用于对商家进行排名的方法和系统与流程
相关申请的交叉引用
本申请要求于2015年7月24日提交的新加坡专利申请no.10201505793r的申请日的优先权和权益,其全部内容通过引用合并于此。
本发明涉及一种用于形成并向潜在顾客呈现进行商业交易的多个商家之间的排名的方法和系统。
背景技术:
通常,各种商家提供特定类型的商品和/或服务(这里统称为“商品”),因此这些商品和服务的潜在消费者必须选择使用哪个商家。已经提出了自动化系统来协助该选择。例如,us8725597旨在提供一种用于确定任何给定的商家是否是可靠的商业伙伴的自动机制,尽管它不比较商家。
此外,存在各种商家比较网站,其向潜在客户呈现具有提供该商品的商家的排名列表的商品,例如给定地理区域内的商家。例如,tripadvisor网站允许顾客查看指定地理区域(例如,城镇)中的旅馆或餐馆的排名列表。列表可以被限制为仅包括符合某些特定标准的旅馆或餐馆(例如,具有特定星级的旅馆或提供特定餐饮的餐馆)。
排名一般是基于由是商家以前的客户的公众成员(即网站是“社交媒体来源”)输入的反馈值。然而,这可能会受到一些危害排名可靠性的问题的影响。特别是,假装使用被考虑的商家但实际上并没有的个人所给予的反馈值是脆弱的。其次,他们可能是与商家有关联的个人,因此留下有偏见的反馈值。第三,即使个人是商家的真正的前客户,他们也可能是统计角度上的非典型的商家的客户;例如,使用商家的经验不佳的个人更有可能留下评论。这些因素导致不同排名网站之间的相当大的变化。例如,图1示出了某个城市的各个餐馆的真实排名,如由比较网站yelp、tripadvisor、justluxe、urbanspoon和zagat给出。为了匿名,餐馆的真实名字已被““餐馆a”至“餐馆z”、“餐馆aa”至“餐馆zz”和“餐馆aaa”至“餐馆ddd”代替。在四家商家比较网站中排名前五位的餐馆a根据tripadvisor甚至不在前18位。
因此,已经考虑了对商家进行排名的替代方法。例如,us8126779允许对商家关于他们以特定价格提供的特定产品进行排名。比较是基于用户选择的标准,允许客户准确地指定对他来说重要的标准。因此,该比较需要用户有足够的时间来指定他的偏好。其只适用于有知识的消费者,并且用于比较销售非常相似的产品的商家,该产品有详细的价格信息。
在使用支付卡进行支付交易之后对商家进行排名也是已知的。如本文中所使用的,术语“支付卡”是指任何合适的无现金支付设备,例如信用卡、借记卡、预付卡、签账卡、会员卡、促销卡、常旅客卡、身份卡、预付卡、礼品卡和/或可以存储支付账户信息的任何其它设备,例如移动电话、智能电话、个人数字助理(pda)、钥匙扣、转发器设备、具有nfc功能的设备和/或计算机。us2014/279185a1和us2012/0296724提出了基于描述使用支付网络用支付卡进行的支付交易的交易数据对商家进行排名。然而,这两个系统都是用于呈现个性化的排名,即特定于正在寻求商家推荐的给定顾客。除了其它之外两者都依赖于描述由相同的潜在客户进行的先前的支付交易的支付数据,该商家排名呈现给该相同的潜在客户。该支付数据可以由与潜在顾客的支付卡相关联的支付网络生成。因此,这些排序方案不适合于这些支付交易不可用的潜在客户,例如之前没有使用支付卡的用户,或者仅使用与支付数据不可用的支付网络相关联的支付卡的用户。
