软件分析系统、软件分析方法和软件分析程序与流程
本发明涉及软件分析系统、软件分析方法和软件分析程序。
背景技术:
伴随智能手机等的移动终端的普及,用户在移动终端上下载而能够使用的应用得以被广泛利用。在搭载有android(注册商标)或ios(注册商标)等的移动终端进行动作的应用大多对用户的隐私信息进行处理。关于用户的隐私信息,由内置于移动终端的传感器等的硬件取得,或由用户自身输入到移动终端。隐私信息例如指的是用户的位置信息、移动终端的个体识别号、地址簿等与用户个人联系起来的信息。
在移动终端进行动作的应用处理隐私信息时,要求对该隐私信息适当地进行处理。此外,对于在移动终端进行动作的应用,要求向用户公开访问何种的隐私信息。
为了实现这种要求,较多的移动终端平台都导入了被称为权限的功能。权限指的是为了控制对于隐私信息的访问而被导入的功能。
例如,对于使用位置信息的应用,在该应用被安装于移动终端时,对用户要求使用位置信息的权限的许可。用户若许可了权限的使用,则该应用被安装于移动终端。在用户不许可权限的使用的情况下,该应用不被安装于移动终端。通过使用权限,用户能够预先获悉存在被应用使用的可能性的隐私信息。
在先技术文献
非专利文献
非专利文献1:r.pandita,x.xiao,w.yang,w.enck,andt.xie,“whyper:towardsautomatingriskassessmentofmobileapplications”,inproc.ofthe22ndusenixsecuritysymposium,pp.527-542,2013
非专利文献2:渡邉卓弥、秋山満昭、酒井哲也、鷲崎弘宜、森達哉、「androidアプリの説明文とプライバシー情報アクセスの相関分析」、コンピュータセキュリティシンポジウム2014論文集、vol.2014,no.2,pp.590-597,oct2014(渡边卓弥、秋山满昭、酒井哲也、鹫崎弘宜、森达哉《android应用的说明文和隐私信息访问的相关分析》,计算机安全研究会2014论文集,vol.2014,no.2,pp.590-597,oct2014)
技术实现要素:
发明要解决的课题
然而,通过现有的权限功能而被提供的信息在大多情况下未被用户所注意(参照非专利文献1、2)。此外,若不具备专门的知识则难以理解通过权限功能而被提供的信息。此外,用于难以直观地把握通过权限功能而被提供的信息。因此,可认为在用户并未察觉的情况下,应用取得了隐私信息。
鉴于这种状况,提出了对应用的说明文中是否记载有访问隐私信息进行自动判定的技术。应用的说明文针对所有需求而被设定,还成为检索应用时的检索对象。例如,非专利文献1提出了如下技术,对移动终端的应用的说明文的文本(以下,也称为说明文文本或文本)进行分析,确定文本中的哪个部分相当于对隐私信息的访问。此外,非专利文献2提出了如下技术,将文本分析与应用的代码分析组合起来,在由代码分析揭示的对隐私信息的访问与文本中的记述存在矛盾的情况下提取存在矛盾的应用。
然而,在非专利文献1、2记载的技术中的说明文的分析中,由人预先读取应用的说明文文本,对是否存在表示访问特定的隐私信息的记载进行解读。并且,根据解读结果对应用赋予标签。然而,隐私信息分布较广,在通过机械学习等的统计方法尝试进行文本的分类的情况下,需要准备大量的文本来赋予标签。一般情况下,手动对数据赋予标签的作业比较耗费成本。此外,对大规模的数据通过手动赋予标签的手法欠缺可伸缩性。
本发明公开的技术就是鉴于上述情况而完成的,其目的在于提供根据应用的代码和说明文,能够自动分析是否对用户公开了应用对于用户的隐私信息的访问的有无的软件分析系统、软件分析方法和软件分析程序。
用于解决课题的手段
