用于在文档中识别中文物种名称的方法与系统与流程
本发明整体上涉及计算机信息处理技术领域,特别地,涉及一种用于在文档中识别中文物种名称的方法与系统。
技术背景:
目前,随着生物多样性领域的科学技术发展,涉及生物学领域的各类书籍、科技论文以及专利文献等日益增多。在这些文献的计算机深度处理中,生物物种中文名称识别技术显得非常重要。源于中文语义及构词的复杂性,生物物种中文名结构复杂,其书写格式多样或不规范等原因,目前还没有一种用于在文档中识别中文物种名称的技术或方法,在计算机处理生物类科技文献时,需要一种用于文档中识别生物物种名称的方法与系统。
技术实现要素:
:
本发明一方面提供一种用于在文档中识别中文物种名称的方法,步骤包括:接收包含中文物种名称的文档;识别所述文档中的中文物种名称字段;识别非物种名称字段;基于所识别的中文物种名称字段向两端扩展,扩展到非物种名称字段终止,合并物种名称字段以得到所述中文物种名称。
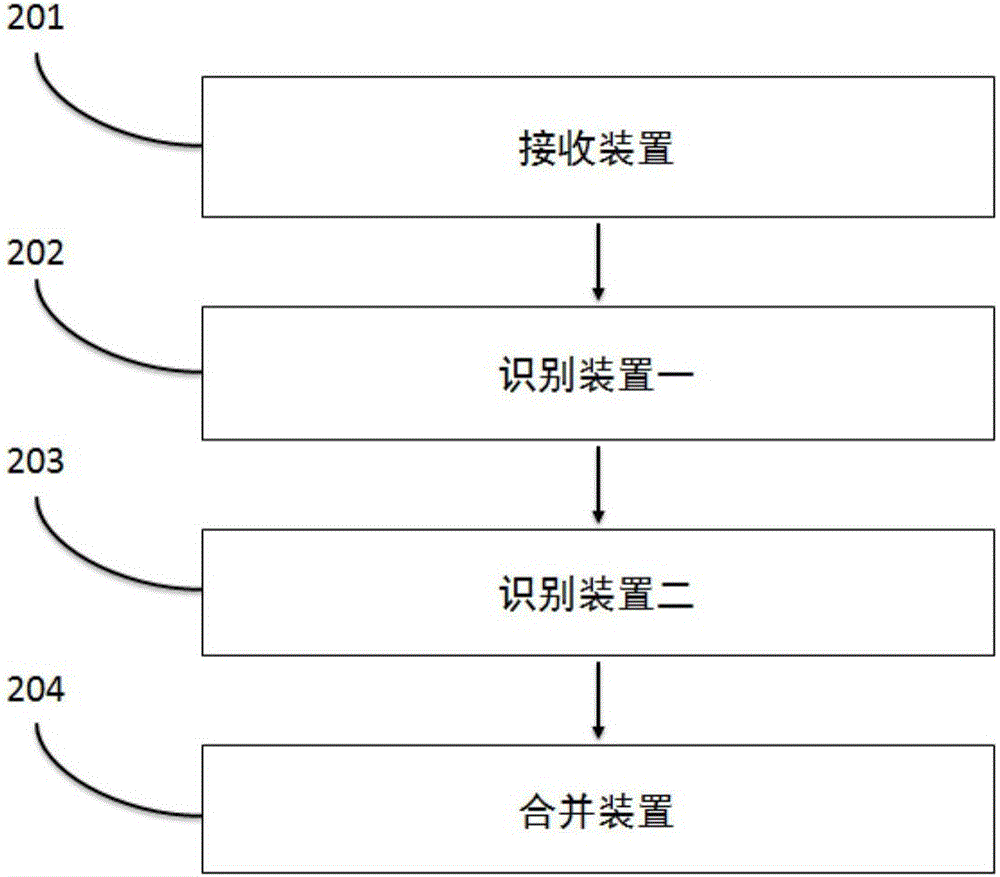
本发明另一方面提供一种用于在文档中识别中文物种名称的系统,如图2所示,装置包括:接收装置,用于接收包含中文物种名称的文档;识别装置一,用于识别所述文档中的中文物种名称片段;识别装置二,用于识别所述文档中的非物种名称片段;以及合并装置,用于基于所识别的中文物种名称片段向两端扩展以得到所述完整的中文物种名称。
本发明的具体实施方式可以有效地从科技文献中识别中文物种名称。
为了实现上述目的,本发明提供了如下的技术方案:
一种在文档中识别中文物种名称的方法,该方法包括:接收包含中文物种名称的文档,识别所述文档中的中文物种名称字段,识别所述文档中的非物种名称字段,基于所识别的中文物种名称字段和非物种名称字段,扩展、合并以得到所述完整中文物种名称步骤。
如所述的一种在文档中识别中文物种名称的方法,其中所述识别所述文档中的非物种名称字段步骤包括:对所述文档进行分词,检查每个分词是否在非中文物种名称字段字典中,响应于所述分词在非中文物种名称字段字典中,确定所述分词为非中文物种名称字段,记录所述非中文物种名称字段的位置信息。
如所述的一种在文档中识别中文物种名称的方法,其中所述识别文档中的中文物种名称字段步骤包括:对所述文档进行分句,基于中文物种名称字典匹配所述文档的分句中出现的所有中文物种名称,记录所述中文物种名称字段的位置信息。
如所述的一种在文档中识别中文生物物种名称的方法,所述位置信息由所述任一物种名称片段或非物种名称片段在所述文档中的起始位置和结束位置组成。
如所述的一种在文档中识别中文物种名称的方法,其中所述非物种名称字段在基于所识别的中文物种名称字段向两端扩展,以得到所述完整中文物种名称中作为终止符。
如所述的一种在文档中识别中文生物物种名称的方法,其中所述基于所识别的中文物种名称字段向两端扩展以得到所述完整中文物种名称步骤包括:从所述生物物种名称字段位置向前后两端扩展直至遇到非生物物种名称片段为止,以获得所述生物物种名称。
如所述的一种在文档中识别中文生物物种名称的方法,在识别所述文档中的中文物种名称字段步骤中,当同一分句中出现一个以上物种名称片段时,检查物种名称片段位置信息之间是否存在包含关系,响应于多个物种名称片段存在包含关系,保留最长的物种名称片段及位置信息。
如所述的一种在文档中识别中文物种名称的方法,该方法还包括以下步骤至少之一:
从已有的生物学领域中文物种名称生成中文物种名称片段字典,包括物种中文学名、俗名、栽培驯化后的品种名称;或者,基于非生物学领域的中文文档,例如数学、物理学、法学、社会学、心理学、管理学等;收集出现频率较高的词,形成非生物物种名称片段字典。
本发明还提供了所述的一种在文档中识别中文物种中文名称的方法与系统用于从科技文献中识别中文物种名称。
