一种基于视频流与人脸多属性匹配的三维人脸建模方法和打印装置与流程
本发明涉及人脸三维建模技术,特别是涉及一种基于视频流与人脸多属性匹配的三维人脸建模方法和打印装置。
背景技术:
许多研究者充分利用计算机在处理图像图形方面的优良性能来模拟和演示三维人脸模型并取得了很大成就。人脸动画已经从传统的关键帧技术发展到表演驱动技术。从可视电话到游戏娱乐,从多通道用户界面到虚拟现实,到处都体现着人脸建模与动画的技术。同时,人们对利用计算机进行三维人脸建模的效果和质量要求也越来越严格,不再仅仅满足于动作僵硬、表情呆板、背景单调的三维人脸及其动画。如何提高建模精确度、丰富模型表情逼真度的技术问题,仍然是该领域的研究热点和研究者共同追求的目标。
目前,关于三维人脸建模的方法主要包括如下几种:1)基于三维扫描仪的三维人脸建模;2)基于单幅人脸图像的建模;3)基于拟合或重建的技术。
但是,现有的三维人脸建模技术存在以下几个问题:
基于三维扫描仪的方法往往存在通用性和灵活性较差的问题,此外,其建模过程的数据量大,操作较为复杂,且其硬件设备的成本昂贵,计算复杂度过高。
基于单幅人脸图像的建模方法由于计算过程复杂,从而导致运算时间过长、计算结果偏差大等不足,通常难以获得良好的建模效果。
基于拟合或重建的技术一般都需要用户的配合,用户友好性较差。例如手工标记关键点、使用前进行用户注册、在建模时需保持无表情或者固定表情等,不能精确地模拟实时的用户表情;同时,外貌、姿态对表情参数精度的影响较大,导致建模精度存在一定的瓶颈。
技术实现要素:
为克服现有技术的不足,本发明的目的在于提供一种精确度高、实现方式简单、用户友好性好、自动快速、建模结果逼真且极具个性化的三维人脸建模方法和装置。
本发明为解决其技术问题采用的技术方案是:
一种基于视频流与人脸多属性匹配的三维人脸建模方法,包括:
建立通用三维人脸模型库,所述三维人脸模型库按照属性分类,所述属性包括性别、年龄、脸型;
采集实时视频中的多幅正侧面人脸图像进行归一化处理,通过预先训练好的多任务学习深度神经网络进行人脸检测及人脸关键点信息提取,并结合多人脸个关键点信息对齐人脸;
利用预先训练好的多任务学习深度神经网络进行人脸属性分析预测,所述属性包括性别、年龄、脸型,结合人脸关键点数据和人脸属性信息与所述的通用三维人脸模型库进行粗配准,获得最接近实时采集的人脸通用模型;
采用关键点优化技术和纹理细化处理技术对粗配准的通用三维人脸模型进行微调修正,合成具有真实感的实时三维人脸视觉外观。
进一步,所述建立通用三维人脸模型库,三维人脸模型库按照属性分类具体包括:
利用三维扫描仪采集原始真实的三维人脸模型并进行规一化处理;
对规一化人脸模型的形状和纹理分别进行主成分分析,得到形变三维人脸模型,最终由三维扫描仪采集到的原始三维人脸模型和经过形变处理的三维人脸模型构成完备的通用三维人脸模型库。
对完备通用三维人脸模型库标注其对应的属性,所述属性包括性别、年龄、脸型,并根据属性对应的类别建立最终的通用三维人脸模型库。
进一步,所述对完备通用三维人脸模型库标注其对应的属性具体包括:
以性别细分为男、女两项;
以年龄段为分类项,共设为儿童、少年、青年、中年、老年5大类,其中儿童时期细分为0-3、4-6岁,少年时期细分为7-12、13-17岁,青年时期细分为18-25、26-40岁,中年时期细分为41-50、51-65岁,老年时期为66岁以上;
以脸型为分类项,将每个年龄段分为多种脸型,分别是椭圆脸型、长脸型、四方脸型、倒三角型、菱形脸型、三角脸型、圆脸型。
