用于并行化SMP数据库中的基于散列的运算符的系统和方法与流程
相关申请案的交叉参考
本发明要求2015年6月24日递交的发明名称为“用于并行化smp数据库中的基于散列的运算符的系统和方法(systemsandmethodsforparallelizinghash-basedoperatorsinsmpdatabases)”的第14/749098号美国非临时专利申请案的在先申请优先权,该在先申请的内容以引入的方式并入本文本中,如同全文复制一样。
本发明大体上涉及系统和方法数据库,并且在具体实施例中,涉及用于并行化对称多处理(symmetricmultiprocessing,smp)数据库中的基于散列的运算符的系统和方法。
背景技术:
随着因特网应用的兴起,越来越多数据产生并存储到数据库中。数据库查询可能非常复杂。并行处理数据库管理系统设计用于管理和处理大量数据。对称多处理(symmetricmultiprocessing,smp)计算机系统含有多个中央处理单元(centralprocessingunit,cpu)核心,所述cpu核心共享大量存储器并且对于运行并行处理数据库系统是理想的。
对于数据库操作,基于散列的运算符包含散列连接和散列聚合。散列连接是对于连接属性的每个不同值,找到具有所述值的每个数据库表中的元组集合的方法。散列连接由两个阶段组成:构建阶段和探测阶段。当连接两个表时,构建阶段首先在较小表(内部表)的顶部上创建散列表。散列表项包含连接属性和数据行。探测阶段与构建阶段使用相同散列函数。探测阶段扫描较大表(外部表)的行,散列连接属性并且通过参考散列表找到内部表中的匹配行。散列聚合是用于实施例如分组的数据库集中操作的方式。类似于散列连接运算符,散列聚合还通过作为散列键的目标聚合属性在关系数据顶部创建散列表。根据散列表,元组可以分成组或可以提取唯一的元组。
技术实现要素:
根据本发明的实施例,用于执行基于散列的数据库操作的设备中的方法包含:在设备处接收数据库查询;创建多个执行工作线程以处理查询;以及由执行工作线程根据数据库表构建散列表,所述数据库表包括多个分区和多个扫描单元中的一个,散列表由执行工作线程共享,每个执行工作线程扫描对应分区并且在分割数据库表的情况下将条目添加到散列表,每个执行工作线程扫描未处理的扫描单元并且在数据库表包括扫描单元的情况下根据扫描单元将条目添加到散列表,并且工作线程以并行方式执行扫描和添加。
根据另一实施例,用于执行基于散列的数据库操作的设备包含处理器和非暂时性计算机可读存储媒体,所述非暂时性计算机可读存储媒体存储由处理器执行的编程,所述编程包含用于执行以下操作的指令:接收数据库查询;创建多个执行工作线程以处理查询;以及由执行工作线程根据数据库表构建散列表,所述数据库表包括多个分区和多个扫描单元中的一个,散列表由执行工作线程共享,每个执行工作线程扫描对应分区并且在分割数据库表的情况下将条目添加到散列表,每个执行工作线程扫描未处理的扫描单元并且在数据库表包括扫描单元的情况下根据扫描单元将条目添加到散列表,并且工作线程以并行方式执行扫描和添加。
根据另一实施例,设备用于执行基于散列的数据库操作。设备包括:接收元件,所述接收元件接收对称多处理(symmetricmultiprocessing,smp)数据库查询;创建元件,所述创建元件创建多个执行工作线程以处理查询并且执行工作线程根据数据库表构建散列表,所述数据库表包括多个分区和多个扫描单元中的一个,散列表由执行工作线程共享,每个执行工作线程扫描对应分区并且在分割数据库表的情况下将条目添加到散列表,每个执行工作线程扫描未处理的扫描单元并且在数据库表包括扫描单元的情况下根据扫描单元将条目添加到散列表,并且工作线程以并行方式执行扫描和添加。
