翻译辅助方法、翻译辅助装置、翻译装置以及翻译辅助程序与流程
本发明涉及对使用短语表的机器翻译进行辅助的技术。
背景技术:
作为机器翻译的一种,存在统计机器翻译。例如,专利文献1公开了以包括通过预先构建的短语表对输入文中的句子进行模糊匹配的步骤作为特征的基于短语的统计机器翻译方法。
现有技术文献
专利文献1:日本特开2010-61645号公报
技术实现要素:
发明要解决的技术问题
然而,对于上述专利文献1的技术,希望对翻译精度有进一步的改善。
用于解决问题的技术方案
为了解决上述问题,本发明的一个技术方案涉及的翻译辅助方法是对机器翻译进行辅助的方法,所述机器翻译使用短语表将第1语言的原文翻译成第2语言的翻译文,所述短语表保存有作为所述第1语言的短语与所述第2语言的短语的对的短语对,所述翻译辅助方法包括如下的存储步骤:存储组合信息,所述组合信息是针对成为所述翻译文的候选的多个翻译候选文的各翻译候选文,确定所述短语表所保存的所述短语对中为了生成所述翻译候选文而使用的所述短语对的组合的信息。
发明的效果
根据上述技术方案,能够实现进一步的改善。
附图说明
图1是说明适用于本发明涉及的一个方式的统计机器翻译系统的框图。
图2是说明短语表的具体例子的说明图。
图3是说明原文和三个翻译候选文的说明图。
图4是本实施方式涉及的翻译系统的功能框图。
图5是说明本实施方式涉及的翻译系统的工作的流程图。
图6是说明被分解成词素的原文的一例的说明图。
图7是说明由机器翻译部生成的数据构造的一例的说明图。
图8是说明翻译结果信息的一例的说明图。
图9是说明五个翻译候选文各自的词素分析的结果的说明图。
图10是说明词素的评价结果的说明图。
图11是说明由评价部搜索出的短语对的组合的说明图。
图12是说明短语对的评价结果的说明图。
标号的说明
1:统计机器翻译系统;2:对译语料库;3:单语言语料库;4:翻译模型;5:语言模型;6:译码器;7:短语表;10:翻译系统;11:用户终端;12:服务器(翻译辅助装置的一例);13:原文输入部;14:机器翻译部;15:翻译候选文输出部;16:选择部;17:翻译模型;18:翻译信息存储部;19:评价部;20:评分调整部;21:语言处理部;22:再次翻译部;23:翻译结果比较部;24:评分再调整决定部;25:权重设定部;30:数据构造;31:路径;40:翻译结果信息;50、50a~50h:词素。
具体实施方式
以下说明的实施方式表示本发明的一个具体例子。以下的实施方式中表示的数值、构成要素、步骤、步骤的顺序等为一例,并非旨在限定本发明。另外,对于以下的实施方式中的构成要素中的没有记载在表示最上位概念的独立权利要求中的构成要素,将作为任意的构成要素进行说明。
(得到本发明的见解)
图1是说明适用于本发明涉及的一个方式的统计机器翻译系统1的框图。统计机器翻译系统1具备对译语料库2、单语言语料库3、翻译模型4、语言模型5以及译码器6。对译语料库2按领域、按语言对而分别准备。领域例如是旅行领域、医疗领域。语言对例如是日语与英语的对、日语与中文的对。
统计机器翻译系统1事先学习对译语料库2来生成翻译模型4,并且学习单语言语料库3来生成语言模型5。译码器6针对输入文(原文),从翻译模型4与语言模型5的组合中搜索概率成为最大的翻译候选文,将其作为输出文(翻译文)。通过使用了维特比(viterbi)和/或集束(beam)搜索的最大似然估计,搜索翻译候选文。
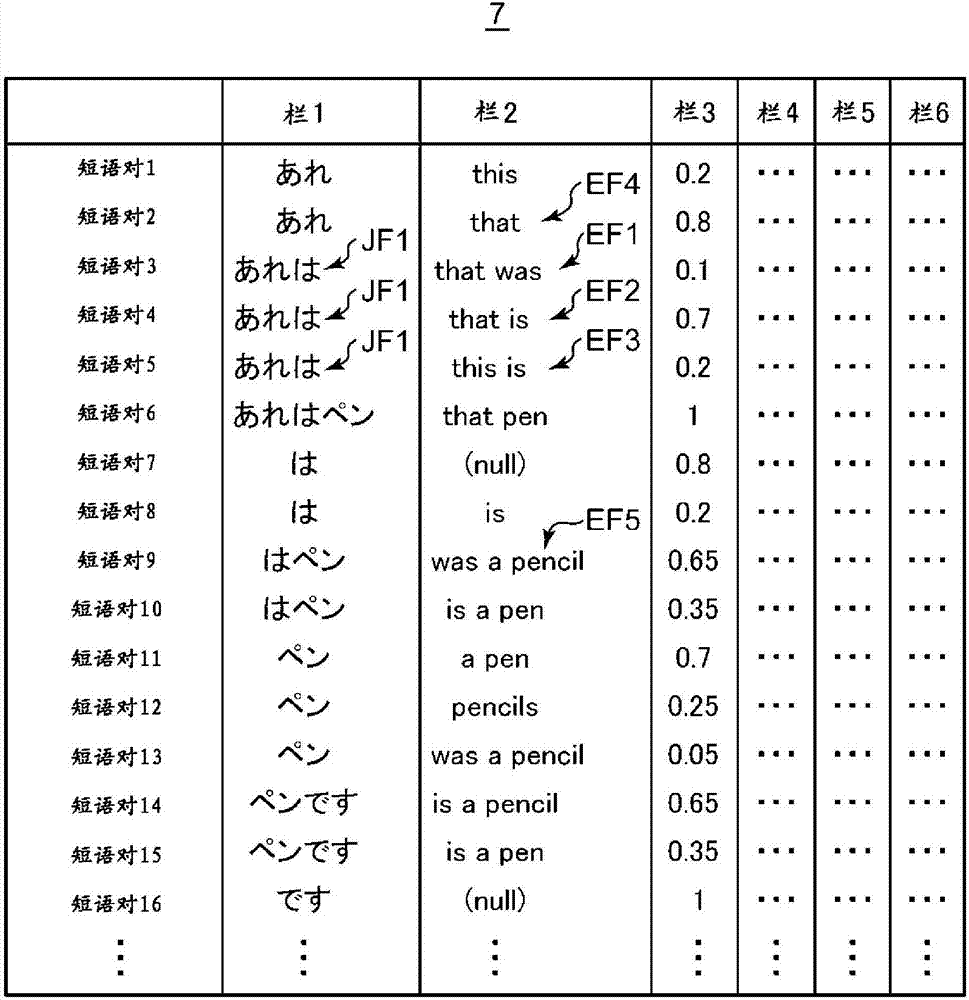
翻译模型4通过短语表来管理。在短语表中,保存有短语对,并且与各短语对关联地保存有各短语对的评分。短语对是第1语言的短语与第2语言的短语的对。评分是与短语对的出现概率有关的信息。设为第1语言是日语、第2语言是英语来说明该情况下的短语表的具体例子。图2是对其进行说明的说明图。在短语表7中,在栏1中示出日语短语,在栏2中示出英语短语,在栏3中示出短语的英日翻译概率,在栏4中示出单词的英日翻译概率之积,在栏5中示出短语的日英翻译概率,在栏6中示出单词的日英翻译概率之积。栏3~栏6中示出的值分别被称为评分。位于同一行的日语短语和英语短语是短语对。在图2中,示出了短语对1~16。
因为使用评分中的短语的英日翻译概率(栏3)对实施方式进行说明,所以短语的英日翻译概率(栏3)示出了值,而单词的英日翻译概率之积(栏4)、短语的日英翻译概率(栏5)、单词的日英翻译概率之积(栏6)省略了值。
