用于指令存储器效率的设备和处理架构的制作方法
相关申请的交叉引用
本专利申请要求获得于2015年8月26日提交的题为“用于指令存储器效率的设备和处理架构”的申请号为62/210,254的美国专利申请的优先权,其通过引用并入本文,如同全文再现。本专利申请还要求获得于2016年3月11日提交的题为“用于指令存储器效率的设备和处理架构”的申请号为15/068,058的美国专利申请的优先权,其通过引用并入本文,如同全文再现。
本改进一般涉及处理器和存储器的领域。
背景技术:
处理器从指令存储器接收指令。当下一个指令不能在随后的时钟周期中执行时,处理器架构中的指令流水线可能存在问题或危险(hazard)。存在这样的技术,即通过例如将无操作指令(nop)插入到指令代码中来解决或避免执行流水线中的危险和依赖性。nop是不执行任何操作的指令,并且nop的插入可以使用指令存储器资源。
技术实现要素:
在一个方面,本文所描述的实施例提供了一种处理器,其具有指令存储器,用于在相应的指令存储器地址处存储指令,每个指令是引用操作数和操作码的数据结构。所述处理器具有指令存储控制器,用于控制对所述指令存储器的访问。所述处理器具有评估单元,用于触发所述指令存储控制器从所述指令存储器接收指令数据,为所述指令数据的操作码和操作数评估操作数依赖性和执行依赖性。所述处理器确定所述指令数据的所述操作码的源数据的源寄存器标识符和由执行所述指令数据而生成的指令结果的目的地寄存器标识符,并评估对所述指令数据的执行的资源要求。当资源要求不可用时,评估单元可以让指令数据等待。所述处理器具有执行单元,用于当所述操作数的源数据准备就绪或可用且所述资源要求指定的所述资源准备就绪或可用时,将所述指令数据分派给计算资源以执行。所述处理器具有终止单元,用于在推测被解决时终止所述指令的执行并触发所述指令结果从临时寄存器到所述目的地寄存器的传送。所述处理器具有寄存器和数据存储器,用于加载所述操作数执行所述指令数据所需的所述源数据并接收由所述指令数据的执行而生成的所述指令结果。所述处理器具有数据存储控制器,用于基于所述指令数据的所述操作码和所述指令结果来控制对于所述源数据的所述数据存储器的访问和对所述数据存储器的读取和写入。
根据一些实施例,所述处理器解决所述输入操作数依赖性和所述执行单元依赖性,而不需要在所述指令存储器中放置nop。
根据一些实施例,所述处理器具有程序计数器单元,用于生成具有至少一个指令存储器地址的读取请求,以请求读取存储在所述指令存储器中的所述至少一个指令存储器地址处的指令数据,所述程序计数器向所述评估单元提供所述读取请求以接收所述指令数据。
根据一些实施例,所述处理器具有指令fifo,用于存储响应于所述读取请求而从所述指令存储器接收的所述指令数据,所述指令数据由所述评估单元保存以用于分派。
根据一些实施例,所述处理器具有指令fifo,其一次接收多个指令作为所述指令数据并验证所述指令数据。
根据一些实施例,所述评估单元具有分配单元,用于指示其准备就绪以接受指令数据,以为所述指令数据的操作码和操作数评估操作数依赖性和执行依赖性,以及分配指令标签以为所述指令数据提供引用标识符。
根据一些实施例,所述分配单元用于将所述指令数据划分成束或组,以用于并行执行所述束或组。
根据一些实施例,所述分配单元可以通过不从指令fifo释放所述指令数据来使所述指令数据等候。
根据一些实施例,所述分配单元对所述指令数据进行解码,以检测无效指令数据,并为所述指令数据触发异常。
根据一些实施例,所述分配单元解码所述指令数据以生成用于所述指令数据的所述操作数和所述操作码的所需资源的指令简档,所述所需资源是所述指令数据的所述操作数和所述操作码的源输入操作数依赖性和所述执行依赖性的一部分。
根据一些实施例,所述分配单元识别所述指令数据的指令类型和计算资源类型,作为对所述指令数据的所述操作数和所述操作码的所述源输入操作数依赖性和所述执行依赖性的评估的一部分。
根据一些实施例,所述评估单元具有记分板单元,用于跟踪所述指令数据的所述操作码的资源和操作数可用性,将所述资源和操作数可用性与用于执行所述指令数据的资源要求的所述输入操作数依赖性和所述执行依赖性进行比较以生成资源可用信号,以及使用所述指令标签跟踪关于当前运行中指令的信息。
根据一些实施例,所述记分板单元用于使用所述指令标签跟踪所述指令数据的状态,保存所述指令标签以等待所述指令数据的完成,并且在检测到所述指令数据的完成时,释放所述指令标签。
根据一些实施例,所述分配单元为所述操作数向所述记分板单元提供标识符,作为对所述指令数据的所述操作数和所述操作码的所述源输入操作数依赖性和所述执行依赖性的评估的一部分。
根据一些实施例,所述执行单元包括分派器,用于基于来自所述记分板单元的资源可用信号来分派所述指令数据作为用于所述计算资源的至少一个队列的条目,以执行所述指令数据的所述操作数和操作码以生成指令结果,当所述指令数据从所述队列分派到所述计算资源时,所述队列前进到下一条目(如有)。
根据一些实施例,所述分派器用于所述指令数据的推测性执行,使得所述指令结果可以在完全解决之前被算出及可用。
根据一些实施例,单个指令与对应的指令标签相关联,所述指令标签用于在所述单个指令的整个生命周期中跟踪所述单个指令的状态,并且维护所述单个指令相对于所述指令数据的其他指令的顺序。
根据一些实施例,所述寄存器还包括多个临时寄存器和提交寄存器,以及提交控制器,所述提交控制器用于通过将与所述指令结果有关的数据从所述临时寄存器传送到所述提交寄存器来触发所述指令的执行的终止或完成,以及向所述评估单元提供状态通知以退回所述指令标签。
根据一些实施例,所述记分板单元使用所述指令标签和运行表来跟踪关于当前运行中指令的信息,所述指令标签对应于所述运行表的索引。
根据一些实施例,所述数据存储器包括本地数据存储器和共享数据存储器,所述处理器通过访问端口连接到所述共享数据存储器。
根据一些实施例,所述评估单元用于使具有执行依赖性或不可用资源要求的指令数据等候。
在另一方面,实施例为处理器提供指令存储控制器,用于控制对指令存储器的访问,所述指令存储器用于在相应的指令存储器地址处存储指令,每个指令是引用操作数和操作码的数据结构。
在另一方面,实施例提供评估单元,用于触发所述指令存储控制器从所述指令存储器接收指令数据,为所述指令数据的操作码和操作数评估操作数依赖性和执行依赖性,确定所述指令数据的所述操作码的源数据的源寄存器标识符和由执行所述指令数据而生成的指令结果的目的地寄存器标识符,并评估对所述指令数据的执行的资源要求。
在另一方面,实施例提供执行单元,用于当所述操作数的源数据准备就绪或可用且由所述资源要求指定的所有资源准备就绪或可用时,将所述指令数据分派给计算资源以执行。
在另一方面,实施例提供终止单元,用于在推测被解决时终止所述指令数据的所述执行并触发所述指令结果从临时寄存器到所述目的地寄存器的传送。
在另一方面,实施例提供数据存储器,用于加载所述操作数执行所述指令数据所需的所述源数据并接收由所述指令数据的所述执行而生成的所述指令结果;所述数据存储器包括本地数据存储器和共享数据存储器,所述处理器通过访问端口连接到所述共享数据存储器。
在另一方面,实施例提供所述评估单元用于让具有执行依赖性或不可用资源要求的指令数据等候。
在另一方面,本文描述的实施例提供一种用于处理器的方法,其涉及以下步骤:为指令数据的读取请求生成至少一个指令存储器地址,所述指令数据存储于指令存储器中至少一个指令存储器地址处,所述指令数据是引用操作数和操作码的数据结构;存储响应于所述读取请求从所述指令存储器接收的所述指令数据,所述指令数据被保存以用于分派;对所述指令数据的所述操作数和所述操作码进行解码,以评估所述指令数据的所述操作数和所述操作码的源输入操作数依赖性和执行依赖性;分配指令标签以为所述指令数据提供引用标识符;跟踪所述指令数据的操作码的资源和数据可用性,将所述资源和数据可用性与所述输入操作数依赖性和所述执行依赖性进行比较,以生成资源可用信号;使用所述指令标签跟踪关于当前运行中指令的信息;响应于所述资源可用信号,输入所述指令数据作为用于计算资源的至少一个队列的条目,以执行所述指令数据从而生成指令结果,当所述指令数据从所述队列分派到所述计算资源时,所述队列前进到下一条目(如有);并基于所述指令数据的所述操作码和所述指令结果来对数据存储器进行读取和写入。
在一些实施例中,该方法可以包括识别输入操作数的源寄存器标识符和所述指令结果的目的地寄存器标识符。
在一些实施例中,该方法可以包括识别所述操作码的不同类型的操作,以识别用于执行所述指令数据的所需资源,以作为所述输入操作数依赖性和所述执行依赖性的一部分,所述不同类型的操作包括整数、向量、分支、跳转、系统、加载或存储操作。
在另一方面,本文描述的实施例提供一种处理器,包括:评估单元,用于接收指令数据、确定所述指令数据的执行依赖性、确定用于所述执行所述指令数据的资源要求和让有执行依赖性或不可用资源要求的所述指令数据等候,以及当没有所述执行依赖性或不可用资源要求时,释放所述指令数据。所述处理器可以具有执行单元,用于在释放所述指令数据时将所述指令数据分派给计算资源以用于执行。
所述处理器可以具有终止单元,用于在推测被解决时终止所述指令的执行并触发所述指令结果从临时寄存器到所述目的地寄存器的传送。
附图说明
在图中,
图1是根据一些实施例的示例性处理器的视图;
图2是根据一些实施例的另一示例性处理器的视图;
图3是根据一些实施例的示例性过程的流程图;
图4是根据一些实施例的示例性分配单元和记分板单元的视图;
图5是根据一些实施例的示例性记分板单元的视图;
图6是根据一些实施例的示例性数据流的流程图;
图7a和7b是根据一些实施例的示例性处理器的视图;
图8是根据一些实施例的另一示例性处理器的视图;
图9是根据一些实施例的示例性指令分派器和解码器的视图;
图10和11是根据一些实施例的寄存器文件索引的视图;
图12是根据一些实施例的用于寄存器文件的示例过程的流程图;
图13是根据一些实施例的示例性计算资源分派的视图;
图14是根据一些实施例的示例性加载存储单元的视图;
图15是根据一些实施例的示例性指令流的流程图;
图16是根据一些实施例的示例性窗口的视图;
图17是根据一些实施例的示例性处理器的视图;
图18是根据一些实施例的示例性指令存储控制器的视图;
图19是根据一些实施例的示例性评估和终止单元的视图;
图20是根据一些实施例的示例性指令接收和解码单元的视图;
图21是根据一些实施例的指令类型的示例性资源表的视图;
图22是根据一些实施例的另一个示例性评估和终止单元的视图;
图23是根据一些实施例的示例性整数寄存器分配表的视图;
图24是根据一些实施例的示例性整数资源表的视图;
图25是根据一些实施例的示例性临时寄存器的视图;
图26是根据一些实施例的示例性寄存器提交控制器的视图;
图27是根据一些实施例的示例性整数寄存器端口表的视图;
图28是根据一些实施例的示例性整数寄存器端口表的视图;
图29是根据一些实施例的另一个示例性整数寄存器端口表的视图;
图30是根据一些实施例的另一示例性可观察信号表的视图;和
图31是根据一些实施例的示例性执行单元的视图。
具体实施方式
本文描述的实施例涉及可以解决或避免执行流水线中的危险或指令依赖性的处理器架构。实施例可以去除例如将nop插入指令存储器以解决危险的需要。处理器架构了解并跟踪由指令序列所要求的依赖性。处理器架构让要求前置指令的输出的指令等候或加入队列,直到该前置指令完成。这可以解决或避免执行流水线中的危险或指令依赖性。这可以移除对指令存储器中的nop的需要,并且可以提供代码密度的优点,因为nop可以从指令存储器中消除。例如,从指令存储器中移除nop增加了给定大小的存储器中的有用指令的数量。这可以允许减少给定程序所用的存储器大小。该处理器架构可以允许使用更小、更经济的存储器或存储更大的程序。这可以提供成本节省并且提升存储器资源效率。这也可以简化编译器开发,因为不再需要编译器知道执行流水线中的指令危险。该处理器架构还可以提供性能效益。该处理器架构还可以为指令束(bundle)或指令部分提供并行处理,并提供推测性执行(speculativeexecution)。此外,通过让指令等候,系统可潜在地减少设计中的门或净开关(nettransition)的数量,这可以降低功耗。
传统处理器可以在多级流水线中实现。取决于指令的复杂性,每个指令在1到n个周期内执行。例如,诸如乘法的数学运算可能需要多个周期。如果新指令使用前置指令的输出作为输入,则新指令必须等候前置指令的完成。这可以被称为“流水线危险(pipelinehazard)”。流水线危险可以使用各种技术解决。例如,可以由编译器通过插入nop指令来允许危险被解决,从而解决流水线危险。本文描述的实施例提供了一种处理器架构,在所有输入准备就绪之前,不会将指令分派到执行流水线中,这可以解决流水线危险。通过让指令等候,处理器架构例如能够从指令存储器中移除nop。此外,处理器架构的实现允许与推测性执行相结合的并行执行流水线,以在让指令等候并等待来自其他指令的输入时提高总体性能。
以下示例性术语可以用于描述各种处理器架构。
指令束(其可被称为四元组(quad-pack))可以指从指令存储器接收的、在指令fifo中加入队列、并由分配单元解码的一组标量和/或向量指令(例如,4×32位指令)。
指令标签(其可以被称为记分板(也称sb)索引)可以是分配给每个指令的唯一标签。当按指令离开分配单元的顺序分配指令标签。当比较两个指令标签时,具有最小指令标签的指令是最早的指令,并且可以在较新的指令(具有较大指令标签)之前被提交。
输入操作数可以指源数据或源值,包括例如由指令用作输入的32位或128位值。
源寄存器可以是在提交标量寄存器(csreg)和提交向量寄存器(cvreg)(其可以统称为creg)中可用的n个标量寄存器或m个向量寄存器中的一个,其包含操作数值用作对指令的输入。
