多元模型参数化的制作方法
本发明涉及确定多元泰勒分散法的参数的方法和装置。
背景技术:
泰勒分散法是使用剪切流提高样品有效扩散率的过程。毛细管中的层流导致流速随径向位置变化。靠近壁的地方,流速是基本固定的,并且流速在中心处最大。这导致相邻层的剪切,其起作用从而提高了样品的分散。
泰勒分散分析(tda)可以用于分析样品内物质的性质。可以将一股样品注入到微孔毛细管中,并随后随着它沿层流区内的毛细管穿过而分散。所注入的一股样品可以是狭窄的(具有短持续时间),这被称为样品脉冲,或者所注入的一股样品可以是长的(具有长持续时间),这被称为样品段塞。一股所显示出的分散程度取决于该股内分子的扩散性,并且可以在注入位点下游的一个或多个点处测量。可以将对样品物质敏感的浓度检测器布置在注入位置下游的一个或多个位置。由此,浓度检测器(例如,uv-可见光光谱仪)可以产生与通过检测器的流体的每个横截面中的分子的浓度成正比的信号。从所述检测器产生的信号通常被称为泰勒图,对应于分子浓度的时间分辨分布,其宽度(σ)与样品物质的流体力学半径(rh)有关。两种熟知的泰勒图谱是由一股狭窄(脉冲)样品的注入和一长股(段塞)样品的注入产生的。通过以下高斯-模拟表达式给出由含有单一组分(component,元)的脉冲所产生的泰勒图谱:
其中tr是停留时间,其可以定义为样品在检测器的平均观测时间(对于脉冲泰勒图),σ为泰勒图的宽度并且a是幅度。
在泰勒分散的长时间极限中,这种分布近似高斯模型:
当注入样品段塞(slug)时(相对长持续时间的一股样品),在检测窗观察前部(front),并且泰勒图谱的表达式为:
对于两种注入类型,宽度σ与根据方程4的样品物质的流体力学半径有关:
其中kb是玻耳兹曼常数,t是温度,η为缓冲液粘度,r为毛细管半径并且tr是毛细管中样品的停留时间。此外,泰勒图下的面积与注入样品的浓度成正比。
可以通过用适当的数学模型拟合实验数据来最可靠地确定所述分布的宽度。如果停留时间足够长以满足泰勒分散条件,则可以通过高斯模型(g)近似估计包含单一组分的样品分布:
其中,该模型参数对应于最大幅度(a),停留时间(tr)和分布宽度(σ)。对于包含两个或更多个组分的脉冲(窄股样品),可以通过高斯分布的叠加和来准确模拟所得的泰勒图。例如,含有双组分的样品混合物的模型为:
其中,拟合参数对应于最大幅度(a)、停留时间(tr)和分布宽度(σ),并且下标1和2分别对应于二个组分。
拟合算法可以用于提供接近匹配实验数据的函数。对于函数,现有技术的拟合算法通常需要种子参数。这些种子参数用作初始估计值,由此拟合算法尝试确定最优解。一般地,初始参数估计值越好,即初始估计值越接近最优解,则找到最优解的概率越大。初始估计值越不受约束或越随机,则找到假局部极小值的风险越高,假局部极小值导致错误或无意义的解。对于单组分模型(方程2),模型参数σ、a和tr的初始估计值可以容易地得自泰勒图本身;例如,根据半高宽度、最大峰高和达到最大峰高的时间。然而,对于二组分模型(方程3),初始估计值不能直接得出,这是因为目前存在4个未知参数:a1、a2、σ1和σ2。
泰勒分散分析已经出现作为用于针对多种材料(包括生物药物产物和它们的聚集体)对扩散系数或流体力学半径进行绝对测量的潜在技术(w.hulse,r.forbes,ataylordispersionanalysismethodforthesizingoftherapeuticproteinsandtheiraggregatesusingnanolitresamplequantities,int.jpharmacetics,2011,416:394-397)。
蛋白质分子在溶液中的可逆自结合是短暂聚集过程,在此期间,单个蛋白质分子(单体)通过弱非共价分子间键合而结合以形成多价结构(低聚物)。在这些相互作用中,单个单体保留了它们天然的构象(r.esfandiaryetal,asystematicmultitechniqueapproachfordetectionandcharacterisationofreversibleself-associationduringformulationdevelopmentoftherapeuticantibodies,j.pharm.sci.,2013,102(1):62-72)并且多个单体的结合导致产生了尺寸定义良好的低聚物群体,如二聚体或三聚体。然而,在其中蛋白质浓度较高的情况下,蛋白质-蛋白质相互作用的影响变得更显著,并且如果出现适合的环境条件,则这些可逆、低价聚集体可以起产生较大、不可逆聚集体的前体的作用(a.salujaandd.s.kalonia,natureandconsequencesofprotein-proteininteractionsinhighproteinconcentrationsolutions,2008,358:1-15)。