具体进行说明,对于短语的英日翻译概率(栏3),例如日语短语jf1(意味着“あれは”的日语)被翻译成英语短语ef1的概率是0.1,被翻译成英语短语ef2的概率是0.7,被翻译成英语短语ef3的概率成为0.2。将这些概率相加得到的值成为1。
考虑如下的方案:统计机器翻译系统1向用户提示在对原文进行翻译时所生成的多个翻译候选文,使用户从多个翻译候选文中选择最佳的翻译候选文,基于该最佳的翻译候选文进行学习。具体进行说明,图3是说明原文os和三个翻译候选文ts1、ts2、ts3之间的关系的说明图。作为对原文os(意味着“あれは、ペンです”的日语)的翻译候选文,设为生成了翻译候选文ts1、ts2、ts3。
在用户选择了翻译候选文ts2时,统计机器翻译系统1在翻译候选文ts1中,将句节(日语“文節”)c1学习为差句节,将句节c2学习为好句节,在翻译候选文ts3中,将句节c3学习为差句节,将句节c4学习为好句节,将句节c5学习为差句节。
如果将上述学习的结果反映于短语表7的评分,则统计机器翻译系统1的翻译精度会提高。
但是,在统计机器翻译系统1对原文进行了翻译的情况下,会产生多个构成翻译候选文(例如,翻译候选文ts1)的短语对的组合。例如存在短语对1、8、11、16的组合和短语对1、7、15的组合。因此,仅根据翻译候选文,并不知道通过哪个短语对的组合生成了该翻译候选文,因此无法将学习的结果反映于短语表7的评分。
因此,为了使得能够确定通过哪个短语对的组合生成了翻译候选文,研究了以下的改善措施。
翻译辅助方法的一个技术方案是对机器翻译进行辅助的方法,所述机器翻译使用短语表将第1语言的原文翻译成第2语言的翻译文,所述短语表保存有作为所述第1语言的短语与所述第2语言的短语的对的短语对,所述翻译辅助方法包括如下的存储步骤:存储组合信息,所述组合信息是针对成为所述翻译文的候选的多个翻译候选文的各翻译候选文,确定所述短语表所保存的所述短语对中为了生成所述翻译候选文而使用的所述短语对的组合的信息。
在翻译辅助方法的一个技术方案中,针对成为翻译文的候选的多个翻译候选文的各翻译候选文,存储组合信息,该组合信息是确定短语表所保存的短语对中为了生成翻译候选文而使用的短语对的组合的信息。由此,根据翻译辅助方法的一个技术方案,能够确定为了生成翻译候选文而使用的短语对的组合。
在上述构成中,在所述存储步骤中,将与为了生成多个所述翻译候选文的各翻译候选文而使用的所述短语对的组合有关的数据构造、以及在所述数据构造中能够获得为了生成多个所述翻译候选文的各翻译候选文而使用的所述短语对的组合的路径作为所述组合信息进行存储。
该构成是组合信息的一例。
在上述构成中,在所述短语表中,与所述短语表所保存的所述短语对分别关联地保存有作为与所述短语对的出现概率有关的信息的评分,所述翻译辅助方法还包括:选择步骤,使用户从多个所述翻译候选文中选择最佳的所述翻译候选文;确定步骤,使用通过所述存储步骤存储的所述组合信息来确定为了生成在所述选择步骤中未被选择的所述翻译候选文而使用的所述短语对的组合;以及评价步骤,针对构成通过所述确定步骤确定出的所述组合的各个所述短语对,进行用于调整所述评分的评价。
在该构成中,对为了生成在选择步骤中未被选择的翻译候选文而使用的各短语对进行用于调整评分的评价,来作为用于调整评分的前提。
在上述构成中,在所述评价步骤中,针对构成通过所述确定步骤确定出的所述组合的各个所述短语对,通过与所述选择步骤选择出的所述翻译候选文所包含的要素进行比较,由此使用预定的基准,对应该提高所述评分的所述短语对进行应该提高所述评分的评价,对应该降低所述评分的所述短语对进行应该降低所述评分的评价。
该构成是评价步骤的一个方式。在翻译候选文例如通过词素分析进行了分解时,词素成为要素。另外,在翻译候选文例如通过句法分析进行了分解时,主语、谓语、补语、宾语等成为要素。作为进行应该提高评分的评价的情况下的基准以及进行应该降低评分的评价的情况下的基准,可考虑各种基准。考虑这些基准对本领域技术人员来说是容易的,因此设为预定的基准。在实施方式中,作为预定的基准,例示了后面说明的(1)~(7)的基准。
在上述构成中,还包括如下的评分调整步骤:进行第1处理和第2处理中的至少一方的处理,所述第1处理是将与被作出应该提高所述评分的评价的所述短语对关联的所述评分进行提高的处理,所述第2处理是将与被作出应该降低所述评分的评价的所述短语对关联的所述评分进行降低的处理。
