基于局部密度和single‑pass的核k均值方法与流程
本发明属于数据挖掘方法技术领域,具体涉及一种基于局部密度和single-pass的核k均值方法。
背景技术:
聚类是在一个给定的数据集中识别出分组的过程,将具有相似特征或有关联的数据划分到同一组。传统的k-means算法只能处理有向行和线性可分割的数据,而针对无向行和非线性可分割的数据时,不能得到理想的聚类结果。
kernel k-means算法是一种基于核(kernel)函数的k-means算法,是传统k-means算法的一种扩展,通过非线性核函数的映射,将原始空间的数据映射到高维特征空间中,在高维特征空间中最大程度的减少聚类误差。然而传统kernel k-means算法的时间复杂度为O(n2),随着数据集的增大,计算效率将会呈指数级降低,在对大规模数据的挖掘和处理中存在很大的局限性。
Single-pass方法是数据挖掘中处理实时流数据的常用方法,如:进行话题发现和检测,聚类结果需要不断的更新,其思想是将需要进行聚类的数据按输入顺序依次以流的方式进行处理,每处理一个数据,增量的更新聚类;在更新的过程中,将新来的数据与已有类的中心进行比较,并划分到与其距离最近的类中。
技术实现要素:
本发明的目的是提供一种基于局部密度和single-pass的核k均值方法,解决了传统kernel k-means算法初始中心点不确定及时间复杂度过高的问题。
本发明所采用的技术方案是,基于局部密度和single-pass的核k均值方法,包括如下步骤:
步骤1、确定数据集D,通过局部密度法选取初始类中心点;
步骤2、待步骤1完成后,随机选择一个包含初始中心点M的样本数据集S;
步骤3、待步骤2完成后,应用kernel k-means算法对样本数据集S进行聚类,其输入参数为:样本点S、聚类数目K、核函数H,输出结果为样本S最终聚类的结果,记为
步骤4、待步骤3完成后,使用梯度下降法对∏s中每个类的中心点{M1,M2,M3,……,Mj}进行优化;
步骤5、待步骤4完成后,将数据集D中其余所有的数据点依次按顺序计算与已有所有类中心Mj的距离,并将其划分到最近的类Cj中;
步骤6、待步骤5完成后,输出数据集D最终的聚类结果。
本发明的特征还在于:
步骤1具体按照以下方法实施:
在聚类前,采用局部密度法选取初始类中点,其思想具体如下:
空间中任意一点p和距离AverageDist,以p点为中心,半径为AverageDist的区域为p点的区域,区域内点的个数称为点p基于AverageDist的密度参数,记为density(p,AverageDist),具体表达方式如下;
具体按照以下步骤实施:
步骤1.1、计算数据集D中两两数据点之间的距离;
步骤1.2、经步骤1.1后,计算两两数据点之间的平均距离AverageDist;
步骤1.3、经步骤1.2后,数据集中所有数据点的密度参数density(p,AverageDist),构成一个集合SET;
步骤1.4、经步骤1.3后,将集合SET中密度最大的数据点作为第一个聚类中心点,同时将与该中心点距离小于AverageDist的点及其密度参数从集合SET中删除;
步骤1.5、重复步骤1.3和步骤1.4,直至找到k个类中心为止;
步骤1.6、待步骤1.5完成后,输出k个中心点M={m1,m2,m3,……,mk}。
步骤2具体按照以下方法实施:
从原始数据集D中,通过采样的方式随机选取一个包含初始中心点的样本数据集S,将对大规模数据集的聚类转换为先对小规模数据集的聚类。
步骤4具体按照以下步骤实施:
步骤4.1、求解目标函数J(X)的导数J`(X);