生物治疗药物制剂中的聚集体已表现出被禁止的危急生命的免疫原性反应(m.vanbeers,m.brdor,minimizingimmunogenicityofbiopharmaceuticalsbycontrollingcriticalqualityattributesofproteins,biotechnolj.,2012,7:1-12);改变生物药效率,并且进而改变药物的效力(k.d.ratanjietal,immunogenicityoftherapeuticproteins:influenceofaggregation,jimmunotoxicol,2014,11(2):99-109);以及影响制剂的溶液粘度及其它物理性质(j.liuetal.,reversibleselfassociationincreasestheviscosityofaconcentrationmonoclonalantibodyinaqueoussolution,j.pharm.sci.,2005,94(9):1928-1940);所有这些导致产生了生产、法规和临床问题。因此,对于生物制药行业,蛋白质溶液中可逆和/或不可逆聚集体的存在具有潜在的较大代价的后果。
尝试减轻不可逆聚集体发生的策略包括(i)耐聚集蛋白质工程,(ii)通过溶剂或赋形剂介导,开发物理学更稳定的制剂和(iii)控制最终制剂中可逆聚集体的绝对量。在所有这些方法中,蛋白质群体的组成是重要的质量属性,并且通过候选或最终制剂中可逆聚集体比例的明显减少来测量成效或质量。同时,之后,特别探索了提供有关蛋白质溶液的组成的定性和定量数据的技术;然而,相对少的技术能够在整个开发流水线的所有阶段提供生物治疗制剂的这些信息。
有利地,tda可以容易地适合于高产量生物制药筛选,这是因为它可以使用毛细管电泳设备和uv检测器,如wo2004/017061中所述的和最近在可商购仪器(
(i)具有高多分散性的聚合物的混合物(r.callendarandd.g.leaist,diffusioncoefficientsforbinary,ternary,andpolydispersesolutionsfrompeak-widthanalysisoftaylordispersionprofiles,jsolchem,2006,35(3):353-379),
(ii)含有一个单分散和一个多分散群体的混合物(h.cottetetal,determininationofindividualdiffusioncoefficientsinevolvingbinarymixturesbytaylordispersionanalysis:applicationtothemonitoringofpolymerreaction,anal.chem.,2010,82:1793-1802);和
(iii)包含两个单分散组分的混合物(r.callendaretal,同上)。
后一实例类似于可以在生物药物制剂中出现的情况,由此样品包含通常是单体和二聚体这样的组分的混合物,这种组分对于尺寸是单分散的。tda具有提取完整生物药物制剂的组成数据的潜能并且与现有技术相比具有一些方法学优势。
当前用于分析多元泰勒图的方法为:
a)使用矩量法获得组分的平均(而不是单独的)扩散系数(h.cottetetal,taylordispersionanalysisofmixtures.analchem2007,79(23):9066-9073;b.kellyandd.g.leaist,usingtaylordispersionprofilestocharacterizepolymermolecularweightdistributions.phys.chem.chem.phys.,2004,6,5523-5530)。
b)以泰勒图的部分高度计算平均扩散系数(和扩散系数的线性组合)(r.callendaretal,同上)。
c)使用泰勒图的面积、高度和方差(variance)计算混合物中的聚合度。
d)使用伪随机初始参数估计值,将高斯函数的和拟合于泰勒图(例如,如cottetetal,同上中对二元混合物所述的)。
e)分析得自泰勒图的去卷积(deconvolve)的减少信号。这包括减去来自混合物全局泰勒图的已知组分的贡献(如cottetetal,同上所述)。
尽管tda作为表征组分混合物(例如,在蛋白质聚集期间产生的组分)的方法是有前景的,但是目前仍不存在使用所讨论的分布所固有的数据来提供多元模型的初始估计值的方法。更具体地,在以下提供的所有条件下,现有技术尚无用于多元模型参数化的方法:
1)二组分混合物,其中:
a)所述二组分是不相关的;或者
b)一个组分的尺寸是已知的;或者
c)不相关组分的二组分混合物,但是其中较小组分的吸光度特征较小并且符号(sign)与较大组分的特征不同。(这通常在样品缓冲液和运行缓冲液浓度不同时发生)。
2)二或三组分混合物,其中所述组分是相关的(例如,单体、二聚体和三聚体),但是组分的尺寸和比例是未知的。