指令结果可以是标量算术逻辑单元(salu)或向量计算资源(vcr)计算的结果值。例如,指令结果可以是32位或128位值。salu处理标量指令。vcr可以指向量乘法累积单元(vmac)、向量算术逻辑单元(valu)、向量查找表单元(vlut)等。
目的地寄存器可以是creg中的y标量寄存器或z向量寄存器之一。其由指令使用以存储其结果。跳转和存储(st)指令不更新目的地寄存器。
运行中指令可以指离开评估单元或其组件,诸如分配单元(例如,图2的分配单元208)时的指令,直到其指令标签被评估单元或其组件,例如记分板单元,释放。
指令依赖性可以指具有对运行中指令的依赖性的指令,其使用那个指令的结果作为其输入操作数之一。当所有依赖性输入操作数值都可用时,指令执行开始。
被分配的指令可以指离开评估单元的指令。
被分派的指令可以指在被分配之后立即被分派到salu切片(slice)的标量指令。向量指令可以在它们在vcr队列中并被传送到vcr时被分派。
被启动的指令可以指所有输入操作数已被vcr或salu接收并且可以开始执行的指令。直到被启动之前,处于vcr或salu的输入阶段的指令仍然可以认为是被分派的。
被提交的指令可以指结果已写入提交的标量或向量寄存器中的指令。可以按顺序执行提交的指令结果。当写访问被发送到dmem时,则st指令已被提交。跳转指令在结果被确认时被提交。
已完成的指令可以指代不具有更多与指令本身相关的要执行的动作的指令。当写访问发送到dmem时,则st指令已完成。当条件被评估时,则跳转指令已完成。对于已完成的和预测不正确的分支,后果可能就是指令流水线冲洗(flush)和程序计数器重新同步。对于其他指令,当指令结果写入csvr中时,即可以是已完成。
冲洗指令可以指预测不正确的分支指令,其导致指令流水线冲洗。
推测性指令可以指在尚未被求解的分支(或跳转)指令之后分配的任何指令。推测性指令可以由于程序中的某些条件(例如,由不可预测的跳转引起的冲洗)而被清除。
异常指令可以指生成异常的任何指令。存在多个异常源,包括例如非法指令操作码、超范围的dmem加载指令(ld)或st地址、存储器纠错码(ecc)错误等。
异常后动作取决于异常的严重性。示例动作可以是激活中断、捕获跟踪数据、跳转到异常处理程序例程等等。
计算资源(cr)队列可以指离开评估单元或其组件,诸如分配单元,并在被分派之前被加入队列的指令。
标量alu(salu)切片可以指例如能够并行处理4个标量指令的一组4个salu单元。每个salu切片共享一个标量乘法单元。
本文中可以描述其他示例性术语和组件以指代各种处理器架构及其组件。
示例性处理器
图1示出了用于数字信号处理器(dsp)、中央处理单元(cpu)等的示例性处理器100架构。处理器100具有实现评估单元、执行单元和终止单元的多个硬件组件。例如,处理器100可以包括imem102、程序计数器104和具有指令fifo106的指令流水线105、分配单元208和记分板单元210、分派器117、具有跳转单元120的分支单元121、数据存储控制器126和dmem128。处理器100还具有标量提交寄存器130、标量计算资源131、向量提交寄存器134和(具有向量临时寄存器136的)向量计算资源133。作为评估单元的一部分,分配单元108可以与记分板单元110一起实现指令评估阶段,因为其可以评估指令以识别瓶颈和依赖性。分配单元108可以例如通过不从指令fifo106释放指令来让指令等候。
imem102在相应的指令存储器地址处存储指令。程序计数器104生成至少一个指令存储器地址,用于针对存储在imem102中该至少一个指令存储器地址处的指令数据的读取请求。指令数据是引用操作数(数据)和操作码的数据结构。操作码可以是指令中指定要执行的操作的部分。指令还以操作数的形式指定操作码将要处理的数据。操作码的规格和格式在处理器100的指令集架构(isa)中进行安排,该处理器100可以是dsp、cpu或其他专用处理单元。指令还具有操作所用操作数的一个或多个指示符(即数据)。一些操作可能有隐式操作数,或者根本没有。操作数可以是寄存器值、堆栈中的值、其他存储器值、i/o端口等等,使用地址、标签或其他标识符来指定和访问。操作的类型包括算术、数据复制、逻辑操作、程序控制、特殊指令等。
ififo106响应于读取请求,存储从指令存储器接收的指令数据,其中让指令数据等候分派。
处理器100的评估单元可以评估指令,包括指令数据的操作数和操作码的执行依赖性(例如,对挂起指令结果的要求),并评估用于指令数据的执行的资源要求。评估单元可以包括分配单元108。分配单元108用于向ififo106指示其已准备就绪,可以接受指令数据来评估指令数据的操作数和操作码的源输入操作数依赖性和执行依赖性。分配单元108分配指令标签,以向指令数据提供引用标识符。指令数据可以指从imem102接收的所有指令(例如,一个或多个指令)。可以从imem102连续接收指令数据,使得指令数据的内容可以随接收或获取新指令而连续改变或更新。评估单元用于接收指令数据、确定指令数据的执行依赖性、以及确定用于指令数据的执行的资源要求。评估单元还用于让具有执行依赖性或不可用资源要求的指令数据等候,并且当不存在所述执行依赖性或不可用资源要求时释放该指令数据。用于执行指令数据的资源要求可以是可用的或不可用的。评估单元可以让指令数据等候不可用的资源要求。评估单元不会让具有可用资源要求的指令数据等候。
记分板单元110用于跟踪指令数据的操作码的资源和数据可用性。记分板单元110用于将资源和数据可用性与输入操作数依赖性和执行依赖性进行比较,以使用资源可用信号来触发分派。记分板单元110用于使用指令标签来跟踪关于当前运行中指令的信息。评估单元还可以包括记分板单元110。
处理器100包括执行单元,该单元当操作数的源数据就绪并且由资源要求指定的所有资源准备就绪时,将指令数据分派给计算资源以进行执行。所述执行单元用于在释放所述指令数据时将所述指令数据分派给计算资源以进行执行。执行单元可以包括分派器117。分派器117基于来自记分板单元110的资源可用信号来分派指令数据,使之成为计算资源(标量cr131、向量cr133)的至少一个队列(标量crq129、向量crq145)的条目,以执行该指令数据,从而生成指令结果。当指令数据从队列被分派到cr(标量cr131、向量cr133)时,则队列(标量crq129、向量crq145)前进到下一条目(如果可用)。标量cr131与标量提交寄存器130交互,并且向量cr133与向量提交寄存器134交互,以读取和写入与指令执行有关的数据。csreg130和cvreg134指的是提交寄存器,因为除了临时寄存器之外,指令还可能需要来自提交寄存器文件的数据。
处理器100包括终止单元,用于在推测被解决时终止所述指令数据的执行,并触发所述指令结果从临时寄存器到目的地寄存器的传送。如本文将描述的,终止阶段涉及将数据写入提交寄存器。标量cr队列129和向量cr队列145可以用于在实际执行单元(例如,操作码、运行中指令、指向输入的指针)前将指令加入队列。指令将被排入队列,且被排入时,位于队列的头部,恰等待执行。当所有需要的输入都在提交寄存器或临时寄存器中时,则将指令推入执行阶段。
dmem控制器(dmc)126用于基于指令数据的操作码从dmem128读取和写入dmem128。dmem控制器126可以包括dmctsr144和dmctvr146作为来自dmem128的数据的分布式临时寄存器块。一旦数据在临时寄存器中,则存在将数据写入提交寄存器的过程。这可以仅用于来自dmem128的数据,这不同于cr临时寄存器,因为后者可以包括从另一指令得到的数据(例如乘法的结果)。在一些情况下,还可以根据时机,将dmctsr144加载到cvr134中。dmem128可以包括处理器100可经由接入端口访问的本地dmem和共享dmem。
ldst队列142可以将来自分派器117的存储或加载指令加入队列。ldst140可以进行地址计算以从存储器(dmem128)拉取。ldst缓冲区127可缓冲存储或加载指令。通过将数据从临时寄存器转入提交寄存器(同时考虑异常),指令的执行得到分配,且可(来自临时寄存器的)终止阶段得到触发。
指令流水线105可以实现指令的评估阶段的功能(例如,评估单元的功能性)。分支单元121可以与评估阶段并行地运行,因为分支指令可以是一种影响pc104值的指令。
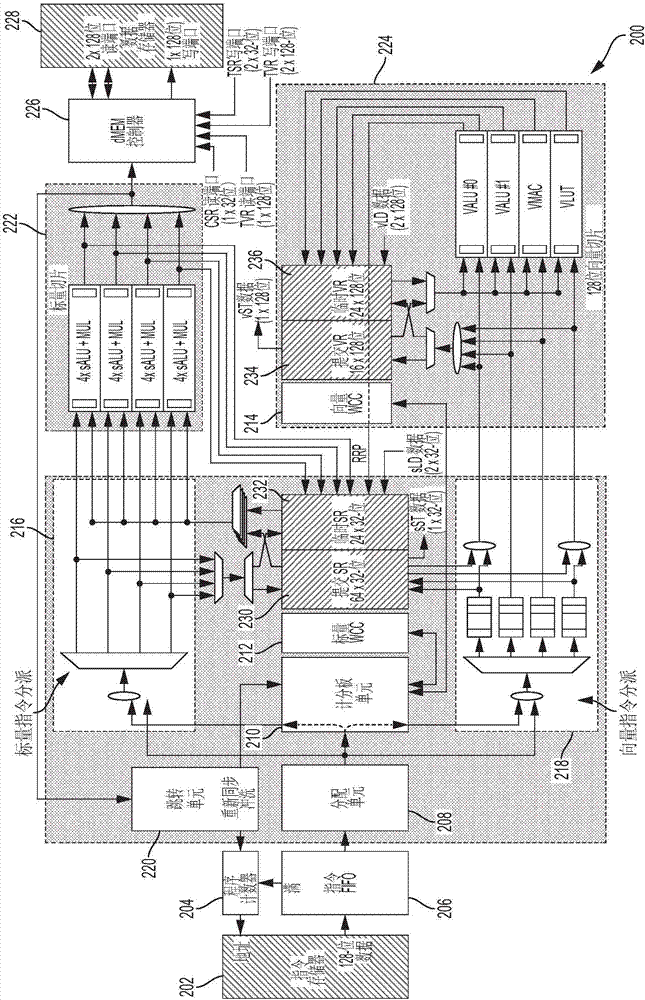
图2示出了用于dsp、cpu等的另一示例处理器200架构。处理器200具有实现评估单元、执行单元和终止单元的多个硬件组件。例如,处理器200具有imem202、程序计数器204、指令fifo206、分配单元208、包括记分板单元210和写提交控制器(标量wcc212、向量wcc214)的控制器组件、标量指令分派器216、向量指令分派器218、跳转或分支单元220、标量切片单元222、向量切片单元224,数据存储控制器226和数据存储器(dmem)228。分配单元208可以被称为指令评估器,因为它可以评估指令以识别瓶颈和依赖性。例如,分配单元208可以通过不从指令fifo206释放指令来让指令等候。处理器200可以类似于处理器100和本文描述的其他示例性处理器(例如参见图7、8、17和18)。根据一些实施例,在图1和图2中示出了类似的处理器组件1和2。以下说明性示例描述参考了图2,但是也可以适用于图1的组件以及本文所描述的其他示例处理器的其他组件。附图可以包括对示例位宽度的引用以作为说明性示例实现。这些是说明性的,并且在不同的实施例中可以使用其他变化和修改。
程序计数器和指令存储器
如图2所示,程序计数器204从指令存储器(imem)202取出或接收指令数据。指令数据是保存指令的数据结构。作为说明性示例,指令数据可以是128位指令数据,其作为四个指令的束或四元组指令。例如指令数据可以指从imem202取出的所有指令,例如但不限于一个四元组或128位指令数据。
为了不使标量和向量cr“忍饥挨饿”,程序计数器204负责保持指令fifo206尽可能充满指令数据。调整当前fifo水平以考虑发送到imem202的挂起读取请求的数量,当最终接收到指令数据时,该请求将消耗fifo空间。当调整的fifo水平满时,程序计数器204停止从imem202请求新数据(以避免溢出),并且当新指令数据可被指令fifo206接受时,程序计数器204重新开始。
与每个指令相关联的imem地址也被发送到记分板单元210。该地址用于从异常或错误预测的分支指令中恢复回来。当发生指令流水线冲洗时,程序计数器204将接收新的imem地址。程序计数器204将使用该值来从imem202检索新的指令。
指令fifo
从imem202接收的指令数据存储在指令fifo206中。一旦指令fifo206非空,并且下一阶段的分配单元208准备就绪,可以接受新的指令束,则提取fifo头条目并推入分配单元208。
作为说明性示例,指令fifo206大小可以是8乘128位条目。假设imem读取有3到4纳秒的数据延迟时间,而四元指令流水线以1ghz的最小目标速率运行(每1纳秒至少一次),则指令fifo206可吸收由突发存储器读请求生成的imem202数据而不用过多地停止数据提取过程。
如果fifo的大小太小(假设为4乘128位作为说明性示例),则处理器性能可能受到负面影响。为了避免fifo溢出,程序计数器204可以每4个读取请求就停止一次。利用3到4纳秒的imem202读访问时间,程序计数器204可以在从imem202接收第一读数据之前停止。只有当从指令fifo206提取第一数据并向下游传送时,程序计数器204才恢复其读请求过程。则在从imem202接收新数据之前,指令fifo206可能就会耗空。具有更深的指令fifo206即可将更新fifo水平(以及因此而来的程序计数器204停止/恢复读请求)的延迟时间列入预算,并且有助于防止缺乏指令发送到分配单元208的情况。
当发生冲洗时(例如,通过跳转单元220),可以清除指令fifo206中的所有指令。随着从新程序计数器204检索到值,即可从imem202接收新指令。
分配单元
当空闲时,分配单元208向指令fifo206指示其准备好接受新的指令束。一旦从指令fifo206接收到新数据,分配单元208就变忙碌。当四元组中的所有指令被传送到标量或向量域时,分配单元208清除其忙状态并变为空闲。
在下一个时钟更新之前可能有一个最小周期。例如,在指令fifo206的输出阶段,脉冲发生器可以在其下一个时钟更新发生之前具有最小周期。类似地,分配单元208输出阶段脉冲发生器可以在声明自已准备好接受新的指令束之前等待来自记分板单元210的资源可用性状态更新。
作为说明性示例,128位指令束可以被分解成4个单独的32位指令。例如,这可以是标量和/或向量指令的混合。在128位指令数据中,首先分析指令槽#0(位31:0),然后是槽#1、#2和#3(分别是位63:32、95:64、127:96)。
分配单元208可以解码每个指令,并检测无效指令格式和操作码并触发异常。
分配单元208可以识别指令类型(例如标量、向量)和cr类型(salu、vmac、valu、vlut)。分配单元208可检测指令束内的无效指令混合。作为说明性示例,对每个指令束可以有1个vmac、2个value、1个samuel、1个vlut等等。例如,同一个束中多于1个vmac或1个标量mul指令可能会触发异常。
分配单元208可以确定所有指令的源输入操作数。输入操作数可以包括即时值。根据指令格式,可以使用整个指令数据(例如32位)将即时值进位输出(carryout)到cr。分配单元208可以向记分板单元210提供指令输入源寄存器标识符以检测束中的指令之间的依赖性。
分配单元208可以基于指令操作码来请求所需的资源来处理所有4个指令。对于ld/st/跳转指令,分配单元208可以请求额外的专用资源。
分配单元208可以监视记分板单元210的资源可用性。记分板单元210可以向分配单元208提供资源状态。