本发明公开的软件分析系统、软件分析方法和软件分析程序的特征在于,根据多个应用的代码来判定该多个应用是否基于权限访问规定的隐私信息。并且,所公开的软件分析系统、软件分析方法和软件分析程序对被判定为访问规定的隐私信息的应用赋予第1标签,对被判定为不访问规定的隐私信息的应用赋予不同于第1标签的第2标签。所公开的软件分析系统、软件分析方法和软件分析程序以相比被赋予第2标签的应用的说明文的文本而言,更多地包含于被赋予第1标签的应用的说明文的文本中的单词的分数变高的方式来计算包含于多个应用的说明文中的单词各自的分数,并且与权限对应地,从多个应用的说明文中提取被计算的分数在从上位起规定数位内的单词。进而,所公开的软件分析系统、软件分析方法和软件分析程序将提取的单词包含于说明文的文本中的应用分类为涉及权限的应用,将提取的单词不包含于说明文的文本中的应用分类为不涉及权限的应用。
发明效果
所公开的软件分析系统、软件分析方法和软件分析程序可获得根据应用的代码和说明文能够自动分析是否对用户公开了应用对用户的隐私信息的访问的有无的效果。
附图说明
图1是表示实施方式的软件分析系统的结构的一例的概略图。
图2是用于说明储存于应用信息存储部中的信息的结构的一例的图。
图3是用于说明存储于关键词列表存储部中的信息的结构的一例的图。
图4是表示实施方式的软件分析系统执行的处理的流程的一例的流程图。
图5是表示实施方式的标签生成处理的流程的一例的流程图。
图6是表示实施方式的分数计算处理(关键词提取处理)的流程的一例的流程图。
图7是表示实施方式的分类处理的流程的一例的流程图。
图8是用于说明实施方式的软件分析系统执行的处理的流程的一例的指令图。
图9是表示变形例的软件分析系统的结构的一例的概略图。
图10是表示储存于变形例的应用信息存储部中的信息的结构的一例的图。
图11是表示变形例的软件分析系统执行的处理的流程的一例的流程图。
图12是表示执行实施方式的软件分析程序的计算机的图。
具体实施方式
以下,根据附图对所公开的系统、方法和程序的实施方式进行详细说明。另外,本发明并不限于该实施方式。此外,还可以适当组合各实施方式。
[软件分析系统的结构的一例]
图1是表示实施方式的软件分析系统1的结构的一例的概略图。图1所示的软件分析系统1例如是用户为了在移动终端上下载应用而访问的下载服务的运营者所运用的进行应用的事先审查的服务器。另外,在以下的记载中,也将“应用程序”称作“应用”。
软件分析系统1具有存储部10、标签生成部20、分数计算部30和分类部40。
存储部10例如是半导体存储器元件或存储装置。例如,作为半导体存储器元件,可使用vram(videorandomaccessmemory:视频随机存取存储器)、ram(randomaccessmemory:随机存取存储器)、rom(readonlymemory:只读存储器)和闪存(flashmemory)等。此外,作为存储装置,可使用硬盘、光盘等的存储装置。
存储部10存储与作为软件分析系统1的分析处理的对象的应用有关的信息。此外,存储部10存储作为软件分析系统1的分析处理的结果而得到的信息。
存储部10具有应用信息存储部11和关键词列表存储部12。图2是用于说明储存于应用信息存储部11中的信息的结构的一例的图。此外,图3是用于说明储存于关键词列表存储部12中的信息的结构的一例的图。
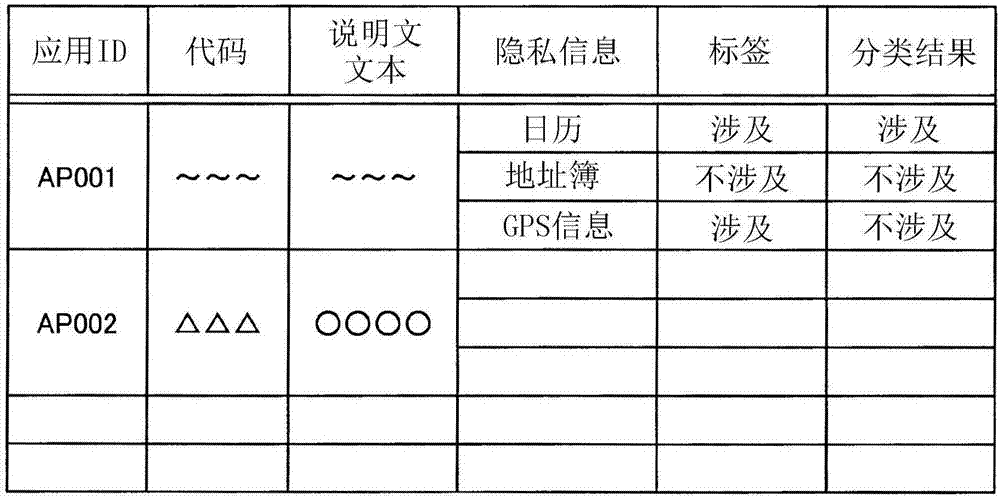
如图2所示,应用信息存储部11以与“应用id”对应的方式存储“代码”、“说明文文本”、“隐私信息”、“标签”和“分类结果”。
“应用id”是用于唯一地识别作为软件分析系统1的分析处理的对象的应用的识别子。“代码”是该应用的代码。例如是应用的源代码。“说明文文本”是该应用的说明文的文本。“隐私信息”表示基于权限而被许可应用的访问的用户的隐私信息的种类。作为隐私信息,例如具有gps(globalpositioningsystem:全球定位系统)信息、日历、相机功能、地址簿等。