3)在二、三或四组分混合物中的所有组分的单独的尺寸是已知的,但是它们在混合物内的比例是未知的,或者反之亦然。
技术实现要素:
本申请的这种方法可以为由样品混合物所产生的泰勒图的流体力学半径和组成提供更准确、可重复和稳健的去卷积,并且使得tda成为生物药物制剂中聚集体(例如,可逆聚集体)表征的更可行的选择。
根据本发明的方面,提供了使用计算机根据得自样品的泰勒图数据估计样品组分的物理性质的方法,其通过以下实现:
将多元泰勒图(taylorgram)模型拟合至泰勒图数据g(t),所述泰勒图数据包含t=tr时多元泰勒图的峰值或前部;所述拟合包括:
估计所述数据的积分或微分值;
基于包含所述数据的积分或微分值的分析表达式,确定所述多元泰勒图(taylorgram)模型的组分的参数。
所述物理性质可以是流体力学半径。
所述方法还可以包括执行泰勒分散以获得所述泰勒图数据。
根据本发明的方面,提供了估计用于将多元泰勒图(taylorgram)模型拟合至包含t=tr时的多元泰勒图峰值或前部的泰勒图数据g(t)的参数的方法;所述方法包括:
估计所述数据的积分或微分值;
基于包含所述数据的积分或微分值的分析表达式确定多元泰勒图(taylorgram)模型的组分的参数,所述参数对应于从中获得泰勒图数据的样品的组分的物理性质。
所述泰勒图峰值可以基本集中在t=tr。
所述泰勒图模型可以包括高斯分布,或者可以包括误差函数。
本发明的申请人已认识到,对包含多元泰勒图峰值或前部的泰勒图数据进行积分或微分提供了可以用于准确估计模型组分参数的信息,所述参数表征了样品组分的物理性质。在上述技术可以基于泰勒图数据确定微分或积分并且可以使用其估计模型参数的程度上,这些参数将对应于样品的平均物理性质,而不是其组分的性质。
估计泰勒图数据的积分或微分值可以包括估计所述数据的一阶微分、二阶微分(例如,
所述方法可以包括基于所述数据估计以下至少两个值,其选自:
x,t=tr时的数据值;
y,所述数据在t=tr时的二阶微分值,
z,开始于或结束于t=tr时的得自于所述数据的积分的值,∫g(t)dt;和
u,开始于或结束于t=tr时的数据的积分的积分值,∫∫g(t)dt2;并且然后
确定参数的估计值,其中确定所述估计值包括求解至少两个联立方程,所述联立方程每个分别包括所述估计值中的一个。
确定所述参数所需的联立方程的数目取决于基于先验知识可能已知(或估计的)模型参数的数目。当仅有两个未知量时,可以使用两个方程。
所述多元泰勒图(taylorgram)模型可以具有一般形式:
或具有一般形式:
并且所述参数可以选自ai和σi。
所述联立方程可以包括以下至少两个:
所述模型可以包括二元(component,组分)泰勒图模型,并且可以满足以下条件中的至少一个:
在估计参数前,a1、a2、σ1、σ2均是未知的;
在估计参数前,σ1和σ2中有一个是已知的,并且a1、a2、σ1、σ2中的剩余参数均是未知的;
所述第二组分具有负值幅度a2,并且所述第二组分的幅度a2小于所述第一组分的幅度a1。
所述模型可以包括二或三元泰勒图模型,其中样品的σi值之间的关系是已知的,并且其中,样品的ai和σi的绝对值是未知的,并且样品ai值之间的比率是未知的。
所述模型可以包括二、三或四元泰勒图模型,其中样品的σ值每一个都是已知的,但是样品的ai值是未知的。
用于估计z和/或u的积分可以开始于t=0并在t=tr结束。同样地,用于估计z的积分可以开始于t=tr并在t=tend结束,其中tend是泰勒图数据的结束时间。所述积分可以具有t=tr时的第一端点,和在其中泰勒图值基本回到基线时的任何时间的第二端点。
所述方法可以包括:
确定数据微分
根据值w、t'和tr确定参数。
当所述泰勒图包含二个组分,并且其中第二组分与第一组分相比幅度相对较小,例如,其中第二组分由样品缓冲液和运行缓冲液之间的不匹配所产生时,该方法可以是特别适合的。
泰勒图模型可以具有一般形式:
所述参数可以选自ai和σi。
所述第二组分可以具有负值幅度a2,并且所述第二组分的幅度大小a2可以小于所述第一组分的幅度大小a1。
这可以对应于样品缓冲液和运行缓冲液之间的缓冲液不匹配,从而样品缓冲液中降低的吸光度导致在泰勒图中产生了负值组分。到目前为止,这些贡献是难以从泰勒图数据中反卷积的,从而对样品组分产生了可靠的估计值。
可以基于以下表达式中的至少一个确定所述参数:
t′=tr±σ1。
可以基于以下表达式中的至少一个确定所述模型的其它参数:
根据本发明的第二方面,提供了估计用于将二元泰勒图模型拟合至数据g(t)的参数的方法,所述数据是包含t=tr时的多元泰勒图峰值或前部的泰勒图,所述方法包括:
对所述数据g(t)进行单元泰勒图模型的最小二乘法拟合;
通过找到三次方程的根确定所述参数,所述三次方程得自于:由一元泰勒图模型拟合至二元泰勒图所产生的积分残方差r2的分析表达式;以及所述数据g(t)的主泰勒图组分(dominanttaylorgramcomponent)的标准偏差σ的先验知识;
所述参数对应于从中获得所述泰勒图数据的样品的组分的物理性质。
