基于观察者视角定位的AR实现方法及其系统与流程
本发明涉及AR的技术领域,更具体地说是指基于观察者视角定位的AR实现方法及其系统。
背景技术:
VR(即虚拟现实)和AR(即增强现实)作为未来的新型显示手段,最近几年风靡全球,众多企业都在围绕VR以及AR的技术,开发出各种终端显示或提供内容服务。其中,AR技术不仅需要将虚拟场景和真实场景进行图像的完美叠加,还需要保证随着观察者位置和视角的移动,虚拟场景必须和真实场景保持同步运动,因而具有较高的技术难度。
目前AR技术主要有以下两种实现方式:
第一种方式是基于深度识别技术对真实场景进行预先三维扫描和位置提取,并在此基础上进行虚拟物体和场景的设计制作;在实际使用时,实时获取观察者的位置和视角并赋予虚拟像机,根据视点的位置赋予三维虚拟渲染引擎用作三维虚拟物体的位置信息,从而获得真实物理空间与虚拟场景的叠加融合,例如微软的Hololens;
第二种方式是基于图像识别技术对真实三维物体进行预先识别扫描,在实际使用过程中,实时识别真实物体,并针对真实物体做虚拟增强显示,例如青橙视界的0glass眼镜。
上述的两种方式分别存在以下的缺点:第一种方式的缺点一是深度识别的范围有限,4-5米范围内效果最佳,超过10米基本无法识别;二是将微型处理器集成于观察者佩戴的AR眼镜内,因此渲染能力有限,导致场景的精细度、复杂度不够,不能支撑各种动态元素;第二种方式的缺点没有真实场景的三维位置信息,不是对三维的真实场景的增强现实,仅仅针对三维物体的增强现实,应用范围非常有限。
因此,有必要设计一种基于观察者视角定位的AR实现方法,实现对真实场景的大小以及复杂程度无限制,渲染能力高、适用性强,且具有广泛的应用范围。
技术实现要素:
本发明的目的在于克服现有技术的缺陷,提供基于观察者视角定位的AR实现方法及其系统。
为实现上述目的,本发明采用以下技术方案:基于观察者视角定位的AR实现方法,所述方法包括:
获取位于真实场景中的观察者的位置以及姿态,并赋予虚拟相机;
发送所述位置以及所述姿态至渲染中心进行渲染,获取三维虚拟场景;
发送所述三维虚拟场景至所述观察者佩戴的显示设备,与所述真实场景进行叠加后显示;
将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配。
其进一步技术方案为:所述获取位于真实场景中的观察者的位置以及姿态,并赋予虚拟相机的步骤,具体采用光束定位、红外定位以及超声波定位中至少一种定位方式获取位于真实场景中的观察者的位置。
其进一步技术方案为:所述获取位于真实场景中的观察者的位置以及姿态,并赋予虚拟相机的步骤,具体采用陀螺仪姿态定位方式获取位于真实场景中的观察者的姿态。
其进一步技术方案为:所述发送所述位置以及所述姿态至渲染中心进行渲染,获取三维虚拟场景的步骤,包括以下具体步骤:
发送所述位置以及所述姿态至服务器的渲染中心;
接收服务器中的控制端的触发指令,所述渲染中心进行三维虚拟场景的渲染。
其进一步技术方案为:所述将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配的步骤,具体包括以下步骤:
基于所述观察者的视角下,预先测量真实场景中的真实物体的位置以及姿态;
