利用符号快速错误检测的硅后验证和调试的制作方法
相关申请的交叉引用
本申请要求2015年6月6日提交的美国临时专利申请序列号62/172,091的权益。
本公开一般涉及集成电路(ic),且更特别地涉及用于对包括片上系统(soc)的集成电路进行有效的硅后验证和调试的方法和结构。
背景技术:
正如本领域的技术人员将容易理解的那样,集成电路及构建于其上的系统的功能性和普遍性正以惊人的速度发展。因此,这种电路和系统已经对当代社会产生了深远的影响。鉴于它们的重要性,用于检验和/或验证这些电路和系统的方法和结构将为本领域带来受欢迎的补充。
技术实现要素:
根据本公开的一方面,涉及用于检验、验证和调试集成电路及于其上构建的片上系统的改进的方法和结构推进了本领域的发展。
我们将根据本公开的方法和结构称为符号快速错误检测(symbolicquickerrordetection)或符号qed。符号qed的说明性特征包括:1)适用于任何片上系统(soc)设计,只要包含至少一个可编程处理器(对于现有soc来说该假设通常都是有效的);2)广泛适用于处理器内核、加速器和非内核组件内的逻辑漏洞(bug);3)不需要故障复现;4)漏洞定位期间不需要人工干预;5)不需要跟踪缓冲区;6)不需要断言(assertion);和7)使用称为“变化检测器(changedetector)”的硬件结构,仅引入小面积占用。
我们通过以下所述展示符号qed的有效性和实用性:1)符号qed能够在几个小时内(在opensparc上少于7小时)正确自动地定位困难的逻辑漏洞,利用传统方法这需要花费数天或数周的时间来定位;2)对于每个检测到的漏洞,符号qed提供一组候选组件,代表该设计中漏洞的可能位置;3)对于每个检测到的漏洞,符号qed利用形式化分析自动生成最小漏洞跟踪;4)符号qed生成的漏洞跟踪比通过传统硅后技术生成的短6个数量级,比qed短5个数量级。
符号qed需要以下步骤协调进行:1)在设计阶段插入“变化检测器”的系统的(和自动的)方法;2)快速错误检测(qed)测试,以较短的错误检测延迟和高覆盖率检测漏洞;和3)形式化技术,根据漏洞检测实现漏洞定位和生成最小漏洞跟踪。
与现有技术的方法形成鲜明对比,符号qed在硅后验证和调试期间自动定位soc中的逻辑漏洞,从而实现极快速错误检测和定位,有利地改进了调试和所得系统的性能以及显著的生产率和上市时间利益。
附图说明
通过参照附图可以实现对本公开更完整的理解,其中:
图1所示为根据本公开的一方面,示出符号qed的概览的示意性流程图;
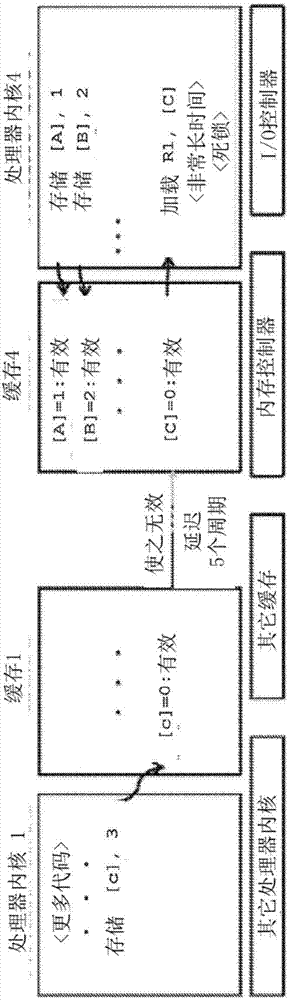
图2所示为根据本公开的一方面,一种示例性的漏洞场景;
图3所示为根据本公开的一方面,示出说明性qed模块接口的示意性框图;
图4所示为根据本公开的一方面,说明性qed模块的伪代码列表;
图5(a)和5(b)所示为qed模块对图5(a)原始指令序列以及图5(b)根据本公开的一方面执行的实际指令的qed转换的说明性实例;
图6(a)和6(b)所示为根据本公开的一方面,6(a)中处于高电平的说明性的变化检测器以及图6(b)中变化检测器的细节的示意性框图。
图7所示为根据本公开的一方面,说明性的部分实例化方法的示意性流程图;
图8所示为根据本公开的一方面,描述opensparct2图表的示意性框图;
图9所示为根据本公开的一方面,示出由符号qed定位的漏洞的候选模块列表的故障百分比的图像,其中所有的92个漏洞都被正确地定位;
图10所示为根据本公开的一方面,描述符号qed的说明性运行的bmc运行时间的图表。
图11所示为根据本公开的一方面,描述符号qed的说明性运行的跟踪长度的图表。
图12所示为根据本公开的一方面,描述在fft和mmult基准测试期间激活的92个漏洞的变化检测器简化设计结果的图线;
图13(a)和13(b)所示为根据本公开一方面,当inst_min=inst_max=3时,说明性的eddi-v示例的原始测试(图13(a))和转换测试(图13(b));以及
图14(a)和14(b)所示为根据本公开的一方面,当inst_min=inst_max=4时plc转换示例的转换代码(图14(a))和plc操作(图14(b);以及
图15所示为一种说明性的计算机系统,其上可以运行和执行根据本公开的方法和结构。
具体实施方式
以下所述仅说明了本公开的原理。因此可以理解,本领域的技术人员将能够设计出各种设置,尽管此处没有明确描述或示出,但体现了本公开的原理,并且应包括在其精神和范围内。更特别地,尽管阐述了许多具体细节,但应当理解,本公开的实施例可以在没有这些具体细节的情况下实施,并且在其它情况下,公知的电路、结构和技术未被示出以便不致混淆对本公开内容的理解。
此外,此处叙述的所有示例和条件语言主要旨在明确仅用于教学目的,以帮助读者理解本公开的原理和发明人为促进本领域而贡献的理念,并且应理解为不限于这些具体叙述的示例和条件。
此外,此处本公开叙述原理、方面和实施例的所有陈述以及其具体示例旨在涵盖其结构上和功能上的等同物。另外,这种等同物包括当前已知的等同物,以及将来开发出的等同物,即所开发出的执行相同功能的任何元件,而不管结构如何。
因此,例如,本领域的技术人员将理解,此处的图表表示实施本公开的原理的说明性的结构的概念视图。
另外,本领域的技术人员将理解,任何流程表、流程图、状态转换图、伪代码等都表示可以基本上在计算机可读介质中表示并由计算机或处理器执行的各种程序,而不管这种计算机或处理器是否有明确示出。