根据该构成,基于评价步骤中的评价,对为了生成在选择步骤中未被选择的翻译候选文而使用的短语对的评分进行调整,因此能够使机器翻译的翻译精度提高。设为进行使评分提高的第1处理和使评分降低的第2处理中的至少一方的处理,是因为:无论进行两方的处理还是进行单方的处理,机器翻译的精度都会提高。
在上述构成中,还包括如下的第1设定步骤:在所述评分调整步骤进行所述第1处理的情况下,根据被进行所述第1处理的所述短语对的所述评分和所述第1语言与被进行所述第1处理的所述短语对的所述第1语言相同的其他短语对的所述评分之间的偏差,设定在所述第1处理中使用的第1预定值,在所述评分调整步骤中,使用通过所述第1设定步骤设定的所述第1预定值来进行所述第1处理。
根据该构成,能够根据被进行第1处理的短语对的评分和第1语言与该短语对的第1语言相同的其他短语对的评分之间的偏差,改变在第1处理中使用的第1预定值。因此,与在第1处理中使用的第1预定值是固定值的技术方案相比,能够使翻译精度提高。
对第1预定值的设定进行详细说明。在第1设定步骤中,在被进行第1处理的短语对的评分和第1语言与该短语对的第1语言相同的其他短语对的评分之间的偏差比较大时,设定第1预定值以使得被进行第1处理的短语对的评分变化较大,在该偏差比较小时,设定第1预定值以使得被进行第1处理的短语对的评分变化较小。也可以反过来。即,在第1设定步骤中,在被进行第1处理的短语对的评分和第1语言与该短语对的第1语言相同的其他短语对的评分之间的偏差比较大时,设定第1预定值以使得被进行第1处理的短语对的评分变化较小,在该偏差比较小时,设定第1预定值以使得被进行第1处理的短语对的评分变化较大。
在上述构成中,还包括如下的第2设定步骤:在所述评分调整步骤进行所述第2处理的情况下,根据被进行所述第2处理的所述短语对的所述评分和所述第1语言与被进行所述第2处理的所述短语对的所述第1语言相同的其他短语对的所述评分之间的偏差,设定在所述第2处理中使用的第2预定值,在所述评分调整步骤中,使用通过所述第2设定步骤设定的所述第2预定值来进行所述第2处理。
根据该构成,能够根据被进行第2处理的短语对的评分和第1语言与该短语对的第1语言相同的其他短语对的评分之间的偏差,改变在第2处理中使用的第2预定值。因此,与在第2处理中使用的第2预定值是固定值的技术方案相比,能够使翻译精度提高。
对第2预定值的设定进行详细说明。在第2设定步骤中,在被进行第2处理的短语对的评分和第1语言与该短语对的第1语言相同的其他短语对的评分之间的偏差比较大时,设定第2预定值以使得被进行第2处理的短语对的评分变化较大,在该偏差比较小时,设定第2预定值以使得被进行第2处理的短语对的评分变化比较小。也可以反过来。即,在第2设定步骤中,在被进行第2处理的短语对的评分和第1语言与该短语对的第1语言相同的其他短语对的评分之间的偏差比较大时,设定第2预定值以使得被进行第2处理的短语对的评分变化较小,在该偏差比较小时,设定第2预定值以使得被进行第2处理的短语对的评分变化较大。
在上述构成中,在所述存储步骤中,针对多个所述翻译候选文的各翻译候选文,存储与基于所述评分而算出的翻译结果有关的数值信息,所述翻译辅助方法还包括:再次翻译步骤,使用所述评分调整步骤后的所述短语表对所述原文进行再次翻译,由此再次生成成为所述翻译文的候选的多个所述翻译候选文,针对再次生成的多个所述翻译候选文的各翻译候选文,生成基于所述评分调整步骤后的所述短语表的所述评分而算出的所述数值信息;比较步骤,对通过所述存储步骤存储的所述数值信息和通过所述再次翻译步骤生成的所述数值信息进行比较,判定是否满足预先确定的基准;以及再次执行步骤,在判定为满足所述预先确定的基准时,再次执行所述评分调整步骤。
与翻译结果有关的数值信息例如是n-best排序。满足预先确定的基准的情况例如是对通过存储步骤存储的n-best排序和通过再次翻译步骤生成的n-best排序进行比较而排序没有变化的情况。根据该构成,对通过存储步骤存储的数值信息和通过再次翻译步骤生成的数值信息进行比较,在判定为满足预先确定的基准时,再次执行评分调整步骤。因此,能够使翻译精度提高。