附图说明
为了更完整地理解本发明以及其优点,现在参考下文结合附图进行的描述,其中:
图1示出根据第一选项的用于数据库操作的系统的实施例的框图;
图2示出根据第二选项的用于数据库操作的系统的实施例的框图;
图3示出用于在工作线程之间重排元组以避免工作线程之间竞争的系统的实施例的框图;
图4是用于散列连接的并行探测的系统的实施例的框图;
图5是用于并行散列聚合的系统的实施例的框图;
图6是用于具有溢出的并行散列表创建的系统的实施例的框图;
图7示出用于并行散列连接的方法的实施例的流程图;
图8示出用于并行聚合的方法的实施例的流程图;以及
图9说明可以安装在主机设备中的用于执行本文所描述的方法的实施例处理系统的框图。
具体实施方式
下文详细论述当前优选实施例的制作和使用。然而,应了解,本发明提供可以在各种具体上下文中体现的多个适用的发明性概念。所论述的具体实施例仅仅说明用于制作和使用本发明的具体方式,而不限制本发明的范围。
本文揭示用于以并行方式执行基于散列的数据库操作的系统和方法。当smp数据库接收查询时,实施例系统和方法创建多个执行工作线程以处理查询。工作线程包含用于数据处理和交换的多个线程。每个执行工作线程分配有一个数据分区。执行工作线程处理其自身的数据分区。所有基于散列的操作首先构建散列表,并且随后执行操作,例如连接和聚合。在所揭示实施例中,创建散列表并在所有执行工作线程之间共享所述散列表。每个工作线程扫描其自身的分区并且将条目添加到共享散列表。对于散列连接,在创建共享散列表之后,每个工作线程使用共享散列表探测其外部连接表的分区。在实施例中,还通过共享散列表完成散列聚合。
本文揭示处理执行工作线程之间的竞争的至少三个方法:同步、无锁定算法和重排。每个工作线程启动生产者线程以在工作线程之间交换数据元组以用于重排。对于散列连接,执行工作线程相对于共享散列表并行扫描以及探测外部表。对于散列聚合,执行工作线程使用共享散列表并行聚合结果。收集工作线程收集来自所有执行工作线程的结果并且将结果发送到客户端或上查询运算符。
如果参与数据库操作的表超过系统的存储器大小,可能发生溢出。在实施例中,查询执行工作线程扫描表并且并行在磁盘上创建散列分区。在溢出情况下,对于散列连接,查询执行工作线程并行创建内部表和外部表的分区对。工作线程使用与非溢出情况相同的方法来并行执行分区明智散列连接,或每个工作线程分配有一定量的分区对来处理。此后,工作线程处理磁盘上的分区并且执行分区明智连接或散列聚合。对于散列聚合,查询执行工作线程构建散列表的分区。工作线程使用非溢出方法逐个处理分区,或工作线程可以分配有多个分区以并行聚合结果。
用于并行化smp数据库中的基于散列的运算符的其它解决方案包含设计用于传统关系数据库管理系统的经典混合散列连接算法和混合高速缓存算法。然而,例如cpu和存储器的系统资源可能不完全用于这些解决方案中。
散列表构建
smp系统具有多个cpu核心。当接收查询时,smp系统启动若干查询执行工作线程以并行处理查询。对于基于散列的操作,第一步骤是构建散列表。在所揭示方法中,在所有查询执行工作线程之间共享散列表。可以通过两种方法组织关系数据:(1)根据smp系统的并行度(degreeofparallelism,dop)分割表。(2)不分割表数据或分区数目不同于dop。在第一种情况下,例如,如果dop是四,启动四个工作线程来执行查询。每个查询执行工作线程分配有一个分区。每个工作线程扫描其自身的数据分区。在第二种情况下,利用并行扫描。扫描单元是多个数据页。每个工作线程处理扫描单元。在完成之后,工作线程扫描另一扫描单元,直到扫描整个表。