在本文的权利要求中,表达为用于执行特定功能的装置的任何元件旨在包含执行该功能的任何方式,包括,例如,a)执行该功能的电路元件的组合或b)任何形式的软件,因此包括,固件、微码等,与用于执行该软件以执行该功能的适当的电路组合。由这样的权利要求限定的本发明需要由各种所叙述的装置提供的功能以权利要求所要求的方式组合和组合在一起。因此,申请人认为可以提供此处所示的功能的任何手段都是其等同物。最后,除非在此另外明确指出,否则附图不是按比例绘制的。
因此,例如,本领域的技术人员将理解,此处的图表表示实施本公开的原理的说明性的结构的概念视图。
术语
以下术语包括提供的定义以帮助进一步理解本公开。
快速错误检测(qed)——一种涉及将现有的硅后验证测试转换为新验证测试以减少错误检测延迟的技术。qed转换允许在错误检测延迟、覆盖率和复杂度之间进行灵活的权衡,并且可以用软件实现,而很少或不需要硬件改变。
漏洞(bug)——计算机程序或系统中导致或以其它方式对其产生不正确或意外的结果或以非预期的方式运行的错误、缺陷、失效或故障。
电气漏洞(electricalbugs)——是一种仅在特定运行条件(电压、频率、温度等)下出现的漏洞类型,可能由设计边缘性、同步问题、噪音等引起。
逻辑漏洞——是一种由一个或多个设计错误引起的漏洞类型。逻辑漏洞包括不适当的硬件实施方式或硬件实施方式与低层级系统软件(例如,固件)之间的不适当的交互。
片上系统(soc)——将系统的所有组件集成到单个芯片或集成芯片组中的集成电路(ic)。其可以包含数字、模拟、混合信号和射频功能。soc还可以指将系统的所有部分封装或以其它方式集成在单个集成电路上的技术。
非内核——soc中既不是处理器内核也不是处理器(例如,图形处理单元)的组件。非内核组件的实例包括缓存控制器、内存控制器和互连网络。
以下所述仅说明了本公开的原理。因此可以理解,本领域的技术人员将能够设计出各种设置,尽管此处没有明确描述或示出,但体现了本公开的原理,并且应包括在其精神和范围内。更特别地,尽管阐述了许多具体细节,但应当理解,本公开的实施例可以在没有这些具体细节的情况下实施,并且在其它情况下,公知的电路、结构和技术未被示出以便不致混淆对本公开内容的理解。
通过一些另外的背景,我们首先注意到集成电路的硅后验证和调试已经成为其设计、测试、制造和支持方面至关重要的一步。通常,硅后验证和调试是半导体ic开发的最后一步,发生在硅前验证和大批量生产之间。
值得注意的是,硅后检验、验证和调试与硅前验证或调试过程形成对比,其中在硅前处理期间,设备通常在具有复杂模拟、仿真和正式验证工具的虚拟环境中进行测试。
不幸的是,仅硅前验证过程不足以验证当代集成电路,特别是soc的正确运行。本领域的技术人员将理解,这种传统的现有技术的硅前技术通常太慢且不能充分地解决电气漏洞。因此,本领域的技术人员越来越依赖于系统级验证(即仿真)和硅后验证(psv)技术。
与硅前验证过程形成鲜明对比,在硅后验证和调试期间,实际制造的ic在实际系统操作环境(即,速度、真实的板等,使用逻辑分析仪和其它基于断言的工具)中进行测试,以检测并修复设计或其它缺陷(通常称为漏洞)。因此正确的硅后验证和调试是至关重要的,因为,如上所述,仅硅前验证往往不足以检测所有可能的漏洞。
还要注意,硅后验证和调试的成本正在上升。将各种组件大量集成到极其复杂的soc中——可能包括多个处理器内核、用于图形或密码的加速器以及非内核组件(也称为嵌套或北桥组件)——大大加剧了硅后验证和调试的挑战。
一般来说,ic的硅后验证和调试涉及三个活动,即:
1)通过施加适当的激励(即,测试程序)来检测漏洞;
2)将漏洞定位到ic内的一个小区域;以及
3)通过软件补丁、电路编辑或硅“再开发”来修复漏洞。
在这一点上,要注意的是,从观察到的故障(硅后漏洞定位)定位漏洞的努力往往占硅后验证和调试成本的大部分。这种硅后漏洞定位涉及识别激活和检测漏洞的输入(例如,指令)的序列(也称为漏洞跟踪)以及漏洞(可能)位于的任何物理硬件(设计区块)。
本领域的技术人员将容易理解,硅后漏洞定位是特别困难的,因为许多现有的硅后技术依赖于:1)系统级仿真以获得预期或“金”系统响应;和/或2)故障复现——这涉及使系统返回到无错误状态,并以确切的输入激励(例如,验证测试指令;验证测试输入;电压、温度和频率操作条件;以及中断)使系统再度运行——使故障复现。
因此,本领域的技术人员将认识到根据本公开的方法和结构为定位ic中和复杂的soc中的逻辑漏洞的系统化和自动化的技术。进一步将认识到,没有用于验证这种ic和soc的正确运行的这种有效的方法和结构——由此构造的未来的系统将仍然容易受到可能危及正确的电路和/或系统运行的逻辑和电气漏洞。
我们将根据本公开的方法和结构称为符号快速错误检测或符号qed。符号qed的说明性特征包括:1)适用于任何片上系统(soc)设计,只要包含至少一个可编程处理器(对于现有soc来说该假设通常都是有效的);2)广泛适用于处理器内核、加速器和非内核组件内的逻辑漏洞;3)不需要故障复现;4)漏洞定位期间不需要人工干预;5)不需要跟踪缓冲区;6)不需要断言;和7)使用称为“变化检测器”的硬件结构,仅引入小面积占用(在opensparc上为1.86%)。
我们通过以下所示说明符号qed的有效性和实用性:1)符号qed能够在几个小时内(在opensparc上少于7小时)正确自动地定位困难的逻辑漏洞,利用传统方法这需要花费数天或数周的时间来定位;2)对于每个检测到的漏洞,符号qed提供一组候选组件,代表该设计中漏洞的可能位置;3)对于每个检测到的漏洞,符号qed利用形式化分析自动生成最小漏洞跟踪;4)符号qed生成的漏洞跟踪比通过传统硅后技术生成的短6个数量级,比qed短5个数量级。