翻译辅助装置的一个技术方案是是对机器翻译进行辅助的装置,所述机器翻译使用短语表将第1语言的原文翻译成第2语言的翻译文,所述短语表保存有作为所述第1语言的短语与所述第2语言的短语的对的短语对,所述翻译辅助装置具备存储部,所述存储部存储组合信息,所述组合信息是针对成为所述翻译文的候选的多个翻译候选文的各翻译候选文,确定所述短语表所保存的所述短语对中为了生成所述翻译候选文而使用的所述短语对的组合的信息。
翻译辅助装置的一个技术方案具有与翻译辅助方法的一个技术方案同样的作用效果。
翻译装置的一个技术方案具备:短语表,其保存有作为第1语言的短语与第2语言的短语的对的短语对;机器翻译部,其使用所述短语表,为了从所述第1语言的原文生成所述第2语言的翻译文,生成成为所述翻译文的候选的多个翻译候选文;以及存储部,其存储组合信息,所述组合信息是针对所述机器翻译部生成的多个翻译候选文的各翻译候选文,确定所述短语表所保存的所述短语对中为了生成所述翻译候选文而使用的所述短语对的组合的信息。
翻译装置的一个技术方案具有与翻译辅助方法的一个技术方案同样的作用效果。
翻译辅助程序的一个技术方案是对机器翻译进行辅助的程序,所述机器翻译使用短语表将第1语言的原文翻译成第2语言的翻译文,所述短语表保存有作为所述第1语言的短语与所述第2语言的短语的对的短语对,所述翻译辅助程序使计算机执行如下的存储步骤:存储组合信息,所述组合信息是针对成为所述翻译文的候选的多个翻译候选文的各翻译候选文,确定所述短语表所保存的所述短语对中为了生成所述翻译候选文而使用的所述短语对的组合的信息。
翻译辅助程序的一个技术方案具有与翻译辅助方法的一个技术方案同样的作用效果。
(实施方式)
以下,基于附图对本发明的实施方式进行详细说明。以第1语言是日语、第2语言是英语的组合进行说明,但第1语言与第2语言的组合并不限定于此。图4是本实施方式涉及的翻译系统10的功能框图。翻译系统10使用统计机器翻译进行翻译。翻译系统10由用户终端11和服务器12构成。翻译系统10具备原文输入部13、机器翻译部14、翻译候选文输出部15、选择部16、翻译模型17、翻译信息存储部18、评价部19、评分调整部20、语言处理部21、再次翻译部22、翻译结果比较部23、评分再调整决定部24以及权重设定部25来作为功能块。
原文输入部13、机器翻译部14、翻译候选文输出部15以及选择部16被设置于用户终端11。用户终端11例如是台式个人计算机、笔记本式个人计算机、智能手机、平板终端。
翻译模型17、翻译信息存储部18、评价部19、评分调整部20、语言处理部21、再次翻译部22、翻译结果比较部23、评分再调整决定部24以及权重设定部25被设置于服务器12。服务器12能够与用户终端11进行通信,是翻译辅助装置的一例。此外,也可以是这些功能块的一部分(例如,翻译模型17)被设置于用户终端11的技术方案。另外,也可以是构成翻译系统10的全部功能块被设置于用户终端11的技术方案。在后者的技术方案中,不需要服务器12,仅通过用户终端11就行,因此成为包含翻译辅助装置的翻译装置。
对设置于用户终端11的功能块进行说明。通过用户向原文输入部13输入原文。在以文字的方式输入原文的情况下,例如键盘、触摸面板成为原文输入部13。在以声音的方式输入原文的情况下,麦克风以及对从麦克风输入的声音进行识别的声音识别装置成为原文输入部13。
机器翻译部14针对输入到原文输入部13的第1语言的原文,生成成为第2语言的翻译文的候选的多个翻译候选文。多个翻译候选文通过图1中说明的统计机器翻译来生成。机器翻译部14是图1所示的译码器6,通过cpu(centralprocessingunit,中央处理单元)、ram(randomaccessmemory,随机存取存储器)以及rom(readonlymemory,只读存储器)等硬件和用于执行机器翻译的各种软件等来实现。
翻译候选文输出部15将由机器翻译部14生成的多个翻译候选文进行输出。在以文字的方式输出翻译候选文的情况下,显示器成为翻译候选文输出部15。在以声音的方式输出翻译候选文的情况下,扬声器成为翻译候选文输出部15。
用户使用选择部16,从自翻译候选文输出部15输出的多个翻译候选文中选择最佳的翻译候选文。例如,键盘、触摸面板成为选择部16。在以声音的方式选择最佳的翻译候选文的情况下,麦克风以及对从麦克风输入的声音进行识别的声音识别装置成为选择部16。
对设置于服务器12的功能块进行说明。这些功能块通过cpu、ram以及rom等硬件和用于执行机器翻译的各种软件等来实现。
