利用相对覆盖元约简进行人脸疲劳状态识别的方法及系统与流程
本发明涉及图像识别
技术领域:
,具体涉及人脸疲劳状态识别的系统及方法。
背景技术:
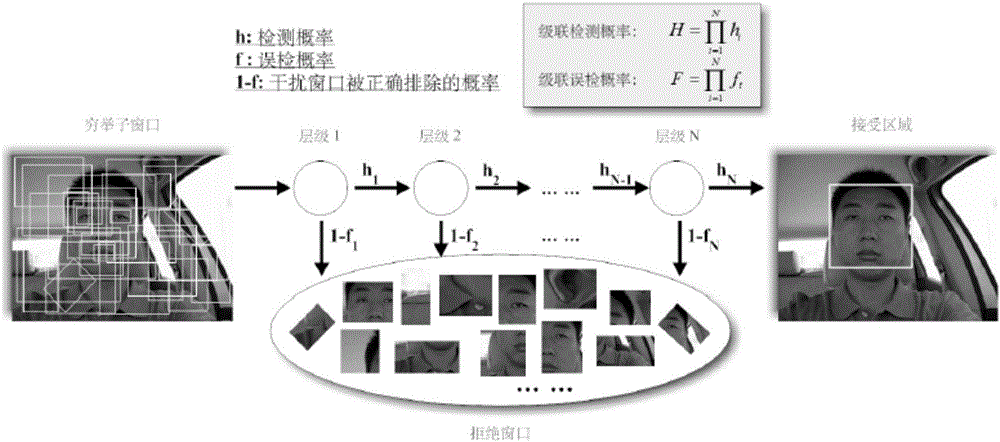
:在很多实际应用问题中,往往需要根据以往的经验对一个事物(通常称为样本)作出一个正确的判断,当对此问题空间中样本的真实分布特点无法全面了解,或者说所拥有的样本数目并不充分的时候,抑或所面临的问题是一个高维稀疏的样本空间中的分类问题时等等,在上述这些情形下,一般要解决两个问题,一是要对样本进行特征提取和表示,第二依据一定的原则来对新的样本进行分类。最近邻分类器和k-近邻分类器是解决此类问题的有效办法,但这两种方法的缺点是决策过程需要与全部带标签样本进行逐一距离计算后才能做出决策,计算量大,导致分类速度慢。C4.5决策树分类器也是一个有效办法,但提取规则数量较多,泛化性能受到影响,而基于支持向量机的分类方法训练过程比较复杂。人脸疲劳表情的识别就属于这样的问题,构造与此高维稀疏样本空间相适应的分类方法是解决此类问题的关键。粗糙集先天具有对于目标问题强大的逼近能力,目前被广泛应用在机器学习与数据挖掘领域当中。上世纪80年代,波兰著名学者Pawlak提出了粗糙集理论,并利用该理论成功解决了名义数据的属性约简以及规则学习问题。但Pawlak的理论框架并不能适用于数值数据,更不能处理包含名义数据、数值数据以及模糊数据的复杂情况。经过十几年的发展,粗糙集理论及其应用取得了长足的发展,在处理不完备和不一致数据上,粗糙集理论成为一种强大且重要的工具。早期Pawlak粗糙集模型中的等价关系也逐步进化出相似关系、邻域关系和优势关系。这些关系所诱导出来的子集族本质上构成了对于论域的覆盖,而不再是划分。因此,这些模型也被纳入覆盖粗糙集的范畴。并且相关模型被提出并用来模拟人类某种方式的推理和决策过程。覆盖粗糙集约简方法可以分为两大类:一类称为覆盖族约简,另一类称为覆盖元约简。覆盖族约简是要通过对一族覆盖的约简达到特征选择的目的,而覆盖元约简则是为了寻找对象的最小描述。基于覆盖元约简的方法一直都没有把决策属性考虑进来,仅是从保持覆盖近似空间的区分能力方面来加以考虑进行研究与应用。这样,就无从利用覆盖元约简的角度来构造分类器。本发明则利用决策属性(样本标签)作为指导,提出了一种行之有效的基于粗糙集覆盖元约简的分类器构造方法,可以广泛用于各种实际分类任务中,并且特别适合像人脸疲劳表情识别这类高维稀疏样本空间的分类问题。粒化和逼近是粗糙集理论体系的两个核心支撑。从认知的角度来说,粒化是形成概念的抽象过程,而逼近则是认知的推理过程。因此,粗糙集在对于问题域进行细致刻画以及构造分类器方面理应具有显著的优势,但是,一直以来都没有办法独立基于粗糙集相关理论来创建分类器,自然也无从利用粗糙集的上述优势形成相应的分类器实现一个人脸疲劳表情识别装置。技术实现要素:本发明为了解决利用现有技术进行人脸疲劳表情识别存在的计算量大或规则多的问题以及目前无法通过覆盖元约简进行人脸疲劳表情识别的问题。