“标签”是根据软件分析系统1的代码分析的结果,由软件分析系统1赋予给各应用的标签。此外,“标签”是表示应用是否访问规定的隐私信息的判定结果的暂定的标签。标签中包括“涉及”和“不涉及”的2种。“涉及”表示代码中存在表示应用访问规定的隐私信息的信息。此外,“不涉及”表示代码中不存在表示应用访问规定的隐私信息的信息。“分类结果”表示软件分析系统1根据对说明文文本进行分析而提取的关键词是否包含于各应用的说明文文本中,来对应用进行分类的结果。“分类结果”中包括“涉及”和“不涉及”的2种。“涉及”表示应用的说明文文本中包含关键词。“不涉及”表示应用的说明文文本中不包含关键词。“标签”和“分类结果”分别对应于各个隐私信息而被储存。另外,关于用于获得标签的生成处理和分类结果的分类处理将在后文描述。另外,图2中,以隐私信息与权限被唯一地对应起来作为前提,将标签和分类结果与隐私信息对应起来存储,也可以构成为取代隐私信息而与权限对应起来存储。
图2中,例如与应用id“ap001”的应用对应起来地存储有该应用的说明文文本“~~~”和对应的代码“~~~”。此外,与该应用对应地还存储有表示该应用是否分别访问3种的隐私信息的标签和分类结果。关于“隐私信息、日历”,存储有“标签、涉及”。这表示,根据代码分析,应用id“ap001”的应用访问用户的日历。此外,在图2中,与应用id“ap001”对应地存储有“隐私信息、地址簿”、“分类结果、不涉及”。这表示,在通过应用id“ap001”确定的应用的说明文文本中不包含与“隐私信息、地址簿”对应的关键词。
接着,参照图3,对被存储于关键词列表存储部12中的信息进行说明。如图3所示,关键词列表存储部12存储“隐私信息”、“功能(权限)”和“关键词”。“隐私信息”与存储于应用信息存储部11中的“隐私信息”同样。“功能(权限)”是许可对于所对应的隐私信息的访问的权限的名称。权限例如指的是对android(注册商标)规定的“read_contacts”、“read_calender”等。“关键词”是被软件分析系统1从应用的说明文文本中提取出的关键词。关于提取关键词的处理的详细情况将在后文描述。
在图3的示例中,与“隐私信息、gps信息”对应地存储有“功能(权限)、location”以及“关键词、gps,location,map”。这表示,基于权限“location”的功能而被许可访问的隐私信息是gps信息。此外,图3还示出作为与权限“location”对应的关键词而提取出了“gps,location,map”的3个单词。另外,在图3的例子中,与各隐私信息和功能(权限)对应地存储有3个关键词。其中,与各隐私信息和功能(权限)对应起来的关键词的数量不限于3个。
返回图1,进一步说明软件分析系统1的结构的一例。标签生成部20根据存储于存储部10中的应用的信息进行代码分析的结果是,生成表示判定为各应用是否访问用户的隐私信息的标签。
分数计算部30使用由标签生成部20生成的标签,对应用的说明文文本进行分析,计算在说明文文本中包含的单词各自的分数。分数计算部30按照每个权限来计算各单词的分数。分数计算部30以相比于标签“不涉及”的应用的说明文的文本而言,更多地包含于标签“涉及”的应用的说明文的文本中的单词的分数变高的方式,计算包含于说明文文本中的单词各自的分数。其中,计算手法不做特别限定,例如,可利用使用比值比或相关反馈的手法。使用这些手法,例如能够根据标签“涉及”的应用的总数、说明文的文本包含规定的单词的应用的总数、标签“涉及”的应用中的说明文的文本包含规定的单词的应用的总数等来计算分数。
此外,分数计算部30计算的分数的计算手法中,越是在标签“涉及”的应用的说明文文本中频繁出现且在标签“不涉及”的应用的说明文文本中几乎不出现的单词,则越被设定为较高的值。即,以越是在标签“涉及”的应用的说明文文本中的出现频度高于在标签“不涉及”的应用的说明文文本中的出现频度的单词,则分数越高的方式来设定分数的计算手法。此外,分数的计算手法中,越是在使用api(applicationprogramminginterface:应用程序设计接口)的应用的说明文文本中频繁出现且在不使用api的应用的说明文文本中几乎不出现的单词越被设定为较高的值。