分配单元208可以根据指令要求,将指令传送到它们的目的地。例如,标量指令可以被发送到标量分派单元216。向量指令可以被写入4个vcr队列之一。
分配单元208可通过清除由向量指令占用的束槽中的指令有效位来保留标量指令组。例如,接收无效指令的切片内的salu可以保持空闲。
每当向下游传送分配单元208指令数据的条件,脉冲发生器按需生成时钟脉冲。在满足所有条件之前,数据被保存在分配单元208,并且指令流水线停止(stall)。
当离开分配单元208时,唯一标签(例如,指令标签,7位)跟踪每条指令的生命周期,并且与运行表的大小相关。该标签由记分板单元210提供,表示记分板单元210中的运行表的64个条目。当指令完成时或由于清除而被清除时,标签被回收。
只有当所需的资源可用时,指令才被传送到标量或向量域。所需资源取决于在分配配单元208处当前被解码的指令简档。发出指令的示例性条件是:(i)运行指令表(ift)中至少有多个(例如4个)可用标签;(ii)对于当前四元组(的ld/st/跳转指令),有足够的ld/st/跳转缓冲区条目可用;(iii)有足够的可用于当前四元组的标量或向量临时寄存器;(iv)(对标量指令和vld/vst指令)有至少1个可用的salu切片;(v)在(每种向量指令的)vcr队列中有足够的可用条目。这些仅是用于该说明性实施例的示例性条件。
标量指令分派
标量指令由分配单元208提供给标量指令分派器216。当指令离开分配单元208时,标量指令处于标量指令分派阶段。进入该阶段的标量指令被路由到标量切片单元222的第一可用salu切片。由于当指令被分配时对记分板单元210ift进行更新,所以标量指令分派216寄存标量指令,然后将数据转发到salu切片中的一个。如果当前分派切片忙而另一切片可用,则标量指令分派216可以跳过当前切片并访问下一个可用的切片。
当分配单元208将标量指令发送到salu切片时,还会将标量指令的标签推入记分板单元210中。记分板单元210使用指令标签来定位输入操作数,并将读取请求发送到寄存器单元(例如,提交标量寄存器230、临时标量寄存器232、提交向量寄存器234、临时向量寄存器236)。当输入操作数取决于运行指令时,则临时标量寄存器232和临时向量寄存器236被访问。否则,读取提交标量寄存器230。当访问提交svr时,读取的数据已经可用,并可以立即返回给salu切片。当从临时标量寄存器232和临时向量寄存器236读取时,该请求可以被挂起,直到目标数据变得可用。从寄存器读取的数据被定向到salu切片。
并行地,4个指令操作码、标签和有效信号可以从分配单元208路由到被选择的标量切片器222的salu切片。输入操作数值将直接从寄存器接收。注意,当未设置有效位时,可以忽略操作码和标签。
标量alu切片
对于本说明性示例,总共4个salu切片可以是可用的。每个salu切片可以独立地处理指令。如果分配单元在指令束内解码出至少一个标量指令,则可以消耗整个salu切片。在分配单元208中,携带向量指令的槽可以被标记为无效并且被其salu忽略。
salu是非流水线cr。当对于位于salu输入端的给定指令,接收到所有输入操作数时,指令执行才开始。基于指令类型,salu执行时间可以是可变的、静态的或固定的。一旦计算完成,结果(和相关联的标签)可以寄存并转发到临时标量寄存器232(tsr)。对于说明性示例,该结果可以是32位。
切片可以向分配单元208提供就绪状态。当至少一个salu正在处理指令时,切片为忙碌(未就绪)。当所有salu已将其指令结果传送到临时标量寄存器232和临时向量寄存器236、dmem控制器226或跳转单元220时,切片变为就绪。如果各切片无一就绪,则在分配单元208处停止指令流水线。一旦有切片变得可用,指令流可以重新开始。
向量指令分派单元
向量指令分派器218可以包括向量cr队列。vcr队列的三种示例类型是:valu、vmac和vlut。当离开分配单元208时,向量指令操作码和标签可被缓冲到三个队列中的一个。作为说明性示例,valu队列可以接受每个四元组最多两个指令,vmac和vlut也类同。valu、vmac和vlut队列的深度可以是例如8个条目。
队列深度是可用临时向量寄存器的数目(例如24)和在停止指令流水线之前的运行中指令的最大数目的函数。每个队列确保按顺序处理相同类型的指令。如果头队列条目不能被分派到其向量cr(或用于valu的cr对),则该队列中的后续指令被停止。最终,如果队列被填满,则整个指令流水线停止。一旦cr准备就绪,队列头条目将被分派。
向量指令分派器218可包括指令分配器。向量指令分配器可以划分为三个独立的进程,每个进程处理vcr队列和相同类型的关联cr。对于valu,读取单个条目,而分派器在cr示例之间交替。
每个进程监视vcr队列指令的可用状态和vcr目的地就绪状态。当两个条件都满足时,就从队列中读取指令操作码和标签,并将其传送到选择的vcr。还将标签转发到sbm以生成寄存器读取请求。
对于value队列,单个读取进程管理两个cr。分派指令时的最长时序路径是记分板单元210使用指令标签查找,以及用于输入操作数的寄存器读取请求生成。因此,记分板单元210和寄存器提供两组端口以读取valu输入操作数。例如,如果读取处理是上述最长时序路径的两倍快,则在相同类型的cr之间交替可以生成相同的整体性能。
本示例性实现可以等效于以等同于最长时序路径的速率运行的两个读取进程(每个cr一个,每个周期最多2个队列读取)。最大valu分派速率也可以由cr在从队列接收到新指令之后解除其就绪状态的往返时间来约束。
对csvr的读请求
在分派阶段期间,读取请求从记分板单元210发送到依赖性提交寄存器230、234以获取无数据依赖性的输入操作数。由于源数据可用,所以该值会被立即返回给处理该指令的cr。
提交寄存器的读端口在4个salu切片之间共享,但可以专用于五个向量cr中的每一个。对提交标量寄存器(csreg)230的读取周期以快如指令流水线速率的速率完成。因此,共享读端口是可能的,并且减少了读取逻辑。对提交向量寄存器(cvreg)234的读取周期也是以比指令流水线速率更快地完成。然而,由于向量cr的数量较少(与标量cr相比),所以使用专用读取端口。
对临时寄存器的读请求
为了更快地求解指令依赖性,可以在临时寄存器中提供推测性的、非提交的数据。对源操作数的读取请求被发送到临时标量寄存器(tsr)232或向量寄存器(tvr)236。接收到的读取请求将被挂起,直到数据在目标寄存器可用。然后通过读取目标寄存器并将其数据发送到目的地cr(vcr或salu切片)来处理该读取请求。
在任何给定端口上,在cr将其挂起指令移动到执行阶段之后,即可接收新的读取请求。然后,分派器可以向同一cr发送新指令,并在相同的寄存器读端口上生成新的读取请求。因此,不需要从寄存器单元到分派阶段的反向压力(backpressure)。
向量cr
向量cr是流水线化的资源。当向量指令发送到cr时,cr变为“忙”并清除其就绪状态。指令在cr的输入阶段等待,直到从提交或临时寄存器230、232、234、236接收到所有输入操作数。然后,指令执行开始,并且cr可以从vcr队列接受新指令(例如,在经过将来自cr的状态更新提供给分派阶段的最小延迟之后)。
向量指令分派器最大分派速率可能受到cr清除其就绪状态和分派阶段接收更新的信号的延迟的限制。还可以受到cr可以操作的最小周期(或最大频率)的限制。
cr独立地操作。基于输入操作数的可用性,执行可以在随机时间开始。一旦处于执行模式,cr流水线延迟可以是固定的,并且指令在cr内进行,直到结果在输出阶段被寄存。
对临时寄存器的写入请求
结果目的地对处理指令的cr而言是不可知的。当指令结果可用时,结果被推入临时寄存器。为每个cr提供了到临时寄存器的写端口。16个标量alu和两个dmem标量ld将它们的结果更新到临时标量寄存器(tsr)232中,而两个valu、1个vmac、1个vlutcr和两个dmem向量ld写入临时向量寄存器(tvr)236。
接收指令结果和标签的写端口通过使用标签查找记分板单元210中的ift来检索所分配的临时寄存器id。结果被写入,并且数据对于所有对该临时寄存器的输入操作数有依赖性的其他运行指令可用依赖性。
写提交控制器(wcc)
指令结果按顺序处理。可用于完成指令的三个示例机制包括:将其结果写入目的地寄存器的指令;当执行dmem写访问时结束的st指令;以及要求确认潜在指令流水线冲洗的跳转指令。
上述第一种机制涉及wcc用来自临时寄存器空间的数据更新提交寄存器空间。st和跳转指令由它们各自的单元(分别为dmem控制器226或跳转单元220)在wcc外部处理,直接向记分板单元210提供指令状态。记分板单元210转而将该状态中继到wcc。
wcc遵循记分板单元210提供的运行中指令状态。wcc根据指令提交序列向4个标量临时寄存器232和四个向量临时寄存器236端口中的一个发送最多四个临时寄存器读取请求。该序列遵循sb条目分配(标签)、跳过nop条目并在跳转和st完成状态下等待。由于指令的提交被顺序地执行,所以在所有先前分支指令(或来自较早指令的潜在异常)被解决之前,不会提交推测性指令。
尽管根据本文描述的实施例不需要nop,但是根据一些实施例,具有nop的指令代码可以由处理器处理。例如,指令代码可以已经具有nop,并且在一些实施例中,nop可以被移除,或者nop也可以继续存在,并且指令代码仍然可以由系统处理或使用。例如,迁移编译器仍然可以将nop插入到指令代码中。根据一些实施例,处理器仍然可以提供用于解决危险的改进,而不管nop是否在指令代码中。也就是说,根据一些实施例的处理器不需要nop来解决危险,但是如果所述移除需要额外的处理步骤,则nop可以出现在指令代码中。
数据读取请求保持被挂起,直到数据在目标临时寄存器变得可用,其中所述目标临时寄存器被分配给wcc想要提交的指令。然后,该请求在四个标量提交寄存器230写端口和四个向量提交寄存器234写端口之一上传送。目标提交寄存器对应于指令目的地,并且通过使用指令标签查找记分板单元210中的运行表来获取。最后,在处理后续指令之前,wcc触发对记分板单元210的请求,使之释放记分板单元210条目。
指令流
图3示出了用于说明性示例处理器架构的指令流循环的过程300的流程图。为了说明的目的可以参考图2的组件来描述示例性过程,但是根据本文描述的实施例的其他示例性处理器架构也可以用于实现过程300的操作。
在302,记分板单元210(标为sbm)将所有资源可用性位设置为“可用”,将下一可用指令标签设置为0到3,并将下一可用标量和向量临时寄存器(tsvr)位置设置为0到3。
在304,分配单元208(标为dm)设置其对imemfifo206的就绪(rdy)信号。当imemfifo206不为空并且分配单元108准备就绪时,imemfifo206将指令束发送到分配单元108(或评估单元的另一组件)。
在306,分配单元208解码指令并寄存记分板信息(例如标量/向量指令、nop、ld、st、jump、操作数位置、目的地位置)。分配单元208还基于指令解码来设置资源要求位(例如所需cr的数量和类型,所需的tsvr的数量)。分配单元208还寄存来自imemfifo206的指令操作码和从记分板单元210接收的指令标签。分配单元108清除其就绪(rdy)信号。分配单元208将当前指令束的资源要求与资源可用性进行比较。当足够的资源可用时,则分配单元108启用脉冲发生器以分配指令。分配单元208在最小周期延迟之后再次设置rdy信号。
在308,利用分配时钟(标为distr_clk),记分板单元210将记分板信息(标为sb_info)记录在ift中,并且更新资源使用数据结构(例如,分配的tsvr、分配的ift位置),并且设置相应的运行位。记分板单元210更新下一个束的资源可用性数据结构、下一个标签和下一个tsvr位置。记分板单元210利用分配给svr位置的最后一个tsvr来更新tsvr映射。记分板单元210利用引用tsvr位置的指令的数量来更新tsvrcnt表。
在310,分配单元208将所需的信息发送到crfifo或salu。
在312,vcr队列或salu将操作数信息发送到csvr或tsvr,并将操作码发送到vcr或salu。
在314,tsvr或csvr将源数据发送到vcr或salu。如果源输入源自csvr,则立即发送。来自tsvr的源输入在可用时发送。记分板单元210考虑刚刚分派的指令来更新tsvrcnt表。
在316,将来自vcr或salu的结果写入tsvr。tsvr设置可用标志并寄存要使用的指令标签来评估冲洗条件。
在318,tsvr设置其对wcc的avail(可用)位。当所有发出的推测都已解决时,wcc将tsvr数据写入svr位置。
在320,wcc设置提交的位。
在322,记分板单元210检查tsvrcnt表以确保tsvr可以被释放(即,在引用tsvr的crfifo中没有指令)。记分板单元210释放tsvr位置和ift条目,以使它们可用于后续指令。如果“运行中”位是指向svr位置的最后指令,则记分板单元210设置该“运行中”位。
控制流
图4中示出了示例性记分板单元410的框图。记分板单元410可以是如本文所述的评估单元的一部分。处理器400控制可以集中在记分板单元410(sbm)中,其连同wcc412控制整个dsp400的数据流。
记分板单元
记分板单元410的功能是跟踪记录关于当前运行中指令的信息。记分板单元410将信息存储在多个表(运行表432、tsvr映射表430和tsvr计数表434)中,并且根据需要更新它们。
运行表432存储关于指令的一般信息,包括例如指令类型(标量或向量)、nop、ld、st、跳转、操作数csvr和tsvr位置、目的地csvr和tsvr位置、以及imem地址。ift中的条目在被分配给指令时被标记为使用中,并且随着指令的结果被提交到csvr而被释放。
tsvr映射表430用于跟踪记录指定给csvr寄存器的最新tsvr位置。它还跟踪记录tsvr位置的运行中和已提交状态。该表由记分板单元410用以正确地分配输入操作数依赖性。