根据测量的所述真实物体的位置以及姿态,调整三维虚拟场景的虚拟物体的位置和姿态。
其进一步技术方案为:所述将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配的步骤,具体是实时调整渲染中心渲染的所述三维虚拟场景的虚拟物体中的位置参数和姿态参数,直至真实场景中的真实物体和三维虚拟场景的虚拟物体匹配。
其进一步技术方案为:所述将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配的步骤之后,还包括使用交互设备在三维虚拟场景中进行交互式操作。
本发明还提供了基于观察者视角定位的AR实现系统,包括获取单元、渲染单元、叠加单元以及匹配单元;
所述获取单元,用于获取位于真实场景中的观察者的位置以及姿态,并赋予虚拟相机;
所述渲染单元,用于发送所述位置以及所述姿态至渲染中心进行渲染,获取三维虚拟场景;
所述叠加单元,用于发送所述三维虚拟场景至所述观察者佩戴的显示设备,与所述真实场景进行叠加后显示;
所述匹配单元,用于将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配。
其进一步技术方案为:所述渲染单元包括发送模块以及接收渲染模块;
所述发送模块,用于发送所述位置以及所述姿态至服务器的渲染中心;
所述接收渲染模块,用于接收服务器中的控制端的触发指令,所述渲染中心进行三维虚拟场景的渲染。
其进一步技术方案为:所述匹配单元包括测量模块以及调整模块;
所述测量模块,用于基于所述观察者的视角下,预先测量真实场景中的真实物体的位置以及姿态;
所述调整模块,用于根据测量的所述真实物体的位置以及姿态,调整三维虚拟场景的虚拟物体的位置和姿态。
本发明与现有技术相比的有益效果是:本发明的基于观察者视角定位的AR实现方法,通过获取位于真实场景中的观察者的位置与姿态,并将交互式设备的位置、姿态及触发信号数据赋予渲染中心,作触发信号进行各种动画触发渲染,依据此位置与此姿态,采用位于服务器中的渲染中心进行三维虚拟场景的渲染,三维虚拟场景发送至观察者佩戴的AR眼镜上和真实场景进行叠加显示,并对显示内容进行调整匹配,即可实现将真实世界和虚拟世界融合显示,采用服务器中的渲染中心进行渲染,将渲染过程集成在服务器内,实现对真实场景的大小以及复杂程度无限制,渲染能力高、适用性强,且具有广泛的应用范围。
下面结合附图和具体实施例对本发明作进一步描述。
附图说明
图1为本发明具体实施例提供的基于观察者视角定位的AR实现方法的流程图;
图2为本发明具体实施例提供的发送位置以及姿态至渲染中心进行渲染并获取三维虚拟场景的具体流程图;
图3为本发明具体实施例提供的将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配的具体流程图;
图4为本发明具体实施例提供的基于观察者视角定位的AR实现系统的结构框图;
图5为本发明具体实施例提供的渲染单元的结构框图;
图6为本发明具体实施例提供的匹配单元的结构框图。
具体实施方式
为了更充分理解本发明的技术内容,下面结合具体实施例对本发明的技术方案进一步介绍和说明,但不局限于此。