图1示出根据第一选项的用于数据库操作的系统100的实施例的框图。系统100说明并行散列表创建。系统100包含共享散列表102、多个工作线程104和分割表106,所述分割表106包含多个分区108。分区108的数目等于dop。出于说明的目的,分区108和工作线程104的数目是三,但本领域普通技术人员将认识到,分区108和工作线程104的数目可以是任何数目并且不限于三。每个工作线程104分配有相应分区108。工作线程104并行扫描分区108并且将条目添加到共享散列表102。
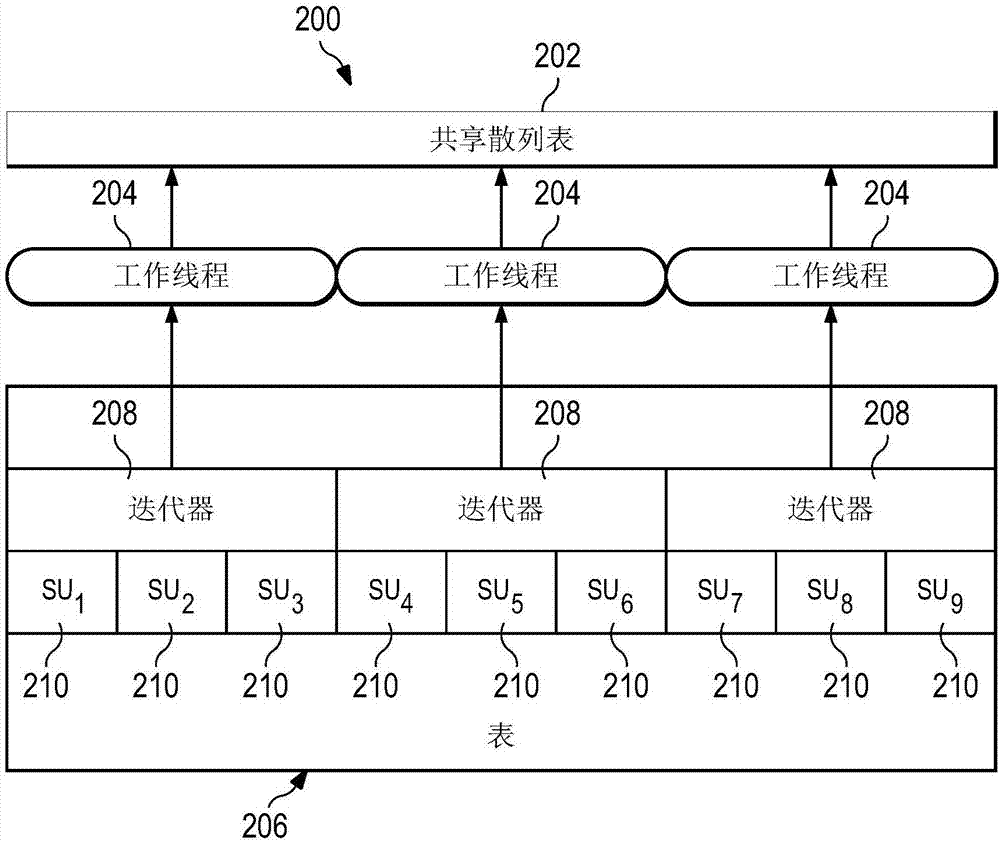
图2示出根据第二选项的用于数据库操作的系统200的实施例的框图。系统200说明用于并行散列表创建的替代实施例。系统200包含共享散列表202、多个工作线程204和表206。表206包含多个迭代器208和多个扫描单元(scanunit,su)210(标记为su1、su2、……、su9)。不分割表206。出于说明的目的,迭代器208和工作线程204的数目是三,但本领域普通技术人员将认识到,迭代器208和工作线程204的数目可以是任何数目并且不限于三。此外,本领域普通技术人员将认识到,su的数目不限于九,但是可以是任何数目。su210的数目必须能被工作线程204的数目整除。如果su210的数目不能被工作线程204的数目整除,一些工作线程204与其它工作线程204相比可以获得更多su210。然而,在实施例中,su210尽可能均匀地分布在工作线程204之间以基本上均匀地将负载分配在工作线程204之间。当创建共享散列表202时,工作线程204对su迭代并且以并行方式将条目添加到共享散列表202。
每个工作线程204分配有一些su210。例如,su1、su2和su3被分配到第一工作线程204;su4、su5、su6被分配到第二工作线程204。这仅出于说明的目的。在其它实施例中,su210到工作线程204的分配可以不同。例如,在另一实施例中,su1、su4和su5被分配到第一工作线程204并且su2、su3和su6被分配到第二工作线程204也是可能的。然而,每个su210仅由一个工作线程204处理。在实施例中,在处理一个su210以确保处理所有su210之后,迭代器208迭代到下一su210。
当构建共享散列表(例如,图1中的共享散列表102或图3中的共享散列表202)时,不同工作线程可以尝试同时将条目添加到相同散列桶。需要协调来解决竞争。揭示用于处理此情况的三个方法。第一选项是可以用于使写入与工作线程之间的相同桶同步的类似于互斥量的同步机构。第二选项利用无锁定算法来创建散列表,例如,在如同全文复制一样以引用方式并入本文本中的第6,988,180号美国专利中所描述,使得不需要同步。在第三选项中,元组可以在工作线程之中重排,使得不同工作线程写入到不同桶,由此避免竞争。