技术实现要素:
本发明旨在提供用于生成满足一个或多个指定标准的商家排名,并将排名呈现给潜在顾客(“用户”)的方法和系统。作为购买商品和/或服务的过程的一部分,顾客可以使用排名作为选择商家的过程的一部分。
一般而言,本发明提出按照一个或多个选择的标准分类的商家根据算法来排序,该算法根据以下项目的函数为每个商家计算各个分数(排名值):(i)表征涉及的商家的先前的商业交易的一个或多个交易数据值,(ii)从一个或多个社交媒体来源获得的一个或多个评价值,以及根据顾客反馈表征商家的特性,以及(iii)控制交易数据值和评价值在确定分数中的相对重要性的预先确定的参数。
本发明可以以集中式计算机系统(例如服务器)的形式来实现,该集中式计算机系统呈现用户可以连接到的接口(例如通过互联网)。或者,可以将其作为在用户拥有的计算设备上运行的应用来提供,可选地与外部数据库进行通信。
附图说明
现在将参考以下附图仅为了示例而描述本发明的实施例,其中:
图1比较了五个商家比较网站的餐馆排名;
图2示出了该方法的实施例的系统;
图3是由图1的实施例执行的方法的流程图;
图4示出了由图1的实施例生成的餐馆排名;和
图5是用于获得用于图1的方法中的参数的方法的流程图。
具体实施方式
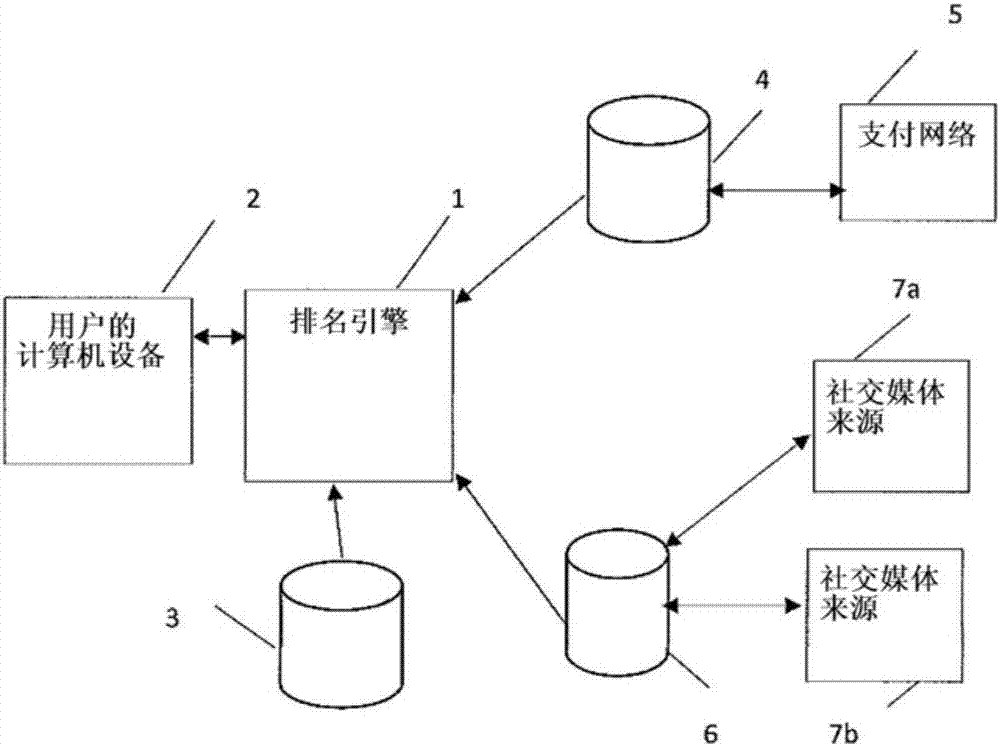
参考图2,描述了本发明的实施例,其是排名引擎1,用于编辑每个提供商品和/或服务(在此统称为“产品”)的商家的排名,并将其呈现给操作与排名引擎1双向通信的计算设备2的用户。在一个实施例中,排名引擎1实现为通过互联网与计算设备2通信的一个或多个服务器。计算设备2可以是个人计算机(pc)或移动设备,例如平板电脑或智能手机。
用户是由多个商家提供的一个或多个商品和/或服务的潜在客户。排名引擎1能够访问描述这些商家中的每一个的基本数据的数据库3:例如,描述商家和每个商家提供的产品的地理位置。
排名引擎1能够访问针对每个商家存储表征涉及商家的先前商业交易的一个或多个交易数据值的交易数据数据库4。交易数据数据库4由支付网络5生成。注意,包含在数据库4中的数据不包括描述单个交易的数据,而是包括每个都描述涉及相应商家的多个交易的数据值。
例如,交易数据值可以存储以下值中的一个或多个:
表a
上面的一些值可以相互推导出来(例如,数量4只是数量1和数量2的比率),所以交易数据数据库4可以为每个商家存储所有这些值,或者其可以只存储它们的子集并且排名引擎1可以根据存储的那些值来计算其它值。
此外,交易数据数据库4可以存储涉及多个产品类别中的每一个的数据,并且在这种情况下,数据库4可以存储每个类别的“标准化”数据,仅涉及包含该产品类别的交易。为提供该产品类别的每个商家存储该数据。例如,如果某个商家仅提供单个产品类别(例如,高端旅馆房间),则数据库4可以包含被指示为与该产品类别相关联的交易数据值,而不存储与任何其它产品类别相关联的交易数据值。或者,给定商家可以销售多个产品类别中的产品(例如,作为连锁旅馆的商家可以同时提供“高端”房间和“经济舱“),并且数据库4包含每一个类别的交易数据值。这些数据是“标准化的”,即特定于给定的产品类别。