二元泰勒图模型可以具有一般形式:
三次方程可以是:
所述方法还可以包括确定样品组分的流体力学半径、样品组分的浓度或第一样品组分和第二样品组分的浓度比。
根据另一个方面,提供了计算机可读介质,其包含一组指令,所述一组指令可操作以使得计算机执行根据本发明的方面的方法。
根据另一个方面,提供了包含计算机或处理器的装置,计算机或处理器被配置以执行根据本发明的方面的方法。
所述计算机可以包括输出单元(例如,显示器或打印机),用于向用户提供参数估计值。所述计算机可以包括输入单元(例如,键盘或鼠标),用于控制所述计算机(例如,选择要确定的参数,输入与所述组分有关的任何先验知识)。
所述装置还可以包括用于执行泰勒扩散分析的工具,以获得所述数据。所述工具可以包括毛细管、泵、样品注入单元和检测器。样品注入单元可以被配置为将样品注入到毛细管内的运行液体中。所述泵可以被配置以驱使运行液体和样品以预定速率或以预定压力通过毛细管。所述检测器可以被配置以产生与通过所述检测器的流体中的分子(或颗粒)的浓度成正比的信号。所述检测器可以包括uv-可见光光谱仪、光电二极管和/或焦平面阵列。
根据另一个方面,提供了分析蛋白质聚集的方法,其包括使用根据本发明的方面的方法。
根据另一个方面,提供了制备产物的方法,其包括使用根据本发明的方面的方法或根据本发明的方面的装置,以研究所述产物的组分的聚集水平。
根据另一个方面,提供了基于根据本发明的方面的方法所产生的产物。
根据另一个方面,提供了一种用于制备产物的装置,其包括产物制备单元(例如,反应器)和工具。所述工具被配置为取样从所述产物制备单元输出的产物,并执行泰勒分散分析以估计产物的组分的物理参数(例如,确定组分的聚集度)。使用来自所述工具的输出以调节所述产物制备单元的操作参数以保持物理参数(例如,聚集度)在预定范围内。
可以将每个方面的可选特征与任何其它方面的可选特征组合。
附图说明
参考附图,将仅通过举例的方式更详细地描述实施方式,附图中:
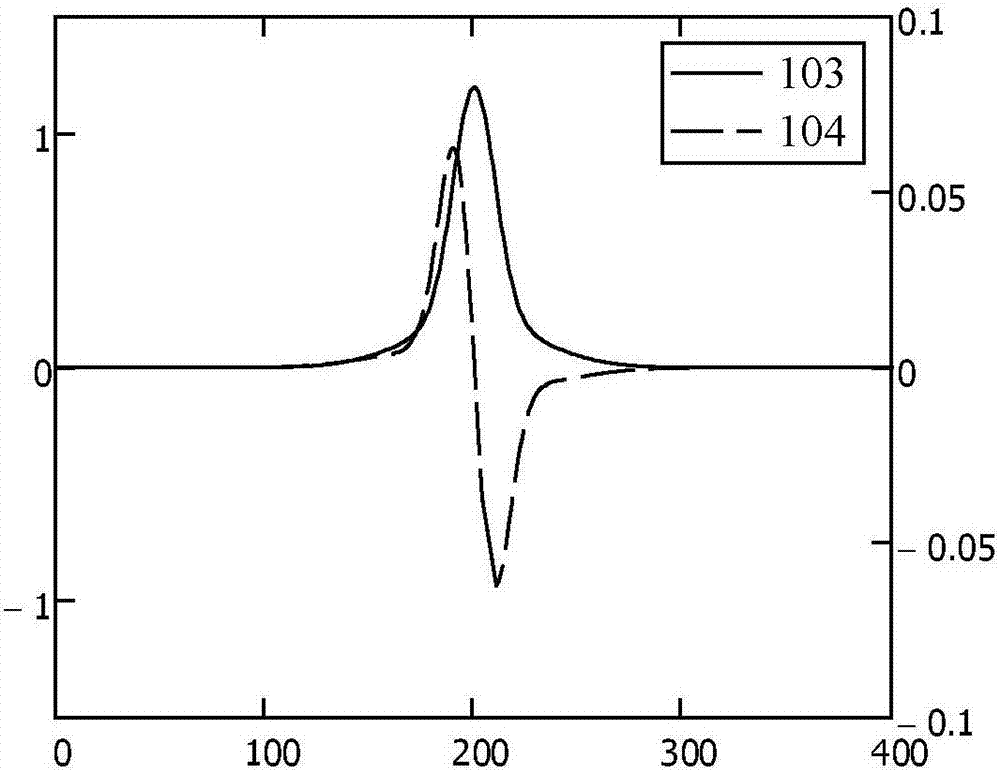
图1是二元高斯泰勒图模型的组成组分的曲线图,其中tr=200、σ1=10s、σ2=30s、a1=1、a2=0.2;
图2是具有其一阶微分的图1的二元高斯模型的曲线图;
图3是具有其二阶微分的图1的二元高斯模型的曲线图;
图4是具有其积分的图1的二元高斯模型的曲线图;
图5是图4的积分的积分(即,模型的二重积分)以及图4的积分的曲线图;
图6是根据实施方式的方法的流程图;
图7是根据另一个实施方式的方法的流程图;
图8是这样的曲线图:包含牛血清白蛋白(bsa)和乙酸的样品的泰勒图数据和所述泰勒图数据的二阶微分,其中样品缓冲液和运行缓冲液之间的缓冲液浓度存在不匹配;
图9是根据另一实施方式的方法的流程图;
图10是根据实施方式的装置的示意性框图;
图11是根据实施方式的用于从样品获得泰勒图数据的装置的示意性框图;
图12是用于制备产物同时监控所述产物的组分的聚集水平的装置的示意性框图;
图13为这样的曲线图:包含咖啡因和bsa的混合物的样品的泰勒图数据;和基于根据实施方式所产生的参数估计值拟合至数据的模型;
图14为这样的曲线图:图13的泰勒图数据和根据现有技术拟合至数据的模型;
图15为这样的曲线图:包含bsa和肌红蛋白的混合物的样品的泰勒图数据;和基于根据实施方式所产生的参数估计值拟合至数据的模型;
图16为这样的曲线图:图15的泰勒图数据和根据现有技术拟合至数据的模型;
图17为这样的曲线图:包含肌红蛋白和免疫球蛋白g(igg)的混合物的样品的泰勒图数据;和基于根据实施方式所产生的参数估计值拟合至数据的模型;
图18为这样的曲线图:图17的泰勒图数据和根据现有技术拟合至数据的模型;
图19为这样的曲线图:磷酸盐缓冲盐水(pbs)缓冲液中igg样品的泰勒图数据,其中样品缓冲液和运行缓冲液之间存在缓冲液浓度的不匹配;和基于根据实施方式所产生的参数估计值拟合至数据的模型;
图20为这样的曲线图:包含igg单体和二聚体的混合物的样品的泰勒图数据;和基于根据实施方式所产生的参数估计值拟合至数据的模型;以及
图21为这样的曲线图:图20的泰勒图数据和根据现有技术拟合至数据的模型。
具体实施方式
在泰勒分散的长时间极限中,可以通过下式近似从包含n个不相互作用的组分的混合物的脉冲泰勒图获得的泰勒图:
其中ai和σi为针对i至n个组分的各自的幅度和泰勒图宽度,tr是所述混合物在观察点的停留时间,并且t为时间。
因此,通过下式近似t=tr(即图1中峰值时间)时的泰勒图x值:
参考图1,示出了第一高斯分布101和第二高斯分布102,其对应于由具有不同流体力学半径(从而导致产生不同的高斯宽度(或标准偏差),σ)的二元的混合物所产生的泰勒图。在该实施例中,第一高斯分布的参数(下标“1”表示)为停留时间,tr=200,第一宽度σ1=10s,第二宽度σ2=30s,第一幅度a1=1,第二幅度a2=0.2。
