一种逆向解析GPU指令的方法及系统与流程
本发明涉及GPU微体系结构、编译器代码生成技术和程序优化技术领域,特别涉及一种逆向解析GPU指令的方法及系统。
背景技术:
多年来,GPU厂商只向用户提供由驱动封装的上层API,而尽量少地暴露其内部原理和细节,如驱动的软件架构、GPU的微架构、指令集等。这导致学术界在GPU架构研究领域,大幅落后于工业界,长期处于停滞状态,在GPU只用于图形加速的年代,这种保守策略在实际应用中并不成为一个突出的问题,甚至具有一定的合理性:最初的绘图API与硬件实现强相关,API只是硬件功能的简单封装,API本身已经暴露了足够多的硬件细节,早期版本的openGL接口更是被称作三维绘图的汇编语言;另外,绘图API的直接调用者非常少,游戏都是基于渲染引擎开发,显卡厂商只要协助优化好主流的渲染引擎,就可以保证绝大多数游戏的流畅运行;从而,显卡厂商可以更自由地改进和创新微架构,无需在底层进行后向兼容,只需在软件封装的绘图API层次上后向兼容即可。
处于垄断地位的GPU厂商Nvidia维持了技术封闭的惯性,不提供汇编器,不支持最底层的汇编编程,也不公开那些只在汇编层次上才能控制的硬件架构特性,作为补充,它提供了底层接口PTX,虽然是和汇编很接近的中间表示,但PTX对硬件的控制能力要低于汇编,比如,PTX不能控制寄存器分配,也不能精确控制指令的调度行为,上层的类C接口对硬件的控制能力更弱,开发人员为了提升性能,只能寄希望于编译器优化,然而,“Daniel J Bernstein,Hsieh-Chung Chen,Chen-Mou Cheng,Tanja Lange,Ruben Niederhagen,Peter Schwabe,and Bo-Yin Yang.Usable assembly language for gpus:a success story.IACR Cryptology ePrint Archive,2012:137,2012.”指出Nvidia提供的编译器NVCC生成的代码效率并不高,比如寄存器分配存在大量bank冲突,实际上,Nvidia发布的许多并行算法库,都是基于内部的汇编器,再进行手工汇编优化,才达到较为理想的效率,问题是,不同于三维绘图领域只有少量的渲染引擎开发商,GPGPU的用户群广泛而多样,而Nvidia只对少量算法库进行了手工汇编优化,只对少量大客户提供了官方支持,其余大量用户却无法从昂贵的GPGPU硬件上榨取出最大的性能,这是对计算资源的巨大浪费,更糟糕的是,许多应用极为广泛的核心算法,Nvidia也并没有优化到位,比如单精度浮点矩阵乘(singe-precision matrix multiplication),Nvidia针对主流Kepler架构的手工汇编优化版,效率只达到理论峰值的74%,是第三方优化的单精度浮点乘和NVIDIA厂商的cuBLAS中的SGEMM性能对比,第三方汇编优化的比cuBLAS性能更高,这些研究表明汇编优化对于挖掘GPU的性能很有价值。
一些研究者在GPU性能调优和工具上有一些零散的进展,比如微基准测试程序“Zhang,Yao,and John D.Owens."A quantitative performance analysis model for GPU architectures."In 2011 IEEE 17th International Symposium on High Performance Computer Architecture,pp.382-393.IEEE,2011.”