分布式文件系统中节点选择方法及装置与流程
本发明涉及分布式数据存储技术领域,尤其涉及一种分布式文件系统中节点选择方法及装置。
背景技术:
随着网络技术及信息处理技术的不断发展,个人数据和企业数据的产生量呈现爆炸性膨胀的趋势,IT系统正面临着海量数据存储成本高、管理困难、可靠性低的问题,为了充分利用资源,减少重复的投资,数据存储作为IT系统的主要架构和基础设施之一,逐步被作为一个完整的系统从IT系统中独立出来,分布式文件系统因为具有海量数据存储、高扩展性、高性能、高可靠性、高可用性的特点,目前正被作为企业海量数据存储方案被业界所广泛讨论和应用。
分布式文件系统旨在通过在网络环境下构建具有高传输性能、高可靠性、高可用性的网络分布式文件系统,通过网络数据流方式实现对海量文件系统中的数据进行存储和访问,解决大规模非结构化数据的存储、查询、高性能读取、高容错性的问题,为IT系统提供高性能、高可靠性、高可用性的存储应用服务,并为今后的分布式计算研究提供技术基础。
分布式文件系统将相同的文件同时存储到网络上多台服务器后,当客户端通过DFS访问文件时,DFS会引导客户端从最接近客户端的服务器来访问文件,让客户端快速访问到所需的文件。在现有技术中,在低成本及可扩展的分布式数据中,如何解决数据存储及提取的方式为当前解决要点。
上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
本发明的主要目的在于提供一种分布式文件系统中节点选择方法及装置,旨在解决现有的分布式存储方式中分布式数据快速提取的问题。
为实现上述目的,本发明提供的一种分布式文件系统中节点选择方法,包括以下步骤:
在检测到数据读取指令时,根据加权二叉树算法计算读取路径;
根据读取路径确定读取所述数据的节点,从所述结点读取所述数据。
优选地,所述在检测到数据读取指令时,根据加权二叉树算法计算读取路径的步骤之前,还包括:
为存储分布式文件的结点组成的二叉树配置OSD路径加权值;
以二叉树的根结点为起点,根据HASH算法及OSD路径加权值遍历二叉树中的结点并存入OSD MAP中;
根据OSD MAP中的结点信息生成加权二叉树。
优选地,所述在检测到数据读取指令时,根据加权二叉树算法计算读取路径的步骤包括:
以加权二叉树中发送数据读取指令的结点为起点,根据结点左OSD路径加权值、右OSD路径加权值中较大者及加权二叉树算法计算读取路径。
优选地,所述方法还包括:
当OSD容量和/或状态变化时,根据HASH算法及OSD路径加权值计算HASH值,并将HASH值与结点左右子树的OSD数目进行比较;
当HASH值小于左子树的OSD数目时,选择左结点,否则选择右结点;
将结点重新映射到OSD MAP中。
优选地,所述方法还包括:
当获取到OSD MAP中的结点故障信息时,查找新的结点替代发生故障的结点;
当所述发生故障的结点恢复正常时,该结点重新加入OSD MAP中。
此外,为实现上述目的,本发明还提供一种分布式文件系统中节点选择装置,包括:
计算模块,用于在检测到数据读取指令时,根据加权二叉树算法计算读取路径;
读取模块,用于根据读取路径确定读取所述数据的节点,从所述结点读取所述数据。
优选地,所述分布式文件系统中节点选择装置还包括配置模块及MAP模块;
所述配置模块,用于为存储分布式文件的结点组成的二叉树配置OSD路径加权值;
所述计算模块,还用于以二叉树的根结点为起点,根据HASH算法及OSD路径加权值遍历二叉树中的结点并存入OSD MAP中;
所述MAP模块,用于根据OSD MAP中的结点信息生成加权二叉树。
优选地,所述计算模块,还用于以加权二叉树中发送数据读取指令的结点为起点,根据结点左OSD路径加权值、右OSD路径加权值中较大者及加权二叉树算法计算读取路径。
