基于特征选择和面部多区域分类器集成的驾驶者疲劳状态识别方法与装置与流程
本发明属于模式识别中驾驶者疲劳状态识别
技术领域:
,具体设计了一种基于特征选择和分类器集成技术,利用人脸多区域精简特征进行驾驶者疲劳状态识别的方法与装置。
背景技术:
:对驾驶者疲劳状态进行识别是一个具有挑战性的模式识别问题,现有的技术主要是针对发生疲劳时两个比较明显的表现,即眨眼频率变慢,开度变小以及出现打哈欠的特征来进行识别。仅关注这两种显著的特征来判定驾驶者的状态存在一定的不足,首先,这种识别技术往往不能够在驾驶者发生疲劳的早期进行预警,往往只有当驾驶者几乎打瞌睡的时候才能给出预警,事实上,此时驾驶者已经处于危险之中了。其次,虽然这两种特征比较显著,但是没有证据表示这是判定疲劳的最优特征,而且,通过眨眼开度与频率来识别疲劳,需要非常清晰并且焦距固定的图像才能进行准确的识别,这在实际使用中很难做到;而打哈欠有些时候并不一定表示真正疲劳。往往在这些表现前后的一些面部特征对于辨识疲劳状态会产生启发作用。如何对与疲劳相关的特征进行评价和选择,以及如何将面部不同区域的特征有效联系起来,是有效进行疲劳状态识别的关键。但是,一直以来没有基于类似思路的驾驶者疲劳状态识别方法和装置公开出来。技术实现要素:本发明的目的是要克服现有技术仅能对于
背景技术:
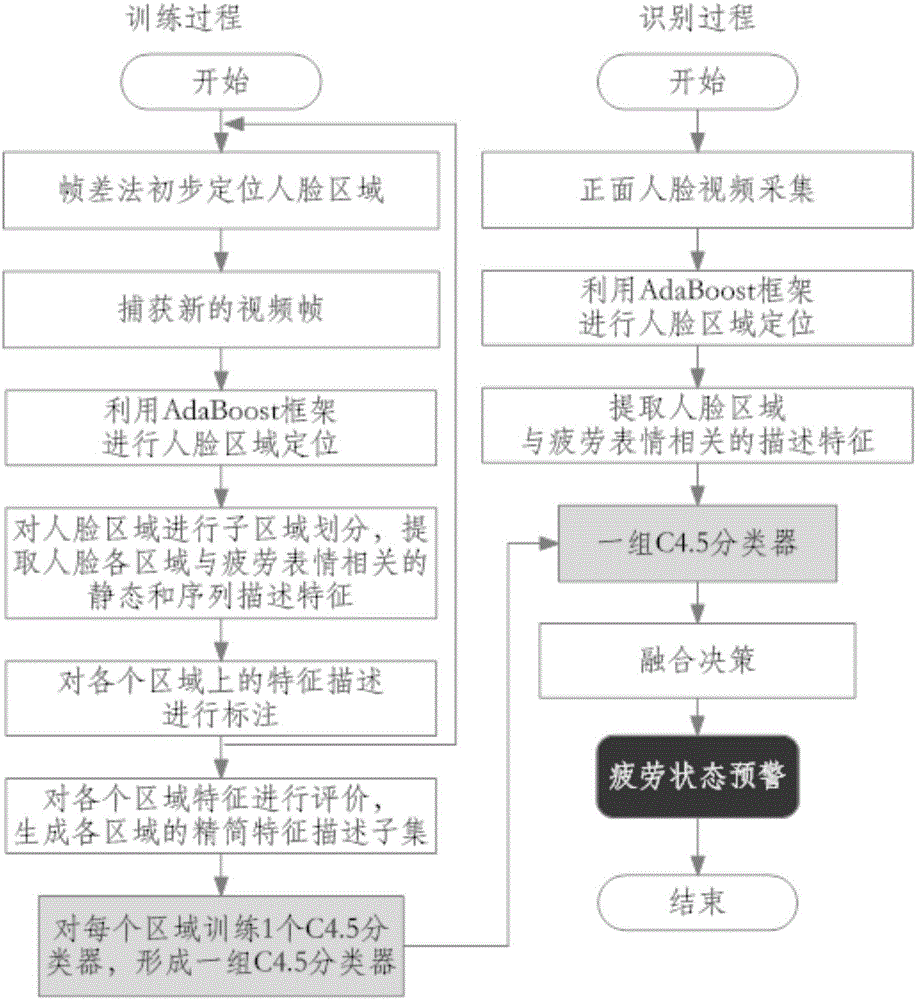
提到的两种与疲劳相关的表现进行识别的不足,提供一种更具一般性的疲劳状态识别方法,能够通过学习出一些不易被观察得到的有效的特征描述,结合人脸各个区域的综合表现,给出一个更加稳定可靠的识别结果,从而能够更加及时的侦测到疲劳表现并对驾驶者进行更早预警。具体地,该方法首先对于人脸与疲劳相关的特征进行特征评价与选择,从而获得对于疲劳表征更加相关与高效的精简特征子集,基于这些在各个人脸子区域上的有效特征集合合理地选用一组分类器进行分类并对识别结果进行集成,与现有方法对比,该方法所提取的特征兼顾面部状态以及状态变化的时序描述特征,并且经过特征选择后,得到的特征对于疲劳状态的表征更具相关性,不同区域的多个分类器具有良好的互补性,对于疲劳状态的平均识别率显著提高。同时,该方法亦可视为一个应用框架,如果有更好的特征描述手段以及更好的分类器,都可以轻易进行替换,或可进一步提高分类性能。本发明为解决上述技术问题采取的技术方案是:一种基于特征选择和面部多区域分类器集成的驾驶者疲劳状态识别方法,所述驾驶者疲劳状态识别方法的实现过程为:一、训练过程:步骤1:通过视频摄录获取人脸视频帧,用帧差法初步定位人脸区域,捕获新的视频帧;步骤2:通过Haar-like特征结合AdaBoost算法框架,进行人脸区域定位;步骤3:对人脸区域进行区域划分,提取人脸各区域与疲劳表情相关的静态特征与序列描述特征(序列描述特征也即动态特征);基于每幅人脸视频帧中人脸的状态,对每帧图像进行类别标注;步骤4:对各个区域得到的特征进行评价和选择,对应生成各区域的精简特征描述子集;步骤5:用各个区域所得到的特征子集训练一组C4.5分类器,所述分类器将用于识别过