“Xinxin Mei,Kaiyong Zhao,Chengjian Liu,and Xiaowen Chu.Benchmarking the memory hierarchy of modern gpus.In Network and Parallel Computing,pages 144–156.Springer,2014.”“Henry Wong,Misel-Myrto Papadopoulou,Maryam Sadooghi-Alvandi,and Andreas Moshovos.Demystifying gpu microarchitecture through microbenchmarking.In Performance Analysis of Systems&Software(ISPASS),2010 IEEE International Symposium on,pages 235–246.IEEE,2010.”、汇编器和GPU汇编级别的优化,然而,他们的工作都只集中在某个单一层面上,没有提出一个能在新一代架构上延续的通用技术,比如指令破解方法和相应的自动化工具,另外GPU还没有汇编级别的公开基准测试程序,大部分正在使用的基准测试程序都是基于CUDA,从而导致测试的结果并不可靠。
技术实现要素:
针对现有技术的不足,本发明提出一种逆向解析GPU指令的方法及系统。
本发明提出一种逆向解析GPU指令的方法,包括:
步骤1,将所述GPU指令进行编译,生成编译文件,将所述编译文件进行反汇编,生成反汇编文件,通过汇编解析器将所述反汇编文件表示成instMap变量,其中所述instMap变量的变量类型包括操作码、修饰码、指令、操作数与对应的操作数类型;
步骤2,将所述instMap变量输入到解码求解器,所述解码求解器判断所述instMap变量的变量类型,并通过已经确定的所述操作码或修饰码查找相对应的编码。
若所述解码求解器分别对所述instMap变量的64位编码的每一位进行探测,再通过反汇编将所述64位编码进行反汇编,如果生成的新反汇编的指令与所述64位编码原有指令的指令名称不一样,则说明所述64位编码当前位表示操作码,根据所述当前位,对操作码在编码空间中进行枚举。
将所述instMap变量中指令的名称与操作数类型作为关键字查询visited字典,对于所述instMap变量里的每一条指令,探测除了操作数之外的其他位,返回已修改的某一位操作数,将<指令,操作数类型>在visited字典里标注为1,表示已经访问过了。
通过将所述instMap变量中指令逐位进行异或,通过修饰码是否改变完成探测修饰码,找到每条指令的修饰码的编码空间后,在修饰码的编码空间进行枚举,找出所有的修饰码的名称,然后根据某一修饰码的名称,找出所有带所述某一修饰码的指令的所有交集,最后将编码与所有带所述某一修饰码的指令的操作码的编码做异或,获取修饰码的编码。
根据操作数的名称,获取与其相对应的编码。
本发明还提出一种逆向解析GPU指令的系统,其特征在于,包括:
生成变量模块,用于将所述GPU指令进行编译,生成编译文件,将所述编译文件进行反汇编,生成反汇编文件,通过汇编解析器将所述反汇编文件表示成instMap变量,其中所述instMap变量的变量类型包括操作码、修饰码、操作数与对应的操作数类型;
查找编码模块,用于将所述instMap变量输入到解码求解器,所述解码求解器判断所述instMap变量的变量类型,并通过已经确定的所述操作码或修饰码查找其余编码。
若所述解码求解器分别对所述instMap变量的64位编码的每一位进行探测,再通过反汇编将所述64位编码进行反汇编,如果生成的新反汇编的指令与所述64位编码原有指令的指令名称不一样,则说明所述64位编码当前位表示操作码,根据所述当前位,对操作码在编码空间进行枚举。