对于给定的产品类别和给定的商家,数据库可以存储以下形式的标准化数据:
表b
可选地,产品类别可以由多个标准来定义。例如,在“餐馆”这一大类中,第一个标准可以是餐馆是“高端”还是“低端”。第二个标准可以是所售食物的类型(例如意大利或印度)。一个可能的类别可以定义为“高端意大利食物”。
排名引擎进一步能够访问存储评价值的信誉数据库6,该评价值是从一个或多个商家比较组织7a、7b(典型地是网站)获得的数据中生成的,该商家比较组织7a、7b收集关于商家的顾客反馈。也就是说,他们是社交媒体来源。在图2中,示出了两个这样的商家比较组织7a、7b,但是可以有任何数量的这种组织。数据库6通常构造为使得其针对给定类型的每个商家包括描述商家对于一个或多个相应的预定标准中的每一个有多好的一个或多个评价值。通过对来自组织7a、7b的相应数据来获得这些评价值中的每一个取平均。例如,在商家是餐馆的情况下,组织7a、7b各自为每个餐馆提供评价值,该评价值指示餐馆的先前用户如何给他们的食物质量、服务质量、物有所值和氛围评分。数据库6存储四个评价值,这是由组织7a、7b提供的各个评价值的平均水平。与存储在数据库4中的客观交易数据值相比,数据库6中的评价值是主观的。
图3示出了使用图2的系统的方法。一旦用户使用计算设备2访问排名引擎1(步骤11)(例如通过互联网使用浏览器),则用户指示指示用户希望购买的产品的一组标准(步骤12)。排名引擎使用数据库3来识别提供该产品的商家(步骤13)。然后,其为每个识别的商家生成分数(步骤14),并使用分数来生成数据,该数据被发送到计算设备2以使其向用户显示识别的商家的列表(或者确切地说,一个或多个具有最高分数的识别的商家)(步骤15)。例如,识别的商家(或其中具有最高分数的商家的子集)可以根据分数(例如,从最高到最低)按顺序列出;和/或识别的商家(或者具有最高分数的商家的子集)可与显示的分数一起列出。
随后,用户可以更详细地指定期望的产品类别(步骤16)。在这种情况下,排名引擎使用数据库3来识别销售该产品类别的商家(步骤17),并且这次使用选择的产品类别的标准化值来计算它们的分数(步骤18),并显示结果(步骤19)。请注意,给定的一对商家的顺序在步骤15中呈现的排名可能与步骤19中呈现的排名不同,例如在交易数据值指示该对商家中的一个在选择的类别的产品中具有更大的专业化。
在步骤14和18根据预定义的等式来计算每个商家的分数,该等式是与该商家有关的数据库4、6中的数据的函数。具体地说,函数是与该商家相关的数据库4和6中的至少一些数据的函数(例如,和),该函数通过预先确定的权重参数加权。在步骤14中,其是数据库4中的表a的值和数据库6中的评价值的加权和。而在步骤18中,可以例如将分数计算为表b中涉及该产品类别的标准化数量和数据库6中的评价值的加权和。
例如,在餐馆的情况下,可以根据作为以下形式的函数的分数模型来计算某个产品类别的分数:
分数=0.7so+0.3ss
其中,so是一些客观交易数据值(即源自数据库4的交易水平数据变量)的加权和的函数(“客观分数”),并且其具有的总权重为0.7,而ss是来自数据库6的主观值的加权和的函数(“主观分数”),并且其具有的总权重为0.3。