程中;二、识别过程:步骤1、捕获驾驶者面部视频并获取视频帧;步骤2、应用AdaBoost算法框架基于Haar-like特征对人脸区域进行检测与定位:步骤3、对人脸区域进行划分,对面部与疲劳表现相关的全局以及各子区域进行静态和动态特征提取,在不同区域提取相应的精简特征,所提取的特征根据训练过程决定;步骤4、利用一组学习好的C4.5决策树分类器对各个区域特征给出一个分类判别结果,然后对不同区域上对应的分类器进行投票表决,最终给出综合判别结果,从而决定是否对驾驶者进行疲劳预警;每个C4.5决策树分类器是通过训练过程得到的。在训练过程的步骤3中,提取特征时,整个人脸区域作为一个全局区域,另外再分割出8个子区域分别计算特征;提取序列描述特征时,设定的滑动时间窗大小为23;全局区域所提取的是5维LLE低维嵌入特征,每个子区域基于灰度共生矩阵提取4个纹理统计特征:角二阶矩(ASM),熵(EN),对比度(CON)以及反差分矩(IDM);基于上述静态特征,分别各自计算出9个序列特征:峰值(PV),均值(M),标准偏差(STD),均方根(RMS),波形因子(SF),偏斜度(S),峰度(K),波峰因子(CF)以及脉冲指数(PI),从而形成动态特征。在训练过程的步骤4中,基于模糊粗糙集技术对各个区域得到的特征进行评价和选择,得到各区域的精简特征描述子集,具体过程如下:首先给出依赖度的定义:采用高斯核函数进行下近似计算:式中,Rθdi(x)表示样本x必然属于决策di的程度,进一步给出决策D对属性子空间B的依赖度定义:式中,U为样本集合;表示计算集合基数;然后基于依赖度的定义,给出特征选择算法,步骤如下:输入:<U,A,D>,U为样本集合,A为条件属性集合,D为决策属性。输出:精简的特征子集F;1)要选择特征的特征子集F,最初特征子集是空集合2)当通过一个循环来选,最大循环次数就是全部特征的个数;3)遍历搜索ai∈A-F;4)计算F中加入这个特征后的依赖度5)搜索结束;6)选择a∈A-F,每轮循环选择加入该特征后依赖度提升最大的那个特征7)如果剩下的特征加入后对于依赖度提升不大,即γFUa(D)-γF(D)≤ε,8)则循环中止;9)结束循环;10)每次把选择出来的特征放到F中,FUa→F,最终F就是选取的特征子集,最终每个区域保留15个特征;11)结束特征选择;12)返回最终的F这个精简特征子集。在识别过程的步骤2中,检测过程会对每一帧图像的不同位置以及不同大小的矩形窗口依次进行检测,找到一个合理的人脸区域;每一个检测窗口是否具备的Haar-like特征就是级联结构中的一个弱分类器,通过弱分类器级联结构可快速排除非人脸区域,准确地定位出人脸区域。