最后,记分板单元410使用tsvrcnt表434来跟踪记录crfifo中对tsvr位置有依赖性的未决指令的数量依赖性。此信息由记分板单元410用以确定在已经提交结果之后是否可以释放tsvr位置。
记分板单元410还跟踪记录资源可用性。资源可用性信息被发送到分配单元408以指示是否有足够的可用资源用于要分配的下一组指令。资源可用性信息可以包括:指令标签和tsvr432位置可用性;ld、st和跳转缓冲区可用性;crfifo条目可用性等等。
记分板单元410与写提交控制器412结合工作,当结果被提交到已提交svr434时,记分板单元410释放临时svr432位置和指令标签。此外,当ld、st、跳转单元420和crfifo条目被各自的处理单元处理时,记分板单元410更新ld、st、跳转单元420缓冲区可用性和crfifo条目可用性。
示例性记分板单元410功能包括:提供与分配单元408的接口以接收关于要分配的指令的信息;跟踪运行表432中的“运行中”指令的信息;跟踪tsvr432可用性,并将之分配给被分配的指令;维护具有分配给标量或向量目的地寄存器的最新tsvr位置的目的地tsvr映射430;跟踪可用的加载、存储和跳转缓冲区条目的数量;跟踪可用的vcr队列条目的数量;当dmem控制器426使用salu标识符从分配的salu捕获dmem地址信息时,向dmem控制器426发送用于加载和存储指令(标量和向量)的salu标识符和标签;当跳转单元420使用salu标识符从分配的salu捕获跳转信息时,发送用于跳转指令的salu标识符和标签到跳转单元420;通告对分配阶段通告资源可用性,以让分配单元408在存在足够的资源可用于分配当前四元指令时启用脉冲发生器;以及从标量和向量分派单元418接收标签,并向用于输入源数据的csvr434和tsvr432发送读取请求,输入源数据将直接从csvr434或tsvr432返回到cr416。
运行指令表(ift)
每个指令被分配了运行表(ift)434中的条目。当指令离开分配单元408时,向指令分配与ift条目的索引相对应的标签。同时,关于该指令的信息被记录在ift434中。由于多个指令可以同时分配,因此相应数量的顺序ift434条目被分配了指令束。示例ift条目字段的详细信息如下表所示。
记分板单元410实现资源可用性跟踪。当指令束离开分配阶段时,记分板单元410为下一个四元组更新资源可用性信息。记分板单元410可以跟踪记录资源可用性。下面提供了资源可用性的说明性示例:
加载缓冲区:最多16个条目
存储缓冲区:最多8个条目
跳转缓冲区:最多4个条目
标量tsvr:最多24个条目
向量tsvr:最多24个条目
运行表:最多64个条目
vmacfifo:vmacvcr队列中最多8个条目
valufifo:valuvcr队列中最多8个条目
vlutfifo:vlutvcr队列中最多8个条目
分配单元408使用资源可用性信息来启用脉冲发生器分配指令束。由于到脉冲发生器的启用信号必须无干扰,所以记分板单元410使用独热编码(one-hotencoded)信号来声明资源可用性状态。
例如,记分板单元410通过设置以下示例信号来指示加载缓冲区可用性:
no_ld_avail
one_ld_avail
two_ld_avail
threeldavail
four_ld_avail
当加载缓冲区条目变得可用时,这些信号可以无干扰变换。分配单元将资源可用性信号与资源要求信号进行逻辑“与”操作,并且当有足够的资源可用于将要发出的四元组中的所有指令时,启用脉冲发生器。
对于本示例,在一个时间同时分配多个指令。因此,在分配指令包之前,必须有足够的资源可用来处理所有指令。说明性示例是四个指令的四元组。
源输入读取
在离开分配单元408之后,立即分派标量指令,同时将向量指令发送到向量分派单元(vdu)418的vcr队列。
标量和向量指令分派单元418将标签发送到记分板单元410以请求它们的操作数。记分板单元410使用标签来查找运行指令表,以确定输入源数据是应该来自提交svr还是临时svr。记分板单元410负责向提交svr或临时svr发送源输入数据读取请求。当从寄存器单元读出后,源输入数据被返回到与该读请求相关联的cr416。如果数据来自临时svr,则数据在变为可用时发送。
tsvr计数表
由于输入操作数依赖性在分配阶段被评估并记录在ift432中,所以这些依赖性应保持有效,直到在分派阶段读取输入操作数。因此,在分派所有依赖性指令之前,不能释放在crfifo中具有依赖性指令的tsvr位置。
在释放指令标签和所分配的临时寄存器之前,记分板单元410监视是否存在尚未分派的链接到已经提交的临时svr寄存器的运行中指令。为了确保临时svr位置在依赖性指令被分派到vcr之前不被重新分配和覆盖,使用了tsvr计数表434来跟踪记录vcr队列中引用该临时寄存器位置的指令数量。
当分配指令时,每当有指令使用临时寄存器作为其输入之一时,作为源数据来源的tsvr计数表434位置增加1。当指令退出vcr队列并被分派时,tsvr计数表434减1。记分板单元410使用该表来确定临时寄存器位置是否可以被释放和重新分配。如果在vcr队列中没有指令引用特定临时寄存器位置,则可以在提交完该临时寄存器位置之后立即释放该临时寄存器位置。否则,即使内容已被提交到csvr,但直到源tsvr映射430计数变为0之前,tsvr位置都不可用。
重要的是注意,源tsvr映射430大于一并不会阻止写提交控制器412将结果写入提交svr434。它仅防止记分板单元410在已经从vcr队列分派引用tsvr位置的所有指令之前过早地释放该位置。一旦wcc412提交了结果,将设置标志以指示该临时svr432已被提交。从此开始,离开分配单元408的任何指令都将引用提交svr434位置,以确保该临时svr432位置的及时释放。注意,对于本例,一旦已经提交了tsvr,则即使tsvr432位置不能被释放,也可以释放与该指令相关联的sb条目。这是一个示例性实施例。
对于标量分派单元,由于没有队列,所以可能没有重新分配tsvr位置的危险。
tsvr映射表
记分板单元410还负责跟踪记录所有标量和向量目的地寄存器(csreg和cvreg)的“运行中”和“已提交”状态。当tsvr位置被分配给指令时,tsvr映射430被更新,以指示目的地寄存器的运行中和已提交状态,以及最近分配给寄存器的tsvr位置。然后,该信息用于为离开分配单元408的后续指令确定源输入位置。
可为标量和向量寄存器使用单独的tsvr映射表。tsvr映射430可以包含与提交的寄存器位置一样多的条目(例如,标量是64位,矢量是16位),并且用指令目的地寄存器来索引。
示例性已提交和运行中标志定义如下所示:
图5示出了示例性记分板条目释放单元500,包括已清除运行中状态的tsvr530。在指令执行结束时,来自cr522的结果数据以及相关联的标签进入临时svr530写端口。标签用于从sbm中的运行表532中查找目的地临时寄存器id。同时,标记被记分板释放单元500用于确定当前指令是否是向提交寄存器空间中的目的地寄存器写入的最近的“运行中”指令。如果确是最近一个以目的地寄存器为目标的指令,则可以设置标志以清除tsvr映射534中的寄存器的运行状态。写入提交控制器512使用该信息,在数据已经写入提交svr之后清除“运行中”位。同时设置“已提交”标志。一旦设置了“已提交”标志,此后启动的指令将使用该提交的寄存器值作为源输入。
一旦结果被提交,就可以重新分配与该指令相关联的sb条目和临时寄存器位置。记分板释放单元500在此时释放sb条目(标签)。然而,在释放tsvr位置之前,要等待所有依赖性指令离开分派阶段。一些实施例可以确保在释放tsvr530之前确已从tsvr530中读出数据。
冲洗
将结合图2作为说明性示例来描述冲洗。当跳转/分支指令被分配单元208识别并分配到salu切片时,记分板将分支指令标签记录在跳转缓冲区中。每个跳转缓冲区条目都跟踪记录一个分支。记分板单元210还标记跳转指令被分派到的saluid。
跳转指令被分派到salu作为接受条件评估的正常指令。在完成时,salu将跳转指令的结果,即用于程序继续的新pc,与跳转指令的标签一起,发送回跳转单元220。
跳转单元220接收所有salu结果,并使用由sbm提供的saluid将salu结果中的一个连接到跳转缓冲区条目的头部。
跳转单元220使用指令标签来查找下一指令的相应pc值(imem地址),并将其与接收到的跳转结果进行比较。如果跳转预测正确,则地址匹配,并且程序执行可以继续,而不生成冲洗。如果条件允许,可以通知记分板单元210分支推测已解决,并且继续下个指令提交。如果地址不匹配,意味着跳转被不正确地预测,则将发出指令流水线冲洗。同时,新的pc204值(来自跳转结果)将被发送到pc204以重新同步pc204值,并且在新位置处开始从imem202获取指令。
当由跳转单元420生成冲洗时,通知记分板单元210中的运行表(ift)。记分板单元210将阻止分配单元208分配新指令。ift将会被更新。记分板单元210使用与创建清除条件的指令相关联的标签来确定应当移除哪些ift条目。在冲洗期间,不允许提交这些条目。如果冲洗指令具有标签n,则在冲洗之后分配的新指令将使用n+1作为其指令标签。
冲洗操作不会重置或清除推测性运行指令。如果指令处于运行中(例如已离开分配阶段)并且新于导致冲洗的指令,则该指令是推测性的。在向量域中,推测性指令可以在执行冲洗时在vcr队列中缓冲。vcr队列在冲洗后会照常读取,等待vcr变为就绪。从vcr队列头条目提取的指令标签用于查找ift。如果指令是推测性的(其标签大于冲洗标签),则指令将被cr清除。cr将保持可用,并继续从其vcr队列中拉出另一条指令。如果标签较小(即该指令比冲洗指令早),则指令由cr照常执行。
对于dmem控制器226,其可以是记分板单元210的从属(slave)。冲洗请求和标签不能发送到dmem控制器226。
图6示出了根据一些示例实施例的用于冲洗的过程600的流程图。
在652,跳转单元650将跳转队列结果的头部与来自salu680的头部进行比较,以确定结果是否导致冲洗。在654,生成新的程序计数器602,其触发指令fifo604在672进行清除。在656,冲洗信号触发记分板单元610声明标志以表示冲洗正在进行中。在658,记分板单元610向dm解除声明rdy以停止输入指令。注意到引起冲洗的标签也会在660相应地清除所有表。在662,记分板单元610向dmem控制器dmc626发送冲洗信息(标签等)。当完成所有操作时,记分板单元610在664向分配单元608声明rdy,以在668接受新指令。记分板单元611在670解除声明标志以表示冲洗完成。
跳转单元
回过来参考图2,作为说明性示例,跳转单元220监视条件评估的结果,并确定是否应当生成冲洗。
跳转单元220存储多个分支指令(例如对于四元组示例为四个)。当在分配单元208处检测到跳转指令时,记录板单元210记录分配的指令的imem地址(pc值),同时还记录指令标签和作为目标的saluid。稍后,一旦salu解决了跳转指令,就将由跳转单元220使用该信息以确定是否应生成冲洗。缓冲区彼此独立,并且当指令离开分配单元208时被更新。
salu将pc结果和相应的指令标签发送到跳转单元220。跳转单元220将跳转缓冲区的头部与输入的pc结果进行比较。然后将imem地址与跳转目的地pc值进行比较。如果它们匹配,则指令流继续而不中断。如果地址不匹配,则触发指令流水线冲洗信号,并且pc202(从imem读取指令)被重新同步到跳转目的地pc值。如果该比较不生成冲洗,则将其丢弃,并且通知记分板单元210可以释放与该评估相关联的标签。如果发生冲洗,则将为记分板单元210生成冲洗信号。此外,将该次冲洗以及新的pc值通知pc202。
从生成冲洗的时间到冲洗过程完成的时间期间,跳转单元220仍然可以接收运行中跳转指令和salu评估结果。这些(基于冲洗标记)将被跳转单元220丢弃或丢掉,并且不会进行评估。
嵌套分支
本处理器架构支持嵌套分支。对程序可以有多少层分支嵌套没有限制。然而,根据程序要求,对于一些实施例,处理器可以一次支持最多4个未决的分支指令。作为说明性示例,本描述可以假设一次有4个未决分支指令,但是也可以使用其他阈值。超过之后,直到分支之一被解决之前,处理器可以停止指令流水线。
由于salu的执行可能是无序的,因此可以无序地接收分支评估结果。只有最外层的分支会被评估。发生在外层分支的冲洗请求将导致内层分支也被冲洗。内层分支的结果,即使是被预测的,也不会由跳转单元220评估。这与前文所述的先前的指令被解决之前不能提交后面的指令结果的事实一致。
冲洗标记
当发生指令流水线冲洗时,记分板单元210增加3位冲洗标记(例如用以支持n=4层嵌套分支)并将其附加到来自分配单元208的所有新指令的指令标签。冲洗标记的大小取决于读取输入操作数的最大延迟。冲洗标记用于在运行表中区分当前条目与具有相同的低6位指令标签值的其他条目。当错误预测的分支花费太长时间才被分派、导致新指令在它之前被置于运行中时,这种情况就会发生。
从指令流水线冲洗恢复
在冲洗之后,运行表可以从跳转引起冲洗之后的首个标签编号立即重新开始。冲洗标记也将递增。在冲洗之后,为指令分配的所有tsvr将被回收。已经在cr中分派的任何运行中指令,无论是推测性的还是非推测性的,都将运行至完成。如果指示有要求,可以将非推测结果提交给csvr。通过使tsvr可用,可以丢弃推测性结果而不提交内容。
在向量分派器218中等待分派的指令仍然可以被分派。推测性指令将被丢弃,并且不向tsvr生成读取请求。非推测性指令将正常操作。
以下提供了冲洗的各种说明性示例实施例。
以下指示信息描述了如何实现冲洗的示例:
pc+0:r5=r6+r7;//iidx=8|非推测性;->更新条目r5为“busy|iidx=8”;
pc+1:if(..)//分支指令应该为“未占”;然而btb判定为“已占”
{
....