进一步,所述人脸关键点包括:脸部轮廓、眼角点、眉间点、鼻下点、颌下点、嘴角点。
进一步,所述多任务学习深度神经网络的训练过程具体包括:
采集标准人脸图像并标注其对应的多个属性的类别,形成一个完备的训练数据集合;
同时进行人脸检测以及人脸关键点定位,并结合多个关键点坐标信息准确对齐人脸;
对标注类别中的属性进行编码;
构造深度神经网络;
利用训练数据集合,训练深度神经网络,最终通过大量训练获得多任务学习深度神经网络模型。
进一步,所述深度神经网络依次包括:输入层、卷积层、非线性层、池化层、二次卷积层、混合卷积层、多属性分类层、输出层;
所述卷积层、非线性层、池化层、二次卷积层分别设置有一个或者一个以上,卷积层的输出作为非线性层或者池化层或者二次卷积层的输入,非线性层的输出作为下一个卷积层的输入;
二次卷积层和池化层的输出作为混合卷积层的输入;
混合卷积层的输出作为多属性分类层的输入;
多属性分类层的输出连接输出层,最终输出分类结果。
进一步,所述采用关键点优化技术具体包括:
首先构造所述人脸关键点信息组合向量A={xc1,xc2,xc3…xcn},其中xci(i=1,2,3…n)表示所述的关键点信息的第i种信息子向量;
然后通过凸优化目标函数得到最优解使得所对齐的人脸关键点参数误差最小;
其中,优化目标函数的约束条件为:θi≥0,∑θi=1;
表示所对齐的关键点和目标关键点之间的偏差,x为所述的关键点信息任意一种信息子向量,符号minθ表示关于求θ极小值,符号||||表示关于求范数;
最后根据最优解对所匹配获得的通用三维人脸模型进行人脸关键点精确对齐。
进一步,所述的纹理细化处理技术,具体包括:
首先计算人脸纹理的有效区域,在纹理图像上,如果一个像素所对应的顶点在图像上的投影坐标位于人脸轮廓之内,并且该顶点在投影角度下是可见的,则相应的像素就位于人脸纹理的有效区域内;
计算每个像素处的位置确定度p,将位置确定度作为代价函数中该像素处的权重,位置确定度定义为投影方向与顶点的法向量之间夹角的余弦;
为重建的三维人脸模型加入两个光照,分别位于三维人脸模型的左前方和右前方各45度,光照的位置固定且强度可变;
以形状无关纹理SIFT为拟合的目标图像,以人脸形变模型的纹理分量合成人脸纹理S1;将代价函数Eξ设置为合成的纹理图像与目标图像之间的偏差,代价函数在纹理的有效区域内进行计算,通过目标函数Eξ>0利用梯度下降法将求得代价函数最小值,然后得到合成的纹理图像S;
选取一个纹理融合的优化系数I,将合成的人脸纹理图像S与形状无关纹理SIFT进行融合,取出形状无关纹理的中心区域补充到合成的纹理图像上,以补充人脸的细节,得到最终融合后的纹理R,其中R=I·SIFT+(1-I)·S。
本发明还提供了一种基于视频流与人脸多属性匹配的三维人脸建模打印装置,包括:
输入单元,用于获取实时视频流中的原始人脸图像;
特征点标记单元,用于在所述原始人像上标记特征点并记录其坐标信息;
通用三维人脸模型库单元,存储有通用三维人脸模型库离线包;
人脸多属性分类单元,用于通过对多个人脸属性任务进行联合训练,用一个深度网络同时完成多个人脸属性目标分类任务,包括进行人脸检测、人脸关键点信息提取以及人脸多属性分析预测;
人脸关键点优化单元,用于提取原始人像上标记特征点及坐标信息,采用凸优化方法进行人脸关键点优化和人脸精准对齐;
人脸纹理细化单元,对初步获取的通用三维人脸模型进行纹理细化;
打印输出单元,用于输出显示并打印建模结果。