优选地,所述分布式文件系统中节点选择装置还包括:
比较模块,用于当OSD容量和/或状态变化时,根据HASH算法及OSD路径加权值计算HASH值,并将HASH值与结点左右子树的OSD数目进行比较;
选择模块,用于当HASH值小于左子树的OSD数目时,选择左结点,否则选择右结点;
映射模块,用于将结点重新映射到OSD MAP中。
优选地,所述分布式文件系统中节点选择装置还包括:
查找模块,用于当获取到OSD MAP中的结点故障信息时,查找新的结点替代发生故障的结点;
加入模块,用于当所述发生故障的结点恢复正常时,该结点重新加入OSD MAP中。
本发明在检测到数据读取指令时,根据加权二叉树算法计算读取路径;根据读取路径确定读取所述数据的节点,从所述结点读取所述数据。本发明通过加权二叉树算法可以根据特定的条件快速找到需要的树结点,提高了分布式数据的提取速度。
附图说明
图1为本发明分布式文件系统中节点选择方法的第一实施例的流程示意图;
图2为本发明分布式文件系统中节点选择方法的第二实施例的流程示意图;
图3为本发明分布式文件系统中节点选择方法的第三实施例的流程示意图;
图4为本发明分布式文件系统中节点选择方法的第四实施例的流程示意图;
图5为本发明分布式文件系统中节点选择装置的第一实施例的功能模块示意图;
图6为本发明分布式文件系统中节点选择装置的第二实施例的功能模块示意图;
图7为本发明分布式文件系统中节点选择装置的第三实施例的功能模块示意图;
图8为本发明分布式文件系统中节点选择装置的第四实施例的功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种分布式文件系统中节点选择方法。
参照图1,图1为本发明分布式文件系统中节点选择方法的第一实施例的流程示意图。
在一实施例中,所述分布式文件系统中节点选择方法包括:
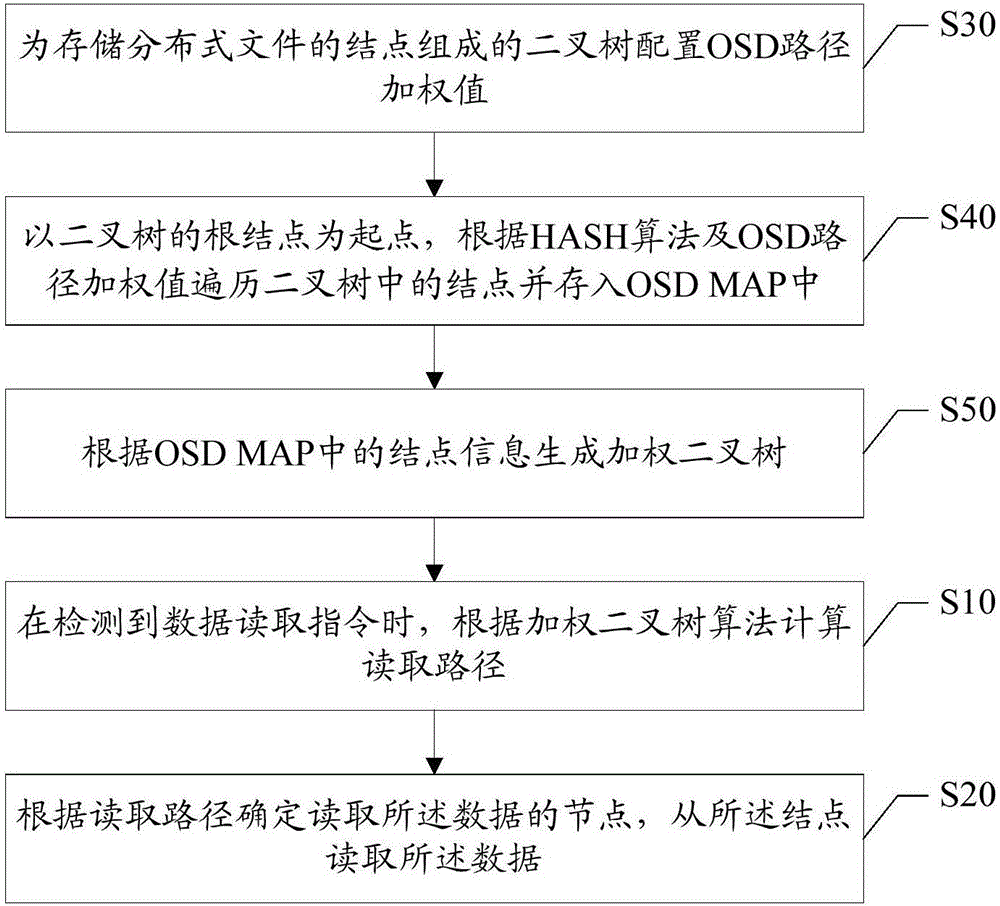
步骤S10,在检测到数据读取指令时,根据加权二叉树算法计算读取路径;
分布式文件系统是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。分布式文件系统的设计基于客户端/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。另外,对等特性允许一些系统扮演客户端和服务器的双重角色。例如,用户可以“发表”一个允许其他客户端访问的目录,一旦被访问,这个目录对客户端来说就像使用本地驱动器一样。分布式文件系统将相同的文件同时存储到网络上多台服务器后,即具备以下功能:1)提供文件的访问效率:当客户端通过DFS(Depth-First-Search,深度优先搜索算法)访问文件时,DFS会引导客户端从最接近客户端的服务器来访问文件,让客户端快速访问到所需的文件。实际上,DFS是提供客户端一份服务器列表,这些服务器内都有客户端所需要的文件,但是DFS会选择最接近客户端的服务器。2)服务器负载平衡功能:每个客户端获得列表中的服务器排列顺序可能都不相同,因此他们访问的服务器也可能不相同,也就是说不同客户端可能会从不同服务器来访问所需文件,从而减轻服务器的负担。本发明一实施例通过加权二叉树算法计算读取路径,可以根据特定的条件快速找到需要的树结点,和二叉树比较具有更详细的参数来判断一个树的状态,OSD(Object Storage Device,对象存储设备)容量状态以及连接状态等。因此,在检测到数据读取指令时,根据加权二叉树算法计算读取路径。
进一步地,所述步骤S10包括:
以加权二叉树中发送数据读取指令的结点为起点,根据结点左OSD路径加权值、右OSD路径加权值中较大者及加权二叉树算法计算读取路径。
