一种基于元搜索引擎的标签自动生成方法与流程
本发明涉及标签获取的方法,特别是一种基于元搜索引擎的标签自动生成方法。
背景技术:
近年来,随着互联网行业的飞速发展以及搜索引擎日趋成熟,各式搜索引擎成为了人们获取信息的有利工具,随着用户的增多,互联网产生的信息量出现了爆炸式的增长,但这些信息资源往往夹杂着各种噪音,搜索引擎无法满足用户的个性化需求。为了更有效的利用这些信息资源,研究者们引入了“标签”技术,让用户能够更加精准的搜索到想要的结果,从海量信息中筛选出有效信息逐渐成为人们的研究热点,随着“标签”技术的成熟,自动标签技术也得到了广大学者的关注。
标签作为一种信息描述形式,近年来也的到了广泛的应用,一般是独立的单词,可以理解为是关键词或者主题词,它可以体现文本的关键信息,利用标签可以更好的发现、管理、传播和利用信息资源。目前越来越多的机构对标签进行了研究和利用,例如我们熟知的美味书签、百度百科、新浪微博等,用户对标签的正确应用,给日常工作带来便利,受到了各领域用户的一致好评。
目前标签获取的方法主要分为两类,一类是由用户捐献标签,这类标签需要较高的人工成本,但往往能够相对准确的反应出文本的关键信息;另一类则是利用数据挖掘和机器学习算法,从文本信息中自动提取能概括文本主题的词语,作为标签,这类方法无需人工干预,用户通过标签获取更加精准的信息。
标签的应用为用户带来很大的便利,如何提升标签的质量也成了人们研究的热点,也是一个难点。首先,互联网上的信息资源格式差异太大,有文本形式、有图片信息,还有视频以及其他形式,同一个资源一般也会包含多方面的信息;其次,对于同一个信息资源,不同标签代表的含义也各不相同,理想的情况是能够将关联度较高的词语作为标签。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术不足,提供一种基于元搜索引擎的标签自动生成方法。
为解决上述技术问题,本发明所采用的技术方案是:一种基于元搜索引擎的标签自动生成方法,包括以下步骤:
1)对文本标题和摘要进行分词处理,并记录词性;对词语进行过滤处理,得到一系列候选关键词;
2)按照候选关键词的先后顺序进行标号,遍历候选关键词,记录词语出现的频率、词语首次出现的位置、末次出现的位置以及词语总数sum,计算词语wi的位置因子L(wi)、词频因子T(wi)、跨度因子S(wi),从而计算出词语信息量m(wi);
3)根据词语信息量计算词语间的相关性;词语wi和词语wj的相关性有如下计算公式:
其中,r(wi,wj)表示词语wi和wj之间的差异性;
4)根据所述相关性计算词语wi的TextRank值:
其中,d指的是阻尼系数,其大小介于0和1之间;P(wi)表示词语wi的TextRank值或者重要性,In(wi)表示与词语wi相关的词语集合;P(wj)表示词语wj的TextRank值或者重要性,P(wi)、P(wj)的初始值均为1,上式等号右侧P(wj)为上一次迭代的值,等号左侧P(wi)为当次迭代的值;
5)对于从搜索引擎爬取的每一条结果的标题和摘要中的词语,利用步骤1)~步骤4)计算TextRank值,将词语按TextRank值进行排序,选取前五个词语作为候选标签;
6)将所有候选标签进行合并,选取得分最高的前N个词语作为标签。
本发明中,N=10。
m(wi)=α*L(wi)+β*T(wi)+γ*S(wi);其中α,β,γ为影响系数,α+β+γ=1。
词语wi的位置因子L(wi)的计算公式为:
其中,area(wi)表示词语wi在句子中出现的位置。
词语wi的词频因子T(wi)计算公式为:
其中,fre(wi)表示词语wi出现的频率。
词语wi的跨度因子S(wi)的计算公式为:
其中,las(wi)为词语wi末次出现的位置;fre(wi)表示词语wi出现的频率。
与现有技术相比,本发明所具有的有益效果为:本发明针对不同的搜索引擎有着独立的特性,在索引机制、排序算法、查找范围等多方面都存在较大的差异,独立搜索引擎的覆盖率相对较低,在查全率和查准率方都不够理想。本发明引入了元搜索引擎技术和自动生成标签,将自动标签技术应用到搜索引擎中,从而保证查全率和查准率。
附图说明