图3示出用于在工作线程之间重排元组以避免工作线程之间竞争的系统300的实施例的框图。系统300包含共享散列表302、多个执行工作线程306和表308。表308分成多个分区310(标记为分区1、分区2和分区3)。共享散列表302根据smp数据库的dop分成分区301。如本领域普通技术人员将认识到,smp数据库是在存储和管理表308的smp计算系统上运行的并行处理数据库管理系统的类型。应注意,dop不必与分区310的数目相同。如果dop不同于分区的数目,情况可以如上文参考图2所描述。在这种情况下,每个工作线程处理一些su并且重排元组。在图3中,dop是三,但是在其它实施例中可以是另一数目。出于说明的目的,分区310和工作线程306的数目是三,但本领域普通技术人员将认识到,分区310和工作线程306的数目可以是任何数目并且不限于三。每个工作线程306分配有相应分区310。
散列连接键并且系统300通过dop修改结果以决定数据应发送到哪个工作线程306。在图3中,dop是三。共享散列表302分成三个部分。每个执行工作线程306扫描其分区310并且在将条目添加到散列表302之前重排数据。每个执行工作线程306启动用于数据交换的生产者线程。生产者线程扫描与启动相应生产者线程的执行工作线程306对应的分区310中的分区数据。生产者线程随后散列分区数据并且将分区数据发送到对应执行工作线程306。执行工作线程306用散列函数304散列数据并且将数据条目添加到共享散列表302的分区301。
散列连接的并行探测
图4是用于散列连接的并行探测的系统400的实施例的框图。系统400包含收集工作线程402、多个工作线程404、共享散列表406和外部表408。收集工作线程402从工作线程404收集结果并且将结果发送到客户端。外部表408分成多个分区410。对于散列连接,在于内部表上构建共享散列表406之后,查询执行工作线程404并行探测用于外部表408的每个行的共享散列表406。取决于外部表408的分区方案,如果分区的数目与dop相同或如果使用并行扫描,任一分区410被分配到工作线程404。出于说明的目的,分区410和工作线程404的数目是三,但本领域普通技术人员将认识到,分区410和工作线程404的数目可以是任何数目并且不限于三。
在实施例中,分区的数目与dop相同。每个工作线程404扫描外部表408中其自身的分区410并且相对于共享散列表406探测条目。
并行散列聚合
图5是用于并行散列聚合的系统500的实施例的框图。系统500包含收集工作线程502、多个聚合运算符504、多个工作线程506和共享散列表508。如本领域普通技术人员将认识到,聚合操作504是数据库操作。收集工作线程502收集来自聚合运算符504的结果。共享散列表508分成标记为s1、s2、……、s8的分区510。对于例如countdisticnt的聚合操作,创建共享散列表508。在已创建共享散列表508之后,工作线程506扫描共享散列表508以聚合元组。在实施例中,共享散列表508分成较小分区510并且在共享散列表508上执行并行扫描。每个工作线程506分配有共享散列表508的分区510。在工作线程506结束处理一个分区510之后,将共享散列表508的新分区510分配到工作线程506,直到处理全部共享散列表508。出于说明的目的,聚合运算符504和工作线程506的数目是三,但本领域普通技术人员将认识到,聚合运算符504和工作线程506的数目可以是任何数目并且不限于三。此外,出于说明的目的,分区510的数目示为八个,但本领域普通技术人员将认识到,分区510的数目可以是任何数目。
用于并行散列连接和散列聚合的溢出处理
如果表太大并且当执行散列连接或散列聚合时,存储器不足以保存整个表,在实施例中数据应溢出到磁盘。在共享散列表的构建期间确定溢出。