如图1~6所示的具体实施例,本实施例提供的基于观察者视角定位的AR实现方法,可以运用在任何场景内,实现对真实场景的大小以及复杂程度无限制,渲染能力高、适用性强,且具有广泛的应用范围。
如图1所示,基于观察者视角定位的AR实现方法,该方法包括:
S1、获取位于真实场景中的观察者的位置以及姿态,并赋予虚拟相机;
S2、发送所述位置以及所述姿态至渲染中心进行渲染,获取三维虚拟场景;
S3、发送所述三维虚拟场景至所述观察者佩戴的显示设备,与所述真实场景进行叠加后显示;
S4、将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配。
在本实施例中,在某一真实场景中首次使用才需要进行上述的S1至S4步骤,或者,于其他实施例,在某一真实场景中每次使用都需要进行上述的S1至S4步骤,具体的依据实际情况而定。
上述的S1步骤,获取位于真实场景中的观察者的位置以及姿态,并赋予虚拟相机的步骤,这里主要获取观察者的位置和观察者的姿态,其中,具体采用光束定位、红外定位以及超声波定位中至少一种定位方式获取位于真实场景中的观察者的位置。
上述的光束定位是通过在定位的空间内搭建发射激光的定位光塔,对定位空间进行激光扫射,在待定位物体上设置多个光信号接收器,并在接收端对数据进行运算处理,直接获取三维位置,比如激光定位。
上述的获取位于真实场景中观察者的姿态,并赋予虚拟相机,主要是为了获取观察者的视角,这里具体采用陀螺仪姿态定位方式获取位于真实场景中的观察者的姿态。
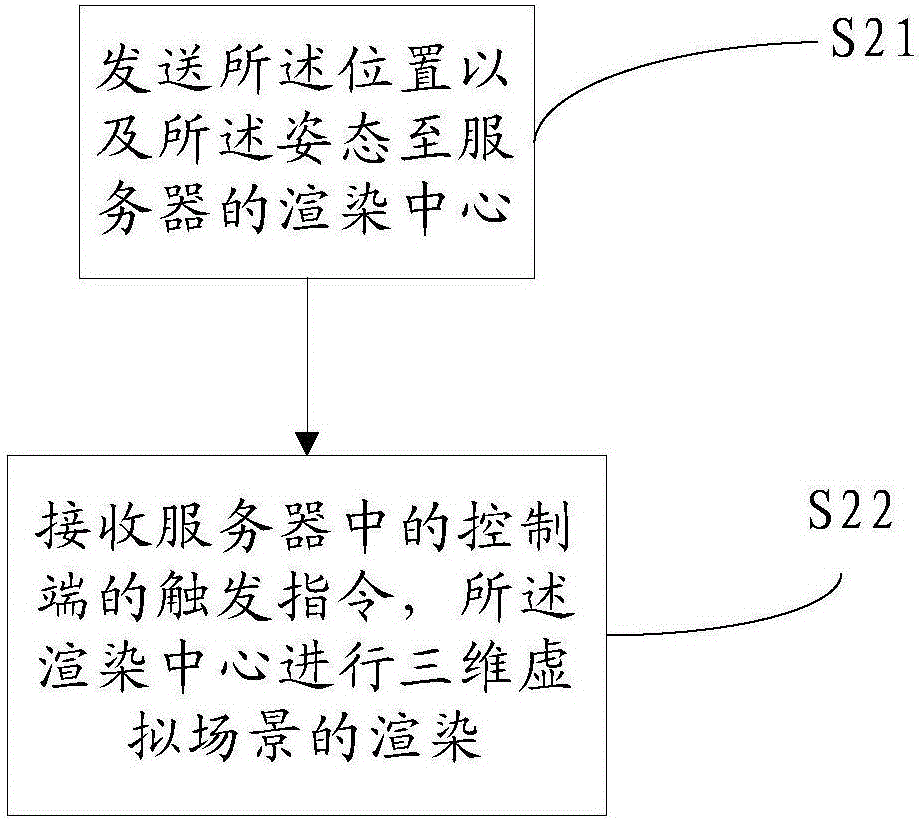
更进一步的,上述的S2步骤,发送所述位置以及所述姿态至渲染中心进行渲染,获取三维虚拟场景的步骤,包括以下具体步骤:
S21、发送所述位置以及所述姿态至服务器的渲染中心;
S22、接收服务器中的控制端的触发指令,所述渲染中心进行三维虚拟场景的渲染。
上述的S21步骤,发送所述位置以及所述姿态至服务器的渲染中心的步骤,渲染中心是一个渲染引擎,其单独设置在服务器,并不集成在观察者所佩戴的所述观察者佩戴的显示设备中,这样由于渲染中心可以采用较高渲染能力的引擎,因此可保证虚拟场景的任意复杂度、精细度,可实现各种复杂的动画及特效。
上述的S22步骤,接收服务器中的控制端的触发指令,所述渲染中心进行三维虚拟场景的渲染,这里的渲染主要是根据观察者的视角以及位置赋予虚拟相机,由虚拟相机进行观察者视角和位置所获取的真实场景进行记录,并以此对三维虚拟场景进行渲染。
上述S3的步骤,发送所述三维虚拟场景至所述观察者佩戴的显示设备,与所述真实场景进行叠加后显示的步骤,这里是将三维虚拟场景由所述观察者佩戴的显示设备呈现出来,与真实场景进行简单的叠加并显示。这里的发送三维虚拟场景是将虚拟的三维场景的视频信号传过来,现在一般的可穿戴设备是有线传输视频信号,也可以无线传输视频信号。
在本实施例中,上述的S4步骤,将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配的步骤,具体包括以下步骤:
S41、基于所述观察者的视角下,预先测量真实场景中的真实物体的位置以及姿态;
S42、根据测量的所述真实物体的位置以及姿态,调整三维虚拟场景的虚拟物体的位置和姿态。