本发明的方法主要步骤包括接收包含中文物种名称的文档,识别所述文档中的中文物种名称字段,识别非物种名称字段,基于所识别的中文物种名称字段和非物种名称字段扩展、合并以得到所述完整的我中文物种名称。本发明的具体实施方式可以有效地从科技文献中识别中文物种名称。
附图说明
图1:本发明用于在文档中识别中文物种名称的具体实施方式示意图。
图2:本发明用于在文档中识别中文物种名称的系统构成示意图。
图3:本发明用于在文档中识别中文物种名称的计算机设备结构框架图。
具体实施方式:
为了对本发明实施例的特征和优点进行详细说明,将参照附图1、2、3,对本发明的实质性内容进行更进一步的描述,但并不以此来限定本发明。
实施例1:
本发明的一种在文档中识别中文生物物种中文名称的系统,如图2所示,该系统包括下述装置:
接收装置,用于接收包括生物物种名称的文档;
识别装置一,用于识别所述文档中的中文物种名称字段;
识别装置二,用于识别所述文档中的非物种名称片段;
合并装置,用于基于所识别的中文物种名称字段向两端扩展以得到所述完整中文物种名称。
以上所有装置的实施过程,各个步骤可以以任何顺序或者同时执行,除非从上下文能够清楚判断某个步骤的实施必须依赖于上一个步骤。此外,步骤之间可以有时间间隔。
图1示出了本发明用于在文档中识别中文物种拉丁学名的具体实施方式。
在步骤101中接收包括中文物种名称的文档。该文档可以是各种文件格式。比如可以是纯文本txt文件,也可以是word文件、pdf文件、XML文件、excel文件、扫描图片等。对于不是纯文本格式的文档,可以对该文档进行预处理以形成纯文本文件。
在步骤102中,识别所述文档中的中文物种名称字段,其中所述中文物种名称是指用于生物学领域中文物种命名的各种科学名称、俗称。如杜鹃、白花杜鹃、大白花杜鹃、杜鹃花叶山茶等。
识别文档中的中文物种名称字段、辅助词字段和种下等级加词字段可以通过与事先建立起来的中文物种名称字典、辅助词字典和种下等级加词字典进行精确和模糊匹配,当然本领域技术人员也可以基于本申请考虑到其它任何适合的识别方式。其中,可以从已有的生物学领域中文物种名录生成中文物种名称字典。
图3示意性的呈现了可以实现本发明的计算机系统结构框架图。图3中所示的计算机系统包括CPU(中央处理器)、RAM(随机存取存储器)、ROM(只读存储器)、系统总线,硬盘控制器、键盘控制器、串行接口控制器、并行接口控制器、显示器控制器、硬盘、键盘、串行外部设备、并行外部设备和显示器。在这些部件中,与系统总线相连的有CPU、RAM、ROM、硬盘控制器、键盘控制器,串行接口控制器,并行接口控制器和显示器控制器。硬盘与硬盘控制器相连,键盘与键盘控制器相连,串行外部设备与串行接口控制器相连,并行外部设备与并行接口控制器相连,以及显示器与显示器控制器相连。
本发明的流程图或者流程图中的每个框图步骤都可以由计算机程序实现。用于执行本发明的操作的计算机程序,可以以一种或多种程序设计语言的任何组合来编写,所述程序设计语言包括面向对象的程序设计语言—例如Java、C++之类,还包括常规的过程式程序设计语言—例如”C”语言、Fortran语言或类似的程序设计语言。计算机程序可以完全地或部分的在用户个人计算上执行、也可作为一个独立的软件包运行、也可在个人移动设备上执行。
图3中的流程图和流程图中的每个框图,揭示了按照本发明的系统、方法和计算机程序产品的可能实现的功能、体系架构和操作流程。在这点上,流程图或流程图中的每个框图可以代表一个模块、程序段、或源代码的一部分,所述模块、程序段、或源代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行程序。
- 还没有人留言评论。精彩留言会获得点赞!