一种基于多通道网络的视频人脸检测和识别方法与流程
本发明涉及一种视频人脸检测识别领域,尤其是涉及一种基于深度学习的视频人脸识别方法。
背景技术:
视频监控是安防系统的一个重要组成部分。随着视频传感器技术以及相应配套技术的发展,从最开始的模拟监控系统,之后的数字-模拟监控系统,到现在开始应用的ip监控系统,视频监控的应用范围越来越大,特别是公安系统大量部署视频监控系统以应用于治安管理以及疑犯追踪等领域。
快速发展的视频监控系统产生了海量的监控视频数据,在治安管理及疑犯追踪领域对这些视频数据的一个主要的处理是通过一个人的一张或数张图片,找到该人出现过的视频文件以及相应的帧数。传统方式使用人力对这些视频数据进行查找、整理,主要的缺点在于查找效率低下,错误率高、需要反复排除,且花费时间长,随着视频监控系统的不断发展以及监控视频数据的不断增加,传统的人人工查找的方法已经越来越不适用。
通过视频图像处理技术和模式识别技术自动地对收集到地视频信息进行处理、识别,已经在交通管理领域已经取得了十分成熟的应用。但是现有的基于图像处理的识别方法仅能够在理想环境下达到较高的识别准确率,在光线变化复杂、图像质量低下、待识别对象姿态变化时,漏检率和误检率便会迅速升高,所以对视频中人脸的自动识别、分析还不能达到实际应用的水平。
随着大数据和深度学习技术的发展,深度学习技术被应用于人脸检测系统中,并取得较好的效果。现有的一些基于深度学习的视频人脸识别专利,如专利CN201511033733.6,将视频视作一组图片,并获取若干张质量较好的图片上的人脸进行识别,这种方法忽略了不同帧之间的联系,丢失了大量的信息,在视频质量变差时,使得最终识别的精确度严重下降。
专利CN201510471210.3提出一种基于深度神经网络的实时人脸识别方法,该方法通过深度神经网络提取人脸的特征向量,首先计算特征向量之间的汉明距离,然后选择处于阈值之下的人脸作为二次识别的对象,计算二次识别的特征向量的欧式距离,以欧式距离来判断待识别人脸属于人脸库中哪一个人脸,以提高人脸库规模较大时的运算效率。
从现有的方法来看,主要是提取视频图像中的某些帧的人脸信息,利用深度学习进行训练和检测识别,对于视频图像中各帧之间的时间-空间上联系还没有考虑,导致准确率较低。
技术实现要素:
为了克服已有视频人脸检测和识别方法的准确率较低的不足,本发明提供了一种准确率较高的基于多通道网络的视频人脸检测和识别方法。
本发明解决其技术问题所采用的技术方案是:
一种基于多通道网络的视频人脸检测和识别方法,包括如下步骤:
S1:视频预处理
接收监控设备收集到的视频数据,并将其分解为一帧一帧的图像,给每一帧图像加上时间信息;
S2:目标人脸检测和姿态系数计算,过程如下:
提取视频图像中人脸位置以及对应的五官位置,计算视频图像中人脸以及标准姿态人脸五官的距离,计算姿态系数,整合姿态相近图像,将相邻帧间位置接近且姿态系数相差最小的人脸视为同一人脸族中的人脸;定义阈值φ,对于每一个人脸族,选取m张p<φ的人脸;如果在该人脸族中p<φ的人脸图像数为mp<φ张,则将该人脸族中姿态系p最小的一张人脸图像复制m-mp<φ份,与其他图像一同构成m张图像,输入到S3中;
S3:人脸姿态纠正:对于S2中得到的m张人脸,进行姿态调整;
S4:基于深度神经网络的人脸特征提取,过程如下:
S4.1人脸特征提取网络训练
在进行视频图像的人脸特征提取时,已预先利用人脸数据库进行特征模型训练,获取人脸数据库中每个人不同角度、不同光照下的M张图像,随机抽取其中m张图像,对这m张图像进行姿态矫正后,将其组合成w'×h'×3m的人脸图像,其中w'为训练图片的宽,h'为训练图片的高,3m为RGB3通道乘以图像数量m,对人脸数据库中每个人进行上述操作,并编上标签,输入到神经网络中训练;