本发明的有益效果是:具有精确度高、实现方式简单、用户友好性好、自动化程度高等优点,能够更直观、完整地获得人脸的正面纹理信息、深度信息等,从而有利于建立起更加细腻逼真、快速精确且极具个性化的三维人脸模型。本发明提供的三维人脸建模打印装置,能极大地降低传统激光扫描进行三维人脸建模的成本和制作时间。
附图说明
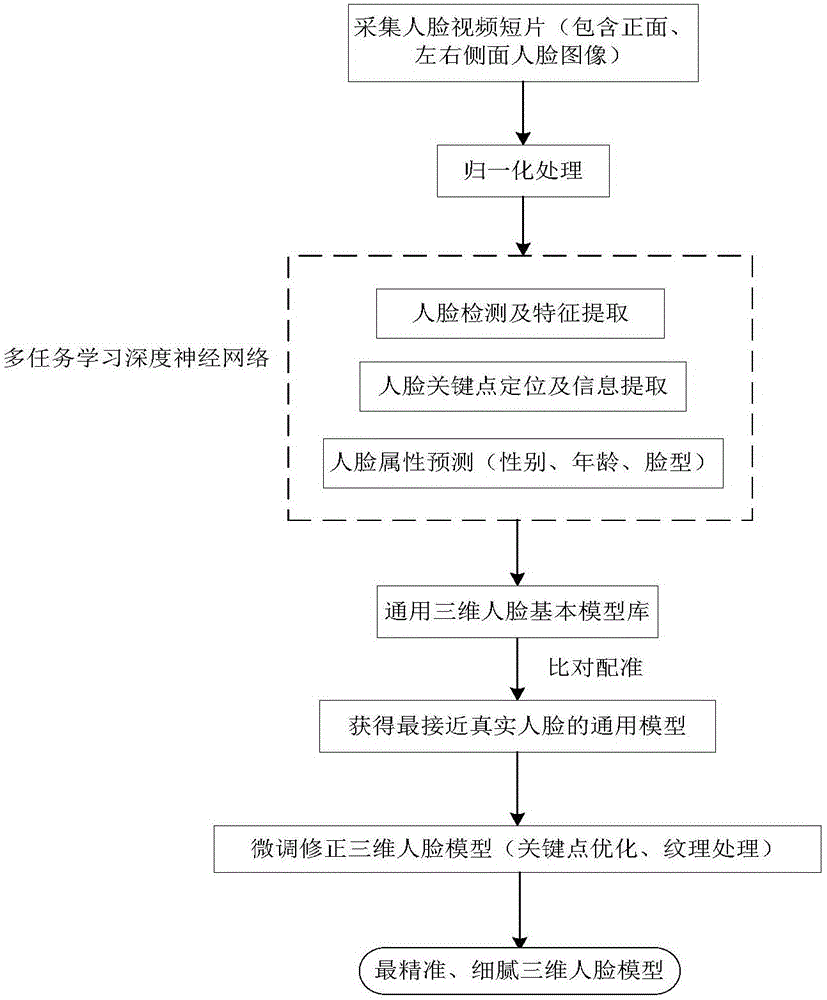
图1是本发明的一种基于视频流与人脸多属性匹配的三维人脸建模方法的流程图;
图2是本发明所述的多人脸属性任务学习深度神经网络示意图;
图3是本发明所述的三维人脸建模打印装置的结构示意图。
具体实施方式
以下结合附图和实例对本发明做进一步说明。
如图1所示,本发明提供了一种基于视频流与人脸多属性匹配的三维人脸建模方法,该方法过程详述如下。
步骤S1:利用三维扫描仪人工采集原始三维人脸模型数据,并人工标注其对应的属性(性别、年龄、脸型),同时根据属性对应的类别建立通用三维人脸模型库。
在一实施例中,步骤1具体包括:
S11,采用三维扫描仪采集真实的三维人脸模型后进行规一化处理。
S12,对规一化人脸模型的形状和纹理分别进行主成分分析(PCA),获得人脸形变模型,目的在于增加模型样本,丰富三维人脸模型数据库,构建完备的通用三维人脸模型库,构建三维人脸形变模型的具体方法包括:
设S和T分别为新的三维人脸模型的形状和纹理,S0为人脸形变模型的平均形状,T0为人脸形变模型的平均纹理,Sk(1≤k≤M)为人脸形变模型的第k个形状分量,Tk(1≤k≤M)为人脸形变模型的第k个纹理分量,αk为重建人脸模型的第k个形状参数,βk为重建人脸模型的第k个纹理参数,M为人脸形变模型的个数,k为1到M之间的整数。即根据主成分分析方法经验均值理论得:
得到形变三维人脸模型后,最终由三维扫描仪采集到的原始三维人脸模型和经过形变的三维人脸模型组成完备的三维人脸模型库。
S13,最后对完备三维人脸模型人工标注其对应的属性(性别、年龄、脸型),并将通用人脸模型库以人脸多属性进行分类,具体过程如下:
S131,以性别分为男、女两项;
S132,以年龄段为分类项,在男、女两项下又分为儿童、少年、青年、中年、老年9个阶段,其中儿童时期为0-3、4-6岁,少年时期为7-12、13-17岁,青年时期为18-25、26-40岁,中年时期为41-50、51-65岁,老年时期为66岁以上;
S133,以脸型为分类项,将每个年龄段分为7种脸型,分别是椭圆脸型、长脸型、四方脸型、倒三角型、菱形脸型、三角脸型、圆脸型,共有7个脸型项目。
在每种三维人脸模型的采集过程中,所述性别分为男女共126(男63、女63)种三维人脸模型。每种三维人脸模型采集10个人脸数据,整个三维人脸模型库共需采集1260个人脸数据。
将每种三维人脸模型的10个人脸数据进行平均化处理,利用加权平均技术得到恰当的合成的平均脸,即是从1260个人脸数据中获取126个平均脸的三维人脸模型,再利用主成分分析法得到形变人脸模型。最终由三维扫描仪采集到的原始三维人脸模型和经过形变处理的三维人脸模型构成完备的三维人脸模型库。
需要说明的是,本发明的重点并不在于建立通用三维人脸模型库,本步骤属于人工离线完成,故该通用三维人脸模型库属离线包,可以下载存储在本地硬盘中,无需重复建立模型库,日后的使用都无需再次建库。
步骤S2:采集实时视频中的多幅正侧面人脸图像进行归一化处理,通过预先训练好的多任务学习深度神经网络快速进行人脸检测、人脸关键点定位和信息提取,并结合多个关键点数据对齐人脸。