翻译模型17对应于图1所示的翻译模型4,通过图2所示那样的短语表7来管理。机器翻译部14使用翻译模型17进行统计机器翻译。此外,在实际的统计机器翻译中,除了翻译模型17之外还需要图1所示的语言模型5,但在本实施方式中,为了简化翻译系统10的说明,省略了语言模型5。
翻译信息存储部18存储翻译信息。在翻译信息中包含翻译结果信息以及组合信息。翻译结果信息是被输入到原文输入部13的原文、机器翻译部14生成的多个翻译候选文等。组合信息是针对多个翻译候选文的各翻译候选文,确定在短语表7所保存的短语对中为了生成翻译候选文而使用的短语对的组合的信息。关于翻译结果信息以及组合信息,将在后面进行详细说明。
评分调整部20基于由选择部16选择出的翻译候选文(即,由用户判断出的最佳的翻译候选文),对管理翻译模型17的短语表7的评分进行调整。
关于其余的功能块,在下面说明的翻译系统10的工作中进行它们的说明。
主要参照图4以及图5来说明本实施方式涉及的翻译系统10的工作。图5是说明该工作的流程图。
用户向原文输入部13输入原文(步骤s1)。作为原文,以图3的原文os为例来说明。
机器翻译部14对输入到原文输入部13的原文进行统计机器翻译(步骤s2)。详细地进行说明,通过预定的方法对通过步骤s1输入到原文输入部13的原文进行分解。作为预定的方法,存在词素分析、句法分析等。在此,以词素分析为例来说明。
通过机器翻译部14对原文进行词素分析,原文被分解成图6所示的4个词素50。机器翻译部14使用这4个词素50以及管理翻译模型17的图2所示那样的短语表7,生成能够获得成为原文的翻译文的候选的全部翻译候选文的、图7所示的数据构造30。图7是说明由机器翻译部14生成的数据构造30的一例的说明图。
数据构造30具有树构造。节点是短语对。这里的短语对是在图2所示的短语表7所保存的短语对中为了生成翻译候选文而使用的短语对。对于短语对,分别示出了日语短语、英语短语、评分。评分是图2的栏3中示出的值。
在数据构造30中,作为为了生成翻译候选文而使用的短语对的组合,示出了组合1~10。例如,组合1是将短语对1、7、11、16按该顺序排列而得到的组合。组合1的翻译候选文成为图8所示的翻译候选文ts4。
机器翻译部14对由数据构造30示出的全部组合的各组合,计算累计概率,决定n-best排序。
机器翻译部14基于以上构成,生成翻译结果信息。图8是说明翻译结果信息40的一例的说明图。翻译结果信息40是对原文以及各个组合示出累计概率、n-best排序以及翻译候选文的信息。
累计概率是将为了生成翻译候选文而使用的各个短语对的评分(图2的栏3中示出的英日翻译概率)相乘而得到的值。例如,在组合1的情况下,参照图7以及图8,0.112(=0.2×0.8×0.7×1)成为累计概率。
n-best排序表示从具有最大的累计概率的组合到具有第n大的累计概率的组合为止的排序。在此,n-best排序的n以5来说明,但并不限定于此。机器翻译部14按累计概率从高到低的顺序,确定第1顺位到第5顺位的排序。在此,组合7是第1顺位,组合9是第2顺位,组合10是第3顺位,组合2是第4顺位,组合5是第5顺位。
在本实施方式中,将n-best排序以及累计概率作为与翻译结果有关的数值信息进行说明。此外,也可以仅将n-best排序作为与翻译结果有关的数值信息。
机器翻译部14使翻译信息存储于翻译信息存储部18(步骤s3)。翻译信息由组合信息和图8所示的翻译结果信息40构成。组合信息是指图7所示的数据构造30以及路径31。路径31是指在数据构造30中能够获得n-best排序的第1顺位~第n顺位(在此为第5顺位)的各个组合的路径(在此,为组合2的路径31、组合5的路径31、组合7的路径31、组合9的路径31、组合10的路径31)。在翻译结果信息40中包含与上述的翻译结果有关的数值信息(累计概率、n-best排序)。
翻译候选文输出部15针对n-best排序的第1顺位到第n顺位(在此为第5顺位)的各个组合,输出翻译候选文(步骤s4)。在此,图8所示的翻译候选文ts5、翻译候选文ts6、翻译候选文ts7、翻译候选文ts8、翻译候选文ts9被输出。在翻译候选文输出部15例如是用户终端11的显示器的情况下,在该显示器上显示这些翻译候选文。