图2示出了组合模型103以及组合模型103的微分(相对于时间t)104,组合模型103是两个高斯分布101、102的和。图3示出了组合模型103的二阶微分105。
可以在t=tr估计方程7所提供的形式的多元高斯分布的二阶微分105的值,从而给出y如下:
图4示出了模型103的积分106。可以估计方程7所提供的形式的模型的积分106的值i,从而给出z如下:
图5示出了积分106的积分107(即模型103的二重积分)。可以估计方程7所提供的形式的模型的积分的积分值以给出u如下:
4个方程(方程9-11)提供了幅度a和宽度σ的联立方程,对于具有不同组分数的混合物可以求解方程。
根据各个分布的宽度,可以确定各个组分的流体力学半径。此外,通过知悉每个组分的消光系数(将浓度传感器的读数与所讨论的组分浓度相关联),可以通过计算每个单个泰勒图组分下的面积来估计混合物中每个组分的比例。
尽管该实施例涉及其中注入作为脉冲的样品股(具有短持续时间)的情况,但是技术人员将理解,可以对注入作为段塞的样品股(具有长持续时间)的情况写出类似的联立方程组。代替基于描述脉冲泰勒图的方程2,基于描述了段塞泰勒图的方程3,可以写出类似于方程9-11的方程。
参考图6,示出了说明所述方法的流程图150,该方法包括以下步骤:
151,任选地,预处理泰勒图数据(例如,通过移动平均滤波器);
152,估计来自处理的(或原始的)泰勒图数据的x、y、z和u中的至少两个;
153,对方程8至11求解以估计参数a和σ;
154,任选地,通过最小二乘回归精细化参数估计值
155,任选地,基于参数估计值确定样品组分的物理性质。
将公开估计将多元模型拟合至泰勒图数据的参数的说明性方法,其解决了本申请背景技术中提及的每种情况。
这些方法中的每一种可以用于分析地计算对泰勒图数据进行拟合的模型参数的估计值。参数估计值可以用作用于进一步回归分析的起点,其旨在微调参数以最小化参考模型和数据所确定的误差函数。例如,可以提供初始参数估计值作为最小二乘回归的输入,最小二乘回归调节参数以最小化误差平方之和。在一些情况下,参数估计值可以足够准确,从而在无需进一步回归分析的情况下用以确定从中获得数据的样品的性质(例如,流体力学半径或浓度)。
在一些实施方式中,在产生参数估计值之前对泰勒图数据的预处理可能是所期望的。例如,用于进行分析的工具的检测器可能会经受基线漂移。这可以通过(例如)将线性函数拟合至基线数据并基于所述线性函数修正原始的泰勒图来修正。另外或者作为另外一种选择,原始的泰勒图可以经受过滤或平滑操作以除去或减弱高频率成分。例如,可以应用移动平均滤波器(例如,savitzky-golay滤波器)或者对数据进行内插样条拟合,或者应用一些其它平滑/过滤技术。
不相关组分的二元混合物
在这种情况下,先前a1、a2、σ1、σ2均是未知的。4个方程(方程8至11)换算为:
x=a1+a2(方程12)
z=a1σ1+a2σ2(方程14)
对4个方程(12至15)联立求解,给出:
a1=x-a2(方程19)
其中
使用这些方程,可以估计4个未知参数。在其中两个宽度σ1、σ2在幅度方面类似的情况下,有可能获得这些方程的非物理解。为了减轻这种情况,w和k的值可以是不同的(例如,通过伪随机量)直至获得物理解。
其中先前已知组分之一的尺寸的二元混合物
在一个实施方式中,通过整理方程1,可以根据尺寸确定已知组分的宽度σ1。在这种情况下,先前已确定了4个未知参数中的一个,并且以上所提供的4个方程(方程12-15)中的任意三个可以用于获得剩余参数的初始估计值。存在可以使用的3个方程的4种这样的组合。
在替代实施方式中,最小二乘法拟合方法找到了对给定数据点集的最佳拟合,其最小化数据点与拟合偏移的平方和(残差)。例如,对于数据集yi,最佳拟合函数f(t,a1…an)随时间t和参数a1…an改变,它是最小化残差r2之和的函数,如以下所提供的:
r2=∑[yi-f(t,a1,…,an)]2(方程22)
因此,单个高斯分布针对二元脉冲泰勒图(等式6)的最小二乘法拟合找到了最小化残差r2的解,如以下所提供的:
其中as和σs分别是拟合的高斯分布的幅度和宽度。
该和可以被估计为随时间的积分,以提供:
为了找到最小值,可以相对于as和σs对方程24求导,并且方程24可以等于0以提供以下联立方程:
假设组分1的流体力学半径的先验知识(以及因此的σ1)并且由于泰勒图的峰高apeak等于a1和a2的和,因此方程25和26可以联立求解以提供σ2(以及因此的流体力学半径)作为以下三次方程的解:
其中
那么,可以通过代入方程25和27确定a1和a2(以及因此从中获得泰勒图的样品中的二元的相对比例)。
尽管已相对于脉冲泰勒图再次描述了以上实例,但是技术人员将理解,可以将类似方法应用于其中泰勒图模式对应于段塞泰勒图的情况(如方程3所述)。
参考图7,示出了说明所述方法的流程图160,该方法包括以下步骤:
161,任选地,预处理泰勒图数据(例如,通过移动平均滤波器);
162,通过最小二乘回归将单元高斯模型拟合至所述数据来确定单元模型参数,
