一种基于蚁群优化的网格分割方法与流程
本发明属于图形学和几何数字处理技术领域,具体涉及一种基于蚁群优化的网格分割方法。
背景技术:
近十多年来,三维数据捕获设备及其技术的进步推动了计算机视觉、医学成像、基于图像建模等技术向纵深发展,产生了许多复杂的三维模型,使得基于网格模型(特别是三角网格模型)的几何处理等相关技术成为近年来计算机辅助设计(CAD)和图形学的重要研究热点。
原始三维网格模型缺少足够的结构特征和语义信息,对原始三维网格模型的理解成为许多几何处理问题亟待解决的重要问题,网格分割通过按照一定的分割准则将原始三维模型分解为不同的部件或曲面片,有助于相关几何处理问题(如曲面压缩、网格重构、参数化、纹理映射、模型检索)的有效解决,实际上正是来自纹理映射、参数化、网格动画、网格变形等问题的需求使网格分割作为一个重要的几何处理问题开始引起人们的重视。
在计算机视觉中,将模型分割为不同部分,有助于进行模型的特征识别,例如将人脸三维模型通过分割识别出脸颊、鼻子、眼睛等。在网格参数化和纹理映射中,通过将模型分割为一系列平坦的区域,可以减少参数化和纹理映射的扭曲变形,提高参数化和纹理映射的质量。
在现有技术中,有些方法需要人工交互,有些需要方法较为复杂,有些方法需要复杂的数据结构。本发明方法较为简单,不需要复杂的数据结构,可以全自动化,而且由于蚁群算法的特点,可以进行并行处理。
蚁群优化(ant colony optimization,ACO)的灵感来源于蚂蚁搜索食物的过程。蚂蚁们利用在走过的路径上遗留和探测外激素(Stigmergy)这种间接的正反馈机制来寻找巢穴到食物源的最短路径。这样,一个普通的组合优化问题就被转变成了一个约束最短路径问题。蚁群优化最初是为研究旅行商问题(TSP)而被提出的,后来被使用到许多工程问题上。
技术实现要素:
发明目的:本发明针对上述现有技术存在的问题做出改进,即本发明公开了一种基于蚁群优化的网格分割方法。在本发明中,将待分割网格的每个网格视为一个蚂蚁,通过蚁群优化迭代将每个网格的标签不断更新。初始化时,所有的网格先赋予一个背景标签。然后随机产生种子点,每一个种子点赋予一个不同于背景标签且唯一的标签,而对于每一个种子点,其邻域周围的网格点赋予和种子点一样的标签。随着蚁群优化的迭代,种子点的标签向外扩散,而标签更新是在满足分割标准的条件下通过蚁群优化的更新机制进行,直到满足迭代标准。蚁群优化完成后,进行区域合并,将较小的区域合并成较大区域,最终完成分割。
技术方案:一种基于蚁群优化的网格分割方法,包括以下步骤:
(1)输入待分割三维网格数据和参数,然后进入步骤(2);
(2)计算网格属性,然后进入步骤(3);
(3)数据预处理,然后进入步骤(4);
(4)在待分割网格中选择种子点,然后进入步骤(5);
(5)进行网格标签初始化,然后进入步骤(6);
(6)进行蚁群优化迭代直到满足迭代标准,然后进入步骤(7);
(7)区域合并,然后进入步骤(8);
(8)输出分割结果。
进一步,步骤(1)中输入的待分割网格数据包括三维网格的几何坐标信息和拓扑信息。
进一步,步骤(2)中网格属性指形状直径函数SDF(Shape Diameter Function),其的计算过程如下:
(21)、对于表面网格上的一个顶点,作一个以该顶点为圆锥顶点、顶点法向量的逆方向为中心线方向的圆锥体;
(22)从该顶点上引出若干条圆锥体范围内的射线交于表面网格,通过构建八叉树结构来计算与网格相交的射线;
(23)去除与顶点法线方向相同的射线,取剩下长度在所有射线长度中位数标准差之内的射线作加权平均,即得到该顶点的SDF值;
其中:一个射线的长度指该射线的顶点和射线法向量逆方向交于表面网格之间的距离;
射线长度中位数指顶点法向量逆方向为中心线方向的圆锥体内所有射线长度的中位数;
对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数;
权值是射线到圆锥中心线的夹角的反角。
进一步,步骤(3)数据预处理包括以下步骤
(31)准备每个网格的辅助数据结构;
(32)计算每个网格的邻域;
对每一个网格顶点,通过搜索输入网格的数据,寻找与该顶点直接相联系的网格顶点,然后将这些网格顶点作为该顶点的领域放到辅助数据结构中;
(33)将SDF归一化
将SDF换算成0到1之间的数值,换算公式如下:
其中,
SDFold为换算前的数值,
SDFnew为换算后的数值,
SDFmin换算前所有网格SDF的最小值,
SDFmax换算前所有网格SDF的最大值。
进一步,步骤(4)中采取随机的方法选择种子点。
进一步,步骤(5)网格标签初始化包括如下步骤:
(51)所有的网格先赋予一个背景标签;
(52)然后对于每一个种子点赋予一个唯一的标签,周围的网格点赋予和种子点一样的标签。
进一步,步骤(6)包括:
(61)对于每次迭代,每个网格从Γ个种子点标签中找到最佳的标签,如果找到最佳的标签和上一次的最佳的标签不一样,网格的标签进行更新;
(62)更新每个网格中每个标签的残留信息浓度。
更进一步,步骤(61)找到最佳的标签参照如下公式:
M=argmaxu{p(u)},u∈Γ
其中,p(u)是一个种子点标签u的转移概率,其计算公式如下:
其中:
τ(u)表示该网格采用某一候补标签u的残留信息浓度;
η(u)表示表示该网格采用某一候补标签u的启发值;
τ(v)表示该网格采用某一候补标签v的残留信息浓度;
η(v)表示表示该网格采用某一候补标签v的启发值;
α和β是控制τ(u)和η(u)相对平衡的两个因子系数;
进一步地,η(u)的计算公式如下:
ε(u)是网格对应于u标签的特征值。
更进一步,步骤(61)中网格特征值的计算就是计算该网格邻域内网格点SDF的标准差,具体计算公式如下:
其中,
SDFi为该网格邻域内对应于u标签的第i个网格点的SDF值,
μSDF为该网格邻域内对应于u标签的SDF平均值,
N为该网格邻域内对应于u标签的网格点个数。
进一步,步骤(62)中,每次迭代后,每个网格中每个标签的残留信息浓度在满足更新的条件下被更新,更新的条件如下:
(a)它的邻域含有高于预先设置的阈值个数的非背景标签;
(b)它的邻域中至少有一个种子点标签满足分割条件;
设τ(u)第一次迭代前的初始值为τ0,并在每次迭代结束时被更新,更新公式如下:
τ(u)←ρ·τ(u)+γ·Δτ(u)
其中,