上述的S41步骤,基于所述观察者的视角下,预先测量真实场景中的真实物体的位置以及姿态,这里主要是先获取观察者视角下的真实物体在真实场景中的具体位置和姿态,在生成三维虚拟场景后根据获取的上述具体位置和姿态调整三维虚拟场景的虚拟物体的位置和姿态,一步到位,调整和匹配的速度较快。
另外,于其他实施例,上述的S4步骤,将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配的步骤,具体是实时调整渲染中心渲染的所述三维虚拟场景的虚拟物体中的位置参数和姿态参数,直至真实场景中的真实物体和三维虚拟场景的虚拟物体匹配。此处是依据叠加显示后的效果来调整,通过改变所述三维虚拟场景的虚拟物体中的位置参数和姿态参数,达到匹配的效果。
无论是上述的哪一种匹配方式,都是基于三维场景的位置和视角信息实现真实物体的识别及其与虚拟物体的匹配,适用性强,且具有广泛的应用范围。
在本实施例中,上述的S4步骤,所述将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配的步骤之后,还包括S5、使用交互设备在三维虚拟场景中进行交互式操作。这里的交互设备包括任意交互设备例如交互式手柄、手套、手环等,通过将交互式手柄的位置、姿态赋予渲染中心用作触发信号,进行各种动画触发渲染,从而实现各种交互式操作。
上述的基于观察者视角定位的AR实现方法,通过获取位于真实场景中的观察者的位置与姿态,并将交互式设备的位置、姿态及触发信号数据赋予渲染中心,作触发信号进行各种动画触发渲染,依据此位置与此姿态,采用位于服务器中的渲染中心进行三维虚拟场景的渲染,三维虚拟场景发送至所述观察者佩戴的显示设备上和真实场景进行叠加显示,并对显示内容进行调整匹配,即可实现将真实世界和虚拟世界融合显示,采用服务器中的渲染中心进行渲染,将渲染过程集成在服务器内,实现对真实场景的大小以及复杂程度无限制,渲染能力高、适用性强,且具有广泛的应用范围。
上述的显示设备包括AR眼镜、头盔,移动终端中的至少一种,于其他实施例,还包括其他可以显示三维虚拟场景的电子产品。
当显示设备为移动终端时,通过手机等移动终端具有拍摄功能的设备看,真实的场景是通过手机等移动终端的摄像头拍摄,再和虚拟叠加,对真实拍摄的场景做延时,从而可以拍摄的真实前景和渲染的虚拟部分同步。
如图4所示,基于观察者视角定位的AR实现系统,包括获取单元10、渲染单元20、叠加单元30以及匹配单元40;
获取单元10,用于获取位于真实场景中的观察者的位置以及姿态,并赋予虚拟相机;
渲染单元20,用于发送所述位置以及所述姿态至渲染中心进行渲染,获取三维虚拟场景;
叠加单元30,用于发送所述三维虚拟场景至所述观察者佩戴的显示设备,与所述真实场景进行叠加后显示;
匹配单元40,用于将真实场景中的真实物体和三维虚拟场景的虚拟物体进行匹配。
上述的获取单元10具体采用光束定位、红外定位以及超声波定位中至少一种定位方式获取位于真实场景中的观察者的位置,采用陀螺仪姿态定位方式获取位于真实场景中的观察者的姿态。
上述的光束定位是通过在定位的空间内搭建发射激光的定位光塔,对定位空间进行激光扫射,在待定位物体上设置多个光信号接收器,并在接收端对数据进行运算处理,直接获取三维位置,比如激光定位。