在步骤14中,在用户指定产品类别之前,使用分数对商家进行排名,其中so是基于三个变量(即权重为0.33、0.33、0.33的花费、账户数量和每个账户的花费)。
在步骤18中,每个产品类别具有不同的函数so(即每个产品类别的so是由不同的各个一组权重参数定义的),并且这些权重参数针对该产品类别加权表b的相应参数的相应值。计算给定产品类别权重的方法如下。在一个具体示例中,某个产品类别的分数可以定义为:
分数=0.7x(0.04240
+0.9385*标准化花费
+0.04191*标准化txn
+0.9743*标准化账户
-0.0148*标准化花费/txn
+0.7482*标准化txn/帐户
+1.053*标准化花费/账户)
+0.3x(0.25*食品质量评价
+0.25*服务质量评价
+0.25*物有所值评价
+0.25*餐馆氛围评价)。(1)
或者,根据第二种可能的模型,分数可以计算为:
分数=0.7x(0.9300*标准化花费
+0.02549*标准化txn
+0.9876*标准化账户
+0.02316*标准化花费/txn
+0.9760*标准化txn/账户
+0.9521*标准化花费/账户)
+0.3x(0.25*食品质量评价
+0.25*服务质量评价
+0.25*物有所值评价
+0.25*餐馆氛围评价)。(2)
在实验中使用等式(2)产生的城市中餐馆的排名如图4所示。顶级餐馆(在图4中称为“餐馆eee”)没有在图1中示出的任何排名中,可能是因为没有收到足够的评论,而另外四个餐馆也没有,该4个餐馆称为“餐馆fff”至“餐馆iii”。
对于给定的产品类别,生成分数模型(例如等式(1)或等式(2))的过程如图5所示。注意,该方法可以针对特定的一类商家(例如在一个地理区域中提供产品类别中的一个的商家)执行,并且然后使用相同的数值对其它类似的类别的商家的分数。例如可以对在纽约的意大利食物餐馆执行,并且然后使用相同的参数对其它类型的食物和/或其它地理位置的食物餐馆进行分类。
在步骤21中,基于三个变量(即权重为0.33、0.33、0.33的花费、账户数量和每个账户的花费)计算一定数量的顶级商家(该组被称为“待审商家”;在该实施例的变体中待审商家不需要是顶级商家)的初始排名。这些是表a的三个参数。因此,每个顶级商家都得到初步分数。这是每个顶级商家的初步分数。初步分数作为计算客观交易水平数据/变量具有的权重的基础。
在步骤22中,计算针对每个商家(不仅仅是待审商家)的表a和表b中指定的所有变量,并且针对每个产品类别计算针对客观分数so的相应的一组权重。对于给定的产品类别的so作为该产品类别的表b中所示的多个参数的函数进行计算。计算表b中每个参数的各个加权参数,使得顶级商家的加权和so尽可能接近于上面计算的初步分数(其如所解释的那样是使用表a的三个参数计算的)。该计算是通过迭代线性回归过程来完成的,称为回归模型开发。