为采集实时视频中的多幅正侧面人脸图像,本实施例中采用多台摄像头,在红外灯照射下从目标人脸的正面及左右面分别进行拍摄,当用户进入图像采集区域时,多台摄像机从多方向不受环境因素影响对图像采集区域内的用户进行拍摄,有效地保证所采集图像的完备性,同时也保证了图像的质量和人脸的正面纹理信息及深度信息等。
本步骤S2中所述“预先训练好的多任务学习深度神经网络”通过对多个属性任务进行联合训练,仅用一个深度网络同时完成多个目标任务,包括进行人脸检测、人脸关键点信息提取以及人脸属性分析预测,所述人脸属性包括但不限于性别、年龄、脸型。
本步骤所述的人脸检测算法,采用任何一种现有的AdaBoost分类器或深度学习算法实现人脸及人脸关键点的检测即可。
本步骤所述的的人脸关键点包括:脸部轮廓、眼角点、眉间点、鼻下点、颌下点、嘴角点等。
本实例中进行人脸检测之后,根据关键点检测技术,进行人脸特征点定位,精确对齐人脸。
步骤S3:经过预先训练好的多任务学习深度神经网络进行人脸属性分析预测,同时结合多个人脸关键点数据和人脸属性信息与所述的通用三维人脸模型库进行粗配准,获得最接近实时采集对象的通用三维人脸模型;需说明的是,所述人脸属性包括但不限于性别、年龄、脸型,
所述“预先训练好的多任务学习深度神经网络”的训练过程包括:
采集人脸图像并标注其对应的多个属性的类别,形成一个完备的训练数据集合;
进行检测人脸、人脸关键点定位及信息提取,同时结合多个关键点坐标信息对齐人脸;
对标注类别中的属性进行编码;
构造深度神经网络;
利用步骤A1形成的训练数据集合,训练步骤A4中的深度神经网络,最终通过大量训练获得多任务学习深度神经网络模型。
图2是本发明所述的多人脸属性任务学习深度神经网络示意图。下面对深度神经网络作详细的说明。
所述深度神经网络包括:输入层,卷积层,非线性层,池化层,二次卷积层,混合卷积层,多属性分类层、输出层。
所述输入层用于自动获取实时视频流中的原始人脸图像,同时对人脸图像进行预处理操作,输出归一化的标准人脸图像,输入层将经过预处理的人脸图像输出至卷积层。
所述卷积层其输入是经过预处理的人脸图片或者图片的图像特征,通过一线性变换输出得到新特征。其输出的新特征为非线性层的输入、下一个卷积层、池化层或者二次卷积层的输入。本实施例中,卷积层A输出的降维新特征为非线性层B的输入和二次卷积层H的输入,卷积层C输出的降维新特征为非线性层D的输入,卷积层E输出的降维新特征为二次卷积层I的输入同时作为卷积层F的输入,卷积层F输出的新特征为卷积层E的输入,卷积层E输出的新特征为卷积层G的输入,卷积层G的输出的降维新特征作为池化层J的输入。
所述非线性层,其通过神经元激活函数,对卷积层输入的特征进行非线性变换,使得其输出的特征有较强的表达能力。非线性层的输出特征为下一个卷积层的输入。本实施例中,非线性层B输出的降维新特征为下一卷积层C的输入。
所述池化层可以将多个数值映射到一个数值。该层不但可以进一步加强学习所得到的特征的非线性,而且可以使得输出的特征的维数变小,确保提取的特征保持不变。池化层的输出特征可以再次作为为卷积层的输入或者混合卷积层的输入。本实施例中,经过卷积层F、G后,卷积层G的输出的降维新特征作为池化层J的输入。
所述混合卷积层,它对二次卷积层以及池化层的输出作一个线性变换,把学习得到的特征投影到一个更好的子空间以利于属性预测。本实施例中,二次卷积层H、I以及池化层J的输出作为混合卷积层L的输入。混合卷积层的输出特征作为多属性分类层的输入。
所述多属性分类层用于对输入目标任务进行计算分析预测,将分类结果至输出层。本实施例中,混合卷积层L的输出特征作为多属性分类层M的输入。