用户使用选择部16,从通过步骤s4输出的五个翻译候选文中选择最佳的翻译候选文来作为通过步骤s1输入的原文的翻译文(步骤s5)。在此,设为选择了图8所示的由组合9构成的翻译候选文ts8。
语言处理部21对通过步骤s4输出的五个翻译候选文分别进行预定的分析,以多个要素对翻译候选文进行分解(步骤s6)。作为预定的分析,存在词素分析、句法分析等。在此,以词素分析为例来说明。在词素分析的情况下,要素成为词素。图9是说明五个翻译候选文各自的词素分析的结果的说明图。例如,由组合7构成的翻译候选文ts7被分解成词素50a、词素50b、词素50c、词素50d这4个词素(要素)。
评价部19对通过步骤s6分解后的词素分别进行评价(步骤s7)。详细地进行说明,评价部19针对在步骤s5中未被选择的翻译候选文的词素,将与通过步骤s5选择出的翻译候选文ts8的词素50e、词素50f、词素50g、词素50h相同的词素评价为好词素,将与通过步骤s5选择出的翻译候选文ts8的词素50e、词素50f、词素50g、词素50h不同的词素评价为差词素,将无法评价是好词素还是差词素的词素评价为中性词素。
图10是说明词素的评价结果的说明图。好词素由“○”表示,差词素由“×”表示,中性词素由“δ”表示。例如,由组合7构成的翻译候选文ts7的词素中的词素50a被评价为好词素,词素50b被评价为差词素,词素50c被评价为好词素,词素50d被评价为差词素。
评价部19针对在步骤s5中未被选择的翻译候选文,确定为了生成翻译候选文而使用的短语对的组合(步骤s8)。在该确定中,使用通过步骤s3存储的翻译信息所包含的组合信息。如上所述,组合信息是图7所示的数据构造30以及在数据构造30中能够获得n-best排序的第1顺位到第5顺位的各个组合的路径31。
评价部19使用能够获得组合7的路径31,对数据构造30进行搜索。由此,得到短语对2、9、16。评价部19使用能够获得组合10的路径31,对数据构造30进行搜索。由此,得到短语对4、14。评价部19使用能够获得组合2的路径31,对数据构造30进行搜索。由此,得到短语对2、7、11、16。评价部19使用能够获得组合5的路径31,对数据构造30进行搜索。由此,得到短语对2、7、14。
图11是说明由评价部19搜索出的短语对的组合的说明图。组合7是短语对2、9、16的组合。组合10是短语对4、14的组合。组合2是短语对2、7、11、16的组合。组合5是短语对2、7、14的组合。
评价部19针对图11所示的各个短语对,进行用于对评分(例如,短语对2的评分为0.8)进行调整的评价(步骤s9)。具体而言,如以下这样来评价短语对。评价部19针对图11所示的各个短语对(即,构成通过步骤s8确定出的组合的各个短语对),将其与通过步骤s5选择出的翻译候选文所包含的词素(要素)进行比较,由此对应该提高评分的短语对进行应该提高评分的评价,对应该降低评分的短语对进行应该降低评分的评价。
在本实施方式中,将被作出了应该提高评分的评价的短语对设为好短语对,将被作出了应该降低评分的评价的短语对设为差短语对,将无法作出任何评价的短语对设为中性短语对。评价为好短语、差短语、中性短语的基准例如如以下所述。
(1)在短语对的英语短语仅由好词素构成时,该短语对被评价为好短语对。
(2)在短语对的英语短语仅由差词素构成时,该短语对被评价为差短语对。
(3)在短语对没有英语短语时(例如,图11所示的短语对16),该短语对被评价为中性短语对。
(4)在短语对的英语短语由好词素和中性词素构成时,该短语对被评价为好短语对。此外,也可以评价为中性短语对。
(5)在短语对的英语短语由差词素和中性词素构成时,该短语对被评价为差短语对。此外,也可以评价为中性短语对。
(6)在短语对的英语短语由好词素和差词素构成时、或者在短语对的英语短语由好词素、差词素和中性词素构成时,该短语对被评价为差短语对。此外,也可以评价为好短语对。另外,在好词素的数量比差词素的数量多时,也可以评价为好短语对,在差词素的数量比好词素的数量多时,也可以评价为差短语对。
(7)在短语对的英语短语仅由中性词素构成时,该短语对被评价为中性短语对。
以组合7为例来具体说明。评价部19针对组合7,按照图10所示的词素的评价,对图11所示的短语对2、9、16分别进行评价。短语对2的英语短语ef4仅由好词素构成,因此被评价为好短语对。短语对9的英语短语ef5包含差词素50b、50d,因此被评价为差短语对。短语对16没有英语短语,因此被评价为中性短语对。