163,基于单元泰勒图模型的参数和样品组分参数的先验知识,通过对方程27求解来估计多元模型参数;
164,任选地,通过最小二乘回归精细化参数估计值;
165,任选地,基于参数估计值确定样品组分的物理性质。
二组分混合物,其中第二组分的幅度小于第一组分的幅度,并且与第一组分的幅度的符号不同
这种情况可以在其中样品和运行缓冲液之间存在不匹配的情况下出现,并且可以由于蒸发、样品处理不当或者样品/缓冲液组分在存储期间发生变化引起。在图8中示出了样品和运行缓冲液之间的不匹配对所得泰勒图数据的影响。在本实施例中,样品缓冲液的浓度低于运行缓冲液的浓度,这表示为对浓度曲线图的负值贡献。
在这种情况下,我们考虑了不相关的二组分(即样品和样品缓冲液)的混合物。需要应用二元模型,从而可以提取样品的真实宽度。
图8示出了在样品缓冲液和运行缓冲液的不匹配导致产生具有负值幅度的第二泰勒图组分的情况下获得的脉冲泰勒图数据110的实例。在该情况下,所述样品包含bsa/乙酸。bsa在泰勒图数据110中产生第一泰勒图组分,而缓冲液不匹配导致在数据110中产生具有负值幅度的第二泰勒图组分。
对于二组分的任何混合物,存在4个未知参数:a1、a2、σ1和σ2,并因此需要4个方程以估计用于拟合算法的初始猜测。可以根据迹线下沉(dip)处(即,t~tr)的吸光值x获得第一方程。
x=a1+a2(方程12)
根据曲线图的最大微分绝对值w获得第二和第三方程。对于单组分拟合,这具有以下绝对值:
对于显示缓冲液不匹配的曲线图,w受样品组分的控制并因此可以通过下式近似:
通过下式给出单组分拟合的最大绝对值的位置:
t′=tr±σ1(方程33)
由于第一组分是主要的,因此来自方程33的t'值近似于二元泰勒图数据的最大值w的时间。
在迹线下沉(dip)处(对应于t=tr),第二微分105不为0并且为正如图8所示,(对于单组分迹线,它在t=tr时将为负值)。通过下式提供y值:
仅使用方程30和方程31,可确定a1和σ1两者。一旦获得了这些参数的估计值,则通过直接代入,根据方程12和方程13直接获得a2和σ2的估计值。
参考图9,示出了方法的流程图170,其包括:
171,任选地,预处理数据;
172,对泰勒图数据求导;
173,根据微分数据确定w和t';
174,根据w和t'估计多元模型的参数;
175,任选地,通过执行最小二乘回归精细化所估计的参数;
176,任选地,确定对应于所估计的参数的样品组分的物理性质。
具有已知尺寸比的二或三组分
在这种情况下,仅有一个未知宽度,这是因为另一个(或在三组分的情况下,另两个)通过先前已知的比值是相关的。对于三组分的情况,存在三个未知幅度和一个未知尺寸或宽度。因此,通过相应的4个方程(参照方程8-11),可以关于以下求解这4个未知量(a1、a2、a3和σ1):
x=a1+a2+a3(方程34)
其中a和b分别是第二和第三组分与第一组分的已知尺寸比。
这些联立方程可以简化为使用熟知方法可以求解的σ1的单一四次方程。根据该解,可以通过代入对a1、a2和a3做出估计。通过对4个相应方程中的任意3个求解,可以针对二元混合物获得类似的解。
具有已知尺寸的四组分中的2个、3个
在这种情况下,由于尺寸(并因此宽度)已知,仅有的未知量是幅度。因此,对于一般情况,通过将它们简化为矩阵方程,可以针对n个未知量(an)求解4个方程(8-11)。以下是适用于n=4组分的方程:
其中σ1、σ2、σ3和σ4是先前已知的(根据方程4确定)。然后,可以通过熟知的矩阵方法对其求解以获得a1、a2、a3和a4的初始估计值。注意,对于二(和三)组分混合物,从4个方程中的任意两个(和三个)构建的2×2(和3×3)矩阵可以用于获得初始估计值。
装置
参考图10,根据实施方式示出了装置40。装置40包含工具50、处理器51、输出单元52和输入单元53。所述工具50可操作以对样品执行泰勒分散分析,从而产生泰勒图数据71。根据实施方式(例如,如上所述),处理器51被配置为估计用于将多元高斯模型拟合至泰勒图数据71的参数。处理器51可以为输出单元52提供输出72,其中,输出单元可以包括显示器或打印机。输出72可以包括基于通过处理器51拟合至数据71的模型的模型参数估计和/或通过所述工具50分析的样品性质的估计。所述处理器51可以被配置以使用估计的模型参数(根据实施方式确定)作为对泰勒图数据71的最佳拟合(例如,通过基于最小二乘法的回归分析)的数值搜索的起点。可以提供输入单元53来控制所述处理器51和/或工具。所述输入单元53可以包括键盘、鼠标或其它适合的用户接口装置。
参考图11,示出了根据实施方式的工具50的三个图。所述工具50包括连接两个容器v1和v2的毛细管2。驱使液体(例如,在恒压下)从容器v1到容器v2。容器v1含有运行(或载体)溶液s,从而初始用运行溶液填充毛细管2。然后,将容器v1与毛细管2断开,并连接含有样品溶液a的第三容器v3。所述样品a可以是溶解在运行/载体溶液s中或不同媒介si中的药物或生物药物物质。在具有赋形剂(例如盐或糖)方面si可以不同于s,即,以不同于s的浓度溶解。在设计以稳定活性药物物质的制剂中,这可以是适合的。
