一种用于电网WAMS系统的时序数据存储方法与流程
本发明属于电网广域监测及时序数据处理
技术领域:
,具体是涉及一种用于电网WAMS系统的时序数据存储方法。
背景技术:
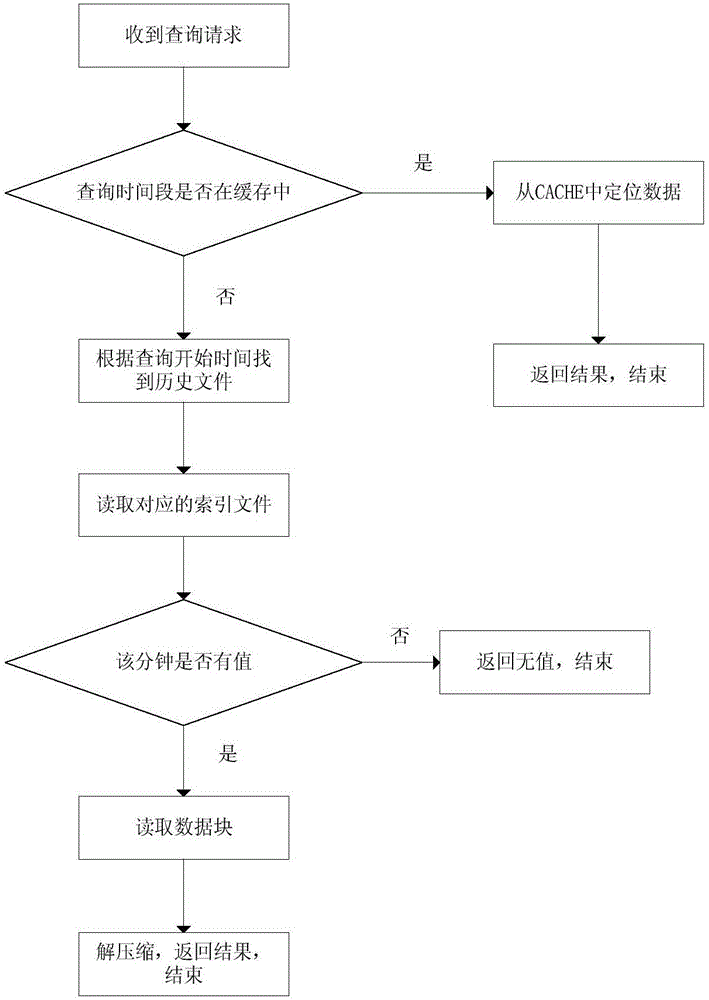
:电网广域监测系统(WideAreaMeasurementSystem,简称WAMS系统),通过布局全网关键测点的同步相角测量单元(PMU),实现对电网主要数据的实时高速率采集,并将采集的数据存储在广域监测主站系统中的时序数据库中,从而提供对电网正常运行与事故扰动情况下的实时监测、分析计算、故障繁衍等。目前WAMS系统发展的主要趋势为:(1)监测节点数量越来越多,由早期的几千测点已扩展至几万点甚至十几万点;(2)采集频率越来越高,目前已支持到最高每秒100帧的采集频率,并且采集频率随着电网负荷的变化可转变;(3)历史数据量越来越大,时序库中一般保存的历史数据都是TB级,对业务的性能冲击越来越大。WAMS系统的这些特性,对系统中时序库的性能、容量等提出了更高的要求。技术实现要素:发明目的:为了克服现有技术中存在的不足,本发明提供一种用于电网WAMS系统的时序数据存储方法,该存储方法具备较高的时序数据写入、查询性能,且性能不会因数据规模扩展而降低。技术方案:为实现上述目的,本发明的一种用于电网WAMS系统的时序数据存储方法,提供测点ID和时序数据结合的存储模型、缓存和文件结合的双层存储架构、按小时独立存储的文件格式以及文件偏移量索引机制;其中,测点ID和时序数据结合的存储模型:存储模型结构为:<id,timestamp,<value1,value2,…,valuen>>,其中id表示该段数据对应的测点ID号;timestamp表示该段数据对应的时间标签,即对应的秒数;value1至valuen表示ID号为id的测点在第timestamp秒的n条数据;缓存和文件结合的双层存储架构:缓存结构:在计算机内存中预分配的一段物理内存内,采用二维数组形式,其中一个维度表示测点ID,另外一个维度表示最新1分钟的60秒,存储所有测点最新1分钟的数据,二维数组中的每个存储单元存储单个测点1秒中的n条数据;文件结构:在文件中存储所有测点1个小时的数据,文件中每个存储单元存储单个测点1分钟的压缩数据块;按小时独立存储的文件格式:设置若干个数据文件,每个数据文件用于存储所有测点1个小时的数据,不同文件中数据时标互相不重复;文件偏移量索引机制:为每个数据文件生成一个索引文件,即每个小时的数据均存在对应的索引文件,索引文件采用二维数组结构,其中一个维度表示测点ID,另一个维度表示每个小时的60分钟,二维数组中的每个单元存储一个偏移量,该偏移量表示对应测点ID在60分钟中某分钟的数据块;所述方法包括数据写入和数据查询两个阶段,所述数据写入阶段包括以下步骤:S11接收测点最新1分钟中第i秒钟的时序数据,i=(0,2,…,59);S12根据测点ID和第i秒钟在缓存结构中找到接收数据缓存位置;S13将接收到的时序数据复制到对应缓存位置中;S14判断该测点数据缓存时间是否超过1分钟,如果是则进入S15,否则结束;S15将缓存结构中该测点最新1分钟内时序数据压缩,形成压缩数据块;S16根据测点ID和最新1分钟时间在文件结构中找到写入位置;S17将该测点最新1分钟内时序数据压缩数据块写入到所述步骤S16中写入位置中;S18将所述步骤S16中写入位置记录到该数据文件对应的索引文件中。进一步地,所述数据查询阶段包括以下步骤:S21收到查询请求,查询请求包括测点ID信息和查询时间段信息;S22判断查询时间段是否在缓存中,如果是则进入S23,如果不是则进入S24;S23根据查询时间段从缓存中定位数据,返回数据结果,结束;S24根据查询开始时间找到历史数据文件,读取该历史数据文件对应的索引文件;S25在索引文件中查询该测点在该时间段显示的分钟时间是否有值,如果没有值则返回无值结束,如果有值则在历史数据文件中根据测点ID信息和查询时间段信息读取数据块;S26将读取的数据块解压缩,返回数据结果,结束。