利用相对覆盖元约简进行人脸疲劳状态识别的方法,包括以下步骤:一、训练一个相对覆盖元分类器:步骤1、获取视频摄录装置中视频图像的人脸视频帧;步骤2、检测出每幅人脸视频帧中人脸核心区域;步骤3、提取人脸核心区域的特征;步骤4、基于每幅人脸视频帧中人脸的状态,对每帧图像进行类别标注;步骤5、将人脸核心区域的特征结合对应的标注形成带标签的训练样本,并构成训练样本集合;步骤6、对训练样本集合中每一个样本生成一个邻域覆盖元,并对邻域覆盖元所覆盖的样本进行计数;以当前样本到最近异类样本的欧氏距离减去当前样本到最近同类样本的欧氏距离作为当前样本的覆盖元半径,如果此覆盖元半径小于0则置此覆盖元半径为0;或者采用当前样本到最近异类样本的距离作为当前样本的覆盖元半径;步骤7、保留覆盖元半径大于0的邻域覆盖元,并记录半径大于0的邻域覆盖元的总数H;步骤8、从所有邻域覆盖元中找到一个包含样本数目最多的邻域覆盖元产生规则(xk,r(xk),y)并加入规则集R中;其中,表示样本xk的邻域覆盖元(xk,r(xk),y)表示进行分类的规则;r(xk)表示样本xk的覆盖元半径;y是决策类别,表示人脸是否为疲劳状态;步骤9、删除邻域覆盖元并将所覆盖的样本从其他各个邻域覆盖元中移除;邻域覆盖元之间会存在交集,删除邻域覆盖元的同时删除与其他各个邻域覆盖元的交集中的样本;步骤10、当规则的数量小于预设的规则数量h时,返回执行步骤8,直到选出h条规则,形成相对覆盖元分类器;二、对新获取的视频图像进行人脸疲劳状态识别:步骤11、新获取视频并得到视频帧;步骤12、检测出每帧图像中的人脸核心区域;步骤13、提取人脸核心区域的特征;步骤14、用训练过程得到的相对覆盖元分类器对提取的人脸核心区域的特征进行分类,从而识别出人脸疲劳状态,并进行疲劳驾驶预警的决策。优选地,步骤6中所述的邻域覆盖元如下:其中,xi,xj分别表示不带类别标签的两个任意样本(只有特征属性没有类别属性);U表示样本集;Δ(xi,xj)为距离函数,δ是一个依赖于xi的参数,表示距离阈值。优选地,步骤6中所述的Δ(xi,xj)采用欧氏距离计算。优选地,步骤2中所述的检测出每幅人脸视频帧中人脸核心区域是通过Haar-like特征结合AdaBoost算法实现的。优选地,步骤3中提取人脸核心区域的特征所述的特征为纹理特征、局部统计特征或者局部描述特征。优选地,步骤3中所述的局部描述特征包括局部二值模式特征、方向梯度直方图特征或尺度不变特征转换特征。优选地,步骤10所述的规则数量h小于等于覆盖元半径大于0的邻域覆盖元的数目H。利用相对覆盖元约简进行人脸疲劳状态识别的系统,包括:人脸核心区域检测模块,用于获取视频摄录装置中每帧视频图像,并在每帧视频图像中确定人脸核心区域;人脸核心区域的特征提取模块,用于从已经获取的人脸核心区域上通过特征提取方法对人脸核心区域进行特征提取;人脸状态标注模块,通过人机交互界面获取用户基于人脸状态对每帧视频图像的标注结果;样本训练模块,基于邻域覆盖元约简算法对人脸核心区域的特征提取模块提取的特征和人脸状态标注模块中每帧视频图像的标注结果构成的带标签的训练样本集合进行训练,形成相对覆盖元分类器;人脸疲劳状态识别模块,使用学习得到的相对覆盖元分类器对人脸核心区域提取的特征进行疲劳状态识别。本发明具有以下有益效果:1、本发明不但利用相对覆盖元约简实现了人脸疲劳表情的识别,而且提高了对于人脸疲劳状态的识别率,识别率高达87.1%。2、本发明所构造的分类器,由于规则泛化性能更好,所以产生的规则更少,而且计算量小,所以分类速度自然更快。因此,提高了分类过程的实时性。3、本发明构造和使用的分类器的泛化性能优秀,所以对于不同人的疲劳状态的识别更加鲁棒,大大提高了该系统的通用性。