ρ为遗传系数,它控制网格当前残留信息浓度对下次迭代的影响程度,该值继承了之前迭代的残留信息浓度;
Δτ(u)为残留信息浓度增量的空间约束分量,其计算公式如下:
其中,
b为假设当前的网格,
b’为邻域中符合分割条件的网格之一,
NS为邻域大小。
更进一步,分割条件描述如下:
对于一个待更新蚂蚁b,其目前的最佳标签为M,假设其邻域含有若干个非背景标签。对于其中一个候选标签u,它的分割条件为:
并且
Ω(b,M)指网格点b邻域中标签为M的网格点集合,
指网格点b邻域中候选标签为u的所有网格点集合;
STD(SDF[Ω(b,M)])指网格点b邻域中标签为M的网格点集合的SDF值的标准差。
进一步,步骤(61)中迭代标准为网格标签更新的比例小于阈值。
进一步,步骤(7)中,蚁群迭代完成后,相邻的区域在满足分割条件的情况下进行合并。
有益效果:本发明公开的一种基于蚁群优化的网格分割方法具有以下有益效果:
在现有技术中,有些方法需要人工交互,有些需要方法较为复杂,有些方法需要复杂的数据结构。本发明方法较为简单,不需要复杂的数据结构,可以全自动化,而且由于蚁群算法的特点,可以进行并行处理。
附图说明
图1为网格标签初始化的示意图;
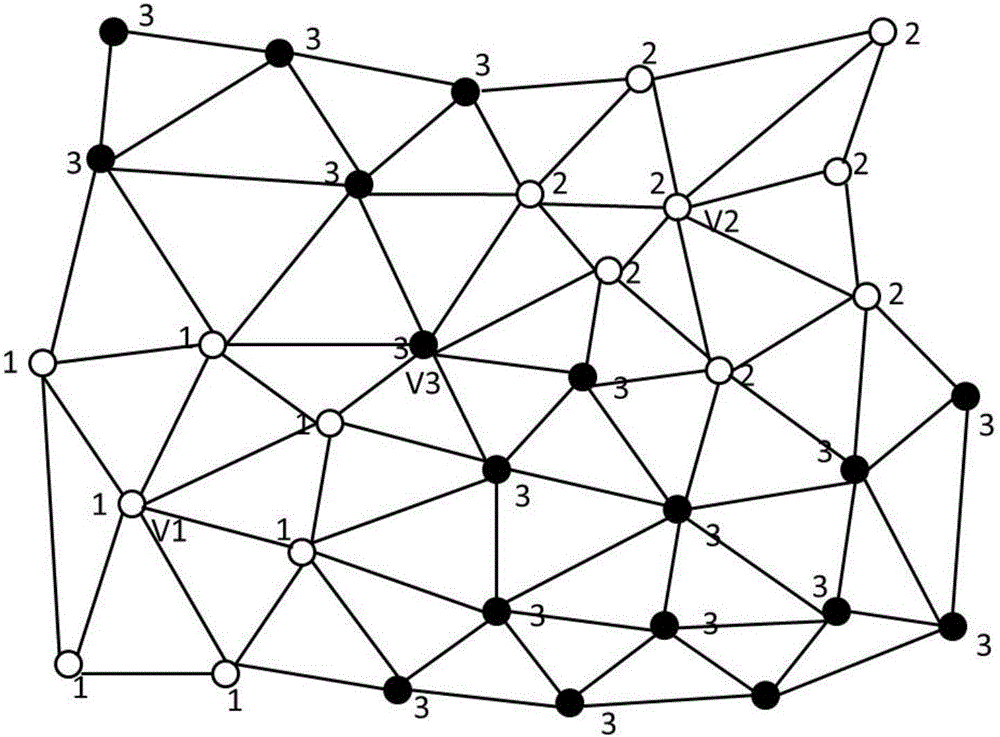
图2为网格邻域示意图,其中Q为V3的邻域。
具体实施方式:
下面对本发明的具体实施方式详细说明。
一种基于蚁群优化的网格分割方法,包括以下步骤:
(1)输入待分割三维网格数据和参数,然后进入步骤(2);
(2)计算网格属性,然后进入步骤(3);
(3)数据预处理,然后进入步骤(4);
(4)在待分割网格中选择种子点,然后进入步骤(5);
(5)如图1所示,进行网格标签初始化,然后进入步骤(6);
(6)进行蚁群优化迭代直到满足迭代标准,然后进入步骤(7);
(7)区域合并,然后进入步骤(8);
(8)输出分割结果。
进一步,步骤(1)中输入的待分割网格数据包括三维网格的几何坐标信息和拓扑信息。
进一步,步骤(2)中网格属性指形状直径函数SDF(Shape Diameter Function),其的计算过程如下:
(21)、对于表面网格上的一个顶点,作一个以该顶点为圆锥顶点、顶点法向量的逆方向为中心线方向的圆锥体;
(22)从该顶点上引出若干条圆锥体范围内的射线交于表面网格,通过构建八叉树结构来计算与网格相交的射线;
(23)去除与顶点法线方向相同的射线,取剩下长度在所有射线长度中位数标准差之内的射线作加权平均,即得到该顶点的SDF值;
其中:一个射线的长度指该射线的顶点和射线法向量逆方向交于表面网格之间的距离;
射线长度中位数指顶点法向量逆方向为中心线方向的圆锥体内所有射线长度的中位数;
对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数;
权值是射线到圆锥中心线的夹角的反角。
进一步,步骤(3)数据预处理包括以下步骤
(31)准备每个网格的辅助数据结构;
(32)计算每个网格的邻域;
如图2所示,对每一个网格顶点,通过搜索输入网格的数据,寻找与该顶点直接相联系的网格顶点,然后将这些网格顶点作为该顶点的领域放到辅助数据结构中;如图2中V3标签为3的邻域网格点4个,而标签为2的所有网格点8个。