对应的,本发明还提供了一种基于特征选择和面部多区域分类器集成的驾驶者疲劳状态识别装置,所述驾驶者疲劳状态识别装置包括:图像获取模块,用于对检测对象的视频捕获以及视频帧提取;ROI区域定位模块,用于触发基于Haar-like特征的级联结构分类器在提取帧中的不同位置进行可变窗口大小的人脸检测,并对检测到的人脸进行子区域划分;ROI区域特征提取模块,用于对得到的人脸全局部分以及各个子区域部分进行特征提取,并同时能根据训练阶段特征选择的结果仅提取相应的特征;疲劳状态集成判别模块,用于对当前被监控的驾驶者的驾驶状态进行评估,它由一组针对不同区域的C4.5分类器构成,其判别函数可以描述为:y*=argmax[count(C(Xk,I)==y)]其中,C(Xk,I)表示一个对应人脸图像I的第k个区域的特征子集Xk的C4.5分类器的分类结果,结果有两种,1为疲劳状态,0为非疲劳状态;count(·)是一个计数函数。所述驾驶者疲劳状态识别装置还包括:人脸状态标注模块,用于通过人机交互界面获取用户基于人脸状态对每帧视频图像的标注结果,以及“基于每幅人脸视频帧中人脸的状态,对每帧图像进行类别标注。由上述技术方案可获得本发明具有如下技术效果:(1)本发明通过对人脸区域进行划分并针对不同区域提取包含静态与序列的不同描述特征,使得对于驾驶者状态的面部描述信息更加全面和丰富,通过构造一组分别对应不同区域的C4.5分类器,使得每个区域对于驾驶者的状态都给出一个分类结论,通过将这些分类器的判别结果进行集成,最终给出驾驶者状态的判定,这样更加可靠和稳定,从而有效提高对于驾驶者疲劳状态的识别性能。(2)以这种方式将能够在一定程度上检测出非典型的驾驶者的疲劳状态,并且对于疲劳驾驶的行为给出更早的预警,这些都是基于对疲劳发生早期序列特征信息的学习得到的。通过实验发现,本方法可以通过精简的特征集合获得对驾驶者疲劳状态平均更高的识别率。所采用的技术PCA_SVMRBFGaborLBP_AdaBoostGentle本发明方法识别准确率0.7244±0.00040.8534±0.03690.9755±0.0048注:这里对比的方法为文献X.Fan,Y.F.Sun,B.C.Yin,andX.M.Guo,"Gabor-baseddynamicrepresentationforhumanfatiguemonitoringinfacialimagesequences,"PatternRecognitionLetters.31,(3)234-243(2010)中所使用和对比的方法。附图说明以下附图仅是本发明的一些实施例,对于本领域具有相关知识的技术人员,可以在不付出创造性劳动的前提下,根据这些附图获得其他附图。图1为本发明所述的基于特征选择和面部多区域分类器集成的驾驶者疲劳状态识别方法的处理过程示意图(识别过程);图2为本发明所述的基于特征选择和面部多区域分类器集成的驾驶者疲劳状态识别方法的流程图(包含训练过程和识别过程);图3为本发明所述基于特征选择和面部多区域分类器集成的驾驶者疲劳状态识别装置的结构框图。具体实施方式下面结合附图1至3,对发明的具体实施方式作进一步描述,以下仅用于更加清楚和详细地说明本发明的技术方案的实施方法,而不能以此来限制本发明的保护范围。参照图2,本发明实现对驾驶者疲劳状态预警,包括训练和识别两个过程,其中训练过程需要对每个区域所提取的特征进行评价与选择,从而生成对应每个区域的精简特征集,并基于这些精简特征集合训练一组C4.5分类器,而在识别过程只需提取这些特征来进行分类。