Tree示意图,(a)是 Kd-Tree对应二维数据集合的一个空间划分示意图,(b)是构建的Kd-Tree示意图,(c)是构建的Kd-Tree在三维空间的应用示意图。
具体实施方式
下面结合附图对本发明的具体实施方式做详细说明。
本实施方式原理如图1所示:在光线跟踪中,跟踪的方向与光传播的方向相反。即光线首先从视点(摄像机)处出发,射向虚拟场景中。若光线与场景中的物体没有交点,则光线将射出平面,追踪结束。反之,光线在场景中物体表面最近的交点处走向有以下三种可能:交点具有理想漫反射性质,采用漫反射方向追踪;交点具有理想镜面性质,光线顺着镜面反射方向继续追踪;交点是规则透射点,光线顺着投射方向继续追踪。光线跟踪是一个递归的过程,当满足下述条件之一即可终止:光线与场景中的物体没有交点;光线对像素的贡献值小于某个预先设定的阈值;当前递归的深度超过了最大追踪深度。
本实施方式采用如图2所示的系统,包括GPU端和CPU端。CPU端负责3D模型解析和后期图像处理后输出,GPU端负责加速结构Kd-Tree的创建和光线跟踪操作。系统流程如图3所示.场景模型首先由CPU端处理,主机端开辟内存/显存空间,将场景模型加载到内存中;然后CPU对场景模型进行解析;将模型信息解析为三角片元数据、材质数据和光源信息,再分别打包发送到GPU端;GPU端将三角片元信息、材质信息、光源信息,分别存储到对应的全局存储器和常量存储器;并建立以各场景模型的包围盒为叶子节点、整个3D场景的场景模型为根节点的Kd-Tree;然后进行光线跟踪操作。
本发明利用CUDA框架在GPU上实现光线跟踪,CUDA(Compute Unified Device Architecture,统一计算设备架构)是NVIDIA公司推出的编程模型,可以在应用程序中充分利用CPU和GPU各自的优点,使得利用GPU的计算性能显著提升,调用CPU与GPU协同处理。
一种基于GPU的光线跟踪方法,如图3所示,包括:
步骤1:CPU端加载场景模型Dragon,如图4所示,解析得到三角片元信息(566098 个顶点,1132830个三角形)、材质信息(0.250000,0.250000,0.250000,1.000000,0.400000,
0.400000,0.400000,1.000000,0.774597,0.774597,0.774597,1.000000,76.800003)、光源信息后打包发送给GPU端;
步骤2:GPU端得到三角片元信息、材质信息、光源信息,分别存储到对应的全局存储器和常量存储器;
步骤3:GPU端建立以整个3D场景的场景模型为根节点的Kd-Tree;
步骤4:GPU端进行光线跟踪操作;
步骤5:CPU端进行后期图像处理:CPU端读取图像缓存区的像素信息,显示到屏幕,完成渲染。
上述步骤1,包括:
步骤1.1:CPU端开辟内存或显存空间,将场景模型加载到内存或显存空间中;
步骤1.2:CPU端对场景模型进行解析,得到三角片元信息、材质信息、光源信息;
步骤1.3:将解析好的三角片元信息、材质信息、光源信息分别打包发送到GPU端。
上述步骤3,包括:
步骤3.1:建立3D场景中的各个场景模型的包围盒及整个3D场景模型的包围盒;
步骤3.2:以整个3D场景模型的包围盒为根节点,自上而下进行分割,建立以Kd-Tree;
步骤3.2.1:分别将整个3D场景模型的包围盒沿着不同轴向(X、Y、Z轴方向)分割成两个子空间即得到左孩子节点、右孩子节点,分别划入左子树、右子树;
步骤3.2.2:计算不同轴向的分割成本C(V)≈Kt+Ki(PL Nl+ PR Nr),Nl,Nr为左孩子节点、右孩子节点中的场景模型包围盒数量,Kt、Ki为常数,PL、PR为光线进入左子树、右子树的概率,PL=SA(VL)/SA(V),SA(VL)表示左孩子节点中的场景模型包围盒的表面积和,SA(V) 表示3D场景中的所有场景模型包围盒的表面积和,PR=SA(VR)/SA(V),SA(VR)表示右孩子节点中的场景模型包围盒的表面积和;
步骤3.2.3:选择最小的分割成本对应的轴向分割平面,将整个3D场景模型的包围盒分割为左孩子节点、右孩子节点;
步骤3.2.4:对步骤3.2.3中分割得到的左孩子节点、右孩子节点均执行步骤3.2.1~3.2.3,分割结果如图5(a)所示,创建好的整个Kd-Tree的逻辑结构如图5(b)所示;
步骤3.2.5:判断是否到达最大分割深度或左孩子节点、右孩子节点内部三角片元数均小于指定阈值,是则停止继续分割,当前的分割结果即建立的Kd-Tree;否则执行步骤3.2.1。最终整个3D场景中的Kd-Tree划分结果如图5(c)所示。
上述步骤4,包括:
步骤4.1:初始化光线簇:根据3D场景中的相机位置生成光线,作为光线簇,存储在光线簇缓存区;
步骤4.2:判定当前光线是否与Kd-Tree的包围盒相交:如果相交,则进行包围盒内部的场景模型与当前光线的相交测试,执行步骤4.3;否则当前光线不与Kd-Tree的包围盒内部的场景模型相交,将该场景模型作为背景信息填充到图像缓存区;
步骤4.3:如果当前光线与包围盒内部的场景模型相交,则根据光源位置判断交点的可见性:如果光源被遮挡,则交点不可见,如果光源未被遮挡,则记录该交点处为光照处,并将该交点填充到图像缓存区;如果当前光线与包围盒内部的场景模型不相交,则将该场景模型作为背景信息填充到图像缓存区;
步骤4.4:根据交点处场景模型的光线信息计算反射光线,并将反射光线设为当前光线,继续追踪;
步骤4.5:当前光线簇缓存区非空且未到达最大遍历深度,返回步骤4.2,对光线簇缓存区中的下一条光线进行追踪;否则停止追踪;
步骤5:CPU端进行后期图像处理:CPU端读取图像缓存区的像素信息,显示到屏幕,完成渲染。
- 还没有人留言评论。精彩留言会获得点赞!