图6是用于具有溢出的并行散列表创建的系统600的实施例的框图。系统600包含多个散列表分区602、604、606、多个工作线程608(标记为工作线程1、工作线程2和工作线程3)、表610。表612分成多个分区612(标记为分区1、分区2和分区3)。散列表分区606驻留在存储器中,而当存储器不足以保存散列表时,散列表分区602、604驻留在磁盘上用于溢出。出于说明的目的,分区612和工作线程608的数目是三,但本领域普通技术人员将认识到,分区612和工作线程608的数目可以是任何数目并且不限于三。此外,散列表分区602、604、606示出一个在存储器中且两个在磁盘上,但本领域普通技术人员将认识到,存储于磁盘上的散列表分区602、604的数目可以是任何数目并且不限于二。
用于溢出的共享散列表创建
在实施例中,在构建共享散列表期间,散列表610的桶分成组。每个组与散列表610的可扩展分区612类似。
当存储器不足以保存散列表610时,一个分区612(例如,分区1)保存在存储器中(例如,散列表分区606保存在存储器中),并且散列表的其它分区612(例如,分区2和分区3)溢出到磁盘上(例如,散列表分区602、604保存在磁盘上)。在实施例中,选择将尺寸最接近用于散列表的存储器的分区保存在存储器中。下文是用于选择保存在存储器中的分区的算法。
用于选择保存在存储器中的分区的方法
对于散列表的所有分区
计算分区中的数据在散列表的数据中所占的百分比
使用百分比来估计每个分区的分区大小
选择大小接近用于散列表的存储器大小的分区
查询执行工作线程608继续将条目添加到共享散列表:对于保存在存储器中的散列表分区,将条目添加到存储器606中的散列表分区;对于其余散列表分区612,将条目添加到磁盘602、604上的分区文件。
具有溢出的并行散列连接
对于在构建共享散列表之后的散列连接,读取外部表并且与共享散列表相同的散列函数和桶数目用于创建外部表的分区:一个分区保存在存储器中,从而与共享散列表中的一个匹配;以及所有其它分区创建在磁盘上。与共享散列表的分区的创建类似,所有查询执行工作线程并行创建外部表的分区。由于多个工作线程可以同时写入到相同分区,因此同步或重排可以用于解决与上文参考图1描述的竞争类似的竞争。在此阶段之后,创建多对分区。对于每一对分区,一个来自外部表且一个来自内部表。每一对分区的桶距离相同。
分区明智连接用于散列连接。首先,连接保存在存储器中的分区对。接下来,加载和连接在磁盘上创建的其它对分区。为了并行化成对散列连接,存在至少两个替代方案。
选项1:使用上文参考图4描述的方法。当连接一对分区时,将散列表的分区加载到存储器中并且所述分区在所有工作线程之间共享。每个工作线程例如通过并行扫描分配有外部表的一大块分区,并且并行执行探测。
选项2:在执行工作线程之间拆分分区对。每个工作线程连接多对分区。连接结果从所有工作线程收集到并且发送到客户端或上层运算符。例如,如果存在从内部连接表和外部连接表创建的1024对分区并且dop是16,每个工作线程连接64对分区。
图7示出用于并行散列连接的方法700的实施例的流程图。方法700开始于块702处,其中在存储器中构建内部表的共享散列表。在块704处,确定一些表是否需要溢出到磁盘。如果是,方法700前进到块708并且使用共享散列表执行并行探测。如果在块704处,不需要溢出到磁盘,方法700前进到块706,其中创建散列表的分区并且一个分区保存在存储器中且其余部分写入到磁盘。在块710处,使用与散列表相同的桶数目创建外部表的分区,其中一个分区保存在存储器中并且其余部分写入到磁盘。在块712处,并行执行成对散列连接。在块714处,确定使用上述选项1还是选项2。如果选择选项1,方法700前进到块716,其中对于每一对分区,方法700前进到块706以使用共享散列表执行并行探测。如果选择选项2,方法700前进到块718,其中将多个分区对分配到每个工作线程以执行成对散列连接。