步骤4.2、经步骤4.1后,针对每一个类簇,确定一个初始的出发点
步骤4.3、经步骤4.2后,按梯度的方向不断迭代,寻找下一个近似点:
式(2)中:r=r+1,α表示步长,范围为(0,1);
步骤4.4、重复步骤4.3,直至的值收敛为止;
此时Πs类的中心点为
步骤4.5、待步骤4.4完成后,输出Πs中所有类的中心点{M1,M2,M3,……,Mj}。
本发明的有益效果在于:
1.本发明基于局部密度和single-pass的核k均值方法,在聚类前采用局部密度法选取初始中心点,聚类完成后通过梯度下降法对聚类中心点进一步优化,有效提高了聚类的准确度。
2.本发明基于局部密度和single-pass的核k均值方法,结合single-pass的思想,通过选取样本集的方式降低算法的时间复杂度,提高算法的计算效率。
附图说明
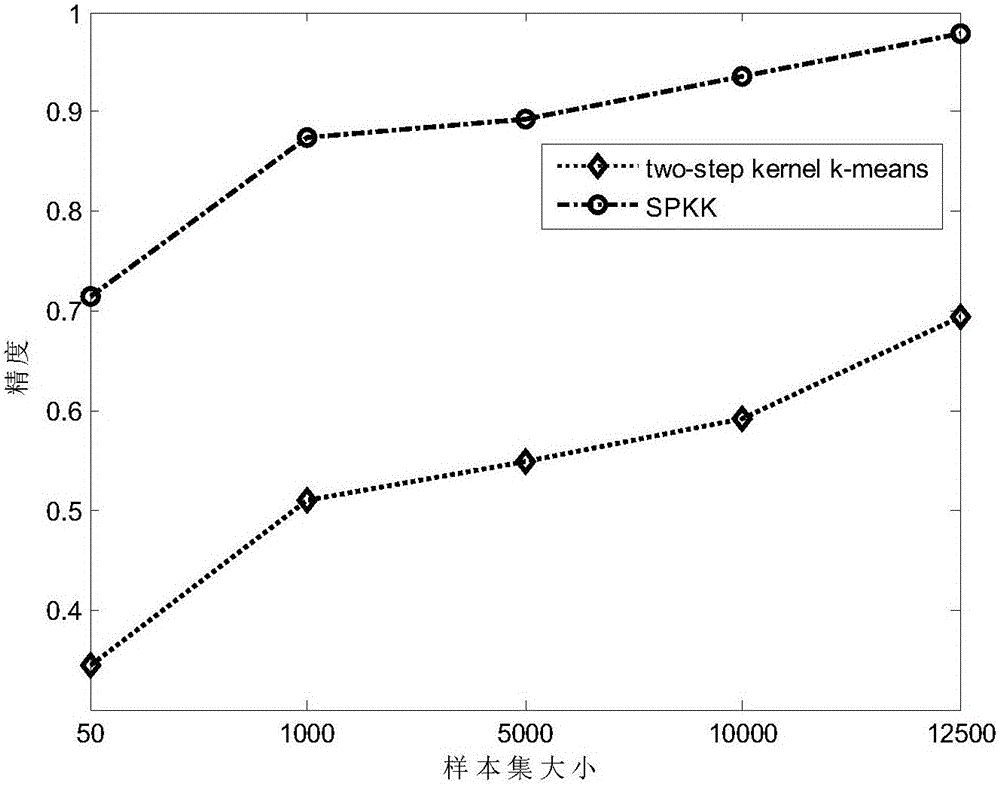
图1是本发明基于局部密度和single-pass的核k均值方法与two-step kernel k-means算法在不同样本集大小下的运行时间结果对比图谱;
图2是本发明基于局部密度和single-pass的核k均值方法与two-step kernel k-means算法在不同样本集大小下的聚类精度结果对比图谱;
图3是本发明基于局部密度和single-pass的核k均值方法与传统kernel k-means算法、two-step kernel k-means算法两种方法,在不同测试数据集下的运行时间结果对比图谱;
图4是本发明基于局部密度和single-pass的核k均值方法与传统kernel k-means算法、two-step kernel k-means算法两种方法,在不同测试数据集下的聚类精度结果对比图谱。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明基于局部密度和single-pass的核k均值方法,具体按照以下步骤实施:
步骤1、确定数据集D,通过局部密度法选取初始类中心点,具体按照以下方法实施:
在聚类前,采用局部密度法选取初始类中点,其思想具体如下:
空间中任意一点p和距离AverageDist(样本间的平均距离),以p点为中心,半径为AverageDist的区域为p点的区域,区域内点的个数称为点p基于AverageDist的密度参数,记为density(p,AverageDist),具体表达方式如下;
具体按照以下步骤实施:
步骤1.1、计算数据集D中两两数据点之间的距离;
步骤1.2、经步骤1.1后,计算两两数据点之间的平均距离AverageDist;
步骤1.3、经步骤1.2后,数据集中所有数据点的密度参数density(p,AverageDist),构成一个集合SET;
步骤1.4、经步骤1.3后,将集合SET中密度最大的数据点作为第一个聚类中心点,同时将与该中心点距离小于AverageDist的点及其密度参数从集合SET中删除;
步骤1.5、重复步骤1.3和步骤1.4,直至找到k个类中心为止;
步骤1.6、待步骤1.5完成后,输出k个中心点M={m1,m2,m3,……,mk}。
步骤2、待步骤1完成后,随机选择一个包含初始中心点M的样本数据集S,具体按照以下方法实施:
从原始数据集D中,通过采样的方式随机选取一个包含初始中心点的样本数据集S,将对大规模数据集的聚类转换为先对小规模数据集的聚类。
步骤3、待步骤2完成后,应用kernel k-means算法对样本数据集S进行聚类,其输入参数为:样本点S、聚类数目K、核函数H,输出结果为样本S最终聚类的结果,记为