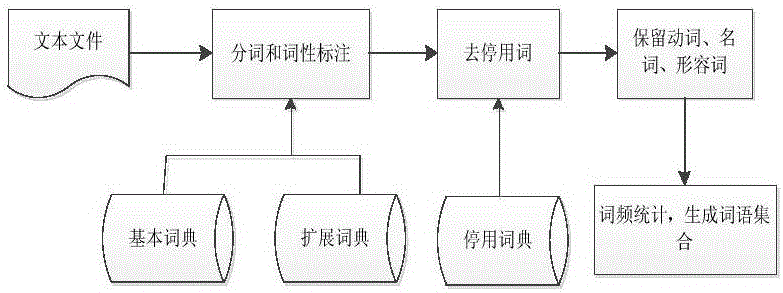
图1为文本预处理过程;
图2为词语的数据结构;
图3为改进后的TextRank算法流程图;
图4为标签提取流程图;
图5为元搜索引擎结构图。
具体实施方式
本发明基于已有的TextRank算法,提出了一种改进的TextRank算法生成标签。本方法一共由3个阶段组成,分别为文本预处理优化,信息量计算,标签提取。
算法改进思路:首先是文本预处理优化,在进行中文分词的同时保留词语的基本信息,包括词性、词位置、词频,构成五元组;其次是词语过滤,去掉停用词,进行词性过滤,根据经验保留名词、动词和动名词,降低噪音干扰;再次重新计算词语信息量,通过统计的词语基本信息,计算词语位置得分、词频、词跨度,并计算综合得分作为词语的权重;最后计算词语间的相似度作为TextRank算法中的边的权重,利用TextRank算法计算每个词的TextRank值。
1.文本预处理优化
文本预处理首先需要对文本进行分词处理,然后去掉噪声词、去掉停用词,保留名词、动词、动名词,分词的同时记录词的偏移量,图1为文本预处理过程,最终记录如下信息:
(1)词的位置信息;
(2)词频信息;
(3)词性;
(4)词的偏移量。
从图4可知,文本预处理主要分为以下四个步骤:
(1)对文本进行中文分词,并记录词语的词性、偏移量等基本信息,这个过程中,需要借助于词典,本发明采用的是HanLP分词工具,该工具自带比较完善的词典文件,包括基本词典、用户自定词典等;
(2)去停用词,去除标点符号、功能性用词、单字等无意义的词,借助于停用词表,减少无用词的干扰;
(3)保留名词、动词、形容词,经过研究发现,95%以上的关键词都属于这三种词性,因此本发明为了减少干扰,只保留了这三种词性的词语,去除了副词、连词、语气词等多种词性的词语,用这种方式来提高关键词的精度;
(4)词频统计,生成词语集合,计算每个词的词频,结合偏移量、词位置的信息,通过这些信息构成一个五元组(词语、词性、词位置、词频、偏移量)。
1.1分词和词性标注
中文分词是关键词提取的基础,本发明第二章也介绍了分词原理以及常用的分词算法,分词工具的好坏直接影响着关键词提取的效果。本发明采用的是HanLP分词系统分词速度在300kb/s左右,分词精度达到95%以上,拥有多种类型的词典,其词典种类如下表1所示:
表1:HanLP中词典详细信息
从表1可以看出,HanLP包含了非常完善的分词词库,对于一些专有名词也有很好的扩展,不足之处是该分词算法对于新词汇的识别能力有限,另外,HanLP在分词的同时能够进行自动标注词性,对于词性标注,它拥有一套自己的规则,将词性规范化,表2是HanLP的词性标注集:
表2HanLP词性标注集
表2列出了HanLP提供的部分词性标注集,可以看出对于所有词性都有明确的分类和定义,下表3-6展示了分词效果:
表3HanLP分词效果
表3展示了HanLP的分词效果,分词的同时对词性进行了标注。
1.2停用词处理
在完成分词工作之后,文章被切分成词语集合,在词语集合中包含有标点符号、单个汉字等多种无意义的词,这些词中有很多出现频率很高,如果不进行过滤处理,将会对后续结果产生很大的影响。
对于停用词的处理,一般会用到停用词典,词典中收录了部分停用词,用户可以根据实际需要自行扩展,本发明用到的停用词典有1457个停用词。
1.3词性过滤
本发明用到的分词工具在分词的同时能够自动进行词性标注,。经过研究者们的实践和分析,85%以上的关键词都是名词或包含名词的组合词,其次动词和形容词,这三种词性加起来涵盖了95%以上的关键词,所以本发明鉴于这个原因,将分词结果只保留名词、动词和形容词,过滤掉其他词性词语,尽可能的减少无用词的干扰。
2.信息量计算
经过文本预处理之后,每个词语被重新组装成一个五元组,用图3-4所示的数据结构表示,对于信息量的计算,本发明考虑了词频、词位置、词跨度等特征信息,一方面重新计算词语权重,另一方面利用相似度原理计算词语间的相似度,作为TextRank算法中的边,融入TextRank算法提取标签。