正如我们将要描述的并且本领域的技术人员将理解的那样,符号qed采用以下有利地以协调的方式一起工作的方法,即1)在设计阶段期间插入“变化检测器”的系统的(和自动的)方法);2)快速错误检测(qed)测试,检测漏洞的错误检测延迟短、覆盖率高;和3)形式化技术,通过漏洞检测实现漏洞定位和生成最小错误跟踪。
参照图1可以观察到根据本公开的符号qed的概览。可以观察到,符号qed涉及两个不同的阶段,即设计阶段和硅后验证阶段。如该图所示,设计阶段系统地且自动地将变化检测器插入到设计中。硅后验证阶段涉及运行qed测试,其中变化检测器记录调试信息,并且如果检测到错误,则通过形式化分析来定位漏洞并生成漏洞跟踪报告。
激励示例
现在我们展示并说明一种从实际漏洞抽象出的漏洞场景,其很难检测,是在商业多核soc的硅后验证期间发现的。该场景描述为:在2个周期中到一缓存的相邻的缓存线的两个存储延迟该缓存接收到的下一个缓存一致性消息5个时钟周期。
只有当两个存储操作在彼此的2个时钟周期内发生到相邻的缓存线时,该漏洞才被激活。由于缓存的接收缓冲区中的延迟,下一个缓存一致性消息(例如,无效)延迟(这些细节在发现和定位该漏洞之前是未知的)。
在硅后验证期间,在soc上运行的测试形成死锁。如图2中所示,由于其中一个处理器内核(内核4)在2个时钟周期内执行存储到内存位置[a],然后存储到内存位置[b]([a]和[b]缓存在相邻的缓存线上)。结果,示例的漏洞场景在缓存4中被激活。
在漏洞被激活后,处理器内核1执行一到内存位置[c]的存储。由于内存位置[c]缓存在多个缓存(缓存1和缓存4)中,所以至内存位置[c]的存储操作必须使内存位置[c]的其它缓存副本(包括缓存4中的缓存副本)无效。但是,由于该漏洞,缓存4接收到的失效消息延迟了5个时钟周期。
在出现任何失效前,处理器内核4从内存位置[c]加载。由于缓存4中的内存位置[c]的缓存副本仍然被标记为无效,因此它加载了旧的副本(此时其包含了错误的值)。然后,在数百万个时钟周期之后,处理器内核4在执行锁定的代码中使用内存位置[c]的错误的值,导致死锁。
当检测到诸如这种死锁时(例如,通过利用超时),必须通过识别漏洞跟踪和漏洞所在的组件来定位漏洞。由于事先并不知道漏洞何时被激活或者系统何时进入死锁,所以得到漏洞跟踪是非常困难的。
此外,由于较长的错误检测延迟,漏洞跟踪可能会非常长,包含许多对于激活或检测漏洞来说不必要的无关指令。如上所述,使用诸如故障复现、跟踪缓冲区、模拟或单纯的形式化方法等传统方法对这种漏洞进行定位可能会极其艰巨。
有利地——且正如我们将要描述的那样——符号qed正确地将该漏洞定位至缓存4,并产生只有3个指令长的漏洞跟踪。进一步有利地,符号qed只需2.5小时即可自动生成该跟踪,而无需故障复现或跟踪缓冲区。
与之形成鲜明对比,传统的硅后漏洞定位方法可能需要手动操作或跟踪缓冲区(或两者都有),且可能需要几天或几周的时间。进一步有利地,符号qed还提供了基于仿真的验证期间的漏洞检测和定位的机会,使得即使该彻底缩短的漏洞检测和定位也可以完全通过根据本公开的方法即符号qed来规避。
快速错误检测(qed)——一般的qed已知可以快速检测处理器内核以及非内核组件中的错误。纯软件qed技术利用各种qed转换,例如利用用于验证的复制指令的错误检测(eddi-v)和主动加载和检查(plc),自动将现有的硅后验证测试(原始测试)转换为新qed测试。
eddi-v——eddi-v针对处理器内核漏洞,通过频繁检查原始指令的结果以及由eddi-v创建的复制指令的结果。首先,寄存器和内存空间分成两半,一半用于原始指令,一半用于复制指令。接下来,原始和复制指令的相应寄存器和内存位置初始化为相同的值。然后,对于原始测试中的每一加载、存储、运算、逻辑、移位或移动指令,eddi-v都会创建对应的复制指令,执行相同的操作——但仅用于保留给复制指令的寄存器和内存。
复制指令以与原始指令相同的顺序执行。eddi-v转换还插入定期检查指令(称为normalchecks(正常检查)),比较原指令的结果与复制指令的结果。
因此,对于每一个复制加载指令,一额外的加载检查指令之后立即插入(在所加载的值被任何其它指令使用前),以检查由原始指令加载的值是否与由相应的复制指令加载的值匹配。类似地,对于存储指令,一存储检查指令在原始存储指令前立即插入,以检查要被存储的值是否与要被由复制指令存储的值相匹配。每个检查指令的形式如下:
cmpra,ra'
其中ra和ra'分别为原始和(对应的)复制寄存器。任何检查指令中的不匹配都表示错误。为了最大限度地减小可能阻止qed的漏洞检测的干扰,插入复制指令和检查指令由参数inst_min和inst_max控制,即在执行任何复制或检查指令前必须执行的来自原始测试的指令的最小和最大数量。
plc——plc针对非内核组件中的漏洞,通过频繁和主动地执行从内存(通过非内核组件)的加载并检查所加载的值。plc首先将原始测试转换成eddi-v转换的qed测试。接下来,plc在整个转换的测试中插入主动加载和检查(plc)操作。plc操作在所有内核和所有线程上运行。
每个plc操作从一组选定的变量加载,并执行检查以检查所加载的值。由于plc测试包括eddi-v,因此每个plc操作都会加载一变量a及其复制版本a',并执行plc检查,如下所示:lock(a);lock(a’);ra=ld(a)ra’=ld(a’)unlock(a’);unlock(a);cmpra,ra’//比较和检测错误。任何不匹配都表示错误。每个plc操作都按照以下方式遍历为plc检查所选择的所有变量:
lock(a);
lock(a’);
ra=ld(a)
ra’=ld(a’)
unlock(a’);
unlock(a);
cmpra,ra’//比较和检测错误
任何不匹配都表示错误。每个plc操作都会遍历为plc选择的所有变量。