有益效果:本发明与现有技术比较,具有的优点是:(1)通过缓存与文件结合的双存储架构,并使用测点ID和时序数据结合的存储模型,以及提供的文件偏移量索引,提升高频时序数据的存储效率以及历史数据的查询效率;(2)通过将每个小时的历史数据分文件独立存储,解决历史数据累计后写入和查询效率下降问题。附图说明图1是数据写入方法流程图。图2是数据查询方法流程图具体实施方式下面结合附图对本发明作更进一步的说明。本发明针对电网WAMS系统中时序数据的特征,设计一种满足于智能电网WAMS场景的时序大数据快速加载、查询,以及高可靠的存储方法。一种用于电网WAMS系统的时序数据存储方法,提供了(1)测点ID和时序数据结合的存储模型;(2)缓存和文件结合的双层存储架构;(3)按小时独立存储的文件格式;(4)文件偏移量索引机制;测点ID和时序数据结合的存储模型:电网WAMS系统中时序数据主要特性为:数据依托于测点存在,每个测点独立产生自己的时序数据;数据为周期性产生,且所有测点数据产生周期一致;典型WAMS系统中数据产生频率为每秒50条数据,这里成为此频率为“帧数”,即每秒50帧数据。根据时序数据的特性,本方法采用测点ID和时序数据结合的存储模型,存储接模型结构为:<id,timestamp,<value1,value2,…,valuen>>,其中,id表示该段数据对应的测点ID号;timestamp表示该段数据对应的时间标签,即对应的秒数;value1至valuen表示ID号为id的测点在第timestamp秒的n条数据;为了提升时序数据的存储效率,本方法采用基于缓存和文件结合的双层存储架构,其中缓存为计算机内存中预分配的一段物理内存:缓存结构:采用二维数组形式,其中一个维度表示测点ID,另一个维度表示最新1分钟(1分钟等于60秒)各个秒数,用于存储所有测点最新1分钟的数据,二维数组中的每个单元存储单个测点1秒中的n条数据,即单个测点最新1分钟内某秒数的n条数据,该秒数为1~60的自然数;缓存结构如表1所示:测点ID0秒1秒2秒……59秒1valuel-valuenvaluel-valuenvaluel-valuen……valuel-valuen2valuel-valuenvaluel-valuenvaluel-valuen……valuel-valuen3valuel-valuenvaluel-valuenvaluel-valuen……valuel-valuen4valuel-valuenvaluel-valuenvaluel-valuen……valuel-valuen表1如表1所示,包括4个测点,分别为:ID为1的测点、ID为2的测点、ID为3的测点和ID为4的测点,对4个测点的最新1分钟的数据按秒数分别进行存储到缓存结构中,将最新1分钟(从0秒到59秒)的测点数据存储在对应位置中,例如,对于ID为1的测点在0秒时的数据为value1至valuen,同样,对于ID为4的测点在59秒的数据为value1至valuen,各个侧单按照数据产生频率独立产生自己的时序数据,并存储在缓存结构的相应位置中;文件结构:在文件中存储所有测点1个小时的数据,文件中每个存储单元存储单个测点1分钟的压缩数据块,即将如表1所示的缓存的二维数组的一行数据进行压缩存储形成的数据块存储到文件单个存储单元中;文件结构如表2所示,表2表2中,对于4个测点(ID为1的测点、ID为2的测点、ID为3的测点和ID为4的测点),将每个测点1个小时内(从0分钟到59分钟)产生的数据按分钟分别存储到文件中各存储单元中,文件中每个存储单元存储的是各测点在1分钟内产生的数据,通过表1中各测点在60秒中产生的数据压缩形成数据块,将各测点1分钟的压缩数据块存储到各存储单元中,例如ID为1的测点产生的0分钟的数据块、ID为4的测点产生的59分钟的数据块等分别存储到各存储单元中;按小时独立存储的文件格式:为了避免随着历史数据规模不断增大而影响时序数据的存储和查询功能,本方法提出按小时独立存储的文件格式,如文件结构所描述的,每个文件存储所有测点一个小时