S4.2视频人脸特征提取
通过S3中得到了m张w×h×3矫正后的人脸彩色图像,每个图像有3个通道,将不同图像以不同通道的形式融合在一起,即融合为一张有3×m个通道的人脸图像w×h×3m;
将得到的这张w×h×3m的人脸图像输入S4.1训练得到到人脸特征提取网络中,并最终得到一个代表该人脸的特征向量;
S5人脸特征比对
对于输入的人脸,利用步骤S4得到特征向量后,再利用余弦距离来匹配输入人脸特征向量与特征库中向量的匹配度,计算过程如下:
S5.1初步筛选
计算待识别人脸的特征与每个类的中心特征的余弦距离,计算方式如公式(10)所示,操作表示为向量的二范数,即向量的长度,cosθ即为向量与向量的余弦距离:
与待识别人脸余弦距离大于设定阈值的类加入备选类中,如果待识别人脸的特征与所有类的中心特征的余弦距离均小于则视为数据库中未存储该人的信息,结束识别。
进一步,所述步骤S5还包括以下步骤:
S5.2精确筛选
对于每一个备选类中的每一个人脸,计算它们的特征向量与待识别人脸的特征向量的余弦距离,选取其中余弦距离超过设定阈值ρ的人脸作为识别结果,并将识别结果所在的视频图像输出;如果每一个备选类中的每一个人脸与待识别人脸的余弦距离均小于ρ,则视为数据库中未存储该人的信息。
再进一步,所述步骤S1中,接收到的视频中的第一帧图像为图像1,然后按时间顺序设定视频中的第t帧图像为图像t,以It表示第t帧图像,以I表示同一视频的帧图像集合,完成对视频的预处理后,按时间从前到后的顺序将分解的图像传到人脸目标检测模块中。
更进一步,所述步骤S2中,目标人脸检测和姿态系数计算的过程如下:
S2.1提取视频图像中人脸位置以及对应的五官位置
对于每一帧图像It,利用哈尔特征找出该帧图像中存在的人脸以及对应的五官的坐标,分别记作F1(x1,y1),F2(x2,y2),F3(x3,y3),F4(x4,y4),F5(x5,y5);
S2.2计算视频图像中人脸以及标准姿态人脸五官的距离
令标准姿态图像I'中人脸五官的坐标为F1'(x'1,y'1),F2'(x'2,y'2),F3'(x'3,y'3),F4'(x'4,y'4),F5'(x'5,y'5),利用公式(1)和公式(2)计算视频图像It和标准姿态图像I'中人脸五官间相互距离:
其中,(xi,yi)、(xj,yj)表示待查找人脸中不同五官的坐标,(x'i,y'i)、(x'j,y'j)表示标准姿态图像中不同五官的坐标,dij表示待识别人脸五官间的相互距离,d'ij表示标准姿态图像中人脸五官间的相互距离;
S2.3计算姿态系数,整合姿态相近图像
定义人脸的姿态系数p,利用公式(3)计算姿态系数p:
其中,λ为缩放系数,用以避免待识别人脸图像与标准姿态图像尺度不一致时造成的误差,λ的值可由公式(4)计算得出,即λ取使得姿态系数最小的值;
所述步骤S3中,姿态调整的步骤如下:
S3.1计算人脸旋转向量
通过已知的标准人脸模型以及视频中五官特征点的坐标,使用POSIT算法得到图像中人脸的姿态信息,即人脸的旋转向量R,即
S3.2计算矫正图像和原图像的映射关系
通过人脸的旋转向量,得到矫正后人脸图像中某一像素点到原人脸图像中某一像素点的映射关系,在矫正后图像中以人脸中轴为y轴,以两眼的连线为x轴,构建坐标系,令(x,y)=f(x',y')为矫正后图像上一点(x',y')到原图像上一点(x,y)的映射,具体如下:
S3.3姿态矫正