二叉树的每个结点至多只有二棵子树(不存在度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。二叉树的第i层至多有2^(i-1)个结点;深度为k的二叉树至多有2^k-1个结点;对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1。二叉树算法常被用于实现二叉查找树和二叉堆。加权二叉树算法:加权二叉树是在二叉树的基础上增加w值,即OSD路径加权值。OSD路径加权值的大小由二叉树上相邻结点之间的距离表示,这个距离在分布式文件系统中主要表现为OSD的可使用容量、OSD的状态、某一个子树上的OSD个数,即,如果某一个子树上的OSD越多、都是可用的状态、每个OSD的容量都满足要求的情况下,子结点就拥有优先获得资源的权利。以加权二叉树中发送数据读取指令的结点为起点,根据结点左OSD路径加权值、右OSD路径加权值中较大者及加权二叉树算法计算读取路径。
步骤S20,根据读取路径确定读取所述数据的节点,从所述结点读取所述数据。
以加权二叉树中发送数据读取指令的结点为起点,以存储要读取的数据的结点为终点,由于要读取的数据在多个节点中均有存储,通过加权二叉树算法计算读取路径,从最短路径对应的节点中读取数据。通过加权二叉树算法可以根据特定的条件快速找到需要的树结点,和二叉树比较具有更详细的参数来判断一个树的状态,OSD容量状态以及连接状态等。
本实施例通过加权二叉树算法可以根据特定的条件快速找到需要的树结点,提高了分布式数据的提取速度。
参照图2,图2为本发明分布式文件系统中节点选择方法的第二实施例的流程示意图。基于上述分布式文件系统中节点选择方法的第一实施例,所述步骤S10之前,还包括:
步骤S30,为存储分布式文件的结点组成的二叉树配置OSD路径加权值;
步骤S40,以二叉树的根结点为起点,根据HASH算法及OSD路径加权值遍历二叉树中的结点并存入OSD MAP中;
步骤S50,根据OSD MAP中的结点信息生成加权二叉树。
在映射策略中,根据权值的优先级实现分布基数,分布基数是指对对象的存储进行组织和位置映射。优先级的高低在部署的初期由默认参数给出,根据二叉树的层数来决定,比如左子树的层数大于右子树的层数,就表示左节点的OSD数目更大,能够满足更多的存储需求,故优先选择左子树。随着OSD的容量在不断的变化以及OSD的状态发生变化,如出现故障等会及时动态调整权值参数。生成二叉树后,配置OSD路径加权值,其过程可描述为:从根结点出发,根据HASH算法查找结点,找到一个结点后,获取此结点权值,权值的内容在加权二叉树算法中有描述,读取其可用的空间大小以及状态,将此结点的数据映射到OSD MAP中,OSD MAP中数据内容为结点的编号、可用空间大小、结点的状态信息。OSD MAP结构为系统中各个模块所共用的结构体,任何的变化都会反映到OSD MAP中。经过下一个结点,已经经过的结点存入OSD MAP中。然后继续查找此结点的子结点,循环此过程。一个结点只会被经过一次,结点经过后就存入到OSD MAP中了,后面算法不会再去判断这个结点,继续往下走。本发明一实施例为存储分布式文件的结点组成的二叉树配置OSD路径加权值;以二叉树的根结点为起点,根据HASH算法及OSD路径加权值遍历二叉树中的结点并存入OSD MAP中;根据OSD MAP中的结点信息生成加权二叉树。
本实施例根据HASH算法及OSD路径加权值等通过运算处理生成加权二叉树,以便运用加权二叉树算法计算路径长度。
参照图3,图3为本发明分布式文件系统中节点选择方法的第三实施例的流程示意图。基于上述分布式文件系统中节点选择方法的第二实施例,所述方法还包括:
步骤S60,当OSD容量和/或状态变化时,根据HASH算法及OSD路径加权值计算HASH值,并将HASH值与结点左右子树的OSD数目进行比较;
步骤S70,当HASH值小于左子树的OSD数目时,选择左结点,否则选择右结点;
步骤S80,将结点重新映射到OSD MAP中。
当OSD容量发生变化和/或OSD的状态(例如,是否可用)发生变化,都需要重新计算HASH值,比较左右的子树,小于左树选择左结点,否则选择右结点,哪边的OSD数目大,也就是容量大,就先选择哪个子树。将结点的容量、状态信息重新映射到OSD MAP中,这里的映射是根据权值来映射,直到遍历完成所有的结点。权值是在遍历的过程中根据读取的OSD个数计算出来的,并记录到OSD MAP中,当要生成加权二叉树时,只需要读取OSD MAP中的信息即可。当OSD容量和/或状态变化时,根据HASH算法及OSD路径加权值计算HASH值,并将HASH值与结点左右子树的OSD数目进行比较;当HASH值小于左子树的OSD数目时,选择左结点,否则选择右结点;将结点重新映射到OSD MAP中。
本实施例当OSD容量和/或状态变化时,对OSD MAP、加权二叉树进行处理,达到实时更新OSD MAP、加权二叉树的目的,保证计算的读取路径的真实有效性。
参照图4,图4为本发明分布式文件系统中节点选择方法的第四实施例的流程示意图。基于上述分布式文件系统中节点选择方法的第三实施例,所述方法还包括:
步骤S90,当获取到OSD MAP中的结点故障信息时,查找新的结点替代发生故障的结点;
步骤S100,当所述发生故障的结点恢复正常时,该结点重新加入OSD MAP中。
当OSD MAP中的结点收到通知发生变化时,如设备故障,则需要查找新的结点来替代该结点,新的结点在前述第一次遍历时即记录到了OSD MAP中,因此只需要读取OSD MAP中还有没被完全使用的结点即可找到用于替代该结点的新的结点。如果有一个从未使用过的OSD结点加入进来,该未使用过的OSD结点会将自己的状态告诉OSD MAP,从而通过OSD MAP即可知道此结点为未使用过的结点,将其插入到二叉树中,并根据其容量等信息附上权值。如果之前发生故障的结点又恢复正常,则同样会重新加入并更新到OSD MAP中。本发明一实施例,当获取到OSD MAP中的结点故障信息时,查找新的结点替代发生故障的结点;当所述发生故障的结点恢复正常时,该结点重新加入OSD MAP中。
本实施例当结点发生故障或恢复正常时,实时更新OSD MAP、加权二叉树,保证计算的读取路径的真实有效性。
本发明进一步提供一种分布式文件系统中节点选择装置。
参照图5,图5为本发明分布式文件系统中节点选择装置的第一实施例的功能模块示意图。
在一实施例中,所述分布式文件系统中节点选择装置包括:计算模块10及读取模块20。
所述计算模块10,用于在检测到数据读取指令时,根据加权二叉树算法计算读取路径;
分布式文件系统是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。分布式文件系统的设计基于客户端/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。另外,对等特性允许一些系统扮演客户端和服务器的双重角色。例如,用户可以“发表”一个允许其他客户端访问的目录,一旦被访问,这个目录对客户端来说就像使用本地驱动器一样。分布式文件系统将相同的文件同时存储到网络上多台服务器后,即具备以下功能:1)提供文件的访问效率:当客户端通过DFS(Depth-First-Search,深度优先搜索算法)访问文件时,DFS会引导客户端从最接近客户端的服务器来访问文件,让客户端快速访问到所需的文件。