分数计算部30与权限对应地以分数从高到低的顺序将上位规定数的单词作为与权限对应的关键词提取。关键词指的是被预测为在访问对应的隐私信息的应用的说明文文本中出现的单词。分数计算部30提取的关键词与隐私信息和权限对应地被存储于关键词列表存储部12。
分类部40对各应用的说明文文本是否包含被提取的关键词进行判定。并且,分类部40将包含关键词的说明文文本的应用分类为“涉及”的应用。此外,分类部40将不包含关键词的说明文文本的应用分类为“不涉及”的应用。分类部40的分类结果与各应用和隐私信息对应地被存储于应用信息存储部11。
[软件分析系统的分析处理的流程的一例]
图4是表示实施方式的软件分析系统1执行的处理的流程的一例的流程图。作为图4的处理的前提,软件分析系统1预先取得与多个应用有关的信息,并存储于存储部10的应用信息存储部11。如图4所示,软件分析系统1的分析处理包含标签生成部20的标签生成(代码分析)(步骤s21)、分数计算部30的分数计算(关键词提取)(步骤s22)、分类部40的分类(步骤s23)的各处理。若分类部40的分类完成则处理结束。以下,对各部的处理的流程进行说明。
[标签生成处理的流程的一例]
标签生成部20根据存储于应用信息存储部11中的应用的信息,生成各应用的标签。图5是表示实施方式的标签生成处理的流程的一例的流程图。如图5所示,标签生成部20首先作为分析的对象而选择1个应用和1个隐私信息(步骤s51)。例如,标签生成部20选择应用id“ap001”的应用。此外,标签生成部20作为隐私信息而选择相机功能。关于标签生成部20对应用和隐私信息的选择的顺序,既可以预先确定并存储于软件分析系统1,也可以由用户指定所选择的应用和隐私信息。
并且,标签生成部20将所选择的应用的代码从应用信息存储部11读出。关于应用的代码,在能够取得源代码的情况下取得源代码并存储于应用信息存储部11。此外,在无法取得源代码的情况下,将使用逆向工程等的手法而反汇编后的代码预先存储于应用信息存储部11。
接着,标签生成部20判定读出的代码中是否包含权限的宣告(步骤s52)。例如在使用android(注册商标)的应用的情况下,标签生成部20判定在androidmanifest.xml中权限是否已被宣告。
标签生成部20在判定为权限已被宣告的情况下(步骤s52,yes),接下来判定与所选择的隐私信息(即权限)对应的api是否包含于代码中(步骤s53)。而且,在判定为包含api的情况下(步骤s53,yes),标签生成部20对函数调用关系图进行分析,判定该api能否被实际调用(步骤s54)。并且,对函数调用关系图进行分析的结果是判定为能够调用的情况下(步骤s54,yes),标签生成部20对该应用生成标签“涉及”(步骤s55)。
另一方面,在判定为权限未被宣告的情况下(步骤s52,no),标签生成部20对该应用赋予“不涉及”的标签(步骤s56)。在判定为不包含api的情况下(步骤s53,no)和根据函数调用关系图分析判定为无法调用的情况下(步骤s54,no)也同样由标签生成部20生成“不涉及”的标签。由此,标签生成处理结束。被生成的标签与应用和隐私信息对应地被存储于应用信息存储部11。
标签生成部20对各应用和隐私信息反复执行图5所示的处理,从而生成与多个应用和隐私信息对应的标签,并存储于应用信息存储部11。
另外,如图5所示那样经过3个阶段的判定而赋予标签的原因在于,在代码中存在权限的宣告或对应的api的情况下,实际有时会成为不访问隐私信息的代码。
[分数计算处理(关键词提取处理)的流程的一例]
分数计算部30使用被赋予标签的应用和隐私信息,提取用于根据说明文文本确定访问隐私信息的应用的关键词。