符号qed——正如我们将要展示和描述的那样,符号qed定位漏洞并自动生成通常只有几条指令(通常少于10条)的短的漏洞跟踪。在兼容qed的漏洞跟踪的空间内(下面解释),由符号qed生成的跟踪是最小的,意味着不存在更短的漏洞跟踪。本领域的技术人员将容易理解和意识到的是,短的漏洞跟踪——诸如由符号qed产生的那些——使漏洞更容易理解和修复。
符号qed采用在形式化验证中使用的有界模型检查(bmc)。给定系统模型(例如,rtl)和要检查的属性(例如,由qed插入的检查),对系统进行形式化分析以确定该属性在有限数量的步骤(时钟周期)内是否能够违反。如果是,就会产生一反例(违反所述属性的具体跟踪)。众所周知,bmc保证如果一属性可以违反,则返回一最小长度的反例。
此时,我们必须首先回顾与使用bmc进行硅后漏洞定位相关的三个挑战。第一,bmc需要一要解决的属性。由于漏洞事先不是已知的,因此很难确定这种属性(并避免错误判断)。第二,较大的设计尺寸限制了bmc的效率。如果设计太大,典型的bmc工具甚至可能无法加载设计。即使可以加载大型设计,在该设计上运行bmc也必然会非常缓慢,可能不能使用。第三,bmc技术的性能受触发漏洞所需的周期数的影响。更特别地,随着触发漏洞所需的周期数增加,bmc性能降低,特别是对于大型设计。因此,除非存在短的反例,否则bmc将花费太长的时间或者根本就找不到。
我们将稍后再讨论第二个挑战。这里我们将讨论第一个和第三个挑战。本领域的技术人员将理解和意识到,解决这些问题的一个关键要素是创建搜索所有可能的qed测试的bmc问题。众所周知,qed测试非常适合检测各种各样的漏洞。qed测试还设计为能够迅速找到错误。通过利用bmc的最小保证来搜索所有可能的qed测试,通常可以找到触发漏洞的非常短的跟踪。有了这个理解,现在我们描述符号qed的细节。
利用bmc解决兼容qed的漏洞跟踪
qed测试利用以下形式的指令提供非常简洁的属性来检查:
cmpra,ra'
对于plc检查和加载检查,ra和ra'保存从非内核组件加载的值,而对于正常检查和存储检查,ra和ra'保存在处理器内核上执行的计算结果。当两个寄存器不相等时检测到错误。因此,我们使用bmc来查找反例的以下形式的属性:
ra==ra’
其中ra是原始寄存器,ra'是相应的复制寄存器。然而,没有另外的限制,bmc引擎将会找到不对应实际漏洞的微不足道的反例。为了确保bmc生成的跟踪确实对应实际的漏洞,我们要求反例必须与qed兼容。
我们将与qed兼容的跟踪定义为具有以下属性的输入序列:
1.输入必须是有效的指令(有效指令的规范可直接从处理器内核的指令集架构(isa)获得;
2.寄存器和内存空间被分成两半,一半用于“原始”指令,一半用于“复制”指令。对于在分配给原始指令的寄存器和内存空间上运行的每一条指令(不包括控制流改变指令),存在相应的复制指令,执行相同的操作,只是是在分配给复制指令的寄存器和内存空间上运行。
3.原始指令的序列和复制指令的序列必须以相同的顺序执行。
4.原始寄存器r与其对应的寄存器r'之间的比较(例如,由bmc工具检查的属性)只有在原始指令和复制指令同步时才会出现,即,对于已执行的每个原始指令,其相应的复制指令也已被执行。
qed模块
确保bmc只考虑qed兼容的漏洞跟踪需要限制至所述设计的输入。这是通过在bmc期间向每个处理器内核的读取阶段添加新qed模块来完成的。请注意,qed模块仅用于bmc工具内,不会添加到制造的ic中。
有利地,对于给定的isa,qed模块仅需要设计一次,且在验证期间作为“库组件”可用。qed模块的设计非常简单,进行测试只需几分钟。
qed模块自动将原始指令序列转换为qed兼容序列。任何控制流改变指令都会确定“原始指令序列”的结束。qed模块只要求序列实际上由有效指令组成,并且只读取自或写入分配给原始指令的寄存器和内存(可直接指定给bmc工具的条件)。首先执行未修改的原始指令序列(直到但不包括控制流指令)。然后对其执行第二次——但不使用原来的寄存器和内存,指令被修改为使用分配给复制指令的寄存器和内存。由于复制仅通过控制流指令触发,所以qed模块不使用inst_min和inst_max的固定值。这些值由原始指令序列的长度动态地确定。这使得bmc工具可以轻松地暗中(且同时)遍历所有指令序列以及inst_min和inst_max的所有值。在第二次执行后,对一信号进行断言,以指示在无漏洞的情况下原始寄存器和相应的复制寄存器应包含相同的值,即,bmc工具应检查属性ra==ra'。
图3显示了qed模块如何与读取单元集成。qed模块的伪代码如图4所示。从图3可以看出,qed模块的输入是:1)enable,如果为0则禁用qed模块;2)instruction_in,为来自读取单元的指令,由处理器内核执行;3)target_address,包含当处理器执行控制流指令时要执行的下一条指令的地址;以及4)committed,为来自处理器内核的信号,用于表示读取的指令是否已被提交(即,写入寄存器或内存的结果)。
继续参照图3,可以观察到来自qed模块的输出为:1)pc,为要读取的下一条指令的地址;2)pc_override,确定处理器内核是否应使用来自qed模块的pc或来自读取单元的pc;3)instruction_out,是由qed模块计算的修改的指令;4)instruction_override,其确定处理器内核是否应使用来自qed模块的修改的指令或来自读取单元的指令;和5)qed_ready,如果committed输入信号为true则将其设置为qed_ready_i,否则为false。