rgb'(x,y)为矫正后图像上(x,y)处的rgb值,rgb(x,y)为原人脸图像上(x,y)处的rgb值,则利用公式(7)得到矫正后人脸图像中某一点(x,y)上的rgb值,设
其中,G为高斯概率矩阵,在实际操作过程中,因为不同人脸的实际三维模型和标准三维模型存在一定差别,所以矫正后图像上的某一点与原图像对应点的映射关系会存在一定误差,因而矫正后图像上某一点的rgb值由原图像上对应位置处附近9个点的rgb共同得出,即通过高斯概率矩阵G求得该点处rgb值的期望值,作为该点的rgb值;公式(7)中k是事先设定好比例值;
对同一人脸族中的每张人脸进行人脸姿态矫正后,得到m若干张大小为w×h×3的人脸图像,即一张拥有RGB3个通道的w×h像素的彩色图像。
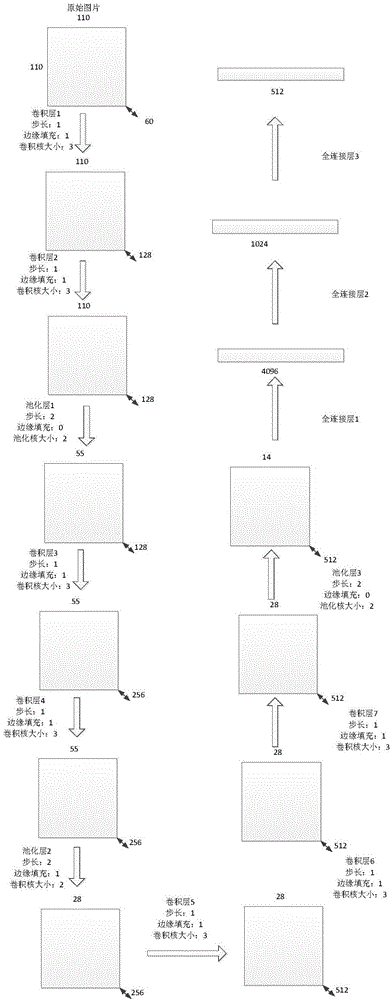
所述步骤S4.1中,采用梯度下降算法训练神经网络,每输入batch张图片并计算损失后更新神经网络的权重,网络中全连接层3输出的512维向量表示输入的人脸是哪一人的概率,对其做softmax回归,得到相应的损失函数,即如公式(9)所示,其中,k表示输入图像所属的类别,zk表示全连接层3输出的512维向量中的第k个数值:
loss=∑-logf(zk) (10)
计算了损失函数后,通过前向推断计算和反向梯度计算,计算出神经网络中各层的更新值,对各层的权值进行更新;
预先对数据库中的人脸特征集进行聚类分析以建立空间索引,操作步骤如下:
S4.1.1对于人脸特征库中的特征使用聚类算法,将这些人脸特征聚为若干类;
S4.1.2对于每一类,计算类中所有人脸的特征向量的均值,记作该类的中心特征。
本发明利用监控视频的各帧之间的关联性,结合深度学习方法,能够在海量的视频文件中目标人脸出现过的视频文件以及所在的帧数。相较于其它方法,本发明通过收集同一个人在不同帧中的图像信息,加以综合考虑,能够最大程度地利用视频数据地信息,从而提高识别地准确率。
本发明的有益效果主要表现在:
1、以往的方法对视频中人脸进行检测时,都是单独地考虑不同帧中的图像,未能够有效地利用视频中的信息。本方法利用将不同图像视作不同通道的方法,将同一个人脸在不同帧中的图像融合为一张多通道的图像,并利用多层卷积网络隐式地提取综合提取这些图像的联合特征。一方面,能够最大程度的利用视频中的信息,提高了准确率;另一方面,多张图像同时输入到神经网络中,避免了多次输入造成的时间浪费;
2、由于需要将多张人脸图像融合为一张图像,必须要确保不同人脸图像中相同位置的特征大致保持一致,即在不同图像中,眼睛、鼻子等要大致处于同一个位置。否则特征提取网络会难以收敛。因而,在进行特征提取之前,必须对人脸图像进行姿态矫正。在本方法里的人脸姿态中,利用了人脸沿中轴线对称的特点,矫正后人脸上某一点的rgb值有其在原图对应位置的rgb值以及沿中轴线对称处对应点的rgb值综合得出。这样,很大程度上避免了一般人脸姿态矫正方法中的信息丢失的弊端,提高了最终识别的准确率;
3、对于视频中特定帧的选取必须要考虑到帧的质量,而帧图像中的人脸姿态是决定帧质量的一个主要因素,但实际过程中对每一帧图像中的每一个人脸都进行姿态估计的代价过大。所以本方法中定义了一种姿态系数来判断人脸的姿态,其能够较好地反映人脸的姿态,同时计算量小。因而能够快速准确地找出一个人脸族中质量较好地若干帧图像。
附图说明
图1是本发明的总体流程图。
图2是本发明实施例中采用的深度学习网络结构图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1和图2,一种基于多通道网络的视频人脸检测和识别方法,所述的方法包括如下步骤:
S1:视频预处理
接收监控设备收集到的视频数据,并将其分解为一帧一帧的图像,给每一帧图像加上时间信息,具体为:接收到的视频中的第一帧图像为图像1,然后按时间顺序设定视频中的第t帧图像为图像t。在下面的叙述中,以It表示第t帧图像,以I表示同一视频的帧图像集合。完成对视频的预处理后,按时间从前到后的顺序将分解的图像传到人脸目标检测模块中。
S2:目标人脸检测和姿态系数计算
S2.1提取视频图像中人脸位置以及对应的五官位置
对于每一帧图像It,利用哈尔特征找出该帧图像中存在的人脸以及对应的五官(双眼、鼻尖以及嘴唇的两侧)的坐标,分别记作F1(x1,y1),F2(x2,y2),F3(x3,y3)。F4(x4,y4),F5(x5,y5)
S2.2计算视频图像中人脸以及标准姿态人脸五官的距离
令标准姿态图像I'中人脸五官(双眼、鼻尖以及嘴唇的两侧)的坐标为F1'(x'1,y'1),F2'(x'2,y'2),F3'(x'3,y'3)。F4'(x'4,y'4),F5'(x'5,y'5),利用公式(1)和公式(2)计算视频图像It和标准姿态图像I'中人脸五官间相互距离。
其中,(xi,yi)、(xj,yj)表示待查找人脸中不同五官的坐标,(x'i,y'i)、(x'j,y'j)表示标准姿态图像中不同五官的坐标,dij表示待识别人脸五官间的相互距离,d'ij表示标准姿态图像中人脸五官间的相互距离。
S2.3计算姿态系数,整合姿态相近图像。
定义人脸的姿态系数p,利用公式(3)计算姿态系数p,用于衡量待识别人脸的姿态与标准姿态的差异,p越小表示待识别人脸的姿态越标准,即将其作为人脸识别的图像的准确率越高;p越大表示待识别人脸的姿态更偏离标准姿态,即图像质量较差,将其作为人脸识别的图像的准确率越低:
其中,λ为缩放系数,用以避免待识别人脸图像与标准姿态图像尺度不一致时造成的误差,λ的值可由公式(4)计算得出,即λ取使得姿态系数最小的值。
计算所有检测到的人脸图像的姿态系数,将相邻帧间位置接近且姿态系数相差最小的人脸视为同一人脸族中的人脸。定义阈值φ,对于每一个人脸族,选取m张p<φ的人脸。如果在该人脸族中p<φ的人脸图像数为mp<φ张,则将该人脸族中姿态系p最小的一张人脸图像复制m-mp<φ份,与其他图像一同构成m张图像,输入到S3中。
S3:人脸姿态纠正
对于S2中得到的m张人脸,进行姿态调整,具体步骤如下:
S3.1计算人脸旋转向量
在监控视频中,出现的人一般离摄像头较远,即人脸上特征点离摄像头的距离要远大于它们之间距离,则可以通过已知的标准人脸模型以及视频中五官特征点的坐标,使用POSIT算法得到图像中人脸的姿态信息,即人脸的旋转向量R。即
S3.2计算矫正图像和原图像的映射关系
通过人脸的旋转向量,可以得到矫正后人脸图像中某一像素点到原人脸图像中某一像素点的映射关系,在矫正后图像中以人脸中轴为y轴,以两眼的连线为x轴,构建坐标系。令(x,y)=f(x',y')为矫正后图像上一点(x',y')到原图像上一点(x,y)的映射。具体如下:
S3.3姿态矫正
rgb'(x,y)为矫正后图像上(x,y)处的rgb值,rgb(x,y)为原人脸图像上(x,y)处的rgb值。则利用公式(7)得到矫正后人脸图像中某一点(x,y)上的rgb值。设
其中,G为高斯概率矩阵,在实际操作过程中,因为不同人脸的实际三维模型和标准三维模型存在一定差别,所以矫正后图像上的某一点与原图像对应点的映射关系会存在一定误差,因而矫正后图像上某一点的rgb值由原图像上对应位置处附近9个点的rgb共同得出,即通过高斯概率矩阵G求得该点处rgb值的期望值,作为该点的rgb值。