从图2可以看出,本发明用到的数据结构包含了词的基本信息,分别记录词语的首位置、末位置、词性、词频,为后面的计算提供了数据基础,下面将具体介绍计算方式。
定义:(1)Di为任意一条结果集,Di={W1,W2,…,Wn};
(2)Ti表示词频得分;
(3)Li为位置得分;
(4)Si为词跨度得分;
(5)Pi为词性特征值;
(6)Sim(d)为相似度得分。
1.词语位置得分
在本发明中,词的位置信息包括标题和摘要,一般如果一个词语出现在标题中,则会认为这个词比较重要,在赋予初始值得时候会有加分项,位置信息计算方法:
2.词频统计
本发明在对一篇文档进行预处理时,会把标题和内容分开去进行中文分词,所以在标题和内容中可能会出现相同的词,所以首先对单个文档进行词频统计,然后再对多个搜索结果进行词频统计:
其中,fre(wi)表示词语wi出现的频率。
3.词跨度计算
词跨度表示词语在文档中的距离,通过记录第一次出现的位置和最后一次出现的位置,由公式3计算得出,它反映出词在文章中的范围。
其中,fir(wi)表示词语wi出现的首位置,las(wi)表示词语出现的末位置。
4.词性因子
根据分析对不同的词性的词分别赋予不同的权值,本发明经过预处理之后只剩下名词、动词和形容词,对于不同的词性赋予不同的权重因子。
5.相似度得分
本发明在相关性算法BM25F算法的基础上加以改进,首先,因为标题和摘要的重要性不同,需要对标题和摘要赋予不同的权重值。
定义:w为检索关键词,z表示不同的域,即表示标题或者正文,Wz表示不同域的权重值,即W1=5,W2=3,Numt表示在文档d中包含查询关键词的个数,Total代表文档d所有词的数量,QNum表示检索条件中包含的w的数量。基于这一定义,得出下面的计算公式:
其中F(w,z)表示在域z中w出现的次数,可以从公式得出,标题和摘要包含的关键词数量与文档的评分值成正比。
最终根据这些信息,计算关键词的信息量。
6.相关度计算
根据万有引力定律,将词语看做一个物体,词的信息量看作物体的质量,词跨度看作物体间的距离,词语wi和wj的相关性有如下计算公式:
其中,m(wi)表示词语wi的信息量,r(wi,wj)表示词语wi和wj之间的差异性,有如下计算公式6所示:
其中S(wi,wj)表示词语wi和词语wj的共现次数。
算法设计思路
文档预处理
首先,利用HanLP分词工具,分别对标题和摘要进行分词处理,并记录词性;其次,词语过滤处理,包括停用词过滤和词性过滤;
计算词的信息量
文本进行预处理之后,会得到一系列候选关键词,按照关键词的先后顺序进行标号,遍历候选关键词,记录词频s_fre、词语首次出现位置s_first、末位置s_last以及词语总数sum,利用公式计算相应的权值:
(1)根据公式(1)计算位置因子;
(2)根据公式(2)计算词频因子;
(3)根据公式(3)计算词跨度因子;
(4)通过上面的信息计算词语的信息量。
计算词语的相关性
根据公式(5)计算词语间的相关性。
计算TextRank值
将公式(5)代入TextRank值的原计算公式得到改进后的公式7:
根据权重提取候选标签
对于每一条结果,将词语按TextRank值进行排序,选取前五作为候选标签。
标签生成
将所有候选标签进行合并,选取得分最高的十个词语作为标签。
从图3可以看出,该算法主要是通过分析词语的特征信息,并通过公式计算特征信息的影响因子,最终综合所有特征信息的影响因子,计算词的信息量,然后利用公式计算词语间相关度,构成TextRank算法图模型中的边,最后,计算每个词的TextRank值。
3.标签提取
设计思路:本发明的数据源来自于搜索引擎爬取的结果,获取每一条结果的标题和摘要,利用改进的TextRank关键词提取算法,获取每一条结果中得分最高的N个词,然后合并所有的结果,并进行排序,取排名前十的词语作为标签。
由图4可以标签提取主要包括三个步骤,首先是数据源处理,本发明通过调用多种搜索引擎的接口,并对其结果进行融合,然后抽取每条结果中的标题和摘要进行分析;然后获取利用改进的TextRank算法,计算每条结果中的TextRank值,取得分最高的前五个作为候选关键词;最后对所有结果进行合并,取得分最高的词作为标签。
- 还没有人留言评论。精彩留言会获得点赞!