图6是表示实施方式的分数计算处理(关键词提取处理)的流程的一例的流程图。首先,分数计算部30从应用信息存储部11读出与结束了标签生成处理的多个应用对应的说明文文本(步骤s61)。并且,分数计算部30选择权限(步骤s62)。而且,分数计算部30对读出的说明文文本进行分析,选择一个包含于说明文文本中的单词(步骤s63)。
并且,分数计算部30计算所选择的单词的分数(步骤s64)。以下,说明使用相关反馈计算分数的示例。作为一例,分数计算部30使用以下的式(1)来计算分数。式(1)是将总数n个(n是自然数)的应用作为分析对象,用于计算在其中第i个(i是1以上n以下的自然数)的应用ai中包含的单词wi的分数的式。
【数1】
其中,式(1)中,r是被赋予标签“涉及”的应用的总数,ri是将单词wi包含于说明文文本中并被赋予标签“涉及”的应用的总数。此外,n是作为分析对象的应用的总数,ni是将单词wi包含于说明文文本中的应用的总数。此外,式(1)中,为避免分子和分母为零,加上了0.5。其中,加上的值不限于0.5,例如还可以是0.1或0.6。
分数计算部30接下来判定是否对所有的单词的分数进行了计算(步骤s65)。在判定为未对所有的单词的分数进行计算的情况下(步骤s65,no),分数计算部30接下来选择作为处理对象的单词(步骤s66)。并且,处理返回步骤s64。另一方面,在判定为对所有的单词的分数进行了计算的情况下(步骤s65,yes),分数计算部30按照对每个权限计算的分数的从高到低的顺序对单词排序,提取上位规定数的单词(步骤s67)。例如,分数计算部30提取上位3个的单词。这里,将所提取的单词的数量设为3的原因在于,基于本发明者等人的实验结果,在将所提取的单词数设为3的情况下,最终得到了良好的分类精度。其中,也可以将所提取的单词数设定位其他的数。由此,分数计算处理(关键词提取处理)结束。
另外,在以上的示例中,采用的是使用相关权重(relevanceweight)来计算分数的手法。然而,用于计算分数的式不限于上述的示例。用于计算分数的式只要是能够将容易包含于某集合的应用而不易包含于其他的集合的应用的单词的性质数值化即可。
例如,可采用比值比作为分数。首先,将规定的单词包含于标签“涉及”的应用的集合中的概率设为p,将包含于标签“不涉及”的应用的集合中概率设为q。并且,用(p/(1-p))除以(q/(1-q))来计算比值比。计算出的比值比越大,则表示规定的单词越容易包含于标签“涉及”的应用的集合,并越不容易包含于标签“不涉及”的应用的集合。
例如,若单词“sns”包含于标签“涉及”的应用的集合中的概率p是0.9,而包含于标签“不涉及”的应用的集合中的概率q是0.1,则根据上式计算出的比值比为81。同样地对于其他的单词也计算比值比并将比值比作为分数。并且,按照分数从高到低的顺序对单词排位。最后,按照位次从上到下的单词的顺序作为更容易包含于“涉及”的应用的集合中的关键词提取即可。
[分类处理的流程的一例]
分类部40根据分数计算部30提取的关键词和应用的说明文文本,基于各应用是否访问隐私信息来对应用进行分类。图7是表示实施方式的分类处理的流程的一例的流程图。
分类部40首先将作为分类对象的应用的说明文文本从应用信息存储部11读出。然后,分类部40提取包含于该说明文文本中的所有的单词(步骤s71)。并且,分类部40判定与分数计算部30提取的关键词一致的单词是否包含于从说明文文本提取的单词(步骤s72)。在判定为包含一致的单词的情况下(步骤s72,yes),分类部40将该应用分类为“涉及”与关键词对应的权限分类的应用(步骤s73)。这里,分类“涉及”表示被判定为对基于与关键词对应的权限而被许可访问的隐私信息进行访问的应用。另一方面,在判定为不包含一致的单词的情况下(步骤s72,no),分类部40将该应用分类为“不涉及”与关键词对应的权限的应用(步骤s74)。这里,分类“不涉及”表示被判定为对基于与关键词对应的权限而被许可访问的隐私信息不进行访问的应用。由此,分类处理结束。