这里,矫正图像利用人脸对称的特性,矫正后的人脸图像信息综合考虑人脸地侧的信息,最大化地提取信息,避免了人脸旋转角度过大时姿态矫正后信息丢失的问题。公式(7)中k是事先设定好比例值,在0-0.5之间取值,k越小意味着更多地考虑单独一侧的图像信息,k越大意味者更多地综合考虑两侧的图像信息。
对同一人脸族中的每张人脸进行人脸姿态矫正后,得到m若干张大小为w×h×3的人脸图像,即一张拥有RGB3个通道的w×h像素的彩色图像。
S4基于深度神经网络的人脸特征提取
S4.1人脸特征提取网络训练
在进行视频图像的人脸特征提取时,已预先利用人脸数据库进行特征模型训练。训练方式如下:
获取人脸数据库中每个人不同角度、不同光照下的M张图像,随机抽取其中m张图像,对这m张图像进行姿态矫正后,将其组合成w'×h'×3m的人脸图像,其中w'为训练图片的宽,h'为训练图片的高,3m为RGB3通道乘以图像数量m。对人脸数据库中每个人进行上述操作,并编上标签,输入到神经网络中训练。
这种将不同图像视为不同通道融合后作为输入的神经网络我们将其称为多通道网络。
本发明采用梯度下降算法训练神经网络,batch设定为256,即每输入256张图片并计算损失后更新神经网络的权重。
上述网络中全连接层3输出的512维向量表示输入的人脸是哪一人的概率,对其做softmax回归,得到相应的损失函数,即如公式(9)所示,其中,k表示输入图像所属的类别,zk表示全连接层3输出的512维向量中的第k个数值。
loss=∑-logf(zk) (19)
计算了损失函数后,通过前向推断计算和反向梯度计算,计算出神经网络中各层的更新值,对各层的权值进行更新,以实现减少loss的目的,从而优化网络。
在实际应用中,考虑到数据库中已经存储的人脸的数目可能十分巨大,可以预先先对数据库中的人脸特征集进行聚类分析以建立空间索引,具体操作步骤如下:
S4.1.1对于人脸特征库中的特征使用聚类算法,如Kmeans,将这些人脸特征聚为若干类。
S4.1.2对于每一类,计算类中所有人脸的特征向量的均值,记作该类的中心特征。
S4.2视频人脸特征提取
通过S3中得到了m张w×h×3矫正后的人脸彩色图像,每个图像有3个通道,将不同图像以不同通道的形式融合在一起,即融合为一张有3×m个通道的人脸图像w×h×3m
将得到的这张w×h×3m的人脸图像输入S4.1训练得到到人脸特征提取网络中,并最终得到一个代表该人脸的特征向量。
S5人脸特征比对
对于输入的人脸,利用步骤S4得到特征向量后,再利用余弦距离来匹配输入人脸特征向量与特征库中向量的匹配度,计算过程如下:
S5.1初步筛选
计算待识别人脸的特征与每个类的中心特征的余弦距离,计算方式如公式(10)所示,操作表示为向量的二范数,即向量的长度(表示向量的长度,表示向量的长度),cosθ即为向量与向量的余弦距离:
与待识别人脸余弦距离大于设定阈值的类加入备选类中。如果待识别人脸的特征与所有类的中心特征的余弦距离均小于则视为数据库中未存储该人的信息,结束识别。
S5.2精确筛选
对于每一个备选类中的每一个人脸,计算它们的特征向量与待识别人脸的特征向量的余弦距离,选取其中余弦距离超过设定阈值ρ的人脸作为识别结果,并将识别结果所在的视频图像输出;如果每一个备选类中的每一个人脸与待识别人脸的余弦距离均小于ρ,则视为数据库中未存储该人的信息,结束识别。
至此,完成视频人脸的识别。
- 还没有人留言评论。精彩留言会获得点赞!