同时融入好友特征和相似用户特征的协同过滤方法与流程
本发明涉及协同过滤方法及系统,尤其涉及一种同时融入好友特征和相似用户特征的协同过滤算法。
背景技术:
近年来,随着互联网产品中信息过载问题的愈发严重,许多产品中都迫切需要提供个性化推荐的功能。然而,传统的推荐技术只考虑了两种实体即“用户”和“物品”,而忽略了好友之间的社交关系对推荐结果的影响。为此,融入社交关系的推荐系统逐渐受到关注,当前已经有许多的科研和工程实践工作证明,社交关系的引入能够有效提高推荐系统的准确性和和个性化程度。
目前,融入社交关系的推荐方法采用的算法,主要分成两大类:(1)基于内存的个性化社交推荐算法:把社交关系融入到传统的基于内存的推荐算法之中,比如在基于用户的最近邻推荐算法或者基于物品的最近邻推荐算法加入社交关系。(2)基于模型的个性化社交算法:把社交关系融入到传统的基于模型的推荐算法之中,比如在概率矩阵分解模型中加入社交关系。
上述两类融入社交关系的推荐方法,只能分别融入社交关系或者用户相似度信息,无法同时对社交关系和用户相似度信息建模,而在真实的互联网产品应用场景之中,用户的兴趣偏好一方面会受到好友的影响,即社交关系的影响。其兴趣另一方面又趋向于相同兴趣偏好的用户,即受到高相似度用户的影响。所以本发明专利提出一种同时融入好友特征和相似用户特征的协同过滤方法和系统,同时把好友特征和相似用户特征融入到用户特征之中,改进协同过滤方法的准确度。
技术实现要素:
本发明的目的在于解决现有技术所存在的问题,找到一种同时融入好友特征和相似用户特征的协同过滤方法,提高协同过滤方法的准确度。
为了实现所述目的,本发明同时融入好友特征和相似用户特征的协同过滤方法,包括以下步骤:
步骤一:获取用户-物品评分矩阵,通过皮尔逊相关系数计算用户之间的相似度,建立用户相似度矩阵;
步骤二:获取用户-用户关系矩阵,对原始用户-用户关系矩阵进行归一化处理,得到归一化后的用户-用户关系矩阵;
步骤三:根据用户相似度矩阵和归一化后的用户-用户关系矩阵将相似用户特征和好友用户特征融入概率矩阵分解模型的用户特征,根据融入相似用户特征和好友用户特征的概率矩阵分解模型获取用户对物品的预测评分,根据预测评分为用户推荐物品。
进一步的,步骤一中,用户之间相似度的计算公式为:
其中,Siw为用户i与物品w的相似度,I为用户i和用户w的公共评分集合,Rij为用户i对物品j的评分,为用户i的评分均值,Rwj为用户w对物品j的评分,为用户w的评分均值。
进一步的,步骤二中,对原始用户-用户关系矩阵进行归一化的过程为:通过归一化,使得Fi表示用户i的好友集合,Tiv为原始用户-用户关系矩阵中第i行第v列的元素表示用户i对用户v的关系。
进一步的,步骤一中,设置相似度阈值,根据用户相似度矩阵选择与用户相似度高于相似度阈值的用户集合作为高相似度用户集合。
进一步的,步骤一中,设置高相似度用户数目的阈值Y,根据用户相似度矩阵选择与用户相似度最高的Y个用户作为高相似度用户集合。
进一步的,Y值为用户的好友数量。
进一步的,融入相似用户特征和好友用户特征的概率矩阵分解模型中:
用户隐因子矩阵U的条件概率为:
物品隐因子矩阵V的条件概率为:
评分预测公式为:
其中,U为用户隐因子矩阵,V为用户隐因子矩阵,S为用户相似度矩阵,T归一化后的用户-用户关系矩阵,Ui为用户i的特征向量,Uυ为用户υ的特征向量,Uw为用户w的特征向量,Vj为物品j的特征向量,Fi为用户i的好友集合,Ni为用户i的高相似度用户集合,Tiv为用户i与物品w的归一化后的关系值,Siw为用户i和用户w之间的相似度,为用户i对物品j的评分预测,为用户i的特征向量与物品j的特征向量的内积。
进一步的,根据融入相似用户特征和好友用户特征的概率矩阵分解模型获取用户对物品的预测评分的步骤包括:
根据预测评分公式、用户隐因子矩阵的条件概率和物品隐因子矩阵的条件概率提出需要最大化的隐因子矩阵的后验概率:
最大化上述概率函数,等价于最小化如下的损失目标函数,
其中表示Frobenius范数,R为用户-物品评分矩阵,U为用户隐因子矩阵,V为物品隐因子矩阵,S为用户相似度矩阵,T归一化后的用户-用户关系矩阵,Rij为用户i对物品j的评分,Ui为用户i的特征向量,Uυ为用户υ的特征向量,Uw为用户w的特征向量,Fi为用户i的好友集合,Ni为用户i的高相似度用户集合,Siw为用户i与物品w的归一化后的关系值,为用户i的特征向量与物品j的特征向量的内积;
采用随机梯度下降的方法优化损失目标函数,获得用户隐因子矩阵U和物品隐因子矩阵V,并使用预测评分。
进一步的,根据预测评分为用户推荐物品的步骤包括:根据预测评分,对前预测评分前N高的物品进行推荐。
通过实施本发明可以取得以下有益技术效果:通过将相似用户特征和好友用户特征融入概率矩阵分解模型的用户特征,建立融入相似用户特征和好友用户特征的概率矩阵分解模型,根据概率矩阵分解模型进行物品推荐,使得推荐结果好友受用户特征和相似用户特征影响,提高协同过滤方法的准确度。
附图说明
图1是同时融入好友特征和相似用户特征的协同过滤方法的流程图;
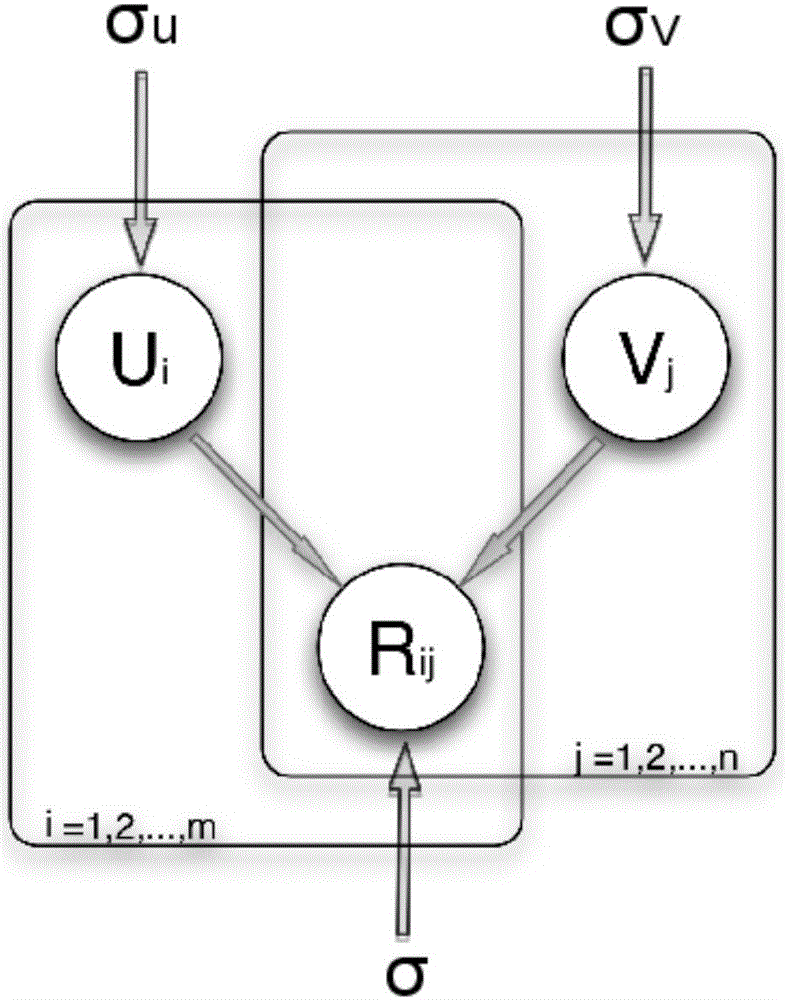
图2为标准矩阵分解模型;
图3为同时融入好友特征和相似用户特征的矩阵分解模型;
图4为同时融入好友特征和相似用户特征的协同过滤系统的框图。
具体实施方式
为了便于本领域技术人员的理解,下面结合具体实施例对本发明作进一步的说明:
如图1所示,本发明同时融入好友特征和相似用户特征的协同过滤方法,包括以下几个步骤:
步骤一:获取用户-物品评分矩阵,通过皮尔逊相关系数计算用户之间的相似度,建立用户相似度矩阵。通过用户相似度矩阵获取高相似度用户合集。
用户相似度矩阵建立过程为:用户-物品评分矩阵Rij为矩阵R中第i行,第j列的元素表示用户i对物品j的评分,一般用户物品评分数值标准为5分制、10分制、100分制等,通过皮尔逊相关系数计算用户之间的相似度,建立用户相似度矩阵S,其中皮尔逊相关系数的计算公式为:
其中,Siw为矩阵S中i行w列的元素表示用户i与物品w的相似度,I为用户i和用户w的公共评分集合,Rij为用户i对物品j的评分,为用户i的评分均值,Rwj为用户w对物品j的评分,为用户w的评分均值。
高相似度用户集合一般可采用三种方式获取,
第一种方法,设置相似度阈值,相似度高于阈值的所有用户为高相似度用户集合,比如阈值为0.5时,相似度高于0.5的所有用户挑选出来做高相似度用户集合。
第二种方法,设置高相似度用户数目的阈值,比如阈值为10时,挑选相似度最高的10个用户做高相似度用户集合。
第三种方法,对应用户好友的关系数量,比如一个用户有20个好友,那么我们对应的,选取20个高相似度用户作为高相似度用户集合,那么就可以跟好友关系的集合公平比较。