沿容器v1、v2之间的毛细管2的长度间隔开窗口w1、w2。毛细管2可以形成为环路,从而可以使用单个光学组件对窗口w1、w2两者进行拍摄,例如,通过将它们布置为在由区域拍摄检测器6的像素阵列所拍摄的区域中彼此邻近。在其它实施方式中,可以使用单个窗口,或者检测器6可以包含单个元件,而不是像素阵列。
为了将一股样品a注入毛细管2,可以将第三容器v3连接到毛细管2,然后在压力下将合适体积的样品a注入后断开。当第三容器v3与毛细管2断开时,将第二容器v2连接至毛细管。检测器6捕获包含在检测器6所接收的光强度的测量的帧序列作为样品溶液4或穿过每个窗口w1、w2的流体前部的脉冲。检测器输出借此提供关于吸光度相对于时间的数据:泰勒图。
图12示意性示出了用于制备产物74的装置45。所述装置45包含用于产生产物74的设备60。所述设备60可以是反应器,并且所述产物74可以是药剂和/或生物药物产物。通过装置40对从所述设备60输出的产物74进行取样,所述装置40执行泰勒分散分析以研究产物74内的组分。基于从所述装置40输出的信号,可以调节所述设备60的操作参数75。例如,所述装置40可以监控产物74中的聚集度,并且调节所述设备60以保持所需的聚集水平(例如,低于/高于阈值,或在范围内)。
实施例
二组分混合物
制备了二组分混合物的三种不同组合,并使用malvern
所述混合物为:
1.咖啡因和bsa(图13和14所示);
2.bsa和肌红蛋白(图15和16所示);
3.肌红蛋白和igg(图17和18所示)。
所述工具包括两个测量位置,其具有两个不同的相应停留时间,并因此每个分析产生了两组泰勒图数据。模型可以被独立拟合至来自传感器位置或基于使来自基于常规模型参数的两组数据的误差最小化的输出。
图13示出了针对包含咖啡因和bsa的样品分别在第一位置和第二位置所获得的泰勒图数据601、602。将基于根据实施方式确定的参数估计值所获得的第一模型组分604、606和第二模型组分603、605叠加在数据601、602上。为了避免使数据601、602模糊,未显示组合模型,但是拟合是良好的。第二模型组分603、605的贡献是显著的。参考图14,对相同数据进行基于所述参数的伪随机起始值的最小二乘法分析产生了质量较差的模型。多元高斯分布的最小二乘回归具有情况不佳的问题,仅通过回归是难以解决的。
图15示出了针对包含bsa和肌红蛋白的样品分别在第一位置和第二位置所获得的泰勒图数据601、602。将基于根据实施方式确定的参数估计值所获得的第一模型组分604、606和第二模型组分603、605叠加在数据601、602上。此外,所述拟合是优秀的,并且第二组分603、605的贡献是显著的。参考图16,对相同数据进行基于所述参数的伪随机起始值的最小二乘法分析产生了对泰勒图误导性的良好拟合,其实际上是不正确的。根据该模型估计的所述第一组分的流体力学半径将错了显著的余量,并且所述第二组分的幅度显著低估。
图17示出了针对包含肌红蛋白和igg的样品分别在第一位置和第二位置所获得的泰勒图数据601、602。将基于根据实施方式确定的参数估计值所获得的第一模型组分604、606和第二模型组分603、605叠加在数据601、602上。此外,所述拟合是优秀的,并且第二组分603、605的贡献是显著的。参考图18,对相同数据进行基于所述参数的伪随机起始值的最小二乘法分析仍产生了对泰勒图还算好的拟合,但它是不正确的。根据该模型估计的所述第一组分的流体力学半径将是不正确的,并且所述第二组分的幅度显著低估。
下表1示出了根据实施方式的通过使用参数估计值所获得的准确度。
表1:得自二组分拟合的流体力学半径结果
基于参数估计值确定的流体力学半径与混合物的已知流体力学半径良好一致。
缓冲液与未知样品的不匹配
图19示出了通过对包含溶解于pbs缓冲液中的igg的样品进行泰勒分散分析所获得的泰勒图数据601、602。在样品和运行(run)缓冲液之间故意引入缓冲液不匹配,从而缓冲液浓度变化结果对泰勒图数据有影响。
根据实施方式,估计模型参数,并将模型参数用作最小二乘回归分析的起点以将模型参数拟合至所述数据。图19中示出了每个拟合模型的第一组分603、605(对应于样品的igg组分)、每个拟合模型的第二组分604、606(对应于缓冲液不匹配)和组合模型607、608。存在与数据的明显的匹配,并且有效除去了缓冲液不匹配的影响。这表明了实施方式使得能够可靠且准确估计要提供的样品性质,甚至在有挑战的测量条件中。表2示出了从分析4个泰勒分散分析所获得的平均流体力学半径。
表2:从对缓冲液不匹配的拟合所获得的流体力学半径结果
在没有igg组分或缓冲液不匹配的先验知识的情况下进行分析。
具有已知尺寸的二个组分的混合物