(33)将SDF归一化
将SDF换算成0到1之间的数值,换算公式如下:
其中,
SDFold为换算前的数值,
SDFnew为换算后的数值,
SDFmin换算前所有网格SDF的最小值,
SDFmax换算前所有网格SDF的最大值。
进一步,步骤(4)中采取随机的方法选择种子点。
进一步,步骤(5)网格标签初始化包括如下步骤:
(51)所有的网格先赋予一个背景标签;
(52)然后对于每一个种子点赋予一个唯一的标签,周围的网格点赋予和种子点一样的标签。
进一步,步骤(6)包括:
(61)对于每次迭代,每个网格从Γ个种子点标签中找到最佳的标签,如果找到最佳的标签和上一次的最佳的标签不一样,网格的标签进行更新;
(62)更新每个网格中每个标签的残留信息浓度。
更进一步,步骤(61)找到最佳的标签参照如下公式:
M=argmaxu{p(u)},u∈Γ
其中,p(u)是一个种子点标签u的转移概率,其计算公式如下:
其中:
τ(u)表示该网格采用某一候补标签u的残留信息浓度;
η(u)表示表示该网格采用某一候补标签u的启发值;
τ(v)表示该网格采用某一候补标签v的残留信息浓度;
η(v)表示表示该网格采用某一候补标签v的启发值;
α和β是控制τ(u)和η(u)相对平衡的两个因子系数;
进一步地,η(u)的计算公式如下:
ε(u)是网格对应于u标签的特征值。
更进一步,步骤(61)中网格特征值的计算就是计算该网格邻域内网格点SDF的标准差,具体计算公式如下:
其中,
SDFi为该网格邻域内对应于u标签的第i个网格点的SDF值,
μSDF为该网格邻域内对应于u标签的SDF平均值,
N为该网格邻域内对应于u标签的网格点个数。
进一步,步骤(62)中,每次迭代后,每个网格中每个标签的残留信息浓度在满足更新的条件下被更新,更新的条件如下:
(a)它的邻域含有高于预先设置的阈值个数的非背景标签;
(b)它的邻域中至少有一个种子点标签满足分割条件;
设τ(u)第一次迭代前的初始值为τ0,并在每次迭代结束时被更新,更新公式如下:
τ(u)←ρ·τ(u)+γ·Δτ(u)
其中,
ρ为遗传系数,它控制网格当前残留信息浓度对下次迭代的影响程度,该值继承了之前迭代的残留信息浓度;
Δτ(u)为残留信息浓度增量的空间约束分量,其计算公式如下:
其中,
b为假设当前的网格,
b’为邻域中符合分割条件的网格之一,
NS为邻域大小。
更进一步,分割条件描述如下:
对于一个待更新蚂蚁b,其目前的最佳标签为M,假设其邻域含有若干个非背景标签。对于其中一个候选标签u,它的分割条件为:
并且
Ω(b,M)指网格点b邻域中标签为M的网格点集合,
指网格点b邻域中候选标签为u的所有网格点集合;
STD(SDF[Ω(b,M)])指网格点b邻域中标签为M的网格点集合的SDF值的标准差。
进一步,步骤(61)中迭代标准为网格标签更新的比例小于阈值。
进一步,步骤(7)中,蚁群迭代完成后,相邻的区域在满足分割条件的情况下进行合并。
上面对本发明的实施方式做了详细说明。但是本发明并不限于上述实施方式,在所属技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!