pc+8:r5=r4-r3;//iidx=16|推测性的;->更新条目r5为“busy|iidx=16”;
}
pc+9:r9=r5+1;//iidx=17|推测性的;->rs0=r5->检查条目r5并得到“busy|ridx=16”;
pc+10:r5=r22+16;//iidx=18|推测性的;->更新条目r5为“busy|iidx=18”;
一个选项可以是实现推测性和深度运行(deep-in-flight)处理器。示例是重排序缓冲区(re-orderbuffer(rob),例如64深rob)。isd分别向crd发出(pc+0)指令和向分支处理单元发出(pc+1)指令。当(pc+1)分支已解决时(bpu将执行结果发送到rob),(pc+0)指令可能仍在运行中。rob在冲洗其推测性指令并重新获取(pc+9)指令之前,可以等待所有未决非推测性指令,即(pc+0)|iidx=8,的提交。因为直到从指令存储器获取新的指令之前都可以提交所有未决的非推测性指令,所以如果rob必须等待所有未决指令的提交,则可能会有严重的冲洗惩罚。此外,大多数未决的指令都是存储器加载的。获取新指令的命令已经由bpu发送到指令存储器。如果rob立即启动推测性指令,则rob需要将寄存器文件r5条目“回滚”到“busy|iidx=8”。rob不仅冲洗rob中的推测性指令,而且还根据rob中的生存条目(例如pc+0|iidx=8|非推测性)冲洗忙向量和iidx寄存器文件。
以下说明描述了处理器处理嵌套分支的另一个示例性冲洗:
对于该示例,作为示意,假设分成流section-a,section-b,section-d和section-e。由于分支的原因,推测性程序流是section-a、section-b、section-d和section-e。第二分支指令(if(r3>r7))是推测错误的分支。假设第二指令(if(r3>r7))远早于第一分支指令(if(r4<r6))获得其操作数。如果bpu支持无序执行,则当处理器执行section-a和section-b时,处理器可以推测性地冲洗section-c并获取section-d。于是,就隐藏了冲洗惩罚。
数据存储控制器
作为示例性说明,对dmem控制器226设计的描述可以假设是同步数据存储器,然而,存储器接口可以适应于异步设计。
dmem控制器226可以支持四元指令束中的ld/st的任何混合。直到ld和st缓冲区充满,dmem控制器226可以处理最多4个ld、4个st或ld/st的混合缓冲区。dmem控制器226可以并行处理最多16个ld和8个st访问请求。在分配阶段,记分板单元210将ld/st缓冲区条目与指令标签一起分配给ld/st指令。对于要离开分配阶段的指令,需要足够的ld/st缓冲区条目。直到ld或st缓冲区条目被释放且可重新分配给新指令之前,dmem控制器226可停止指令流水线。可以独立地为ld和st指令维持指令排序。只要没有检测到地址冲突,就可以允许较新的ld在较早的st之前通过。一旦检测到ld/st地址冲突,所有ld都可能停止,直到冲突解决。当所有未决的st(乃至并包括冲突的st)被发送到dmem228时,就解决了ld/st地址冲突。发送到dmem228的st指令都假定是已完成的。只有这样,才能重新开始ld处理。ld可以是推测性的。st不可以是推测性的。推测性ld数据可以写入临时寄存器,但不会在提交寄存器中更新。st仅在所有先前的推测都被解决时才可被启动。st数据总是来自提交寄存器,并且只有当记分板单元210已经发送寄存器读取请求并且dmem控制器226已经接收到st数据,st数据才可以被发送到dmem228。当所有前置指令被提交时,记分板单元210发送对特定指令的st数据的读取请求。
由于指令执行时间不是确定性的,并且指令可以基于其输入操作数可用性在任何时间启动,所以条件访问解决和有效地址可以从16个salu中的任一个无序地到达dmem控制器226。为了保证存储器访问序列,使用记分板单元210ld和st缓冲区来记录已分配的ld和st指令。
ld和st缓冲区条目的排序以及sbm的标签分配可以保证dmem控制器226按顺序处理所有dmem相关指令。运用所有运行中ld和st指令的标签,dmem控制器226可以确定ld和st的顺序和优先级。
dmem异常
dmem控制器226检测非法存储器访问,例如无效或非法访问、地址超出范围等。当检测到这种状况时,dmem控制器226将问题作为异常报告给记分板单元210,并且可以在本地清除ld和st而不发送到存储器。
当执行ld时,可以从存储器返回的唯一异常是来自读取访问的数据错误。对于st,在执行存储器写访问时不会出现异常。
ld和st优先级和冲突解决
可以保留ld和st指令序列。然而,允许在较早的st指令之前发送较新的ld指令。
在向dmem228发送ld或st访问之前,dmem控制器226必须确保已经从salu228接收到所有较早的st运行中ld和st指令信息(存储器地址,范围等)。否则,不可能检测到针对较新的ld指令的潜在地址冲突。
在一些实施例中,对于以下示例,处理器可以允许超过st的ld优先级:ld指令是最早的(ld缓冲区头部);所有较早的(与最早的ld标记相比)st指令信息(地址范围等)在dmem控制器226处可用;没有地址细节,不可能确认潜在的ld/st冲突;控制器使用来自st缓冲区的sbm标签而知道了较早的st指令;较早的st地址与ld地址不重叠;等等。
如果上述示例优先化条件中有一个不满足,则可以阻止头ld缓冲区条目。ld/st冲突自然会通过处理st缓冲区条目来解决。一旦冲突的st被发送到dmem228,冲突标志就会被清除,并且ld缓冲区头条目会被允许读取dmem228。
ld指令
dmem228在其2个读端口中的每一个上顺序执行存储器读取。因此,dmem控制器226记录哪个ld指令被发送到2个存储器读端口中的哪一个,并且期望ld数据以相同的顺序在同一端口上返回。当由存储器返回读取数据时,dmem控制器226将指令标签与接收的ld数据相关联,并将其(用标签)转发到临时标量寄存器232或向量寄存器236(tsvr)。
只有当ld数据被发送到tsvr时,dmem控制器226才能将ld完成通知给记分板单元210。记分板单元210然后就可释放ld缓冲区条目(不需要ld数据的提交)。一旦释放条目,dmem控制器226还清除该指令的所有相关联的记录。
如果发生异常(例如读取数据错误),异常状态将用ld指令完成状态来进行标记。
st指令
为了允许存储器写入发生,dmem控制器226可以在提交st之前等待所有指令。不再监视提交序列,记分板单元210仅在st是下一个要提交的指令时才发送st数据读请求。从提交寄存器(例如230,234)读取的数据被直接发送到dmem控制器226;一旦接收到,dmem控制器226执行存储器写访问。
然后,dmem控制器226将st的完成通知记分板单元210。类似于ld,记分板单元210和dmem控制器226可释放st缓冲区条目和与该指令相关联的所有其他记录。
与ld相反,因为假定发给存储器的st必然完成,所以记分板单元210要释放与指令相关联的标签时,并不会等待st数据的提交。
接口描述
处理器可以实现以下示例性接口相关特征。
分配单元
当指令离开分配单元208时,记分板单元210将每个ld和st指令分配给ld或st缓冲区中的条目并记录标签。缓冲区的目的是保证dmem控制器226中的资源可用性,并允许dmem控制器226跟踪记录ld和st指令之间的顺序。
记分板单元210向dmem控制器226提供ld和st缓冲区信息(标签、标签有效状态、处理指令的saluid)。由于当指令被分配时ld和st缓冲区被填充,所以dmem控制器226假定信息是稳定的。
标量alu
salu负责评估有条件ld和st指令并计算有效的存储器地址和范围。在与16个salu中的每一个的源同步的点对点接口上,ld和st结果信息被发送到dmem控制器226。
当ld和st信息来自salu时,保存有标签、有效标签和saluid的记分板单元210ld和st缓冲区可以是稳定的。salu端口已经被配置为(使用来自sbm的saluid)将ld和st结果路由到位于dmem控制器226中的ld或st信息缓冲区的适当条目。
提交标量和向量寄存器
如果给定st指令不是推测性的,则st32或128位数据总是来自在源同步接口上的提交寄存器(例如230、234)。
当该st指令的所有前置指令已被提交时,记分板单元210发起对提交寄存器(例如230、234)的st数据读请求。因此,当dmem控制器226接收到st数据时,其假定st请求是非推测性的,并且可以启动dmem写访问。
dmem
dmem控制器226可以与dmem时钟同步。
读端口可以配备有28位地址。每次从存储器读取128位数据。dmem控制器226为sld提取32位ld数据,并且忽略剩余的数据位。
写端口配备有地址、128位数据且每位都能写入。对于sst,只写入128位数据中的32位。还可能存在未对齐的访问。
临时标量和向量寄存器
连接至临时寄存器空间的接口用于将ld数据从dmem228返回给处理器200。dmem控制器226从两个读端口中的任一个接收dmem数据,检索与ld数据相关联的指令标签,并且向寄存器单元源同步地发送该数据和标签。
dmem控制器226具有到标量和向量临时寄存器单元的两个专用点对点连接。dmem控制器226将ld数据发送到标量或向量寄存器接口。临时寄存器使用标签来查找记分板单元210的ift并确定所分配的临时寄存器标识符,并用ld数据更新寄存器内容。
记分板单元
dmem228st指令状态反馈被发送到记分板单元210。如果发生ld/st异常(非法存储器地址、读取数据错误等),则16个ld或8st缓冲区条目之一被标记为“异常”。在与异常指令的ld或st缓冲区索引相对应的位上设置标志。一旦记分板单元210接收到异常通知,就采取进一步的动作,并且最终释放异常后(post-exception)sb条目。
dmem控制器226在st指令作为写访问被发送到dmem228时,还将指令完成状态更新发送到记分板单元210。在与st指令的st缓冲区和索引相关联的位上设置标志。记分板单元210接收st完成通知并且最终释放指令标签。
一旦ld和st条目被记分板单元210释放,就会重置发送到dmem控制器226的指令标签有效状态。dmem控制器226检测状态的更新,并立即释放与该指令相关联的所有本地缓冲区条目。
存储可以是提交,如寄存器写入。在一些示例中,仅有已提交的数据才可以用于st指令和诸如寄存器内容。存储指令可以使用来自尚未写入寄存器文件的读取和写入提交的数据,然后将之写入存储器。这也可以是存储-提交(store-commitment)。
如果地址-rob被合并到数据-rob中,则rob实际上起到存储队列的作用,其中存储有效地址按照iidx存储。
如果ld的有效地址与存储队列中的任何未决的存储指令的有效地址不冲突,则ld可以是推测性的和乱序的。
实施例可以采用ld或st而不是移动指令来交换标量寄存器和向量寄存器。请看示例:
sv128vr7,r3;//(*r3)=vr7;
ldr7,r4;//r7=(*r4);r4=r3+3;
这实际上将vr7的第三通道(lane)移动到r7。rob可以检测ld或st冲突,使得在st完成之前ld不会被发送到存储器。流水线可能被停止。然而,如果ld被推测并且st数据在rob中,则rob简单地将要存储的128位数据的第三通道返回到r7。
dmem特件
dmem228可以使用周期性时钟提供同步接口。例如,dmem228可以具有2x读取端口、1个写入端口、128位数据宽度等等。对于在相同周期上发送到dmem228的读取和写访问,其顺序可能不会得到保证。在一些示例中,存储器是字节可寻址的,在128位边界上访问。当访问128位数据时,忽略地址四个lsb。存储器地址配备有位[31:4]。未对齐的读/写访问在dmem控制器226中使用对齐寄存器来处理。dmem228读写端口具有相同的延迟。在写访问之后的下一时钟周期上发送的对同一存储器地址的读取访问将读取更新的数据。与在上一个存储器时钟周期启动的写入的地址相同的地址进行读取,必须返回该写访问更新的数据。由于潜在的缓冲区未命中,读取数据延迟不是确定性的。但是,保持给定端口上的访问顺序。在存储器读端口上的读访问上的缓冲区未命中可能使该端口上的后续读访问停止向核心返回读数据。
在另一方面,提供了另一示例性处理器架构,其可以使用指令解码器和分派器、重排序缓冲区、缓冲区元件和寄存器文件来实现分配单元和记分板单元的评估功能。
图7示出了根据一些实施例的示例性处理器700。处理器700可以包括用于评估单元、执行单元和终止单元的组件。例如,处理器700包括:imem接口702,用于向imem存储器发送读请求,请求读取存储在相应指令存储器地址处的指令;指令缓冲区704,用于存储响应于读请求、从指令存储器接收的指令数据,其中保存用于分派的指令数据;以及程序计数器706,用于为该读请求生成至少一个指令存储器地址,以请求读取存储在imem的该至少一个指令存储器地址处的指令数据。指令数据是引用操作数(数据)和操作码的数据结构。处理器700包括解码寄存器708、寄存器文件712、分支处理单元(bpu)712、指令分派器(id)710、重排序缓冲区(rob)720,这些一起工作,使用指针来评估指令数据的操作数和操作码的源输入操作数依赖性和执行依赖性、为指令数据分配指令标签以提供引用标识符、为指令数据的操作码跟踪资源和数据可用性、将资源和数据可用性与输入操作数依赖性和执行依赖性进行比较、以及使用指令标签跟踪当前运行中指令的有关信息。处理器700包括:加载存储单元(lsu)714;运算或计算资源(cr)716,用以基于资源可用信号来管理分派,指令数据作为至少一个队列的条目,供计算资源的执行指令数据以生成指令结果,其中当所述指令数据从队列分派到所述计算资源时,所述队列前进到下一条目(如果可用)。dmem接口718用于基于指令数据的操作码,从数据存储器读取和向数据存储器写入。
图8示出了根据一些实施例的另一示例处理器800。处理器800可以包括用于评估单元、执行单元和终止单元的组件。处理器800包括:imem接口802,用于向imem存储器发送读请求,请求读取存储在相应指令存储器地址处的指令;ififo804,用以响应于读取请求,存储从指令存储器接收的指令数据,其中让指令数据等候分派。指令数据是引用操作数(数据)和操作码的数据结构。处理器包括分支处理单元(bpu)806、id808、寄存器文件(regfile)810、rob812、rob写压缩器(rwc)814,这些一起工作,使用指针来评估指令数据的操作数和操作码的源输入操作数依赖性和执行依赖性、分配指令标签以提供指令数据的引用标识符、跟踪指令数据的操作码的资源和数据可用性、将资源和数据可用性与输入操作数依赖性和执行依赖性进行比较、以及使用指令标签跟踪关于当前运行中指令的信息。处理器800包括lsu816,cr分派818,用以基于资源可用信号来管理分派指令数据,其作为计算资源的至少一个队列的条目用于执行指令数据以生成指令结果,其中当所述指令数据从队列分派到所述计算资源时,所述队列前进到下一条目(如果可用)。dmem接口820用于基于指令数据的操作码,从数据存储器读取和向数据存储器写入。
对于处理器800,可以同时和按各种速率提取指令。例如,可以发出四条指令。作为示例,指令格式可以是低位优先(1ittleendian)。对于每个cr,可以存在具有单独的分派指令fifo804的多个并行(标量、向量)运算/计算资源(scr/vcr)。处理器800可以允许对指令进行无序执行。可以存在用于分支、加载、存储和cr(运算资源)指令的单独缓冲区,以允许无序执行。可以通过专用的bpu806执行分支指令。例如,多个深度bpu806和ififo804指令处理可以允许未解决的条件分支操作的推测性执行。可以根据一些示例,在建模之后确定ififo804深度。处理器800可以具有带有两个加载端口和一个存储端口的专用加载/存储处理单元(lsu816)。可能存在由lsu816处理的多个并行地址计算。可以有在下一个地址计算中用到的地址结果的快速路径。无序推测性加载和有序非推测性存储可以由lsu816内的逻辑来识别和解决。处理器800可以按顺序写回到regfile810,这可以由64个条目数据重排序缓冲区(数据rob)812来保证。当cr结果被写入rob812时,也可以被广播到cr、加载、存储和bpu缓冲区元件。
以下提供可用于描述根据本文描述的实施例的示例处理器架构的另一些示例性术语。
“四元组”指令可以指四个32位指令的组。这是可以加载到本文所描述的示例处理器中的多个指令的说明性示例。
以下状态定义可以用于定义处理器800的功能性。“已声明”可以指状态位,如果该位等于逻辑“1”,则处于“已声明”状态。“设定”一个位就是将其置于“已声明”状态。状态位如果等于逻辑“0”,则可以是“解声明”状态。“重置”一个位就是将其置于“解声明”状态。
以下寄存器位定义可以用于定义处理器800的功能性。rsx可以指寄存器源,其中x=0,1,2,并且dsx可以指数据源,其中x=0,1,2。rdx可以指寄存器目的地,其中x=0,1,这些取决于一个指令有多少输出。rdx是当rov812条目准备就绪提交时,要在regfile810中写入到何处的地址。ddx可以指数据目的地,其中x=0,1,取决于指令有多少输出。ddx是当rob812条目准备就绪提交时,要在位置rdx处写入到regfile810中的数据。vsx可以指向量或标量指示器,其中x=0,1,取决于一条指令有多少个输出。该位用以了解当rob812准备就绪提交时有多少位要写入regfile810。“忙碌”意味着寄存器已被选为指令输出的目的地,并且当指令还在执行时不能从regfile810读取出来。当指令完成且寄存器已经被提交回regfile810时,则该寄存器不再忙碌,并且可用于从regfile进行读取。brfx可以指与rsx相关联的寄存器文件忙碌位,其用在寄存器记分板中,用以表示regfile810中特定寄存器“忙碌”且不应该被读取。brbx可以指与rsx相关联的rob忙碌位,其可以用在寄存器记分板中以表示在rob812中特定的寄存器“忙碌”,且不应该被读取。iidx可以指由指令索引生成器生成的指令索引。iidx可以用以跟踪记录用于数据的寄存器。