将所述instMap变量中指令的名称与操作数类型作为关键字查询visited字典,对于所述instMap变量里的每一条指令,探测除了操作数之外的其他位,返回已修改的某一位操作数,将<指令,操作数类型>在visited字典里标注为1,表示已经访问过了。
通过将所述instMap变量中与编码相对应的指令逐位进行异或,通过修饰码是否改变完成探测修饰码,找到每条指令的修饰码的编码空间后,在修饰码的编码空间进行枚举,找出所有的修饰码的名称,然后根据某一修饰码的名称,找出所有带所述某一修饰码的指令的所有交集,最后将编码与所有带所述某一修饰码的指令的操作码的编码做异或,获取修饰码的编码。
根据操作数的名称,获取与其相对应的编码。
由以上方案可知,本发明的优点在于:
发明可有效应对GPU封闭技术体系而对编译和程序优化的限制:
1.由于NVIDIA没有提供指令编码,基于NVIDIA现有工具链,本发明提出的方法解析出GPU指令编码,指令的基本格式如图1所示。63~54表示操作码,42~23表示20立即数,21~18表示判定寄存器,17~10表示源寄存器,9~2表示目标寄存器,1~0表示,具体的域与指令语法相关;
2.在破解指令编码的基础上,结合PTX文档,可构造GPU汇编器;
3.可为GPU编译器提供了一些编译辅助功能,提高GPU程序的效率;
4.可设计和标准化一系列的微基准测试程序来探测GPU微架构特性和参数。
附图说明
图1为指令的编码格式示例图;
图2为指令解析算法流程图;
图3为操作数解法器算法(算法1)图;
图4为操作码解法器算法(算法2)图;
图5为修饰码解法器算法(算法3)图。
具体实施方式
以下为本发明指令解析算法流程,如下所示:
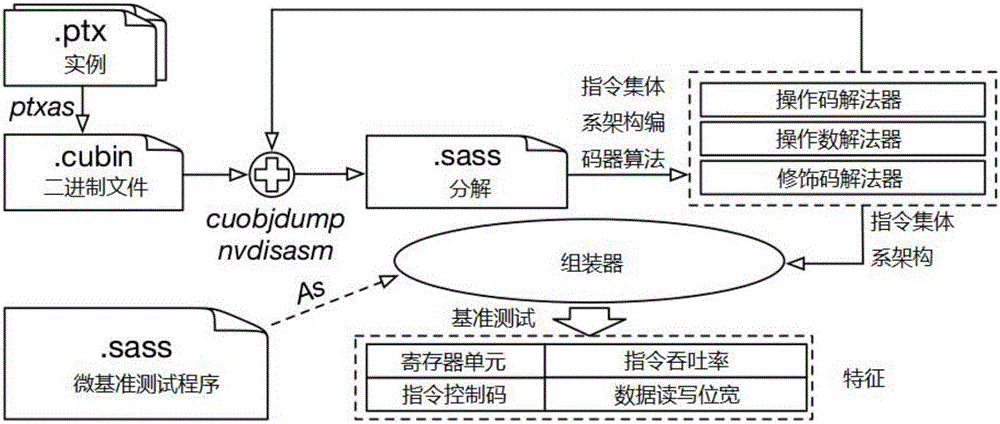
指令解码需要生成64位指令编码和汇编指令的对应关系,如图2所示,算法流程如下:
首先利用PTX指令生成器,自动生成NVIDIA PTX文档中的所有指令及其修饰码的组合,然后把这些PTX文件用ptxas编译成cubin,并通过cuobjdump反汇编,最后把反汇编的信息,通过汇编解析器表示成instMap变量,用于解码求解器的输入,其中instMap的结构包括:操作码、指令、修饰码、所有的操作数和对应的操作数类型等。
操作数可以是寄存器(R5)、全局内存([R6+0x20])、常量内存(C[0x2][0x40])、共享内存([0x50])、立即数(0x9and1.5)和判定寄存器(P3),我们发现,操作数的名字总是和数字相关,因此可以推测操作数的编码可以用它的名字来表示,比如寄存器操作数R5的二进制编码是101,立即数0x9的编码是1001,相反,操作码和修饰码则是助记符,不能直接通过名字表达成二进制,因此操作码和修饰码需要在他们的编码空间进行枚举,我们发现修饰码是指令相关的,同一个名字的修饰码在不同指令的编码也可能不同,比如LD和LDG的类型修饰码名字都是.32,.64,.128,.S16,.U16,.S8,.U8,但是掩码的位置却不同,因此对于修饰码,我们需要按照具体指令分别处理。
以下为本发明操作码解法器算法,如图3所示:
操作码和修饰码不能通过名字判断其编码,算法1展示了操作码解法过程,根据NVIDIA提供的伪汇编PTX文档,编写PTX代码,然后用ptxas编译成cubin,再用cuobjudump反汇编,得到的汇编码(instMap变量)作为算法1的输入(1行),我们详细介绍下操作码求解器的具体过程,对于反汇编文件里的每一行指令,分别对其64位编码的每一位进行探测(第9行),这里主要是通过反转指令的每一位(11行),然后再通过反汇编工具nvdisasm进行反汇编(13行),如果新反汇编的指令和原有指令的指令名称不一样(15行),说明这一位表示操作码,然后把这位保存在opBits里,得到这里位之后,可以对操作码在编码空间进行枚举。