具体地,训练过程包含以下步骤:步骤1:通过视频摄录装置通过程序获取人脸视频帧。步骤2:通过Haar-like特征结合AdaBoost算法框架,检测出人脸核心区域。步骤3:对人脸区域进行区域划分,并提取静态与序列描述特征。提取序列特征时,本发明设定的滑动时间窗大小为23。提取特征时,整个人脸区域作为一个全局区域,另外再分割出8个子区域分别计算特征。全局区域所提取的是5维LLE低维嵌入特征,每个子区域基于灰度共生矩阵提取4个纹理统计特征:角二阶矩(ASM),熵(EN),对比度(CON)以及反差分矩(IDM)。上述静态特征,分别又可以各自计算出9个序列特征来,它们是峰值(PV),均值(M),标准偏差(STD),均方根(RMS),波形因子(SF),偏斜度(S),峰度(K),波峰因子(CF)以及脉冲指数(PI)。这些特征在对于驾驶者状态分类时,由于所处的区域不同其分类能力必然会有较大差异,很多特征对于该区域的描述能力是不够强的,或者说这个特征是冗余的,因此,需要一个特征评价算法来对上述提取的静态和序列特征进行评价,从而得到对应各个区域的精简且高效的特征子集。步骤4:基于模糊粗糙集技术,对各个区域得到的特征进行评价和选择。注意,此过程可能耗时较长,但只需要在训练阶段实施一次,识别过程不需要进行。具体的算法步骤如下:首先,给出一些相关概念。基于模糊近似算子θ,样本x隶属于决策dk的下近似定义为:这里,Rθdk(x)表示x必然属于决策dk的程度。其中,θ具体以θcos模糊算子给出定理:如果任一值域在单元区间的核函数k:U×U→[0,1]且满足k(x,x)=1,那么,它至少满足Tcos-传递性。因为高斯核满足上述定理条件,在实际进行下近似计算时,可以采用高斯核函数,从而使计算过程得以简化:进一步,可以给出决策D对属性子空间B的依赖度定义:基于依赖度的定义,下面可以给出特征选择算法,步骤如下:输入:<U,A,D>,U为样本集合,A为条件属性集合,D为决策属性。输出:精简的特征子集F。步骤5:用各个区域所得到的特征子集训练一组C4.5分类器,这组分类器将用于识别过程中。注意,这一步骤也仅在训练过程实施,在识别过程直接使用即可。步骤6:集成各个分类器的判别结果,从而决定是否对该驾驶者进行预警。这里对分类器集成可以采用不同的策略或学习方法,本发明仅以投票方式作为实施例。识别过程的步骤如下:步骤1:通过视频摄录装置通过程序获取人脸视频帧。步骤2:通过Haar-like特征结合AdaBoost算法框架,检测出人脸核心区域。步骤3:对人脸区域进行区域划分,在不同区域提取相应的精简特征。步骤4:用训练过程得到的各个C4.5分类器对对应的人脸区域特征进行分类,然后给出集成分类结果,从而决定是否对驾驶者进行疲劳预警。本发明说明书中,说明了大量的具体细节,具有相关知识的技术人员能够理解并可以进行实践。在实施例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。以上所述,仅为本发明一个具体的实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1