虽然以下组件示例功能性是参考处理器800来描述的,但也可以应用于本文所描述的其他处理器架构。
ififo804可以指指令获取fifo。rob812可以指重排序缓冲区。id808(或预先解码)可以指具有预先解码的指令分派器。标量资源缓冲区元件可以称作srbex,其中x=0至7。标量cr指令被置于任何空闲srbex元件,不管该元件的输入是否被阻止。如果输入数据可用,则被存储在srbex中。如果输入数据不可用,则指向数据rob中该数据的最终存储位置的指针被存储在srbex中。
向量资源缓冲区元件可以被称作vrbex,其中x=0至7。向量cr指令被置于任何空闲vrbex元件中,不管该元件的输入是否被阻止。如果输入数据可用,则被存储在vrbex中。如果输入数据不可用,则指向数据rob中该数据的最终存储位置的指针被存储在vrbex中。
加载缓冲区缓冲区元件可以被称为ldbex,其中x=0至15。不管其输入是否被阻止,加载指令都被置于任何空闲ldbex元件中。如果输入数据可用,则被存储在ldbex中。如果输入数据不可用,则指向数据rob的指针被存储在ldbex中,而数据将最终存在数据rob中。
存储缓冲区缓冲区元件可以被称为ldbex,其中x=0至15。存储指令被顺序置于stbex元件中,不管该元件的输入是否被阻止。如果输入数据可用,则被存储在stbex中。如果输入数据不可用,则指向数据rob中该数据的最终存储位置的指针被存储在stbex中。
分支处理缓冲区元件(bpbe)可以指降分支(fallbranch)类指令,其等待一旦输入参数可用时被分派。分支类指令被顺序地置于bpub中。
运算或计算资源(cr)可以是向量或标量资源。例如,scr可以指标量运算资源,且vcr可以指向量运算资源。
imem接口
imem接口802可以在一些示例中被实现为连接到imem的同步接口,但是也可以是指令高速缓冲区结构。被用于访问imem的地址可以被称为程序计数器(pc)。在重置时,imem内部的pc可以被重置为0,且imem可以推入多个指令(例如,四个指令,每个均32位)至ififo804且对pc增4。每个地址代表32位。由于每次事务处理(transaction)imem向ififo推入多个指令(例如,128位),所以pc必须被增加与多个被推入指令数量相应的数(例如4)。在一些示例中,imem可以继续增加pc,增加数为多个指令的数量,且在每个循环中将指令数据推入ififo,唯下述的示例条件例外:如果存在来自ififo804的full指示,则指令推入必须停止;如果存在来自于bpu806的wait指示,则指令推入必须停止;如果由于分支指令,bpu发送pc更新,则imem可以用更新了的pc来更新其内部pc,并重新开始“正常”操作;
iftfo
ififo804可以对来自同步域的指令重新设置为id块的时钟域。ififo804可以具有以下属性。存在多个条目。如果ififo804是full,则ififo804必须用信号通知imem802,从而指令将停止被推入。ififo804可以包括多个指令,例如四个32位指令{instr0,instr1,instr2,instr3}作为说明性示例。
指令分派
指令分派器(id)808块具有以下示例性属性:来自ififo804的指令被预先解码为如分支、加载、存储、标量计算资源(scr)或向量计算资源(vcr)指令。因为vmac指令需要多至3个128位输入,所以vcr指令被进一步分类为vmac和非vmac。
被解码的分支指令和任何直接目标地址信息被直接发送到bpu806。如果bpu806缓冲区已满,则id808将停止,导致ififo804最终成为full。如果有四个未解决的推测性分支指令,则bpu806报告full。在将指令推入regfile810之前,id808必须检查缓冲区元件(srbe、vrbe、ldbe、stbe和bpu)的可用性。如果具有任何未被推入的指令,则id808能够基于各自的可用性推入四个指令中的任一个,直到剩下的指令被推入rf810之前,id808将停止。
id808将修改所有寄存器资源/目的地数,修改幅度为rf810窗口偏移(windowbase)。寄存器开窗口控制(windowingcontrol)在id808块中被处理。id808包括8个条目返回地址堆栈(ras)以支持8层子例程调用嵌套。ras用于支持从函数调用的返回。当call指令执行时,返回地址被保存在ras中。如果另一个call指令在ret指令之前被执行,则下一个地址将被push到ras顶部。
当ras指令被执行时,返回地址将从ras顶部弹出,并被用于获取call指令之后的指令。当有推测性指令仍未解决时,id808将不会分派call或ret指令。如果ras是满的,则如果另一个call指令被解码时,id808将发出异常。id808将顺序分配指令索引(iidx)给每条指令。id808包括6位iidx计数器,对于一些示例性实施例其从0数到63,然后回滚至0。作为说明性示例,四元可以消耗4个iidx值。iidx计数器会为每个四元而增量。rob812包括64个条目,因此每个iidx对应于rob812的一个条目位置。对于每个rob812,rob[y](其中,“y”是从0到63的条目编号),rob提供独热(one-hot)忙碌状态给id(其可以表达为rob[y].busy)。当id808尝试分配iidx[5:0]=y,则必须首先检查在rob[y]处的rob812条目。如果rob[y].busy=1,则id必须停止,因为rob为满。
图9示出了示例性指令分派和解码单元(id)908的示意图。在本示例中,id908具有id控制930、脉冲生成器938和输出流水线948。id控制930具有解码器932、初步匹配单元934、ififo读取器936、最终匹配单元940、索引分配942、寄存器窗口管理器944和分支接受单元946.
rf(寄存器文件)
寄存器文件(rf)810可以具有以下属性。每个条目可以包括:1个忙碌位、5个深度iidx堆栈和数据字段(其大小取决于寄存器文件类型而变化)。当寄存器忙碌时,后续指令被给予来自iidx堆栈头部的iidx,其跟rob条目相对应,在rob条目处可找到数据。iidx堆栈可允许4个未决的条件分支和指针的快速冲洗。一个示例性的标量寄存器可以具有一个64条目32位(sr0至sr63)。在一些示例中,rf810可以支持12个读取端口和4个写入端口。rf810可以设置有16个寄存器访问窗口。访问窗口可以由函数调用来控制,可以按4、8或12个寄存器来轮转。来自call的返回地址存储在ras中。溢出生成窗口溢出异常,其中所述异常处理程序必须将较早窗口的内容转储(spill)到堆栈上预分配的转储区域。当从函数调用返回至已溢出的窗口时,生成窗口下溢异常,其中溢出处理程序必须将转储到堆栈的寄存器值复制回寄存器文件中。寄存器开窗口控制在id808块中处理。可以存在一个16条目128位向量寄存器文件(vr0至vr15),其可以支持12个读取端口和4个写入端口。rf810可以支持2个类型的向量数据:例如vfloat(8x16)和vfloat(4x32)。可以存在一个4条目128位的对齐寄存器文件(al0至al3),其支持一个读取端口和一个写入端口。可以存在一个8条目32位的选择寄存器文件(sl0至sl7)和一个16条目1位的布尔寄存器文件(bl0至bl15)。
rfiidx堆栈
对于每个rf810可以存在一个iidx堆栈,其记住或记录被分配的5层iidx。这允许rf810迅速从最多4层推测展开。rf810iidx堆栈可以具有以下属性。在重置后,头和尾指向相同的堆栈单元。当存在推测性分支时,堆栈头部将增量一。id808块确保无多于4个的未解决推测性分支指令,因为超过则bpu806将满,并且如果另一个分支指令加入进来,id808将停止。当读取特定寄存器的请求从rf810提出,则rf810从堆栈的头部返还iidx,此即最近的寄存器实例。如果在相同分支层次上存在对相同寄存器目的地多个写入时,iidx将被覆盖。rob812能够处理相同的寄存器具有多个iidx。对rf810的写是按序的,且检查在尾部的iidx值以观察是否存在匹配。如果不存在匹配,则rf810将不接受写,因为这是一个由rob812处理的较早的寄存器实例。分支按顺序解决。当分支被解决为被接受,则尾部增量一。有冲洗时,对rf810iidx堆栈指示冲洗分支的数量,且对头部减量该数值。即,如果存在三个同时要被冲洗的分支,则头部将减量3。当头部等于尾部时,将不再存在任何未解决的推测性分支。下文中给出的是4个深度iidx堆栈的示例性图,但是对于5个深度iidx堆栈也适用相同的原理。
图10和11示出了具有4个深度寄存器1002a、1004a、1006a、1008a、1002b、1004b、1006b、1008b的iidx堆栈1000a、1000b。相同的原理适用于其他层数的寄存器,例如5个深度寄存器。
rob
rob812(图8)可以具有以下示例性属性。rob812可以使用触发器(flipflop)来构建。存在64个rob812条目,其用rob[y]来表示,其中y=0至63。每个条目包括以下示例性字段:
rob[y].spec:当前阶段的推测性位。
rob[y].br_id:分支标识,其指示指令对哪个分支进行推测。
rob[y].busy:指示rob条目忙碌,等待被写入。
rob[y].dstdat.vs:此位指示目的地数据是向量还是标量。
rob[y].dstdat.num:指示寄存器数,其中目的地数据需要被写入rf810。
rob[y].dstdat.dat:包括目的地数据,其可以是向量或标量。
rob[y].dstadr.num:指示寄存器数,其中目的地地址数据需要被写入rf810。这将仅由ld和st指令使用以返回地址更新。也可以用于同样返回布尔值的向量指令。
rob[y].dstadr.dat:包括目的地地址数据,其仅可以是标量。这将仅由ld和st指令使用以返回地址更新。也可以用于同样返回布尔值的向量指令。
图12示出了将rob812条目退回(retire)到rf810的示例性数据过程1200。该示例性过程1200可以示出rob[y].busy=1至rob[y].busy=0的转变。在1202,检查初始状态,并且如果指令数据非推测性,则过程移动到1204,等待rwc814接受指令数据,或如果指令数据是推测性的,则移动到1206。在1210,过程1200等待提交(例如rwc814)以接受,且在1212,指令数据被提交。在1216,过程1200等待bpu806触发冲洗,并且在1214等待提交冲洗。在1208,过程等待rwc814以触发冲洗,并且然后继续到1214。
rwc(rob写压缩器)
rwc814可以具有以下示例性属性。rwc814可以包括用于每个运算或计算资源(cr)的单独的输入fifo,以及lsu816输出(例如可以存在每个cr和rwc814之间的点对点连接)。当cr返回结果数据(如图8中示为dd)时,可以发送到具有相关联的iidc号和rd号的rwc814。iidx号指向rob812中将写入dd值的位置。可以具有到rob812的8小道写入总线,并且也可以具有到所有缓冲区元件(be)的8小道写入广播总线。在该总线上存在额外的带宽以允许快速放空fifo,从而应对可引起fifo填满的资源阻塞。相同数据被广播到rob812和be。
索引保存接口可以是来自于rf810的独热编码信号(例如64位),其可告知rwc814由当前指令输入选择的iidx值。如果这些索引中的任何一个可以匹配被广播到和写入rob812的数据的索引,则rwc814将把那些被指示的iidx值写入到rob812和be,但是也会在之后将这个数据重新广播(例如,在预设的时钟周期),耗尽空闲rwc814带宽。该对数据进行重新广播针对竞争(race)状态进行了保护,在竞争状态下,在从rob812请求相同iidx的同时,数据被广播到各be。例如,可能会有运行中指令错过当前不在be中的被广播的数据。
标量资源缓冲区元件(srbe)
srbe具有以下示例性属性。处理器800可以包括16个srbe,并且每个srbe能够保存例如一条指令。srbe可以以任何顺序被填充。id808块做出能够加载哪个srbe的决策。当输入全都可用时,srbe可以允许无序地排空(drain)。冲洗/接受信号可以由id808发送给srbe。在srbe中的推测性的且匹配清除分支id(brid)的任何等待中指令可以由crd818来使其准备就绪被分派并成为非推测性。当rwc814将被冲洗的srbe指令写入rob812时,对应的iidx将被释放。srbe中的匹配接受brid的任何等待中指令都可成为非推测性的。
向量资源缓冲区元件(vrbe)
vrbe具有以下示例性属性。作为说明性示例,处理器800可以包括8个vrbe,且每个vrbe可保存例如一条指令。vrbe以任何顺序填充。id808块做出能够加载哪个vrbe的决策。当输入全都可用时,vrbe允许无序地排空。冲洗/接受信号可以由id808发送给vrbe。在vrbe中的推测性的且匹配冲洗brid的任何等待指令可以由crd818来使其准备就绪被分派并成为非推测性。当rwc814将被冲洗的vr指令写入rob812时,对应的iidx将被释放。vrbe中的匹配接受brid的任何等待指令都可以成为非推测性的。
计算或运算资源分派
图13示出了示例性crd1318,其可以包括具有匹配器1322和控制fsm1324的crd控制1320。crd1318也可以具有标量交换矩阵1326和向量交换矩阵1328。crd1318具有脉冲生成器和输出流水线1332。crd1318可以具有以下示例性特性。crd1318可以把数据和指令从m标量队列发送到n标量计算资源。crd1318可以把数据和指令从p向量队列发送到q向量计算资源。crd1318可以操作保守型(conserving)轮叫(round-robin)调度器。调度器顺序地服务具有可被传输的数据的下一队列。标量交换矩阵1326允许任何标量队列元素的内容被发送到任何标量计算资源。向量交换矩阵1328允许任何向量队列元素的内容被发送到任何向量计算资源。当cr准备就绪接收数据时,来自队列元素的数据可以仅被发送到cr。crd818可以生成脉冲,用于将数据发送到计算资源。脉冲生成可以用脉冲生成器1330在内部完成。当数据可用于传输时,脉冲发生器可以是活动的。标量输出总线是广播总线,并且处理器800实现当前可以假设该总线一次广播到5个标量计算资源。广播总线可以代替点对点连接,用于减少电线的数量。向量输出总线是点对点,且直接连接到目标向量计算资源。标量和向量输出总线向输出流水线1332提供数据。在一些示例中,vmac操作可以被允许在一个广播输出总线上发送,其可以例如允许其他广播总线存储2个而非3个128位的寄存器值。
crd1318实现可以基于实例的假设。在被授权的队列之后的周期中,可以不存在在下一个时钟周期上的另一个授权。这可以暗指队列应该被顺序地写入,而不应当总写入相同的队列。当在其队列中剩下一个点时,scr/vcr队列可以发送将满(almostfull)信号。当其满或将满时,就不能向scr/vcr发送数据。将满信号可能要用一个周期来进行更新,结果让队列最后变成满。crd1318可以向scr/vcr队列一次发送一个元素。用于确定指令的计算资源的类型的分类可以在将指令发送到crd1318之前在crd1318之外执行。
加载存储单元
图14示出了从rob812和rwc814(图8)接收数据的示例性lsu1416。还将参考图8作为各种组件之间的交互的说明性示例。lsu1416可以具有以下属性。lsu1416可以包含16个ld缓冲区元件(ldbe),其中每个ldbe可以保存一个指令。vrbe以任何顺序填充。id808块做出能够加载哪个ldbe的决策。当输入全都可用时,ldbe允许无序地排空。
可有两个加载alu,每个对应两个加载端口中的一个。每个加载alu可以向具有相关联的iidx的rwc814返回地址更新。当前或更新的地址可以在对dmemif的加载请求中使用。加载数据可以经由dmemif返回,并且可以被发送到具有其相关联的iidx的rwc814。
加载/存储地址冲突由lsu1416检查。如果加载地址与任何未决的store地址匹配,则加载停止。一旦store被发送到dmem并且不再是未决时,则地址冲突被移除,load将被允许继续。
lsu包含16个st缓冲区缓冲区元件(stbe),其中每个stbe可以保存一条指令。stbe按顺序填充。何时加载stbe的决策由id808块做出。当输入全部可用且不是推测性时,stbe按顺序排空。
对于一个存储端口,有一个存储alu。每个存储alu向具有其相关联的iidx的rwc814返回地址更新。当前或更新的地址将在对dmemif的存储请求中使用。
冲洗/接受信号被发送到lsu1416内的ldbe。可以使ldbe中匹配冲洗brid的任何等待中指令就绪,可以绕过dmem加载并且利用垃圾(garbage)地址更新和结果数据返回到rwc814。当rwc814将冲洗的ld指令写入rob812时,对应的iidx将被释放。ldbe中的匹配接受brid的任何等待指令都可以被设为非推测性的。
冲洗/接受信号被发送到lsu1416内的stbe。可以使stbe中匹配冲洗brid的任何等待中指令就绪,可以绕过dmem存储并且利用垃圾地址更新数据返回到rwc814。当rwc814将冲洗的st指令写入rob时,对应的iidx将被释放。stbe中的匹配接受brid的任何等待指令都可以被设为非推测性的。
状态寄存器
存在用于控制处理器内的唯一功能的各种处理器和硬件状态寄存器。