图8是用于说明实施方式的软件分析系统1执行的处理的流程的一例的指令图。图8所示的处理对应于参照图4至图7说明的处理的流程。
如图8所示,在软件分析系统1中,首先,准备作为分析的对象的应用的信息和说明文文本(图8的(1))。例如,软件分析系统1通过网络取得应用的数据,并存储于存储部10。
然后,标签生成部20参照存储于存储部10中的应用的代码(图8的(2)),执行该代码的分析(图8的(3))。标签生成部20根据代码分析的结果生成标签并存储于存储部10(图8的(4))。
分数计算部30一并取得存储于存储部10中的应用的信息和标签(图8的(5)),执行分数计算处理(关键词生成处理)(图8的(6))。分数计算部30进行处理的结果是生成关键词列表,并存储于存储部10。接下来,分类部40从存储部10取得关键词列表(图8的(7))。接着,分类部40从存储部10取得说明文文本(图8的(8))。分类部40根据所取得的关键词列表和说明文文本,执行文本分类(图8的(9))。并且,将分类部40进行处理后得到的分类结果存储于存储部10(图8的(10))。
[实施方式的效果]
如上述的那样,上述实施方式的软件分析系统具有标签生成部、分数计算部和分类部。并且,标签生成部根据多个应用的代码,判定该多个应用是否基于权限访问规定的隐私信息。此外,标签生成部对被判定为访问规定的隐私信息的应用赋予第1标签(“涉及”),对被判定为不访问规定的隐私信息的应用赋予不同于第1标签的第2标签(“不涉及”)。分数计算部以相比被赋予第2标签的应用的说明文的文本而言,更多地包含于被赋予第1标签的应用的说明文的文本中的单词的分数变高的方式来计算包含于多个应用的说明文中的单词各自的分数,并且与权限对应地从多个应用的说明文中提取被计算的分数从上位起规定数位内的单词。分类部将分数计算部提取的单词包含于说明文的文本中的应用分类为涉及权限的应用,将分数计算部提取的单词不包含于说明文的文本中的应用分类为不涉及权限的应用。
因此,实施方式的软件分析系统通过将代码分析与说明文的文本分析组合起来,能够高精度地判定应用对隐私信息的访问的有无、以及对应用的说明文中的隐私信息的访问的涉及的有无。此外,实施方式的软件分析系统能够使说明文的文本分析变得自动化,能够提高文本分析的处理效率和抑制成本。此外,实施方式的软件分析系统能够自动地执行在访问隐私信息的应用的说明文中以特征形式包含的单词的提取,能够提高处理效率和抑制成本。这样,根据实施方式的软件分析系统,根据应用的代码和说明文,能够自动地分析是否已对用户公开了应用对用户的隐私信息的访问的有无。
[变形例]
在上述实施方式中,软件分析系统1根据各应用的代码和说明文文本,判定该应用是否访问规定的隐私信息。此外,上述实施方式的软件分析系统1根据说明文文本,对各应用向隐私信息的访问是否已在说明文中公开进行分类。以下,作为变形例说明软件分析系统对新检测出的应用进行分析而取得分类结果,并根据分类结果确定恶性应用和良性应用的示例。变形例的软件分析系统还构成为,在新检测出的应用是恶性应用的情况下向用户发出警告。
图9是表示变形例的软件分析系统1a的结构的一例的概略图。如图9所示,变形例的软件分析系统1a具有存储部10a、标签生成部20、分数计算部30、分类部40、确定部50和发送部60。此外,存储部10a具有应用信息存储部11a和关键词列表存储部12。标签生成部20、分数计算部30、分类部40具备与上述实施方式的软件分析系统1具有的标签生成部20、分数计算部30、分类部40同样的结构和功能。此外,存储于关键词列表存储部12中的信息也与上述实施方式的软件分析系统1的情况同样。变形例的软件分析系统1a与上述实施方式的软件分析系统1的不同之处在于,具有确定部50、发送部60以及存储于应用信息存储部11a中的信息。在以下的说明中,对与上述实施方式的软件分析系统1同样的结构和功能省略说明,仅对不同之处进行说明。