附图说明图1为具体实施方式一的步骤流程示意图;图2为实施例中AdaBoost级联检测框架的原理示意图。具体实施方式具体实施方式一:结合图1说明本实施方式,本实施方式所述的利用相对覆盖元约简进行人脸疲劳状态识别的方法,包括以下步骤:一、训练一个相对覆盖元分类器:步骤1、获取视频摄录装置中视频图像的人脸视频帧;步骤2、检测出每幅人脸视频帧中人脸核心区域;步骤3、提取人脸核心区域的特征;步骤4、基于每幅人脸视频帧中人脸的状态,对每帧图像进行类别标注;步骤5、将人脸核心区域的特征结合对应的标注形成带标签的训练样本,并构成训练样本集合;步骤6、对训练样本集合中每一个样本生成一个邻域覆盖元,并对邻域覆盖元所覆盖的样本进行计数;以当前样本到最近异类样本的欧氏距离减去当前样本到最近同类样本的欧氏距离作为当前样本的覆盖元半径,如果此覆盖元半径小于0则置此覆盖元半径为0;或者采用当前样本到最近异类样本的距离作为当前样本的覆盖元半径;步骤7、保留覆盖元半径大于0的邻域覆盖元,并记录半径大于0的邻域覆盖元的总数H;步骤8、从所有邻域覆盖元中找到一个包含样本数目最多的邻域覆盖元产生规则(xk,r(xk),y)并加入规则集R中;其中,表示样本xk的邻域覆盖元(xk,r(xk),y)表示进行分类的规则;r(xk)表示样本xk的覆盖元半径;y是决策类别,表示人脸是否为疲劳状态;步骤9、删除邻域覆盖元并将所覆盖的样本从其他各个邻域覆盖元中移除;邻域覆盖元之间会存在交集,删除邻域覆盖元的同时删除与其他各个邻域覆盖元的交集中的样本;步骤10、当规则的数量小于预设的规则数量h时,返回执行步骤8,直到选出h条规则,形成相对覆盖元分类器;二、对新获取的视频图像进行人脸疲劳状态识别:步骤11、新获取视频并得到视频帧;步骤12、检测出每帧图像中的人脸核心区域;步骤13、提取人脸核心区域的特征;步骤14、用训练过程得到的相对覆盖元分类器对提取的人脸核心区域的特征进行分类,从而识别出人脸疲劳状态,并进行疲劳驾驶预警的决策。具体实施方式二:本实施方式的步骤6中所述的邻域覆盖元如下:其中,xi,xj分别表示不带类别标签的两个任意样本(只有特征属性没有类别属性);U表示样本集;Δ(xi,xj)为距离函数,δ是一个依赖于xi的参数,表示距离阈值。其他步骤和参数与具体实施方式一相同。具体实施方式三:本实施方式所述的步骤6中所述的Δ(xi,xj)采用欧氏距离计算。其他步骤和参数与具体实施方式二相同。具体实施方式四:本实施方式的步骤2中所述的检测出每幅人脸视频帧中人脸核心区域是通过Haar-like特征结合AdaBoost算法实现的。其他步骤和参数与具体实施方式一至三之一相同。具体实施方式五:本实施方式的步骤3中提取人脸核心区域的特征所述的特征为纹理特征、局部统计特征或者局部描述特征。其他步骤和参数与具体实施方式一至四之一相同。具体实施方式六:本实施方式的步骤3中所述的局部描述特征包括局部二值模式(Localbinarypatterns,LBP)特征、方向梯度直方图(HistogramofOrientedGradient,HOG)特征或尺度不变特征转换(Scale-invariantfeaturetransform,SIFT)特征等多种局部描述特征。其他步骤和参数与具体实施方式一至五之一相同。