在步骤23中,为多个变量中的每一个收集来自社交媒体网站7a、7b的主观信息,对于每个变量,从收集的信息导出数字评价值,将评价值组合成单个主观分数(“ss“)并且存储在信誉数据库6中。例如,在餐馆的情况下,所有社交媒体网站针对每个商家对于服务质量、物有所值、氛围和食物质量四个变量中的每一个给出分数。对于这些变量中的每一个,可以通过组合社交媒体网站上的相应值来计算相应的评价值。这些评价值的组合给出了主观分数ss。例如,等式(1)和(2)中的这些评价值中的每一个都赋予相同的权重,即每个被赋予0.25的相对权重。
注意,在不同的实施例中,等式(1)和(2)中的每个评价值的相对权重可以被赋予不同的值(例如,如果证明(例如通过食客调查)对食客而言金钱和/或食品质量比服务或氛围更重要,则其相应的相对权重可以更高。评价值也不必须是线性地组合以形成主观分数(即作为加权和);例如,如果发现食品质量非常低,则主观分数ss可以被限制在较低的值,而不管其它分数多高。
进一步,来自不同社交媒体网站的数据值可以在不同的范围。例如,一个社交媒体网站可以对于某个变量具有一个范围,其是1到10的整数范围,而另一个社交媒体网站可以将变量评价为1到5范围内的整数(即从1到5星),而第三个社交媒体网站可以例如使用学校成绩a...f。因此,纯粹的数字平均值可能会生成误导。相反,更一般地,对于每个变量,来自社交媒体网站的各个数据值被适当地组合,例如通过将每个数据转换为公共比例,并且然后生成评价值作为转换的分数的数值组合(例如,加权平均值或其它平均值,例如中位数)。
在步骤24中,等式(1)和(2)是以客观交易数据值(即从数据库4导出的交易水平数据变量)的权重的被赋予总体权重0.7客观分数so而创建的,而来自主观信息(即,来自数据库6的评价值)主观分数被赋予的整体权重为0.3。再一次地,在另一个实施例中,so和ss的相对加权可以是不同的。结合交易数据值和加权的主观信息给出最终的模型方程,例如,等式(1)和(2)。注意,回归模型开发过程是迭代的,并且依赖于使用哪些变量的细节,所以过程的不同实现将生成不同的系数(例如,对于不同的产品类别,或者如果存在不同数量的迭代步骤和/或者如果使用的客观交易数据值与表a和b中的不同,或者如果变量以某种方式转换)。
实施例具有几个优点。首先,其不依赖于任何描述用户(潜在顾客)的数据。因此,其可以被关于其选择商家的个人标准给出非常少的信息的顾客使用,和/或被没有可用的支付卡交易数据的顾客使用。其次,其对来自社交媒体网站的主观数据中的任何问题(例如假评论)都相对不敏感。该实施例可以由参与支付交易的银行或其它方方便地实现,并且因此访问用于创建数据库4的交易数据。
虽然仅详细描述了本发明的单个实施例,但是许多变化是可能的。例如,可以将附加信息并入分数的计算中,例如描述商家资产负债表的任何可用数据。
如上所述,排名引擎1可以实现为通过互联网与独立的计算设备2通信的一个或多个服务器。在这种情况下,排名引擎包括用于从计算设备2接收指示商家必须符合的标准并且指示用户想要购买的产品的数据以及用于向计算设备2发送数据的接口,例如以表示如何生成显示的数据的形式,其表示被识别为符合标准的商家,以根据排名的形式。然而,排名引擎可以可选地包括在计算设备2上存储和运行的应用的组件。事实上,在某些实施例中,排名引擎可以完全实现为这样的应用。进一步,尽管数据库3、4、6被示出为分离的,但是它们中的任何一个或多个可以是单个较大数据库的一部分。
- 还没有人留言评论。精彩留言会获得点赞!