步骤4、待步骤3完成后,使用梯度下降法对Πs中每个类的中心点{M1,M2,M3,……,Mj}进行优化,具体按照以下步骤实施:
步骤4.1、求解目标函数J(X)的导数J`(X);
步骤4.2、经步骤4.1后,针对每一个类簇,确定一个初始的出发点
步骤4.3、经步骤4.2后,按梯度的方向不断迭代,寻找下一个近似点:
式(2)中:r=r+1,α表示步长,范围为(0,1);
步骤4.4、重复步骤4.3,直至的值收敛为止;
此时Πs类的中心点为
步骤4.5、待步骤4.4完成后,输出Πs中所有类的中心点{M1,M2,M3,……,Mj}。
步骤5、待步骤4完成后,将数据集D中其余所有的数据点依次按顺序计算与已有所有类中心Mj的距离,并将其划分到最近的类Cj中。
步骤6、待步骤5完成后,输出数据集D最终的聚类结果。
表1是本发明基于局部密度和single-pass的核k均值方法中所使用的测试数据集及其特征,所有的数据集都取自UCI数据库,包含Iris、Pendigits、Letter Image Recognition(LIR)、Shuttle这四个数据集作为测试数据来验证其有效性。
表1测试数据集
如图1和图2所示,展示了使用LIR数据集,通过随机选取不同大小(50、1000、5000、10000、12500)的初始样本集,对two-step kernel k-means算法和本发明基于局部密度和single-pass的核k均值方法(简称SPKK)的运行时间和聚类精度对比图,其结果表明:针对同一数据集LIR,SPKK方法与two-step kernel k-means方法的运行时间和聚类精度都取决于初始样本集的大小,初始样本集越大,运行时间越长,精度越高;同时可以看出SPKK的运行时间比two-step kernel k-means稍长,但是其最终聚类结果的准确性比two-step kernel k-means算法高很多。对于其它不同的数据集,也可以得出相同的结论。
图3和图4是使用Iris、Pendigits、LIR、Shuttle这四个不同的数据集,对kernel k-means、two-step kernel k-means以及本发明方法的运行时间和聚类精度对比图;结果表明,相比传统的kernel k-means算法,本发明基于局部密度和single-pass的核k均值方法在运行时间和聚类精度两个方面都有较大的改善,而two-step kernel k-means算法,虽然其运行时间有所减少,但是聚类精度较差。
传统的kernel k-means算法每次迭代之后类簇的中心是通过簇内所有对象的均值来表示,而并不是真正的中心点,当出现个别分散的数据点时,通过均值所表示的中心点误差将会很大。梯度下降法的作用在于优化聚类中心,针对每一个类,确定一个初始的出发点,按梯度的方向不断迭代,寻找下一个近似点,直到该点的值收敛。
本发明基于局部密度和single-pass的核k均值方法,在进行聚类开始前,通过局部密度法选取高密度且低相似性的类初始中心点;然后通过采样的方式,从原始数据集中随机抽取一个包含初始中心点的样本数据集S,并使用kernel k-means算法对样本数据集S进行聚类,将对大规模数据集的聚类转换为先对小规模数据的聚类,并对聚类结果中的每个类使用梯度下降法进一步优化,确定准确的类中心点;最后将原始数据集中其余的数据按照single-pass的思想依次划分到已有的类中。本发明基于局部密度和single-pass的核k均值方法,解决了传统kernel k-means算法初始中心点不确定及时间复杂度过高的问题。
- 还没有人留言评论。精彩留言会获得点赞!