步骤二:对原始用户-用户关系矩阵进行归一化,得到归一化后的用户-用户关系矩阵;
归一化用户-用户关系矩阵的建立具体过程为:使用原始用户-用户关系矩阵这里矩阵T中第i行,第v列的元素Tiv表示用户i对用户v的关系,一般最常见的用户关系评分数值标准是01二元数值,即用户间存在好友关系时Tiv=1,否则Tiv=0,通过归一化,使得其中Fi表示用户i的好友集合。
以评分数值标准是01二元数值的用户-用户关系矩阵为例,归一化前的用户-用户关系矩阵T如下:
归一化的过程是将用户关系矩阵中,每一行的数值和变成1,归一化后的矩阵如下:
Fi表示用户i的好友集合,在上述表中,用户i的好友合集为用户i所在行中的非0数值所应在列中的用户。如用户5的好友合集为用户1、用户2和用户3,且用户5与用户1好友关系数值为1/3,用户5与用户1好友关系数值为1/3,用户5与用户1好友关系数值为1/3,其和为1。
步骤三:根据用户相似度矩阵和归一化后的用户-用户关系矩阵将相似用户特征和好友用户特征融入概率矩阵分解模型的用户特征,根据融入相似用户特征和好友用户特征的概率矩阵分解模型获取用户对物品的预测评分,根据预测评分为用户推荐物品。
其步骤包括:
1)在用户特征中同时融入好友用户特征和相似用户特征,提出一种改进的概率矩阵分解模型,改进的概率矩阵分解模型即融入相似用户特征和好友用户特征的概率矩阵分解模型。
如图2,标准的概率矩阵分解模型中,用户的隐因子矩阵U的条件概率是第i个用户的隐因子特征向量为Ui,物品的隐因子矩阵的条件概率是第j个物品的隐因子特征向量为Vj,表示Ui服从均值为0方差为的多维正态分布,表示Vj服从均值为0方差为的多维正态分布,同理,本申请后续公式中同类型公式的意义不在详细阐述,m表示对应矩阵的行数,n表示对应矩阵的列数。
如图3,在同时融入用户特征和相似用户特征的概率矩阵分解模型中,物品的隐因子矩阵的条件概率为而用户的隐因子矩阵的条件概率为:
其中U为用户隐因子矩阵,S为用户相似度矩阵,T归一化后的用户-用户关系矩阵,σT、σV、σU、σS为方差,可人工设定,Ui为用户i的特征向量,Uυ为用户υ的特征向量,Uw为用户w的特征向量,Vj为物品j的特征向量,Fi为用户i的好友集合,Ni为用户i的高相似度用户集合,Siw表示用户i和用户w之间的相似度,Tiv为用户i与物品w的归一化后的关系值。
对用户i对物品j的评分预测为用户隐因子向量与物品隐因子向量的内积
(2)根据步骤1提出的评分预测公式、用户隐因子矩阵的条件概率和物品的隐因子矩阵的条件概率,提出需要最大化的隐因子矩阵的后验概率如下:
最大化上述概率函数,等价于最小化如下的损失目标函数,
其中表示Frobenius范数,R为用户-物品评分矩阵,U为用户隐因子矩阵,V为物品隐因子矩阵,S为用户相似度矩阵,T归一化后的用户-用户关系矩阵,σ、σV、σU、σS是方差,Rij是用户i对物品j的评分,Ui是用户i的特征向量,Uυ为用户υ的特征向量,Uw是用户w的特征向量,Fi表示用户i的好友集合,Ni表示用户i的高相似度用户集合,Siw表示用户i与物品w的归一化后的关系值,为用户i的特征向量与物品j的特征向量的内积,λU,λV,λT和λS为可调权重参数,λS≥0并且λT≥0,两个参数的大小选择也会影响模型的最后预测精度,也可以理解为好友或者高相似度用户对特定用户特征影响的大小,比如λT比较大,那说用户特征受到好友影响较大,λS较大,那说用户特征受到高相似度用户影响较大,目标函数表明用户特征同时受到其好友特征和相似用户特征影响,Iij表示指示函数,如果用户i以对物品j评过分,它的值等于1,否则为0,为了防止过拟合;上标T表示其两侧矩阵的內积。