具有溢出的并行散列聚合
在溢出情况下,在创建散列表的分区之后,以并行方式作用的查询执行工作线程通过至少两种方式中的一个聚合结果。
选项1:使用上文参考图5中的系统500描述的方法。在处理所有分区之前,以并行方式作用的工作线程同时扫描和聚合一个散列分区。
选项2:将散列表的分区分配到工作线程。每个工作线程处理多个分区。
图8示出用于并行聚合的方法800的实施例的流程图。方法800开始于块802处,其中在存储器中构建表的共享散列表。在块804处,确定是否需要溢出到磁盘。如果不是,方法800前进到块806,其中使用共享散列表执行并行聚合。如果在块804处,不需要溢出到磁盘,方法800前进到块808,其中创建散列表的分区,其中一个分区保存在存储器中且其余部分写入到磁盘。在块810处,执行并行聚合。在块812处,确定是否选项1还是选项2。如果选择选项1,方法800前进到块814,其中对于每个分区,在块806中执行使用共享散列表的并行聚合。如果在块812处选择选项2,方法800前进到块816,其中将多个分区分配到每个工作线程以执行聚合。
图9说明可以安装在主机设备中的用于执行本文所描述的方法的实施例处理系统900的框图。如图所示,处理系统900包含可以(或可以不)如图9中所示布置的处理器904、存储器906和接口910-914。处理器904可以是用于执行计算和/或其它与处理相关的任务的任何组件或组件集合,且存储器906可以是用于存储编程和/或供处理器904执行的指令的任何组件或组件集合。在实施例中,存储器906包含非暂时性计算机可读媒体。接口910、912、914可以是允许处理系统900与其它设备/组件和/或用户通信的任何组件或组件集合。例如,接口910、912、914中的一个或多个可以用于将数据、控制或管理信息从处理器904传送到安装在主机设备和/或远端设备上的应用程序。作为另一实例,接口910、912、914中的一个或多个可以用于使用户或用户设备(例如,个人计算机(personalcomputer,pc)等)能够与处理系统900交互/通信。处理系统900可以包含图9中未描绘的额外组件,例如,长期存储设备(例如,非易失性存储器等)。
在一些实施例中,处理系统900包含在接入电信网络或另外作为电信网络的部件的网络设备中。在一个实例中,处理系统900处于无线或有线电信网络中的网络侧设备中,所述网络侧设备例如,基站、中继站、调度器、控制器、网关、路由器、应用程序服务器,或电信网络中的任何其它设备。在其它实施例中,处理系统900处于接入无线或有线电信网络的用户侧设备中,所述用户侧设备例如,移动站、用户设备(userequipment,ue)、个人计算机(personalcomputer,pc)、平板计算机、可穿戴式通信设备(例如,智能手表等),或用于接入电信网络的任何其它设备。在其它实施例中,处理系统900是不具有与其它设备通信的能力的单独数据处理系统。