参照图4可以观察到,qed模块具有内部变量:1)current_mode,其跟踪qed模块是否在执行原始指令(orig_mode)或复制指令(dup_mode);2)qed_rewind_address,其保存原始指令序列中第一条指令的地址;3)pc_override_i和instruction_override_i,其为pc_override和instruction_override的内部版本(唯一的区别是当enable信号被设置为0时,pc_override和instruction_override也都被设置为0,禁用qed模块);和5)qed_ready_i,当原始寄存器和复制寄存器应具有相同的值时(在无漏洞的情况下),其发送信号。最初,qed_ready_i设置为false,并且只有在原始和复制指令都已执行时才设置为true。
qed模块以orig_mode开始。当读取一控制流指令时,qed模块切换到dup_mode,将存储在qed_rewind_address中的地址加载到pc中,并将pc_override_i设置为1(且只要enable为true,pc_override也设置为1)。处理器内核然后重新执行从存储在qed_rewind_address中的地址开始的指令。
在dup_mode模式下,复制指令输出为instruction_out,instruction_override_i设置为1,所以内核执行复制指令而不是来自读取单元的原始指令。在所有复制指令执行完毕后,相应的寄存器应相等,且因此一旦结果写入寄存器(来自处理器内核的committed信号为true),qed_ready就设置为true。此时,处理器将执行控制流指令,qed模块将存储qed_rewind_address中的下一个要执行的指令的地址(即,控制流指令的目标),然后返回到orig_mode。由qed模块执行的转换的示例如图5所示。更特别地,可以在图5中观察到执行的原始指令和实际指令的序列。
初始状态
本领域的技术人员可以理解和意识到,以上概述的方法确保bmc仅考虑qed兼容的跟踪。但是,bmc运行的初始状态必须是与qed一致的状态,以确保不会产生错误的反例。也就是说,分配给原始指令的每个寄存器和内存位置的值必须与复制指令的相应寄存器或内存位置匹配。一种方法是将处理器从其复位状态启动。但是,复位状态可能不是与qed一致的(或者可能难以确认是否一致)。有些设计也会经历复位序列,可能会延长周期数,使bmc问题更困难。例如,对于opensparct2,复位后只有一个处理器内核处于活动状态,系统执行初始化指令序列(约600个时钟周期长),以激活系统中的其它内核。
在系统已经执行复位序列(如果有)之后,从与qed一致的状态开始以提高bmc的运行时间是有利的。根据本公开,获得qed一致状态的一种方式是运行“一些”qed程序(独立于用于漏洞检测的特定测试)并在qed检查已经比较了所有的寄存器和内存值之后立即停止(这确保了每个“原始”寄存器或内存位置具有与相应的“复制”寄存器或内存位置相同的值)。从模拟器读取寄存器值和内存值,且用于在准备运行bmc时设置设计的寄存器值和内存值。人们可以使用超快模拟器(而不是rtl)获得这些值,超快模拟器利用数千个处理器内核轻松模拟大型设计。因此,该步骤不会影响符号qed的可扩展性。
利用bmc查找反例
在插入qed模块并设置初始状态后,我们使用bmc找到属性的反例:
其中n是由isa定义的寄存器的数量。此处,(对于a∈{0……n/2-1}),ra对应于为原始指令分配的寄存器,ra’对应于为复制指令分配的寄存器。我们允许bmc选择的指令包含加载和存储指令,使我们的方法能够激活和检测非内核组件中的漏洞以及处理器内核中的漏洞。
处理大型设计
本领域的技术人员将容易理解,现有技术的商业bmc工具可能无法加载完整的soc(例如,对于opensparct2就是这种情况)。此处,我们讨论处理这种大型设计的三种技术。
处理器内核中的漏洞和处理器内核外的漏洞
如果qed测试无法通过正常检查或存储检查,我们可以立即推断出该漏洞位于处理器内核检查失败的位置处。这是因为通过设计,正常检查和存储检查会在处理器内核产生的任何错误值离开处理器内核并传播到非内核组件或其它处理器内核之前捕获该值。因此,我们只需要在检查失败处的单个处理器内核上执行bmc,以便找到反例。如果在加载检查或plc检查时测试失败,我们不能立即推断出漏洞的位置。对于这些情况,我们考虑了两种方法:变化检测器和部分实例化,以简化bmc要分析的设计。
变化检测器
图6示出了根据本公开一方面的变化检测器的示意图。我们插入变化检测器来记录验证过程中信号逻辑值的变化。这些变化检测器插入在所有组件的边界处,这些组件可能在进一步分析中被移除(例如,在rt等级中的某个级别)。例如,对于后面所示和所述的结果,变化检测器插入在opensparct2设计的主soc模块下的所有信号线的一个等级。它们监视该级别的所有模块之间的信号,包括处理器内核、二级缓存库、内存控制器和i/o控制器。
变化检测器包括初始化为全1的并且只要检测到信号值的变化就重置为全0的k位纹波计数器。由于qed测试的错误检测延迟时间短,k≈10通常是足够的(变化窗口为1,023)。当qed测试检测到错误时,系统停止,且扫描并保存变化检测计数器值。使用变化检测器中记录的值,创建出一简化的设计用于进一步分析。如果在变化窗口期间,变化检测器没有记录元件的输入或输出信号的逻辑值的任何改变,则bmc将组件从分析中排除。
部分实例化
有利地,如果由变化检测器产生的简化设计对于bmc工具来说还是太大的话,或者如果我们需要将漏洞定位到更小的设计,则可以使用部分实例化方法。部分实例化通过两种设计简化技术来实现。第一种技术是采用具有多重实例的所有模块,并不断将其数量减少一半,直到只剩下一个。第二种技术是去除单实例模块,只要移除模块不会将设计划分为两个完全分离的组件即可。