(3)采用随机梯度下降的方法最小化步骤2)中的优化目标函数,获得用户隐因子矩阵U和物品隐因子矩阵V,并使用预测未知评分,进而为每个用户个性化推荐top-N个物品。
本发明中,步骤一与步骤二之前没有前后逻辑关系,也就是说,既可以先进行步骤一,也可以先进行步骤二。
如图4所示,本发明还设计了一种采用同时融入好友特征和相似用户特征的协同过滤方法的协同过滤系统,包括:
用户相似度矩阵建立模块:获取用户-物品评分矩阵,通过皮尔逊相关系数计算用户之间的相似度,建立用户相似度矩阵;
用户-用户关系矩阵归一化模块:获取用户-用户关系矩阵,对原始用户-用户关系矩阵进行归一化处理,得到归一化后的用户-用户关系矩阵;
物品推荐模块:根据用户相似度矩阵和归一化后的用户-用户关系矩阵将相似用户特征和好友用户特征融入概率矩阵分解模型的用户特征,根据融入相似用户特征和好友用户特征的概率矩阵分解模型获取用户对物品的预测评分,根据预测评分为用户推荐物品。
以下以电影推荐和音乐推荐为例进行进一步描述:
电影推荐
1)建立用户相似度矩阵:从原始的用户-电影评分数据中,通过皮尔逊相关系数计算用户之间的相似度,建立用户相似度矩阵;通过皮尔逊相关系数计算用户之间的相似度,建立用户相似度矩阵S,皮尔逊相关系数计算公式为其中是用户i对电影的评分均值,是用户w的对电影的评分均值,集合I表示用户i和用户w的公共电影评分集合。
2)建立归一化的用户-用户关系矩阵:使用原始用户-用户关系矩阵这里矩阵T中第i行,第v列的元素Tiv表示用户i对用户v的关系,通过归一化,使得其中Fi表示用户i的好友集合。
3)个性化推荐生成:将步骤1获得的用户间相似度信息和步骤2获得的归一化后的用户好友关系,同时融入到用户特征之中,进一步改进标准概率矩阵分解模型,通过随机梯度下降求解本发明中提出的目标函数,为用户生成个性化的top-N个电影推荐结果。
音乐推荐
1)建立用户相似度矩阵:从原始的用户-音乐评分数据中,通通过皮尔逊相关系数计算用户之间的相似度,建立用户相似度矩阵;通过皮尔逊相关系数计算用户之间的相似度,建立用户相似度矩阵S,皮尔逊相关系数计算公式为其中是用户i对音乐的评分均值,是用户w的对音乐的评分均值,集合I表示用户i和用户w的公共音乐评分集合。
2)建立归一化的用户-用户关系矩阵:使用原始用户-用户关系矩阵这里矩阵T中第i行,第v列的元素Tiv表示用户i对用户v的关系,通过归一化,使得其中Fi表示用户i的好友集合。
3)个性化推荐生成:将步骤1获得的相似用户特征信息和步骤2获得的归一化后的用户好友关系,同时融入到用户特征之中,进一步改进标准概率矩阵分解模型,通过随机梯度下降求解本发明中提出的目标函数,为用户生成个性化的top-N个音乐推荐结果。
以上所述仅为本发明的具体实施例,但本发明的技术特征并不局限于此,任何本领域的技术人员在本发明的领域内,所作的变化或修饰皆涵盖在本发明的专利范围之中。
- 还没有人留言评论。精彩留言会获得点赞!