确定部50对标签生成部20生成的标签与分类部40的分类结果进行比较,确定矛盾的应用。例如,图2中,在针对应用id“ap001”的应用存储的信息中,与“隐私信息,gps信息”对应的标签为“涉及”,而分类结果为“不涉及”。这表示,根据通过应用id“ap001”确定的应用的代码分析的结果,该应用访问用户的gps信息。此外,根据该应用的说明文文本的分析的结果,表示关于该应用访问用户的gps信息而在说明文中并未涉及。即,应用id“ap001”的应用是访问作为用户的隐私信息的“gps信息”的应用,然而该应用却在用户仅凭阅读说明文而无法获悉的状态下被发布。确定部50如上确定“标签”与“分类结果”不一致的应用。
关于确定部50确定的应用,在应用信息存储部11a中存储表示为恶性的标记。图10是表示存储于变形例的应用信息存储部11a中的信息的结构的一例的图。在图10的示例中,与“应用id,ap001”、“隐私信息,gps信息”、“标签,涉及”、“分类结果,不涉及”对应地存储有“标记,on”。这表示,应用id“ap001”的应用访问gps信息,然而这种情况并未记载于说明文,可推定为恶性应用。
发送部60在用户要下载被确定部50确定为恶性应用的应用时,将表示该应用被推定为恶性应用的警告发送给该用户的移动终端。发送部60例如发送表示被推定位恶性应用以及被该应用访问的隐私信息的通知。
图11是表示变形例的软件分析系统1a执行的处理的流程的一例的流程图。首先,确定部50将对应的标签和分类结果从应用信息存储部11a读出(步骤s111)。然后,确定部50判定所读出的标签与分类结果之间是否存在矛盾(步骤s112)。例如,在标签是“涉及”,而分类结果是“不涉及”的情况下,确定部50判定为存在矛盾。此外,在标签是“不涉及”,分类结果也是“不涉及”的情况下,确定部50判定为不存在矛盾。
在判定为存在矛盾的情况下(步骤s112,yes),确定部50将该应用判定为恶性应用(步骤s113)。并且,确定部50与存储于应用信息存储部11a中的该应用的信息对应地,将表示为恶性应用的标记设为on。另一方面,在判定为不存在矛盾的情况下(步骤s112,no),确定部50结束处理。
并且,发送部60向下载了被确定部50确定为恶性应用的应用的用户发送警告(步骤s114)。由此,变形例的确定部50和发送部60的处理结束。
[变形例的效果]
这样,变形例的软件分析系统1a还具有确定部,该确定部将被标签生成部赋予第1标签(“涉及”)且被分类部分类为不涉及权限的应用的应用确定为恶性应用。因此,软件分析系统1a能够易于确定在代码分析的结果与文本分析的结果中存在矛盾的应用,并作为恶性应用提取。
此外,变形例的软件分析系统1a还具有发送部,该发送部在被标签生成部赋予第1标签(“涉及”)且被分类部分类为不涉及权限的应用的应用被安装于移动终端时发送警告信息。因此,能够对使用移动终端下载应用的用户警告存在恶性应用的可能性。
(其他的实施方式)
以上对本发明的实施方式进行了说明,然而本发明除了上述实施方式以外,还可以通过其他的实施方式实施。以下,对其他的实施方式进行说明。
在上述实施方式中,预先在软件分析系统1中存储有1个以上的应用的信息。然而不限于此,软件分析系统还可以构成为,通过网络与提出应用的应用制作者的信息终端等连接,并接收从该信息终端发送的应用进行分析。这种情况下,可以构成为发送部60将确定部50的处理结果发送给应用制作者的信息终端。此外,这种情况下,可以构成为不执行分数计算部的分数的计算和关键词的提取。即,分类部可以使用已被存储于关键词列表存储部12中的关键词来执行新的应用的分类。通过这样构成,每当接收到新应用时,无需更新关键词列表,能够迅速执行分类部的处理。
此外,软件分析系统1还可以构成为通过网络与提供应用服务的1个以上的服务商的服务器连接。并且,还可以构成为从该服务商的服务器向软件分析系统1适当发送新应用,从而成为分析对象。
[系统结构等]