例如,如果设计具有通过交叉开关连接到缓存的处理器内核,则交叉开关就不能移除,因为这会将处理器内核与缓存完全断开。由于我们找到的漏洞跟踪是在处理器内核上执行的指令的形式,因此每个所分析的设计必须包含至少一个处理器内核。图7显示了这种方法的步骤。一旦创建了一整套简化的(部分实例化的)设计,使用bmc工具对它们全部进行并行分析。
举个例子,我们现在考虑具有8个内核、1个交叉开关、8个缓存、4个内存控制器和各种i/o控制器的opensparct2。假设i/o控制器被变化检测器去除(有多种类型的i/o控制器,但每种类型只有1个实例),将设计减少到8个核心、1个交叉开关、8个缓存和4个内存控制器。这在bmc工具中不适用,并且不保存为部分实例。接下来,具有多个实例的组件减半,将设计减少到4个核心、1个交叉开关、4个缓存和2个内存控制器。
不幸的是,这在bmc工具中仍然不适用,所以不能保存为部分实例。交叉开关不能移除,因为这会将内核从其它组件断开。在下一个缩减步骤中,设计减少到2个核心、1个交叉开关、2个缓存和1个内存控制器。该设计确实合适,所以我们保存它。接下来,内存控制器可以去除(因为有单个实例)。或者,内核和缓存的数量可以除以2。这两个都保存下来。进一步的缩减产生设计越来越小的子集,每个子集都保存下来。当不可能再缩减时,所有保存的设计都并行运行。
结果
首先参照图8——其示出了opensparct2的示意图——现在我们使用opensparct2soc[opensparc]论证符号qed的有效性,opensparct2是ultrasparct2的开源版本,是具有8个处理器内核(64个硬件线程)、私有一级缓存、8个共享二级缓存库、4个内存控制器、基于交叉开关的互连以及各种i/o控制器的5亿晶体管soc。我们在opensparct2soc上模拟了逻辑漏洞场景。这些模拟的场景表示从各种商业多核soc中提取的各种各样的“困难”的漏洞场景。它们被认为是困难的,是因为花了很长时间(几天至几个星期)来定位。漏洞场景包括处理器内核中的漏洞、非内核组件中的漏洞以及与电源管理相关的漏洞。
我们修改了opensparct2soc的rtl来包含这些漏洞场景。对于80个漏洞场景,我们将漏洞场景参数x设置为2个时钟周期,将漏洞场景参数y设置为2个时钟周期(特别要注意,x和y的值越小,漏洞就越难以检测)。对于12个电源管理漏洞场景,激活标准是设置为从原始测试中选择的5个指令的序列,在指定的处理器内核上执行。这是模拟电源管理控制器。当插入漏洞时,如果漏洞插入到一组件中,所述漏洞就在组件的所有实例中。
对于bmc,我们使用明导国际(mentorgraphics)的奎斯塔形式化工具(questaformaltool)(版本10.2c_3),采用128gbram的amd皓龙处理器6438。我们使用eddi-v和plcqed转换将fft测试的8线程版本(来自splash-2)和矩阵乘法测试(mmult)的内部并行化的8线程版本转换为qed测试以检测漏洞。inst_min和inst_maxqed转换参数设置为100,这通常实现在几百个时钟周期内检测到漏洞。请注意,尝试额外的测试(超出fft和mmult)被认为是不必要的,因为这两个测试(在qed转换后)都能够检测到所有的92个漏洞(且符号qed中的bmc步骤独立于检测漏洞的qed测试)。我们将前面描述的qed模块添加到opensparct2处理器内核中的读取单元的rtl中。对产生的带有qed模块的读取单元在奎斯塔形式化工具中进行测试,以确保它正确地将原始指令序列转换为qed兼容的漏洞跟踪。对50个不同长度(1到10个指令长)的原始指令序列的测试过程花费了大约1分钟的运行时间。此外,我们模拟了由符号qed(依赖于qed模块)产生的所有的漏洞跟踪,以确保漏洞跟踪确实激活并检测相应的漏洞。
结果总结在表1中。原始(no-qed)列显示使用最终结果检查运行原始验证测试(fft或mmult)的结果,以根据预先计算的已知正确结果来检查测试结果。qed列显示qed转换后运行相同测试的结果。请注意,与符号qed不同,原始(非qed)和qed测试(没有第三部分e中讨论的分析技术)只能报告存在漏洞;它们不能定位漏洞(即,确定漏洞是否在处理器内核中,在任何非内核组件中,或者是由组件之间的相互作用引起的),也不能在漏洞被激活时非常精确地确定。该表分类为处理器内核漏洞、非内核漏洞(此处我们包括了位于非内核组件中的漏洞以及处理器内核与非内核组件之间的接口中的漏洞)以及电源管理漏洞。每项包含两组数字,最上面的一组包含从fft测试得到的结果,最下面的一组包含从mmult获得的结果。在表1中,“漏洞跟踪长度(指令)”示出了漏洞跟踪中指令的[最小,平均,最大]数量。“错误跟踪长度(周期)”表示执行漏洞跟踪所需的[最小,平均,最大]时钟周期数。这两个数字是不同的,因为对于所有的指令来说,每条指令的周期(cpi)不是1(例如,加载或存储指令可能需要多个时钟周期来执行)。
对于符号qed,漏洞跟踪的报告长度与bmc工具发现的跟踪中的指令数量相对应(不包括由qed模块创建的复制指令)。
对于只能通过在多处理器内核上执行指令才能找到的漏洞,每个内核的指令数量可能不同。例如,一个内核可能具有为3个指令长的漏洞跟踪,而另一个内核则具有为1个指令长的漏洞跟踪。我们报告内核长度最长的漏洞跟踪(本示例中为3),因为所有的内核都必须完成激活和检测漏洞(且内核并行执行指令)。