图12是说明短语对的评价结果的说明图。好短语对由“○”表示,差短语对由“×”表示,中性短语对由“δ”表示。
此外,也可以以与上述同样的方式对为了生成通过步骤s5选择出的翻译候选文而使用的短语对分别进行评价。该情况下,全部短语对都被评价为好短语对。
作为对好短语对、差短语对、中性短语对的评分进行的处理,例如存在以下的处理。
<1>评分调整部20对好短语对的评分乘以预定权重,使评分增大。此外,评分调整部20也可以对好短语对的评分加上预定值,使评分增大。
<2>评分调整部20对差短语对的评分乘以预定权重,使评分减小。此外,评分调整部20也可以从差短语对的评分减去预定值,使评分减小。
<3>评分调整部20维持中性短语对的评分。
<4>评分调整部20以与<1>同样的方式使中性短语对的评分增大。
<5>评分调整部20以与<2>同样的方式使中性短语对的评分减小。
<6>评分调整部20在通过<1>增大了好短语对的评分时,使包含与该短语对的日语短语相同的日语短语的短语对的评分减小,使将这些评分相加得到的值为1。具体进行说明,参照图2,评分调整部20例如在使短语对2的评分成为了0.9时,使短语对1的评分成为0.1。
<7>评分调整部20在通过<2>减小了差短语对的评分时,使包含与该短语对的日语短语相同的日语短语的短语对的评分增大,使将这些评分相加得到的值为1。具体进行说明,参照图2,评分调整部20例如在使短语对9的评分成为了0.55时,使短语对10的评分成为0.45。
评分调整部20单独或组合使用<1>~<7>,对图12所示的短语对分别调整评分(步骤s10)。这是一种翻译模型17的学习。评分调整部20例如可以使用<1>、<2>以及<3>来调整评分,也可以仅使用<1>来调整评分,也可以仅使用<2>来调整评分,也使用<1>以及<2>来调整评分,也可以使用<1>以及<4>来调整评分,也可以使用<2>以及<5>来调整评分。
以下,对使用了<1>、<2>以及<3>的评分调整进行详细说明。设为对好短语对的预定权重例如为1.2,对差短语对的预定权重例如为0.8。参照图12,评分调整部20首先对构成组合7的短语对2、9、16的评分进行调整。
因为短语对2为好短语对,所以评分调整部20在图2所示的短语表7中将短语对2的评分从0.8提高到0.96(=0.8×1.2)。因为短语对9为差短语对,所以评分调整部20在短语表7中将短语对9的评分从0.65降低到0.52(=0.65×0.8)。因为短语对16是中性短语对,所以评分调整部20在短语表7中将短语对16的评分维持为1。构成组合7的短语对2、9、16的评分调整后的累计概率成为0.4992(=0.96×0.52×1),变为比图8所示的当初的累计概率(0.520)小。
此外,在评分调整后的累计概率仍然比构成用户选择出的翻译候选文的短语对的累计概率大时,也可以再次进行步骤s10的处理。即,评分调整部20将构成组合7的短语对2、9、16的评分调整后的累计概率(0.4992)与构成通过步骤s5选择出的翻译候选文的短语对的评分的累计概率(即,图8所示的构成组合9的短语对的评分的累计概率0.490)进行比较,在前者比后者大时,再次对构成组合7的短语对2、9、16进行步骤s10的处理。
评分调整部20针对其余的组合(组合10、2、5),也以与组合7同样的方式对评分进行调整。
在步骤s10之后,再次翻译部22使用与步骤s2同样的方法,对通过步骤s3存储的翻译信息所包含的原文(即,通过步骤s1输入的原文)进行再次翻译(步骤s11)。在再次翻译中,使用评分调整后的短语表7。在该再次翻译中,再次翻译部22针对再次生成的多个翻译候选文,生成再次翻译结果信息(未图示)。因为使用评分调整后的短语表7进行再次翻译,所以再次翻译结果信息有可能会与图8所示的翻译结果信息40不同的是与翻译结果有关的数值信息(n-best排序、累计概率)。
此外,也可以是机器翻译部14进行步骤s11的处理。该情况下,在翻译系统10中不具备再次翻译部22。