图示的各装置的各构成要素是功能概念的性质,未必要求物理上如图所示那样构成。即,各装置的分散、统合的具体方式不限于图示的内容,也可以将其全部或一部分根据各种负荷和使用状况等以任意的单位在功能或物理上分散、统合构成。例如,可以将关键词列表存储部12构成为在软件分析系统1的外部的存储装置中存储,由其他的服务器使用关键词来确定恶性应用。
进而,由各装置进行各处理功能的全部或任意的一部分可通过cpu和被该cpu分析执行的程序来实现,或者可作为基于布线逻辑的硬件来实现。
此外,还可以手动来进行在本实施方式中说明的各处理中的作为自动进行而说明的处理的全部或一部分,或者,还可以通过公知的方法自动进行作为手动进行而说明的处理的全部或一部分。此外,关于在上述文件中或附图中示出的包含处理步骤、控制步骤、具体名称、各种数据和参数的信息,除了特别说明的情况以外可任意变更。
[程序]
此外,还可以制作将在上述实施方式中说明的由软件分析系统1、1a执行的处理通过计算机可执行的语言记述的程序。例如,还可以制作将实施方式的软件分析系统1、1a执行的处理通过计算机可执行的语言记述的程序。这种情况下,计算机执行程序,由此可获得与上述实施方式同样的效果。进而,还可以将该程序记录于计算机可读取的记录介质中,并使计算机读入记录于该记录介质中的程序并执行,由此实现与上述实施方式同样的处理。以下,对执行实现与软件分析系统1、1a同样的功能的程序的计算机的一例进行说明。
图12是表示执行软件分析程序的计算机1000的图。如图12中例示的那样,计算机1000例如具有存储器1010、cpu(centralprocessingunit:中央处理单元)1020、硬盘驱动器接口1030、磁盘驱动器接口1040、串行端口接口1050、视频适配器1060和网络接口1070,这些各部分通过总线1080而被连接。
存储器1010如图12中例示的那样,包括rom(readonlymemory:只读存储器)1011和ram(randomaccessmemory:随机存取存储器)1012。rom1011例如存储bios(basicinputoutputsystem:基本输入输出系统)等的boot程序。硬盘驱动器接口1030如图12中例示的那样,与硬盘驱动器1090连接。磁盘驱动器接口1040如图12中例示的那样,与磁盘驱动器1041连接。例如可装卸磁盘或光盘等的存储介质被插入磁盘驱动器1041。串行端口接口1050如图12中例示的那样,例如与鼠标1110、键盘1120连接。视频适配器1060如图12中例示的那样,例如与显示器1130连接。
这里,如图12中例示的那样,硬盘驱动器1090例如存储os(operatingsystem:操作系统)1091、应用程序1092、程序模块1093和程序数据1094。即,上述的程序作为记述有被计算机1000执行的指令的程序模块而例如被存储于硬盘驱动器1090。
此外,上述实施方式中说明的各种数据作为程序数据而例如被存储于存储器1010或硬盘驱动器1090。并且,cpu1020根据需要将存储于存储器1010和硬盘驱动器1090中的程序模块1093和程序数据1094读出到ram1012,来执行各种处理步骤。
另外,作为程序的程序模块1093和程序数据1094,不限于存储于硬盘驱动器1090中的情况,例如还可以存储于可装卸的存储介质,通过磁盘驱动器等而被cpu1020读出。或者,作为程序的程序模块1093和程序数据1094,还可以存储于通过网络(lan(localareanetwork:局域网)、wan(wideareanetwork:广域网)等)连接的其他的计算机,通过网络接口1070而被cpu1020读出。
标号说明
1、1a软件分析系统
10、10a存储部
11、11a应用信息存储部
12关键词列表存储部
20标签生成部
30分数计算部
40分类部
50确定部
60发送部
- 还没有人留言评论。精彩留言会获得点赞!