观察报告1:符号qed自动产生的漏洞跟踪比依靠最终结果检查的传统硅后验证测试短6个数量级,比qed测试短5个数量级。符号qed产生的漏洞跟踪非常短(我们利用模拟证实了它们的正确性)。此外,符号qed不需要跟踪缓冲区来产生正确的漏洞跟踪。这些都是非常困难的漏洞,利用传统方法花了很多天或几周才能定位(通过由传统技术产生的长漏洞跟踪也是显而易见的)。短的漏洞跟踪使调试更容易。图11显示了每个漏洞场景下跟踪长度的更详细的可视化。如表1中所用,“覆盖率”是检测到的92个漏洞的百分比。符号qed和qed都检测到了所有的92个漏洞,但原始测试只检测到一半以上的漏洞。
表1
如其中所使用的,“bmc运行时间”表示bmc工具查找漏洞跟踪所用的[最小,平均,最大]分钟数。“定位的漏洞”表示定位到的漏洞的百分比。注意,原始(非qed)测试和qed测试都只能检测到漏洞,而不能定位漏洞。我们没有包括不使用我们的符号qed技术运行bmc的任何结果,原因有两个:(i)整个设计不加载到bmc工具中;以及(ii)即使这样做了,我们也需要检查运行bmc的属性,并且没有明确的方法来弥补这些属性(除了手动插入,但这将是主观的且非常耗时的)。
观察报告2:符号qed在不到7小时内正确自动地生成所有漏洞的简短反例,不依赖于跟踪缓冲区。符号qed对于opensparct2等大型设计是有效的,而使用传统硅后技术则是具有挑战性的。对于符号qed,所有的处理器内核漏洞都是通过正常检查或存储检查来检测的。因此,我们能够确定该漏洞一定位于处理器内核内。这仅仅是基于qed检查确定的,而不是因为我们知道模拟的是哪些漏洞。针对这些漏洞报告的bmc运行时间对应于只有处理器内核被加载的bmc运行。对于非内核和电源管理漏洞,采用部分实例化技术(第三部分e)。变化检测器确定诸如i/o控制器的组件对于激活漏洞来说是不需要的。涉及其它组件的部分实例化并行运行。对于opensparct2,每个漏洞有5个并行运行;每个运行对应于以下部分实例中的一个,按大小降序排列。91)2个处理器核心、2个二级缓存组、1个内存控制器;2)1个处理器内核、1个二级缓存库、1个内存控制器;3)2个处理器内核、2个二级缓存库;4)1个处理器内核、1个二级缓存库;和5)1个处理器内核。回想一下,如果组件中存在漏洞,那么它就在组件的所有实例中。对于这些漏洞,报告的bmc运行时间对应于产生反例的最小部分实例的运行时间。请注意,该部分实例化还提供了可能包含该漏洞的组件的小候选列表。例如,对于给定的漏洞,如果两个部分实例2和5都生成一反例,则仅报告来自部分实例5的结果。这是因为虽然2和5二者都包含处理器内核和缓存,但5没有内存控制器或缓存库。这表明内存控制器和缓存库不需要激活和检测该漏洞。
观察报告3:符号qed正确定位漏洞并提供与设计中漏洞的可能位置相对应的组件的候选列表。图9为显示由符号qed定位的漏洞的故障的图表。符号qed定位了所有92个漏洞场景。对于26.1%的漏洞,符号qed将漏洞精确地定位到1个处理器内核;对于56.5%的漏洞,符号qed将漏洞定位到1个处理器内核、1个二级缓存库和连接二者的交叉开关;对于17.4%的漏洞,符号qed将漏洞定位到2个处理器内核、2个二级缓存库以及连接这些组件的交叉开关。表1中报告的符号qed的bmc运行时间使用前面讨论的qed一致的初始状态约束。
每个漏洞的详细运行时间如图10所示。在图10中,我们报告了每个漏洞的三个运行时间:从重置序列后紧接的状态开始的运行时间(在这种情况下为qed一致),通过运行fftqed测试以及利用生成的寄存器和内存值为bmc播种而获得的从qed一致初始状态开始的运行时间,以及在运行mmult之后类似地为bmc播种。结果表明,与从复位后的状态开始相比,使用通过运行qed测试获得的qed一致的初始状态在运行时间时实现了高达5倍的改善。还要注意,使用fft测试的结果与使用mmult测试的结果之间没有观察到显著的差异。
为了评估用于减小设计尺寸的变化检测器,我们在opensparct2中使用了相同的92个漏洞场景,并运行了之前讨论的qed转换(eddi-v和plc)fft和mmult测试。通过1023个周期的变化窗口,我们发现对于这些测试,只有处理器内核、交叉开关、二级缓存和内存控制器是简化设计的一部分。
因此其它组件(如i/o控制器)可以从设计中去除。对于所述92个漏洞,如图12所示,二级缓存(l2c)和内存控制器(mcu)的数量也变化。对于其中3个漏洞(使用fft基准),设计尺寸减小到足以从部分实例化的设计中消除一模块(在每种情况下为内存控制器)。我们使用synopsysdesigncompiler(新思科技设计编译器)和synopsysedk32nm库进行综合,以计算opensparct2soc上的变化检测器的芯片级面积占用。我们在1067个信号上插入变化检测器,总共24214位,因此整个设计需要24214个变化检测器。这导致1.86%的芯片级面积占用。然而,考虑到变化检测器没有减少内存控制器、缓存或缓存标记的数量足以消除大部分漏洞的部分实例化设计(参见图12),在该示例中,我们可以省略变化检测器,只观察这些组件之间的信号。被监测的信号数量然后降至899,只需要监测12734位。面积占用减少至0.98%。因此,变化检测器的部分使用,通常在外围组件上看到间歇性活动,似乎是最具成本效益的策略;监视具有高利用率的缓存和内存控制器等组件可能不会增加显著的价值。
本领域的技术人员将容易理解,该占用显著小于用于硅后调试的可重新配置逻辑的4%的占用。此外,这种方法完全避免了使用跟踪缓冲区(以及相关的面积占用)。虽然我们说明了在opensparct2soc上符号qed的有效性,但符号qed并不依赖于关于opensparct2的具体实施的任何信息。结果,符号qed适用于各种soc设计。