所述输出层用于输出建模结果。
所述卷积层、非线性层、池化层、二次卷积层分别设置有一个或者一个以上,卷积层、非线性层、池化层三层的多次组合,可以更好的处理输入的图像,使其特征具有最佳的表达能力。
步骤S4:采用关键点优化技术和纹理细化技术对粗配准的通用三维人脸模型进行微调修正,合成具有真实感的实时三维人脸视觉外观。
本步骤S4中,所述的关键点优化技术主要采用凸优化方法,具体方法包括:
首先构造所述人脸关键点信息组合向量A={xc1,xc2,xc3…xcn},其中xci(i=1,2,3…n)表示所述的关键点信息的第i种信息子向量。
然后通过凸优化目标函数得到最优解使得所对齐的人脸关键点参数误差最小。
其中,优化目标函数的约束条件为:θi≥0,∑θi=1;
表示所对齐的关键点和目标关键点之间的偏差,x为所述的关键点信息任意一种信息子向量,minθ表示关于求θ极小值,符号“||||”表示关于求范数。
最后根据最优解对粗配准的通用三维人脸模型进行人脸关键点精确对齐。
本步骤S4中,所述的纹理细化技术,具体包括:
首先计算人脸纹理的有效区域,在纹理图像上,如果一个像素所对应的顶点在图像上的投影坐标位于人脸轮廓之内,并且该顶点在投影角度下是可见的,则相应的像素就位于人脸纹理的有效区域内;
计算每个像素处的位置确定度p,将位置确定度作为代价函数中该像素处的权重,位置确定度定义为投影方向与顶点的法向量之间夹角的余弦;
为重建的三维人脸模型加入两个光照,分别位于三维人脸模型的左前方和右前方各45度,光照的位置固定且强度可变;
以形状无关纹理SIFT为拟合的目标图像,以人脸形变模型的纹理分量合成人脸纹理S1;将代价函数Eξ设置为合成的纹理图像与目标图像之间的偏差,代价函数在纹理的有效区域内进行计算;
通过目标函数Eξ>0利用梯度下降法将求得代价函数最小值,然后得到合成的纹理图像S;
选取一个纹理融合的优化系数I,将合成的人脸纹理图像S与形状无关纹理SIFT进行融合,取出形状无关纹理的中心区域补充到合成的纹理图像上,以补充人脸的细节,得到最终融合后的纹理R,其中R=I·SIFT+(1-I)·S。
通过关键点凸优化技术及纹理细化技术后,使得最终合成的三维人脸视觉外观更具真实感和个性化。
如图3所示,本发明还提供了一种基于视频流与人脸多属性匹配的三维人脸建模打印装置,包括:
输入单元,用于获取实时视频流中的原始人脸图像,同时对人脸图像进行预处理操作,输出归一化的标准人脸图像;
特征点标记单元,用于在所述原始人像上标记特征点并记录其坐标信息;
通用三维人脸模型库单元,所述通用三维人脸模型库单元属于离线包,可以下载存储在本地硬盘中,无需重复建立模型库,以后的使用都无需再次建库;
人脸多属性分类单元,用于通过对多个人脸属性任务进行联合训练,用一个深度网络同时完成多个人脸属性目标分类任务,包括进行人脸检测、人脸关键点信息提取以及人脸多属性分析预测;
人脸关键点优化单元,用于提取原始人像上标记特征点及坐标信息,采用凸优化方法进行人脸关键点优化和人脸精准对齐;
人脸纹理细化单元,对初步获取的通用三维人脸模型进行纹理细化,使最终的建模结果更真实可靠、细腻其个性化;
打印输出单元,用于输出显示并打印建模结果。
本发明实施方法中的步骤可以根据实际需要进行顺序调整、合并和删减。
以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,都应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!