cbegin寄存器保存循环寻址模式的起始地址指针。cend寄存器保存循环寻址模式的结束地址指针。各种各样的寄存器可用于窗口溢出检测、调用增量、旧窗口基址(oldwindowbase)、特权级别、用户向量模式、异常模式和中断级别功能性。
当前窗口溢出启用寄存器可以限定当前是否启用窗口溢出异常。当前循环启用寄存器可以限定当前是否启用硬件循环指令回环(loopback)功能。
另外的示例性寄存器包括:由硬件循环控制逻辑使用的循环开始地址指针,以支持两层硬件循环嵌套;由硬件循环控制逻辑使用的循环结束地址指针以支持两层硬件循环嵌套;由硬件循环控制逻辑使用的循环计数以支持两层硬件循环嵌套;窗口基址寄存器,其保存应用于regfile读取的当前偏移;窗口开始寄存器,其中每一位表示sr寄存器的状态。
计算资源状态寄存器可以用于控制cr内的唯一功能。
数据存储器访问
数据存储器访问可以具有以下示例性属性。数据存储器访问可以有两个加载端口,在其中将加载放入流水线。数据存储器访问可以具有一个写入端口。
bpu和推测性操作
分支指令(例如,操纵程序计数器的指令)被顺序放置到四个分支处理缓冲区缓冲区元件(bpbe)之一中。在任何时候在bpbe中可以有最多四个未决(即,未解决的)分支指令。如果id808中有更多的分支指令,它们将保持在那里,直到在bpbe中开辟了空闲位置。在分支预测过程需要的情况下,bpu806可观察bpbe中的所有指令。
对于无条件分支指令,分支指令之后和在新目标分支地址取出的指令之前的所有指令将在id808块中被丢弃。无条件分支不使用分支目标缓冲区(btb)中的条目。条件分支使用btb和分支预测。当检测到条件分支时,在目标地址(如果采用分支)和顺序地址(如果不采用分支)之间进行分支预测和btb选择。程序流继续在这个新地址获取指令。直到分支条件被解决之前,这些新指令现在都是“推测性的”。对于该示例性实施例,bpu806允许最多四层推测,这意味着存在四个未解决的分支指令。
对于未决分支,需要解决的结果可能无序地发生。bpu806可以用信号按序发送特定分支的“冲洗”或“接受”。bpu806可以存储顺序地址,以免分支被错误地采用;因此在冲洗之后程序可以在正确的地址快速重新开始。
处理器还可以实现高速缓冲区行为、跟踪端口、核心间通信端口和片上调试的功能性。
异常和中断
一旦解决了所有未决的分支,返回地址就是非推测地址,也就可以对异常和中断提供服务。当检测到启用的异常/中断时:如果存在至少一个未决的分支指令(处理器处于推测性状态)并且另一分支指令被解码,则id块将停止分派。未决的分支指令必须有时间来解决,而没有其他分支指令引发进一步的推测。一旦所有未决的分支已经解决并且处理器不再是推测性的,则当前pc的返回地址将被保存到整数返回寄存器,并且中断向量的目标地址将被发送到imem。rti(中断返回)指令将使该整数返回值作为下一个pc值发送到imem。
数据流概述
图15示出了作为说明性示例实施例的过程1500的流程图。只要ififo未满,就从imem接口一次获取多个指令到ififo块。作为示例,一次获取四条指令。
指令要求“不忙”的源数据和可用的资源对该源数据进行操作。当资源完成其操作时,其输出目的地数据。寄存器源(rs)值在regfile上寻址并指向数据源(ds)值。图15指示r和p以及其他参考字母。
寄存器目的地(rd)值在regfile中寻址出需要最终写入特定资源数据目的地(dd)的位置。rd和dd首先由资源(通过rwc)写入rob中iidx指向的位置。rob条目还包含rob忙碌(brb)位、提交(c)位和推测性(s)位。
一旦指令可以提交,dd就被写入regfile的地址rd。例如,如果指令不忙、没有仍处于推测性状态的分支、而且是最早的iidx值,则可以提交指令。例如,对regfile的处理器写入是非推测性且按指令顺序的。在一些示例中,提交的数据可以用于st指令。例如,加载指令输出两个数据rd0和rd1。
来自ififo的指令被预解码为分支、加载、存储、标量计算资源(scr)或向量计算资源(vcr)指令。vcr指令进一步分类为vmac和非vmac。例如,vmac指令可能需要最多三个128位输入。
一旦分类,id可以基于以下示例,将单独的指令移出到regfile。如果有一个空闲的rob索引(iidx)分配给该指令。如果在分类的缓冲区缓冲区元件中有空间,即如果这是向量计算指令,则检查vrbe中是否存在空闲缓冲区缓冲区元件。一旦由id确定指令可以移动到空闲缓冲区缓冲区元件,则指令将从id,通过regfile,通过rob流向缓冲区缓冲区元件,而不停止。
对于使用绝对立即目标地址的无条件分支指令,信息被直接传递到bpu或bpbe,以允许将需要被id块丢弃的指令(例如,四个指令)发生快速分支。例如,这可以是当具有无条件分支的四元被预解码时的运行中的四个指令。对四元组指令的提及仅是说明性示例。
当指令在id块中时,rsx和rdx值按窗口基址量提取并更新。对于该说明性示例,三个输入s/vmac指令必须是四元组中的第四个指令,因为instr3通道支持读取三个128位输入。在rdx指向的regfile条目中,regfile忙碌(brf)位被声明,并且iidx字段被更新。iidx指向rob中最终需要由cr写入rd数据(dd)的条目。iidx是表示rob条目0到63的六位值。iidx[5:0]具有到rob的一对一映射。
iidx/rob的大小反映了在任何时候可以处于运行中的指令的总数。这可以意味着rob中的“空闲”条目,因此“空闲”iidx号,可用于分配给正在发出的指令。
如果rob中的所有条目仍然忙碌,则指令获取将停止,直到存在至少四个空闲条目。在regfile块中检查每个rsx,以确定它是否忙碌。rsx可以在regfile中忙碌,但在rob中不忙,而分支仍然是推测性的,或在rd处于rob中并等待被提交到regfile的非推测时间内。如果rsx不忙,则将指令操作码位加上所需的rsx数据(dsx)传递给rob。如果rsx忙碌,如brf位所指示,可能会发生以下示例性功能。
返回存储在regfile中的iidx号,其指向rob中寻找rsx的位置。该iidx号也被发送到rwc以免出现竞争状况。指令操作码位加上此iidx号被传递给rob。如果iidx指向的rob条目不忙,则数据将被读取并作为rob的输出提供(与操作码一起)传递到id块。如果ridx指向的rob条目忙碌,则操作码和iidx将作为rob的输出。
在图15的流程图中,pdsx指向指针/数据,并且是从regfile传递到rob和从rob传递到缓冲区缓冲区元件中的内容。pdsx中的一个额外位告诉逻辑其中包含的是指针还是数据。当在rob中请求输入时,这也触发从rob到regfile的需提交的任何条目的写入。一旦提交,一个条目将在下面的周期中退回,以避免从regfile读取刚提交的值出现竞争状况。当指令流过rob时,包含分支处理、加载、存储、标量资源和向量资源缓冲区缓冲区元件内的单元的标识(bpube、ldbe、stbe、srbe、vrbe)。这允许将指令从rob广播到缓冲区缓冲区元件。
如果有可用空间,则分支指令按序推入bpbe并等待其输入。对于该示例,在任何时间在bpbe中可以有最多四个未决(即,未解决的)分支指令。如果id中有更多的分支指令,将留在那里,直到在bpbe中开辟了空闲位置。在分支预测过程需要的情况下,bpu可观察bpbe中的所有指令。
如果有可用空间,则加载指令以任意顺序被推入ldbe。如果与存储指令没有地址冲突,则lsu可以观察ldbe中的所有指令,以允许乱序的dmem加载访问。
对于加载,操作码、rd和iidx可以与两个pdsx值一起推入ldbe。当pdsx中的地址元素可用时,将计算dmem地址,并且如果与先前的挂起存储没有地址冲突,则将执行加载。
来自加载指令的地址输出(iidx,rd1和dd1)可以被发送到rwc以被写入rob,而不等待加载数据返回。当dmem加载数据返回时,iidx、rd0和dd0将被发送到rwc以写入rob。所有存储指令按顺序推入stbe。
对于存储,操作码、rd和iidx与三个pdsx值一起被推入stbe:两个pdsx值用于计算存储地址,一个pdsx值用于存储数据。当pdsx中的地址元素可用时,可以计算dmem地址并且可以执行存储。
来自存储指令的地址输出(iidx、rd1和dd1)可以被发送到rwc以被写入rob。所有向量资源指令以任何顺序推入vrbe。所有标量资源指令以任何顺序推入,首先推入srbe,如果srbe已满,则推入vrbe。标量输入数据可以存储在128位向量寄存器的32个最低有效位(lsbs)中。
缓冲区缓冲区元件(在bpbe,ldbe,stbe,srbe和vrbe中)中的受阻指令输入可以单独监视rwc广播总线,以监测何时广播具有所需iidx的数据。这可能是受阻的输入所需的数据。该广播数据可以被锁存。一旦指令具有其所有输入,就可以被移动到计算资源。
从regfile发送到rwc的“索引保留”信息确保缓冲区缓冲区元件不会错过具有匹配iidx的数据的广播。crd监视srbe和vrbe的状态,以了解什么时候拉出指令并推入crfifo。例如,如果在vrbey中有vcrx指令在等待,并且vcrxfifo未满,则crd将读取vrbey,设置vrbey可用,并将指令写入vcrxfifo。
当指令具有其所有输入并被分派到计算资源(cr)时,会将操作码、iidx号和dsx值传给cr。
当cr返回结果数据dd时,可以发送到具有相关iidx号的rwc。iidx号指向rob中将写入dd值的位置。在存在等待该数据的指令的情况下,rwc可以将来自cr的数据广播回缓冲区缓冲区元件。
对于这个例子,一旦指令可以被提交,dd就在地址rd被写入regfile,意味着数据在rob中,并且索引不是推测性的。dd可用于被其他指令从rob推测性地读取。
在分支的情况下,记录分支iidx,并且在rob的结果中,凡iidx大于所记录的分支iidx的,都被标记为“推测性的”,并且不能被提交(写入)到regfile。该推测性数据可用于其他指令作为输入,但是这些指令输出也将是推测性的,并且在rob内被标记为推测性的。
以下示例可以描述分支何时被解决。如果分支被正确预测,在推测性数据是有效的,并且可以被提交到regfile。在等待提交时,数据仍然可以用作新指令的输入,并且这些新指令输出数据可以不再是推测性的。
如果分支被不正确地预测,推测性数据是无效的并且必须从rob冲洗。通过将rob中的读指针移动到下一个非推测性位置,使“冲洗”发生。
寄存器开窗口
图16示出根据一些实施例的实现开窗口的硬件寄存器的示例性示意图。标量寄存器(sr)寄存器文件包含64个32位寄存器(sr0-sr63)。sr寄存器文件配置有16个寄存器访问窗口。寄存器开窗口是通过减少保存和恢复寄存器的需要来在函数调用之间管理寄存器的有效方式。函数调用可以按4、8或12个寄存器旋转寄存器窗口,其中该旋转增量包含在调用操作码中。总是与先前的寄存器窗口重叠,使得函数参数和返回值可以在重叠寄存器中传递。当旋转寄存器窗口时,新窗口可能从63绕回到0,这导致窗口溢出异常。溢出的寄存器需要转储到堆栈,然后子例程方可继续。当从有寄存器转储到堆栈的子例程返回时,这些寄存器必须在跳转到返回地址之前恢复。
当窗口溢出1604发生时,生成必须将溢出的寄存器转储到转储堆栈的异常。被转储的寄存器的窗口起始位1602清0,这指示当从子例程调用返回时,必须从堆栈转储堆栈恢复这些寄存器。
这些是用于寄存器窗口控制的两个示例性硬件寄存器:(1)windowbase[6:0]寄存器1606保存有硬件在给定窗口内访问正确sr寄存器所需的偏移值。例如,如果windowbase[6:0]=52,则sr1实际上是sr(1+52)=sr53;和(2)windowbase1602寄存器是64位寄存器,其中每个位表示对应sr是否转储到堆栈。
对于图16所示的示例,当使用寄存器开窗口时,以下示例性假设的做出涉及在当前16寄存器窗口内使用sr寄存器:当前窗口的sr0保存当前增量值和返回地址。当前窗口的sr1必须保存当前堆栈指针(stkptr)。
寄存器窗口有三个增量,可以使用call4/x4、call8/x8和call12/x12分别以4、8和12的增量来实现。标记“x”表示目标地址来自寄存器,而无“x”表示目标地址来自当前pc加上立即偏移的和。
calln指令设置ps.incr位设置为“n”,这是4种状态之一:0、4、8或12(ps=杂项程序状态寄存器)。ps.incr稍后可以由entry指令使用,entry指令必须是被调用的子例程执行的第一条指令。calln指令将calln后的指令的增量n和返回地址写入sr(0+n)寄存器,然后处理器跳转到目标地址。例如,call4将保存增量4和返回地址到sr4,然后跳转到目标地址。当entry指令执行后窗口旋转时,增量和返回地址将保留在新窗口的sr0中。
如本文所述,entry是用call4/x4、call8/x8和call12/x12调用的所有子例程的第一条指令。该指令不被由call0/x0调用的子例程所使用。示例性entry指令执行以下操作:
使用当前的windowbase[6:0],从sr1读取stkptrcur。更新stkptrnxt=stkptrcur-immediate_frame_size。
用ps.incr中的量更新新的windowbase[6:0]。
使用新的windowbase[6:0],将stkptrnxt写入sr1。
检查有无windowoverflowexception。
windowend[6:0]=windowbase[6:0]+16
如果windowend[6]=1,则窗口已溢出。
如果没有溢出,继续执行子例程中的指令。
如果溢出:
将entry之后的指令的pc保存到epc(异常pc寄存器)
跳转到windowoverflowexception(n)处理程序,其中n是4、8或12。
示例性windowoverflowexception处理程序执行以下操作:
从sr1读取当前stkptr。
如果windowoverflowexception(4)
需要检查前一窗口外部的低位4个寄存器。这些低位4个寄存器将是sr12..sr15
创建windowbaseplus12...windowbaseplus15
如果windowbaseplus12[6]=1,则sr12转储到stkptr指向的堆栈,并清除windowstart[windowbaseplus12]位
…
如果windowbaseplus15[6]=1,则sr15转储到stkptr指向的堆栈,并清除windowstart[windowbaseplus15]位
如果windowoverflowexception(8)
需要检查前一窗口外部的低位8个寄存器。这些低位8个寄存器将是sr8..sr15
创建windowbaseplus8...windowbaseplus15
如果windowbaseplus8[6]=1,则sr8转储到stkptr指向的堆栈,并清除windowstart[windowbaseplus8]位
…
如果windowbaseplu15[6]=1,则sr15转储到stkptr指向的堆栈,并清除windowstart[windowbaseplus15]位
如果windowoverflowexception(12)
需要检查前一窗口外部的低位12个寄存器。这些低位12个寄存器将是sr4..sr15
创建windowbaseplus4...windowbaseplus15
如果windowbaseplus4[6]=1,则sr4转储到stkptr指向的堆栈,并清除windowstart[windowbaseplus4]位
…
如果windowbaseplus15[6]=1,则sr15转储到stkptr指向的堆栈,并清除windowstart[windowbaseplus15]位
执行rfwo-从窗口溢出返回
跳转到epc指向的地址
retw从由call4/x4、call8/x8和call12/x12调用的并且具有entry作为第一条指令的子例程返回。retw执行以下操作:
retw使用sr0[29:0]作为返回地址的低30位,并用retw指令的pc地址的位31和30作为返回地址的高2位。sr0[31:30]表示用于获取当前windowbase的窗口增量。
检查是否有任何寄存器被转储:
如果sr0[31:30]=1=增量为4
检查windowstart[windowbaseplus12...windowbaseplus15]位以查看是否清除了某些位。
如果sr0[31:30]=2=增量为8
检查windowstart[windowbaseplus8...windowbaseplus15]位以查看是否清除了某些位。
如果sr0[31:30]=3=增量为12
检查windowstart[windowbaseplus8...windowbaseplus15]位以查看是否清除了某些位。
如果没有任何寄存器被转储(即所有位都设置为1),则retw执行以下操作:
从windowbase中减去该增量。
跳转到返回pc地址。
如果有任何寄存器被转储,执行以下操作:
将retw指令的pc地址保存到epc。当返回到windowunderflowexception(n)处理程序时,处理器将重新执行retw指令。
使用增量“n”跳转到正确的windowunderflowexception(n)处理程序。
windowunderflowexception处理程序执行以下操作:
从sr1读取当前stkptr。
如果windowunderflowexception(4)
需要检查前一窗口外部的低位4个寄存器。这些低位4个寄存器将是sr12..sr15
创建windowbaseplus12...windowbaseplus15
如果windowstart[windowbaseplus12]=0,则从stkptr指向堆栈的堆栈恢复sr12,并设置windowstart[windowbaseplus12]位为1.