翻译结果比较部23对图8所示的翻译结果信息40所包含的n-best排序与上述再次翻译结果信息所包含的n-best排序进行比较,判定n-best排序是否没有变化(步骤s12)。n-best排序没有变化的情况是满足预先确定的基准的情况的一例。作为其替代,也可以将图8所示的组合9的n-best排序(即,在步骤s5中由用户选择出的翻译候选文的n-best排序)在再次翻译结果信息所包含的n-best排序中不位于第1位的情况、或组合9的n-best排序在再次翻译结果信息所包含的n-best排序中虽然位于第1位但n-best排序为第1位的累计概率和第2位的累计概率之差为预定值以下(即,差很小)的情况设为满足预先确定的基准的情况。
翻译结果比较部23在判定为n-best排序没有变化时(步骤s12:是),评分再调整决定部24作出再次执行评分调整的决定(步骤s13),返回到步骤s10。
翻译结果比较部23在判定为n-best排序发生变化时(步骤s12:否),翻译系统10的工作结束。此外,在本实施方式中,执行了步骤s11~步骤s13,但也可以在步骤s10中结束翻译系统10的工作。
如以上进行的说明,根据本实施方式涉及的翻译系统10,针对机器翻译部14生成的多个翻译候选文的各翻译候选文,能够确定为了生成翻译候选文而使用的短语对。因此,能够基于用户从多个翻译候选文中选择出的翻译候选文,对为了生成其余的翻译候选文而使用的短语对的评分进行调整。
对在步骤s6中使用句法分析的情况进行简单说明。语言处理部21对通过步骤s4输出的五个翻译候选文分别进行句法分析,以多个要素对翻译候选文进行分解。在句法分析的情况下,例如,以树构造来表现句法的情况下的各节点(为了简单,例如设为主语s、谓语v、补语c、宾语o等)成为要素。例如,通过步骤s5选择出的翻译候选文ts8(组合9)被分解成“that=s”、“is=v”、“apen=c”。其他的翻译候选文、例如组合7被分解成“that=s”、“was=v”、“apencil=c”。
在步骤s7中,对通过句法分析而得到的要素进行评价。以组合7为例来说明,评价部19将“that=s”评价为好要素、将“was=v”评价为差要素,将“apencil=c”评价为差要素。
评价部19以与词素分析的情况同样的方式,对图11所示的短语对分别进行用于调整评分的评价(步骤s9)。以组合7为例来说明,评价部19将短语对2判定为好短语对,将短语对9评价为差短语对,将短语对16评价为中性短语对。
评分调整部20以与词素分析的情况同样的方式,对通过步骤s9进行了评价的短语对分别调整评分(步骤s10)。此时,评分调整部20对被评价为差短语对的短语对,使进行了比较的要素的种类不同的情况(例如,“apen=c”和“apencil=o”)下的评分与进行了比较的要素的种类相同的情况(例如,“apen=c”和“apencil=c”)下的评分相比更大地变化。由此,能够提高对句法构造错误的学习效果。
对本实施方式的变形例进行说明。在本实施方式中,将在评分的调整(步骤s10)中使用的预定权重设为了固定值,而在变形例中,使预定权重为可变值。权重设定部25在提高好短语对(例如,图2的短语对2)的评分的第1处理(上述<1>)被进行的情况下,根据好短语对的评分、和日语(第1语言)与该短语对的日语相同的其他短语对(图2的短语对1)的评分之间的偏差,设定在第1处理中使用的预定权重(第1预定值)。偏差例如是方差。并且,评分调整部20使用权重设定部25设定的预定权重,使好短语对的评分增大。
权重设定部25在上述偏差比较大时,设定预定权重以使得好短语对的评分变化较大,在上述偏差比较小时,设定预定权重以使得好短语对的评分变化较小。也可以反过来。即,权重设定部25在上述偏差比较大时,设定预定权重以使得好短语对的评分变化较小,在上述偏差比较小时,设定预定权重以使得好短语对的评分变化较大。
权重设定部25在降低差短语对(例如,图2的短语对9)的评分的第2处理(上述<2>)被进行的情况下,根据差短语对的评分和日语(第1语言)与该短语对的日语相同的其他短语对(图2的短语对10)的评分之间的偏差,设定在第2处理中使用的预定权重(第2预定值)。偏差例如是方差。并且,评分调整部20使用所设定的预定权重,使差短语对的评分减小。
权重设定部25在上述偏差比较大时,设定预定权重以使得差短语对的评分变化较大,在上述偏差比较小时,设定预定权重以使得差短语对的评分变化较小。也可以反过来。即,权重设定部25在上述偏差比较大时,设定预定权重以使得差短语对的评分变化较小,在上述偏差比较小时,设定预定权重以使得差短语对的评分变化较大。
产业上的可利用性
本发明例如可以利用于统计机器翻译。
- 还没有人留言评论。精彩留言会获得点赞!