具体实施方式七:本实施方式的步骤10所述的规则数量h小于等于覆盖元半径大于0的邻域覆盖元的数目H(如果h大于覆盖元半径大于0的邻域覆盖元的数目H,则将h值置为覆盖元半径大于0的邻域覆盖元的数目H,即h值与覆盖元半径大于0的邻域覆盖元H的数目相等)。其他步骤和参数与具体实施方式六相同。具体实施方式八:以上具体实施方式的计算内容均是通过计算机实现的,所以能够将以上的计算过程以及执行内容编写成执行代码,并对各个功能进行模块划分编写,使其成为一套能够实现人脸疲劳状态识别的系统,而被更加广泛应用。本实施方式所述的利用相对覆盖元约简进行人脸疲劳状态识别的系统,包括:人脸核心区域检测模块,用于获取视频摄录装置中每帧视频图像,并在每帧视频图像中确定人脸核心区域;人脸核心区域的特征提取模块,用于从已经获取的人脸核心区域上通过特征提取方法对人脸核心区域进行特征提取;人脸状态标注模块,通过人机交互界面获取用户基于人脸状态对每帧视频图像的标注结果;样本训练模块,基于邻域覆盖元约简算法对人脸核心区域的特征提取模块提取的特征和人脸状态标注模块中每帧视频图像的标注结果构成的带标签的训练样本集合进行训练,形成相对覆盖元分类器;人脸疲劳状态识别模块,使用学习得到的相对覆盖元分类器对人脸核心区域提取的特征进行疲劳状态识别。实施例为了定义覆盖元,所以首先要给出一种通用的样本距离度量方法,能够适应包含名义属性、数值属性以及模糊属性的样本距离度量。具体给出的距离函数如下:其中,m是属性的个数,i是属性的序号,是属性ai的权重,是样本和关于属性ai的距离,定义为同时其中maxa和mina分别指属性a所有取值中的最大值和最小值;接下来,为任一样本x构造覆盖元,以当前样本到最近异类样本的欧氏距离减去当前样本到最近同类样本的欧氏距离作为当前样本的覆盖元半径,其覆盖元半径按下式计算得到:其中,NM(x)表示距离x最近的异类样本,NH(x)表示距离x最近的同类样本。第一,在邻域关系下,对带有标签的训练样本集合进行整理,使之成为一个1型一致(同时也保持2型一致)的决策系统。首先,给出一些必要的定义:定义1.给定任意的xi∈U,xi在特征空间的邻域定义为其中,U表示样本集,xi,xj分别表示不带类别标签的两个任意样本(只有特征属性没有类别属性);U表示样本集;Δ(xi,xj)为距离函数,δ是一个依赖于xi的参数,表示距离阈值。定义2.设是一个邻域覆盖决策系统,D代表决策属性。是U的一个任意子集。中X的1型和2型上,下近似定义为其中,和分别称为1型和2型覆盖下近似,和分别称为1型和2型覆盖上近似。定义3.设是一个邻域覆盖决策系统。U/D={X1,X2,…,Xl}是D诱导的对于U的划分。决策D的1型和2型上,下近似定义为定义4.设是一个邻域覆盖决策系统,U/D={X1,X2,…,Xl}。x∈U,如果存在Xi∈U/D,使得则称x是1型一致的。如果存在x'∈U和Xi∈U/D,使得且则称x是2型一致的。定义5.如果U中所有样本1型一致,即则称,邻域覆盖决策系统1型一致;否则称该系统1型不一致。如果U中所有样本2型一致,即则称,邻域覆盖决策系统2型一致;否则,称该系统是2型不一致。基于上述定义,分别生成每个样本的邻域覆盖元,形成一族覆盖元,如果某个样本所形成的覆盖元半径小于0或是包含不同类标的样本,则对该样本进行标记,等全部样本都计算完覆盖元后,把标记样本从训练样本集中删除,这样经过整理后的带标签的训练样本集合一定是一个1型一致的邻域覆盖决策系统。