当溶解于pbs缓冲溶液中时,免疫球蛋白(igg)单体和二聚体的流体力学半径分别为5.2nm和7nm。为了确定igg样品中低聚物的相对比例,根据实施方式,获得了3个泰勒图,并使用通过固定组分尺寸以及因此它们的伪高斯宽度所产生的初始参数估计值拟合该3个泰勒图。然后,计算每个组分拟合下方的面积以获得样品中单体和二聚体的相对比例。
图20示出了基于根据实施方式所产生的参数估计值所获得的模型拟合的实例。示出了泰勒图数据601以及第一模型组分603和第二模型组分604。表3提供了得自3个这种分析的平均比例。
为了比较,图21示出了通过无预定估计值(即伪随机)所得的拟合,其中最佳拟合是用于第二组分具有负值幅度的模型。
已描述了本发明的实施方式,其解决了样品表征中的多个重要问题。本发明的实施方式使得泰勒分散分析成为制剂(例如,生物药物制剂)中聚集体表征的更可行的选择。
尽管已关于脉冲泰勒图广泛地描述了实施例,但是本领域的技术人员将理解,可以将类似方法应用于其中泰勒图模式对应于段塞泰勒图的情况(如方程3所述)。适用于段塞泰勒图的方程是更长的,但是直接使用(例如)软件(如wolframmathematica)产生。
在所附权利要求所限定的本发明的范围内,各种变形是可行的。
权利要求书(按照条约第19条的修改)
1.一种用于通过计算机将多元泰勒图模型拟合至从所述样品获得的泰勒图数据g(t)来估计样品的流体力学半径的方法,所述泰勒图数据包含t=tr时多元泰勒图峰值或前部,所述方法包括:
估计数据的积分或微分值;
基于包含所述数据的积分或微分值的分析表达式确定所述多元泰勒图模型的组分的所述流体力学半径。
2.根据权利要求1所述的方法,进一步包括对所述样品执行测量以获得所述泰勒图数据。
3.根据权利要求1或2所述的方法,其中,估计数据的积分或微分值包括估计以下中的至少一个:所述数据的一阶微分、所述数据的二阶微分、所述数据的三阶微分、所述数据的一次积分、所述数据的二次积分和所述数据的三次积分。
4.根据任一前述权利要求所述的方法,包括:
基于所述数据,估计至少两个值,所述至少两个值选自:
x,t=tr时所述数据的值;
y,t=tr时,所述数据的二阶微分值
z,得自于开始于或终止于t=tr的所述数据的积分值,∫g(t)dt;和
u,开始于或终止于t=tr的所述数据的积分的积分的值,∫∫g(t)dt2;并且,然后
确定所述流体力学半径的估计值,其中确定所述估计值包括求解至少两个联立方程,所述联立方程每个分别包括所述估计值中的一个。
5.根据任一前述权利要求所述的方法,其中,所述联立方程包括以下中的至少两个:
6.根据权利要求5所述的方法,其中,所述模型包括二元泰勒图模型,并且其中满足以下条件中的至少一种:
在估计所述流体力学半径前,a1、a2、σ1、σ2均是未知的。
在估计所述流体力学半径前,σ1和σ2中的一个是已知的,并且a1、a2、σ1、σ2中剩余参数均是未知的;
第二组分具有负值幅度a2,并且所述第二组分的幅度a2小于第一组分的幅度a1。
7.根据权利要求5所述的方法,其中:
i)所述模型包括二元或三元泰勒图模型,并且其中,所述样品的σi值之间的关系是已知的,并且其中,所述样品的ai和σi的绝对值是未知的,并且所述样品的ai值之间的比率是未知的;或者
ii)所述模型包括二元、三元或四元泰勒图模型,并且其中所述样品的σi值均是已知的,但是所述样品的ai值是未知的。
8.根据权利要求1或2所述的方法,包括:
确定所述数据的微分
根据w、t'和tr值确定所述流体力学半径。
9.根据权利要求8所述的方法,其中,所述泰勒图模型具有以下一般形式:
以及,所述方法包括确定选自ai和σi的参数,和
第二组分具有负值幅度a2,并且所述第二组分的幅度大小a2小于第一组分的幅度大小a1。
10.根据权利要求9所述的方法,其中,基于以下表达式中的至少一种确定所述流体力学半径:
t′=tr±σ1。
11.根据权利要求10所述的方法,其中,基于以下表达式中的至少一种确定所述模型的其它参数:
12.一种用于通过计算机将二元泰勒图模型拟合至数据g(t)来估计样品的流体力学半径的方法,所述数据是从所述样品获得的泰勒图并且包含t=tr时多元泰勒图峰值或前部,所述方法包括:
对所述数据g(t)进行单元泰勒图模型的最小二乘法拟合;
通过找到三次方程的根,确定所述流体力学半径,所述三次方程来源于:由一元泰勒图模型对二元泰勒图分布的拟合所产生的积分残方差r2的分析表达式;以及所述数据g(t)的主泰勒图组分的标准偏差σ的先验知识。
13.根据权利要求12所述的方法,进一步包括对所述样品执行测量以获得所述泰勒图数据。
14.根据权利要求12或13所述的方法,其中,所述二元泰勒图模型具有一般形式:
所述三次方程为:
15.一种计算机可读介质,包含一组指令,所述一组指令可操作以使得计算机执行根据任一前述权利要求所述的方法。
16.一种包含处理器的装置,被配置以执行根据权利要求1至14中任一项所述的方法。
17.根据权利要求16所述的装置,还包含执行泰勒分散性分析的工具,以获得所述数据。
- 还没有人留言评论。精彩留言会获得点赞!