实际上,DFS是提供客户端一份服务器列表,这些服务器内都有客户端所需要的文件,但是DFS会选择最接近客户端的服务器。2)服务器负载平衡功能:每个客户端获得列表中的服务器排列顺序可能都不相同,因此他们访问的服务器也可能不相同,也就是说不同客户端可能会从不同服务器来访问所需文件,从而减轻服务器的负担。本发明一实施例通过加权二叉树算法计算读取路径,可以根据特定的条件快速找到需要的树结点,和二叉树比较具有更详细的参数来判断一个树的状态,OSD(Object Storage Device,对象存储设备)容量状态以及连接状态等。因此,在检测到数据读取指令时,根据加权二叉树算法计算读取路径。
进一步地,所述计算模块10,还用于以加权二叉树中发送数据读取指令的结点为起点,根据结点左OSD路径加权值、右OSD路径加权值中较大者及加权二叉树算法计算读取路径。
二叉树的每个结点至多只有二棵子树(不存在度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。二叉树的第i层至多有2^(i-1)个结点;深度为k的二叉树至多有2^k-1个结点;对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1。二叉树算法常被用于实现二叉查找树和二叉堆。加权二叉树算法:加权二叉树是在二叉树的基础上增加w值,即OSD路径加权值。OSD路径加权值的大小由二叉树上相邻结点之间的距离表示,这个距离在分布式文件系统中主要表现为OSD的可使用容量、OSD的状态、某一个子树上的OSD个数,即,如果某一个子树上的OSD越多、都是可用的状态、每个OSD的容量都满足要求的情况下,子结点就拥有优先获得资源的权利。以加权二叉树中发送数据读取指令的结点为起点,根据结点左OSD路径加权值、右OSD路径加权值中较大者及加权二叉树算法计算读取路径。
所述读取模块20,用于根据读取路径确定读取所述数据的节点,从所述结点读取所述数据。
以加权二叉树中发送数据读取指令的结点为起点,以存储要读取的数据的结点为终点,由于要读取的数据在多个节点中均有存储,通过加权二叉树算法计算读取路径,从最短路径对应的节点中读取数据。通过加权二叉树算法可以根据特定的条件快速找到需要的树结点,和二叉树比较具有更详细的参数来判断一个树的状态,OSD容量状态以及连接状态等。
本实施例通过加权二叉树算法可以根据特定的条件快速找到需要的树结点,提高了分布式数据的提取速度。
参照图6,图6为本发明分布式文件系统中节点选择装置的第二实施例的功能模块示意图。所述分布式文件系统中节点选择装置还包括配置模块30及MAP模块40。
所述配置模块30,用于为存储分布式文件的结点组成的二叉树配置OSD路径加权值;
所述计算模块10,还用于以二叉树的根结点为起点,根据HASH算法及OSD路径加权值遍历二叉树中的结点并存入OSD MAP中;
所述MAP模块40,用于根据OSD MAP中的结点信息生成加权二叉树。
在映射策略中,根据权值的优先级实现分布基数,分布基数是指对对象的存储进行组织和位置映射。优先级的高低在部署的初期由默认参数给出,根据二叉树的层数来决定,比如左子树的层数大于右子树的层数,就表示左节点的OSD数目更大,能够满足更多的存储需求,故优先选择左子树。随着OSD的容量在不断的变化以及OSD的状态发生变化,如出现故障等会及时动态调整权值参数。生成二叉树后,配置OSD路径加权值,其过程可描述为:从根结点出发,根据HASH算法查找结点,找到一个结点后,获取此结点权值,权值的内容在加权二叉树算法中有描述,读取其可用的空间大小以及状态,将此结点的数据映射到OSD MAP中,OSD MAP中数据内容为结点的编号、可用空间大小、结点的状态信息。