同时,保存未被标记的样本所生成的各个覆盖元。基于上面所构造的满足1型一致的邻域决策系统,通过相对覆盖约简,习得一个精简的具有更好泛化性能的分类器。在邻域覆盖关系下,基于相对覆盖约简进行分类器学习的过程也就是训练相对覆盖元分类器的过程如下:步骤1、获取视频摄录装置中视频图像的人脸视频帧;步骤2、检测出每幅人脸视频帧中人脸核心区域;检测出每幅人脸视频帧中人脸核心区域是通过Haar-like特征结合AdaBoost算法实现的。图2给出了AdaBoost级联检测框架的原理示意图。步骤3、提取人脸核心区域的特征;步骤4、基于每幅人脸视频帧中人脸的状态,对每帧图像进行类别标注;步骤5、将人脸核心区域的特征结合对应的标注形成带标签的训练样本,并构成训练样本集合;步骤6、对训练样本集合中每一个样本生成一个邻域覆盖元,并对邻域覆盖元所覆盖的样本进行计数;以当前样本到最近异类样本的欧氏距离减去当前样本到最近同类样本的欧氏距离作为当前样本的覆盖元半径,如果此覆盖元半径小于0则置此覆盖元半径为0;或者采用当前样本到最近异类样本的距离作为当前样本的覆盖元半径;步骤7、保留覆盖元半径大于0的邻域覆盖元,并记录半径大于0的邻域覆盖元的总数H;步骤8、从所有邻域覆盖元中找到一个包含样本数目最多的邻域覆盖元产生规则(xk,r(xk),y)并加入规则集R中;其中,表示样本xk的邻域覆盖元(xk,r(xk),y)表示进行分类的规则;r(xk)表示样本xk的覆盖元半径;y是决策类别,表示人脸是否为疲劳状态;步骤9、删除邻域覆盖元并将所覆盖的样本从其他各个邻域覆盖元中移除;邻域覆盖元之间会存在交集,删除邻域覆盖元的同时删除与其他各个邻域覆盖元的交集中的样本;步骤10、当规则的数量小于预设的规则数量h时,返回执行步骤8,直到选出h条规则,形成相对覆盖元分类器;所述的规则数量h小于等于覆盖元半径大于0的邻域覆盖元的数目H。然后,对新获取的视频图像进行人脸疲劳状态识别:步骤11、新获取视频并得到视频帧;步骤12、检测出每帧图像中的人脸核心区域;步骤13、提取人脸核心区域的特征;步骤14、用训练过程得到的相对覆盖元分类器对提取的人脸核心区域的特征进行分类,从而识别出人脸疲劳状态,并进行疲劳驾驶预警的决策。通过以上的过程进行疲劳驾驶预警具有以下优点:1、提高了对于人脸疲劳状态的识别率:本发明所设计的分类器适合高维稀疏样本空间的分类问题,因此,对于疲劳表情的识别具有更好的效果,其识别结果相较于NEC,1-NN,支持向量机(SVM)以及同样是规则学习的分类器CART和C4.5具有更好的识别效果。表1给出了在实验室建立的疲劳面部表情数据集上用不同分类器进行疲劳状态识别的性能对比。数据采自15个人,每个人若干段视频,实验采用10折交叉验证方式计算平均识别率。表1NEC1-NNLSVMCARTC4.5本发明识别率78.0%71.4%67.1%66.6%70.5%87.1%2、提高了识别的实时性:本发明所构造的分类器,由于规则泛化性能更好,所以产生的规则更少,而且计算量小,所以分类速度自然更快。因此,提高了分类过程的实时性。3、提高了对于不同人进行识别的适应性:本发明构造和使用的分类器的泛化性能优秀,所以对于不同人的疲劳状态的识别更加鲁棒,大大提高了该系统的通用性。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1