渲染单元20包括发送模块21以及接收渲染模块22;
发送模块21,用于发送所述位置以及所述姿态至服务器的渲染中心;
接收渲染模块22,用于接收服务器中的控制端的触发指令,所述渲染中心进行三维虚拟场景的渲染。
发送模块21中提及的渲染中心是一个渲染引擎,其单独设置在服务器,并不集成在观察者所佩戴的所述观察者佩戴的显示设备中,这样由于渲染中心可以采用较高渲染能力的引擎,因此可保证虚拟场景的任意复杂度、精细度,可实现各种复杂的动画及特效。
接收渲染模块22的渲染主要是根据观察者的视角以及位置赋予虚拟相机,由虚拟相机进行观察者视角和位置所获取的真实场景进行记录,并以此对三维虚拟场景进行渲染。
叠加单元30是将三维虚拟场景由所述观察者佩戴的显示设备呈现出来,与真实场景进行简单的叠加并显示。
在本实施例中,匹配单元40包括测量模块41以及调整模块42;
测量模块41,用于基于所述观察者的视角下,预先测量真实场景中的真实物体的位置以及姿态;
调整模块42,用于根据测量的所述真实物体的位置以及姿态,调整三维虚拟场景的虚拟物体的位置和姿态。
测量模块41主要是先获取观察者视角下的真实物体在真实场景中的具体位置和姿态,在生成三维虚拟场景后根据获取的上述具体位置和姿态调整三维虚拟场景的虚拟物体的位置和姿态,一步到位,调整和匹配的速度较快。
于其他实施例,上述的匹配单元40是实时调整渲染中心渲染的所述三维虚拟场景的虚拟物体中的位置参数和姿态参数,直至真实场景中的真实物体和三维虚拟场景的虚拟物体匹配。此处是依据叠加显示后的效果来调整,通过改变所述三维虚拟场景的虚拟物体中的位置参数和姿态参数,达到匹配的效果。
上述的匹配单元40都是基于三维场景的位置和视角信息实现真实物体的识别及其与虚拟物体的匹配,适用性强,且具有广泛的应用范围。
在本实施例中,基于观察者视角定位的AR实现系统还包括操作单元50,操作单元50用于使用交互设备在三维虚拟场景中进行交互式操作,这里的交互设备包括任意交互设备例如交互式手柄、手套、手环等,通过将交互式手柄的位置、姿态赋予渲染中心用作触发信号,进行各种动画触发渲染,从而实现各种交互式操作。
上述的基于观察者视角定位的AR实现系统,通过获取单元10获取位于真实场景中的观察者的位置与姿态,并将交互式设备的位置、姿态及触发信号数据赋予渲染中心,作触发信号进行各种动画触发渲染,渲染单元20依据此位置与此姿态,采用位于服务器中的渲染中心进行三维虚拟场景的渲染,三维虚拟场景发送至所述观察者佩戴的显示设备上,叠加单元30将三维虚拟场景和真实场景进行叠加显示,并匹配单元40对显示内容进行调整匹配,即可实现将真实世界和虚拟世界融合显示,采用服务器中的渲染中心进行渲染,将渲染过程集成在服务器内,实现对真实场景的大小以及复杂程度无限制,渲染能力高、适用性强,且具有广泛的应用范围。
上述的显示设备包括AR眼镜、头盔,移动终端中的至少一种,于其他实施例,还包括其他可以显示三维虚拟场景的电子产品。
上述仅以实施例来进一步说明本发明的技术内容,以便于读者更容易理解,但不代表本发明的实施方式仅限于此,任何依本发明所做的技术延伸或再创造,均受本发明的保护。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!