内产生的数据,这样对于t个小时就对应t个文件,且不同文件中数据时标互相不重复,并且文件以对应的小时数来命名,例如第一个小时所有测点产生的数据均存储到第一个文件中,第t个小时所有测点产生的数据均存储到第t个文件中;该方法在每次数据写入时,只需访问一个文件,根据产生数据的小时数找到对应的文件数;同样后期查询也可以根据要查询的时间段定位到对应的文件,例如查询时间段安排在第i个小时第j分钟第m秒,则找到对应的第i个文件,在第i个文件中找到该测点的j分钟的数据块,最后在缓存结构中找到该测点第j分钟中第m秒的数据,依次解压得等到数据,无论数据量多大,写入和查询所需操作的文件数是一定的,性能不会发生降低。在本发明中,为了提升时序数据的检索效率,提出了一种文件偏移量索引机制,该索引机制中,具体操作是为了每个数据文件生成一个索引文件,即每个小时所有测点的数据会有对应的索引文件,索引文件如表3所示:测点ID0分钟1分钟2分钟……59分钟1offsetoffsetoffset……offset2offsetoffsetoffset……offset3offsetoffsetoffset……offset4offsetoffsetoffset……offset表3表3中,索引文件采用二维数组结构,两个维度分别为测点ID和每个小时的60分钟(从0分钟到59分钟),二维数组中的每个单元存储一个偏移量(offset),表示对应测点ID在某分钟数的数据块;通过索引文件可以事先索引到某测点在某分钟是否存在数据值,避免对不存在数据值的测点进行检索,提升了数据的检索效率;本发明方法通过提供的测点ID和时序数据结合的存储模型、缓存和文件结合的双层存储架构、按小时独立存储的文件格式以及文件偏移量索引机制实现数据的写入和查询;如图1所示,数据写入阶段包括以下步骤:计算机内存中接收某个测点最新1分钟内i秒钟的时序数据,i=(0,2,…,59);根据测点ID和i秒钟在缓存结构中找到接收数据的缓存位置,例如ID为1的测点最新1分钟内0秒产生的时序数据的缓存位置应该是测点ID为1,时刻为0秒处;将接收到的测点最新1分钟内i秒钟的时序数据复制到对应缓存位置中,例如将ID为1的测点最新1分钟内0秒产生的时序数据复制到缓存结构中ID为1,时刻为0秒的位置中;判断测点产生数据并缓存数据时间是否超过1分钟,如果不是就结束,如果是则进入下一步骤;将缓存结构中该测点最新1分钟内产生的时序数据进行压缩形成数据块;根据测点ID和最新1分钟对应的分钟数在文件结构中找到压缩数据块的文件写入位置,例如对于ID为1的测点的1分钟产生的数据写入位置为标签点为1的1分钟数据块;将该测点最新1分钟内压缩数据块写入到文件结构中对应位置,例如将ID为1的测点的1分钟产生的数据压缩形成的数据块写入到文件中标签点1的1分钟数据块位置处;将该测点最新1分钟内压缩数据块对应的文件位置记录到对应的索引文件中,例如将ID为1的测点的1分钟产生的数据压缩形成的数据块写入到文件中标签点1的1分钟数据块位置处后,将索引文件中ID为1的测点、1分钟处做offset记录。如图2所示,数据查询阶段包括以下步骤:收到查询请求,查询请求中包括测点ID信息和查询时间段信息;判断查询时间段是否在缓存中,如果是则根据查询时间段从缓存中定位数据,并返回数据结果后结束,例如查询请求为:查询ID为1的测点0秒产生的数据,从缓存结构中测点ID为1、秒数为0的存储单元中找到时序数据;如果不是则根据查询开始时间找到历史数据文件,读取该历史数据文件对应的索引文件,在索引文件中查询该测点在该时间段显示的分钟时间是否有值,如果没有值则返回无值结束,如果有值则在历史数据文件中根据测点ID信息和查询时间段信息读取数据块,最后将读取的数据块解压缩,返回数据结果,结束。通过将每个小时的所有测点产生的历史数据独立存储,解决历史数据累计后写入和查询效率下降问题。以上所述仅是本发明的优选实施方式,应当指出:对于本
技术领域:
的技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1