通过编写不同修饰码的组合并进行验证,进一步得到修饰码编码,然而,由于NVIDIA提供的PTX文档不全,这样并不能保证找到所有的操作码编码和修饰码编码,通过算法1我们可以找出所有的指令。
以下为本发明操作数解法器算法,如图4所示:
算法2是操作数解码器的求解过程。首先建立一个字典(记为visited字典),字典的key为操作数所在指令的名字和操作数类型,value则标记改操作数是否已被解码。输入是由操作码求解器的输入,操作数与操作数个数,顺序和类型和具体的指令相关,因此我们标记一组操作数是否被探测,需要具体指令的名字和操作数类型(一个数组)作为关键字查询visited字典,对于反汇编文件里的每一条指令(第4行),探测除了操作数之外的其他位(第8行),也是通过翻转指令编码中的一位(第10行)得到,wichChange返回修改的是哪一个操作数,然后把这些位放到合适的数组里,把<指令,操作数类型>在visited字典里标注位1,表示已经访问过了(第18行)。
以下为本发明修饰码解法器算法,如图5所示:
修饰码(Modifier),定义了某一条指令的具体行为,比如LD有类型修饰码:.U8,.S8,.U16,.32,.64,.128,还有cache操作修饰码:.CS(cache streaming),.CG(cache at global level)等。修饰码相对操作码来说更为复杂,它的位置跨越很多操作位,而且与操作码相关,比如,同样是类型修饰码,LD和LDG的修饰码在指令中的位置就不同,一种解决方法是通过把指令逐位地异或,然后观测修饰码是否改变来进行探测(第6行到13行),找到每条指令的修饰码的编码空间后,在修饰码的编码空间进行枚举(第15行),下一步需要确定具体某个修饰码的编码,比如.U8的编码,.S8的编码,这个过程对应代码的20到29行,首先找出所有的modifier的名字(第20行),然后具体某一修饰码的名字,找出所有带这个修饰码的指令的所有交集(23-25行),最后把这条编码和这条指令的操作码的编码做异或,这样就只留下修饰码的编码。
本发明还提出一种逆向解析GPU指令的系统,包括:
生成变量模块,用于将所述GPU指令进行编译,生成编译文件,将所述编译文件进行反汇编,生成反汇编文件,通过汇编解析器将所述反汇编文件表示成instMap变量,其中所述instMap变量的变量类型包括操作码、修饰码、操作数与对应的操作数类型;
查找编码模块,用于将所述instMap变量输入到解码求解器,所述解码求解器判断所述instMap变量的变量类型,并通过已经确定的所述操作码或修饰码查找其余编码。
若所述解码求解器分别对所述instMap变量的64位编码的每一位进行探测,再通过反汇编将所述64位编码进行反汇编,如果生成的新反汇编的指令与所述64位编码原有指令的指令名称不一样,则说明所述64位编码当前位表示操作码,根据所述当前位,对操作码在编码空间进行枚举。
将所述instMap变量中指令的名称与操作数类型作为关键字查询visited字典,对于所述instMap变量里的每一条指令,探测除了操作数之外的其他位,返回已修改的某一位操作数,将<指令,操作数类型>在visited字典里标注为1,表示已经访问过了。
通过将所述instMap变量中与编码相对应的指令逐位进行异或,通过修饰码是否改变完成探测修饰码,找到每条指令的修饰码的编码空间后,在修饰码的编码空间进行枚举,找出所有的修饰码的名称,然后根据某一修饰码的名称,找出所有带所述某一修饰码的指令的所有交集,最后将编码与所有带所述某一修饰码的指令的操作码的编码做异或,获取修饰码的编码。
根据操作数的名称,获取与其相对应的编码。
- 还没有人留言评论。精彩留言会获得点赞!