用于执行基于散列的数据库操作的设备中的方法的所揭示实施例包含:在设备处接收数据库查询;创建多个执行工作线程以处理查询;由执行工作线程根据数据库表构建散列表,所述数据库表包括多个分区和多个扫描单元中的一个,散列表由执行工作线程共享,每个执行工作线程扫描对应分区并且在分割数据库表的情况下将条目添加到散列表,每个执行工作线程扫描未处理的扫描单元并且在数据库表包括扫描单元的情况下根据扫描单元将条目添加到散列表,并且工作线程以并行方式执行扫描和添加。所述方法还可以包含通过执行工作线程使写入与散列桶同步以最小化用于散列桶的执行工作线程之间的竞争,或利用无锁定算法来最小化用于散列桶的执行工作线程之间的竞争。在实施例中,所述方法可以包含:根据smp数据库的并行度(degreeofparallelism,dop)将散列表分成多个散列表分区;通过每个执行工作线程启动用于数据交换的对应生产者线程,所述生产者线程扫描来自数据库表的对应分区数据,散列对应分区数据以及将散列的对应分区数据发送到对应执行工作线程;以及用执行工作线程对散列的对应分区数据进行散列并且将数据条目添加到分割散列表的相应分区。所述方法可以包含:分割外部表;以及将外部表的每个分区分配到执行工作线程中的相应一个,每个执行工作线程通过其它执行工作线程执行的扫描和探测来相对于散列表并行扫描外部表的对应分区以及探测来自外部表的条目。在实施例中,所述方法可以包含执行聚合操作,其中聚合操作包括:将散列表分成分区;将第一分区分配到执行工作线程中的第一个执行工作线程;以及当执行工作线程中的第一个执行工作线程完成处理第一分区时,将第二分区分配到执行工作线程中的第一个执行工作线程,其中在分配到执行工作线程中的第一个执行工作线程之前,第二分区尚未由执行工作线程中的一个处理。在实施例中,所述方法可以包含:将散列表的桶分成组;将组中的一个保存在存储器中;以及将组中的其它组溢出到存储磁盘上。所述方法还可以包含:与散列表中的所有数据相比,确定散列表的分区中的数据的百分比;以及根据百分比并且根据存储器的大小选择组大小。在实施例中,所述方法可以包含:创建一对分区,每一对分区包括内部表的分区和外部表的分区;将散列表的分区加载到存储器中,散列表的分区由执行工作线程共享;以及将外部表的分区的多个部分中的每一个分配到执行工作线程中的相应一个,每个执行工作线程与其它执行工作线程并行地在分区的所分配部分上执行连接操作。所述方法可以包含:创建一对分区,每一对分区包括内部表的分区和外部表的分区;在执行工作线程之间拆分分区对,每个工作线程连接一对或多对分区;以及收集来自执行工作线程的连接结果。在实施例中,所述方法可以包含执行具有溢出的并行散列聚合操作,其中并行散列聚合操作包括当执行工作线程中的一个空闲时,将未处理的散列分区分配到执行工作线程中的一个。所述方法可以包含执行具有溢出的并行散列聚合操作,其中并行散列聚合操作包括将散列表的分区中的每一个分配到相应执行工作线程,每个执行工作线程处理其所分配分区。
用于执行基于散列的数据库操作的设备的所揭示实施例包含处理器和非暂时性计算机可读存储媒体,所述非暂时性计算机可读存储媒体存储由处理器执行的编程,所述编程包含用于以下操作的指令:接收smp数据库查询;创建多个执行工作线程以处理查询;以及由执行工作线程根据数据库表构建散列表,所述数据库表包括多个分区和多个扫描单元中的一个,散列表由执行工作线程共享,每个执行工作线程扫描对应分区并且在分割数据库表的情况下将条目添加到散列表,每个执行工作线程扫描未处理的扫描单元并且在数据库表包括扫描单元的情况下根据扫描单元将条目添加到散列表,并且工作线程以并行方式执行扫描和添加。
虽然已参考说明性实施例描述了本发明,但此描述并不意图解释为具有限制意义。本领域普通技术人员在参考所述描述后将会明白,说明性实施例的各种修改和组合以及本发明其它实施例。因此,所附权利要求书意图涵盖任何此类修改或实施例。
- 还没有人留言评论。精彩留言会获得点赞!