本领域的技术人员现在将理解,我们的符号qed技术依赖于用于创建硅后验证测试的qed技术,但是存在重要的差异。与符号qed不同,qed单独不能直接定位漏洞。如前所述,与符号qed相比,通过qed获得的漏洞跟踪可能非常长(当不使用跟踪缓冲器时长达5个数量级)。对于处理器内核中的漏洞,利用自我一致性检查等技术可以进一步提高符号qed的性能。然而,现有技术的自我一致性检查只能解决处理器内核漏洞,并且我们在商业soc中的漏洞的经验表明单内核组件也是soc中困难漏洞的重要来源。
硅后验证和调试越来越高的重要性促进了漏洞定位和产生错误跟踪的很多工作。用于硅后漏洞定位的ifra以及相关的blog技术仅针对处理器(以及公布的结果针对电气漏洞)。ifra和blog对于非核心组件内的漏洞的有效性尚不清楚。这些技术也需要人工付出——与符号qed形成鲜明对比。
许多当代硅后漏洞定位方法依赖于跟踪缓冲区和断言。这些技术的不足已经讨论过了。(一些针对跟踪缓冲区插入的启发式算法,例如恢复率及其派生因子只能用于逻辑漏洞,因为它们使用模拟来计算未被跟踪的信号的逻辑值)。相比之下,符号qed不需要任何跟踪缓冲区或设计特定的断言,并提供一非常简洁而通用的属性来快速检测和定位逻辑漏洞。
通过使用形式化方法将多个较短的跟踪(或系统状态)整合到较长的跟踪中,一旦检测到错误或系统崩溃,系统(如backspace及其衍生系统)提供具体的漏洞跟踪。一些backspace衍生系统需要故障再现,正如我们所讨论的那样,由于heisenbug效应,这是非常具有挑战性的。其它系统(如nutab-backspace)解决了一些故障再现的难题,但需要设计专用的“重写规则”来确定两个相似的状态是否相同。这些重写规则必须由设计者手工制作,并且需要设计者的直觉,这对于大型设计来说可能是困难的。此外,发现的漏洞跟踪可能非常长,而且与符号qed不同,这些技术不能减小漏洞跟踪的长度。此外,仅依靠形式化方法进行漏洞定位的技术不能扩展到如opensparct2等的大型设计。
一些形式化技术需要针对特定的电气漏洞模型的特定的漏洞模型)可能不适用于逻辑漏洞,因为要为所有的逻辑漏洞创建漏洞模型是非常困难的。依靠详细的rtl模拟来获得设计的内部状态的方法对于大型设计而言是不可扩展的,因为大型设计的整个系统rtl级仿真非常慢,每秒少于10个时钟周期。虽然其它针对硅后漏洞诊断的技术已在其它地方提出,但是这种技术可能需要对设计的内部状态进行多次详细的rtl模拟,以引导插入用于调试的硬件结构。最后,butramin为用于缩短漏洞追踪的长度的硅前技术。为了用在大型设计的硅后验证和调试中,需要大量仿真来捕获系统中所有触发器的逻辑值,即使并非不可能,也将是困难的。尽管如此,在符号qed定位漏洞并生成相应的短错误跟踪后,可能会有机会使用这种技术。
作为另一个说明性的例子,我们示出了图13(a)和13(b)中的eddi-v转换示例,其中图13(a)示出了原始测试,图13(b)示出了说明根据本发明的eddi-v示例,其中inst_min=inst_max=3。在图14(a)和14(b)中示例性地示出了plc示例,其中图14(a)示出了转换的代码,而图14(b)示出了根据本公开的一方面inst_min=inst_max=4时plc转换示例的plc操作。
最后,图10示出了适合于实现根据本公开的一方面的方法和系统的示例性的计算机系统1000。可以立即理解,这样的计算机系统可以被集成到另一个系统中,例如路由器,并且可以通过分立元件或一个或多个集成元件来实施。计算机系统可以包括例如运行多个操作系统中的任何一个的计算机。本公开的上述方法可以作为存储的程序控制指令在计算机系统1000上实现。
计算机系统1000包括处理器1010、内存1020、存储设备1030和输入/输出结构1040。一个或多个输入/输出设备可以包括显示器1045。一个或多个总线1050通常互连组件1010、1020、1030和1040。处理器1010可以是单核或多核。另外,该系统可以包括进一步包括片上系统的加速器等。
处理器1010执行指令,其中本公开的实施例可以包括在一个或多个附图中描述的步骤。这样的指令可以存储在内存1020或存储设备1030中。数据和/或信息可以使用一个或多个输入/输出设备来接收和输出。
内存1020可以存储数据并且可以是计算机可读介质,诸如易失性或非易失性内存。存储设备1030可以为系统1000提供存储,包括例如之前描述的方法。在各个方面中,存储设备1030可以是使用磁、光学或其它记录技术的闪存设备、磁盘驱动器、光盘设备或磁带设备。
输入/输出结构1040可以提供系统1000的输入/输出操作。
结论
在这一点上,本领域的技术人员将很容易理解我们的符号qed技术,这是一种结构化和自动化的方法,克服了硅后验证和调试的挑战。有利的是,符号qed自动检测和定位硅后验证中的逻辑漏洞,并提供可能包含漏洞的候选组件列表。此外,符号qed产生的漏洞跟踪比传统的硅后验证测试(其依赖于最终结果检查)短6个数量级,并且比qed测试短5个数量级。符号qed是完全自动化的,不需要人为干预,也不需要跟踪缓冲区。符号qed既有效又实用,正如在opensparct2上所展示的那样,它正确地定位了从各种商业多核soc的硅后验证中出现的错误中抽象出来的92个困难的逻辑漏洞。值得注意的是,这些已知的逻辑漏洞最初花费了很多天或几周的时间来定位。相比之下,其它形式化技术可能需要几天,或者对于opensparct2等大型设计而言完全失败。
在这一点上,本领域的技术人员将容易理解,虽然已经关于特定的实施方式和/或实施例描述了根据本公开的方法、技术和结构,但是本领域的技术人员将认识到本公开并不限于此。因此,本公开的范围应仅由所附权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!