OSD MAP结构为系统中各个模块所共用的结构体,任何的变化都会反映到OSD MAP中。经过下一个结点,已经经过的结点存入OSD MAP中。然后继续查找此结点的子结点,循环此过程。一个结点只会被经过一次,结点经过后就存入到OSD MAP中了,后面算法不会再去判断这个结点,继续往下走。本发明一实施例为存储分布式文件的结点组成的二叉树配置OSD路径加权值;以二叉树的根结点为起点,根据HASH算法及OSD路径加权值遍历二叉树中的结点并存入OSD MAP中;根据OSD MAP中的结点信息生成加权二叉树。
本实施例根据HASH算法及OSD路径加权值等通过运算处理生成加权二叉树,以便运用加权二叉树算法计算路径长度。
参照图7,图7为本发明分布式文件系统中节点选择装置的第三实施例的功能模块示意图。所述分布式文件系统中节点选择装置还包括比较模块50、选择模块60及映射模块70。
所述比较模块50,用于当OSD容量和/或状态变化时,根据HASH算法及OSD路径加权值计算HASH值,并将HASH值与结点左右子树的OSD数目进行比较;
所述选择模块60,用于当HASH值小于左子树的OSD数目时,选择左结点,否则选择右结点;
所述映射模块70,用于将结点重新映射到OSD MAP中。
当OSD容量发生变化和/或OSD的状态(例如,是否可用)发生变化,都需要重新计算HASH值,比较左右的子树,小于左树选择左结点,否则选择右结点,哪边的OSD数目大,也就是容量大,就先选择哪个子树。将结点的容量、状态信息重新映射到OSD MAP中,这里的映射是根据权值来映射,直到遍历完成所有的结点。权值是在遍历的过程中根据读取的OSD个数计算出来的,并记录到OSD MAP中,当要生成加权二叉树时,只需要读取OSD MAP中的信息即可。当OSD容量和/或状态变化时,根据HASH算法及OSD路径加权值计算HASH值,并将HASH值与结点左右子树的OSD数目进行比较;当HASH值小于左子树的OSD数目时,选择左结点,否则选择右结点;将结点重新映射到OSD MAP中。
本实施例当OSD容量和/或状态变化时,对OSD MAP、加权二叉树进行处理,达到实时更新OSD MAP、加权二叉树的目的,保证计算的读取路径的真实有效性。
参照图8,图8为本发明分布式文件系统中节点选择装置的第四实施例的功能模块示意图。所述分布式文件系统中节点选择装置还包括查找模块80及加入模块90。
所述查找模块80,用于当获取到OSD MAP中的结点故障信息时,查找新的结点替代发生故障的结点;
所述加入模块90,用于当所述发生故障的结点恢复正常时,该结点重新加入OSD MAP中。
当OSD MAP中的结点收到通知发生变化时,如设备故障,则需要查找新的结点来替代该结点,新的结点在前述第一次遍历时即记录到了OSD MAP中,因此只需要读取OSD MAP中还有没被完全使用的结点即可找到用于替代该结点的新的结点。如果有一个从未使用过的OSD结点加入进来,该未使用过的OSD结点会将自己的状态告诉OSD MAP,从而通过OSD MAP即可知道此结点为未使用过的结点,将其插入到二叉树中,并根据其容量等信息附上权值。如果之前发生故障的结点又恢复正常,则同样会重新加入并更新到OSD MAP中。本发明一实施例,当获取到OSD MAP中的结点故障信息时,查找新的结点替代发生故障的结点;当所述发生故障的结点恢复正常时,该结点重新加入OSD MAP中。
本实施例当结点发生故障或恢复正常时,实时更新OSD MAP、加权二叉树,保证计算的读取路径的真实有效性。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!