…
如果windowstart[windowbaseplus15]=0,则从stkptr指向堆栈的堆栈恢复sr15,并设置windowstart[windowbaseplus15]位为1.
如果windowunderflowexception(8)
需要检查前一窗口外部的低位8个寄存器。这些低位8个寄存器将是sr8..sr15
创建windowbaseplus8...windowbaseplus15
如果windowstart[windowbaseplus8]=0,则从stkptr指向堆栈的堆栈恢复sr8,并设置windowstart[windowbaseplus8]位为1。
…
如果windowstart[windowbaseplus15]=0,则从stkptr指向堆栈的堆栈恢复sr15,并设置windowstart[windowbaseplus15]位为1。
如果windowunderflowexception(12)
需要检查前一窗口外部的低位12个寄存器。这些低位12个寄存器将是sr4..sr15
创建windowbaseplus4...windowbaseplus15
如果windowstart[windowbaseplus4]=0,则从stkptr指向堆栈的堆栈恢复sr4,并设置windowstart[windowbaseplus4]位为1.
…
如果windowstart[windowbaseplus15]=0,则从stkptr指向堆栈的堆栈恢复sr15,并设置windowstart[windowbaseplus15]位为1.
执行rfwu-从窗口下溢返回
跳转到epc指向的地址,其跳转回retw指令。现在将完成retw而无异常出现。
这是示例性说明,并且可以使用其他变型来实现本文所描述的开窗口技术。
冲洗
冲洗操作可以具有以下示例性属性。id观察rob的状态,并通过停止获取来确保存在的推测性指令不超过32条。bpu按序解决分支,一次接受一个分支,并一次性冲洗所需的多个分支。rf中的iidx堆栈确保iidx在接受和冲洗操作期间得到适当处理。id块处理对未解决的分支的数量的跟踪记录,将条件分支后跟随的指令标记为推测性的,并且添加id.brid(分支id)以指示指令相关联的是4个分支级别中的哪一个。
以下提供说明性示例。前面的“rdiidx堆栈”部分包含类似代码序列的说明。
假设
无未解决的分支
rob索引由id挑选并由iidx表示
rdnum=寄存器目的地编号
为了简单起见,这里没有示出ld的地址更新
r5=r2+r3
在id中,向指令附加:iidx=1;spec=0;brid=dontcare
在rf的r5:busy=1;iidx=1
在rob[1]:spec=0;brid=dontcare;rdnum=5
…
ldr4
在id中,向指令附加:iidx=3;spec=0;brid=dontcare
在r4的rf:busy=1;iidx=3
在rob[3]:spec=0;brid=dontcare;rdnum=4
brr4<r6
在id中,向指令附加:iidx=4;spec=0;brid=dontcare;branch=1
在rf中,由于输入r4忙碌,返回指针iidx=3,其指向r4将最终写入rob的位置。
由于branch=1,将iidx堆栈的头部增量1,将尾部内容复制到头部
设置curbrid=0
在rob[3]处:spec=0;brid=dontcare
后续指令将设置为推测性,同时brid=0
…
r5=r2+r3
在id中,向指令附加:iidx=7;spec=1;brid=0
在r5的rf:busy=1;iidx=7
iidx堆栈头部已增量,因此前一iidx=1保存在尾部。头部现在指向iidx=7
在rob[7]:spec=1;brid=0;rdnum=5
…
brr5<r7
在id中,向指令附加:iidx=9;spec=1;brid=0;branch=1
在rf中,由于输入r5忙,返回指针iidx=7,其指向最当前的r5将最终写入rob的位置。
由于branch=1,将iidx堆栈的头部增量1,将尾部内容复制到头部
设置curbrid=1
在rob[9]处:spec=1;brid=0
后续指令将设置为推测性,同时brid=1
…
r5=r2+r3
在id中,向指令附加:iidx=11;spec=1;brid=1
在r5的rf:busy=1;iidx=11
iidx堆栈头部已增量,因此前一iidx=7被保存在头部下一位(onebelow)。头部现在指向iidx=11
在rob[11]:spec=1;brid=1;rdnum=5
…
ldr2
在id中,向指令附加:iidx=13;spec=1;brid=1
在r2的rf:busy=1;iidx=13
在rob[13]:spec=1;brid=1;rdnum=2
brr2<r7
在id中,向指令附加:iidx=14;spec=1;brid=1;branch=1
在rf中,由于输入r2忙碌,返回指针iidx=13,其指向r2将最终写入rob的位置。
由于branch=1,将iidx堆栈的头部增量1,将尾部内容复制到头部
设置curbrid=2
在rob[14]处:spec=1;brid=1
后续指令将设置为推测性,同时brid=2
…
r5=r12+r13
在id中,向指令附加:iidx=17;spec=1;brid=2
在r5的rf:busy=1;iidx=17
iidx堆栈头部已增量,因此前一iidx=11被保存在头部下位(below)。头部现在指向iidx=17
在rob[17]:spec=1;brid=2;rdnum=5
…
在某个时间点,iidx=1的r5被写入rob并提交给rf。由于对于r5,尾部指向iidx=1,所以允许写。尾部不移动。
…
在iidx=20,brid=0被解决为已接受
在id中,接受brid=0被发送到rf/rob/be
在rf中,尾部增量1。对于r5,尾部现在指向iidx=7。
在rob和be中,为brid=0的所有条目设置spec=0
在iidx=30,brid=1被解决为已冲洗,这意味着brid=2也需要冲洗。在id中,brid=1和brid=2的冲洗被发送到rf/rob/be
在rf中,因为有2个分支被冲洗,头部减量2。对于r5,头部现在等于尾部,头部/尾部,现在指向iidx=7。
在rob中,对于具有brid=1或brid=2的所有条目,设置spec=0和flush=1
在be中,对于具有brid=1或brid=2的所有条目,设置spec=0和ready=1
ld/st冲突
存储是通过寄存器写入提交的数据的示例。例如,提交的数据可以用于st指令这项要求可能不足以得出使用提交的数据(寄存器内容)的st指令被提交的事实。存储指令可以使用来自rwc的尚未写入寄存器文件的数据,然后将它们写入存储器。这也是存储-提交。如果地址-rob被合并到数据-rob中,则rob实际上起到存储队列的作用,其中按照iidx存储着存储有效地址。如果ld的有效地址与存储队列中的任何未决的存储指令的有效地址不冲突,则ld可以是推测性的和乱序的。
在一些示例中,可以使用ld/st而不是move指令来交换ar(标量寄存器)和vr(向量寄存器)。下面提供了一个示例:
sv128vr7,r3;//(*r3)=vr7;
ldr7,r4;//r7=(*r4);r4=r3+3;
该示例可以将vr7的第三小道移动到r7。rob会检测ld/st冲突,使得在st完成之前ld不会被发送到存储器。流水线被停止。然而,如果ld是推测性的,并且st数据在rob中,则rob简单地将要存储的128位数据的第三通道返回到r7。
示例性处理器
图17示出了根据一些实施例的示例性处理器的示意图。作为说明性示例,数字信号处理器1700可以是具有低功率技术的高性能异步risc处理器以提供高性能处理单元。例如,处理器1700可以在多核配置中使用,其中程序被划分为多个进程,每个进程在处理器1700上运行。
在一些示例性实施例中,系统可以将许多处理器1700集成到同一asic中。照此,系统可以创建强大的多核soc以满足系统要求。处理器1700架构可以提供网格连接的网络。
编译器的效率和开发与指令集和处理器架构紧密相关。处理器1700架构可用于开发高效编译器。
处理器1700通过其csr接口1702、连接到共享存储器(dmem)的dmem接口1704和外部输入中断与外部代理交互。初始化期间程序指令通过csr接口1702被写入imem1708。在任何时间,可以使用dma传输将程序所需的输入数据加载到共享dmem1706,以从核心加载和存储的方式可被访问。由程序生成的输出数据经由共享dmem1706离开处理器1700。指令按顺序经过评估1720、执行1730和终止1740阶段。评估阶段从imem1708获取指令。从本地数据存储器1704或控制和状态寄存器1712收集所有必要的输入操作数,以便执行指令。当推测被解决并且结果(如果有的话)被写入数据存储器或目的地寄存器时,指令将退回(终止)。
从由sbm分派到exm直到终止,指令被认为是在运行中。从被指定给指令直到被提交到ir或vr,临时寄存器被认为是在运行中。
术语“队列中”可以用于描述指令从被记分板单元分派到cr队列开始直到离开exm中的预获取缓冲区为止的状态。整数寄存器(ir)可以是用于整数值的32位寄存器。术语“使用中”可以用于描述资源从被记分板单元分配开始直到被释放的时间为止的状态。“推测性”指令是可以引起冲洗或异常的指令。“事务处理”可以是检查特定条件被满足的动作、向脉冲发生器请求脉冲以及向下游发送源同步数据和时钟。“向量寄存器”(vr)可以是易失性的128位寄存器保存。vr可以包含不同的值,例如32位浮点值、8x16位固定或浮点值、4x32位固定值或浮点值等。
以下可以用于描述不同大小的数据。“半字节”指4位:“字节(b)”指8位;“半字(hw)”指16位;“字(w)”指32位;双字(dw)“”指64位;“千字节(kb)”指1024字节(或8192位)。
处理器1700可以支持机器级特权,包括指令访问csreg、中断管理指令、以及用于陷阱、计时器和中断支持的csr控制和状态字段。例如,处理器1700可以具有64kb(tbd)指令存储器和256kb(tbd)数据存储器,并且存储器可以是字节寻址和低位优先。处理器1700可以支持各种寄存器类型。例如,处理器1700可以支持32个32位整数寄存器(ir)、32个32位浮点寄存器,其中vr的位[31:0]支持浮点寄存器;32个128位向量寄存器(vr),其中vr是保存浮点、定点或整数值的simd寄存器;以及控制和状态寄存器(csr)1712。
处理器1700可以支持精度异常(preciseexception)和中断以及单步调试并且提供处理器1700的可观察状态。
示例使用模型
处理器1700可以是可以在多核配置中使用的高性能、高能效的信号处理核心。
在示例应用中,处理器1700在集群内实例化,其使用共享数据存储器来控制和促进到集群内的处理器1700的数据移动和来自集群内的处理器1700的数据移动。多个集群构成一个组,并且多个组可以互连以提供处理核心的网格。消息、dma和路由器引擎可以允许处理器1700之间的完全连接性。
指令生命周期
指令从imem1708进入处理器1700。指令在初始化期间通过csr接口1702加载到imem1708。imem1708的内容在程序执行期间不改变。一旦imem1708被加载,处理器1700可以被配置为通过配置寄存器开始启动。
一旦启用,处理器1700变得自主并且执行程序。当启用时,除了调试模式,imem1708和dmem1706内容之外,处理器1700配置寄存器可以用csr读和写指令或通过csr接口1702修改。一旦被禁用,处理器1700可以停止获取新指令。处理器1700活动状态确认核心何时空闲。
在处理器1700内,指令经历其生命周期的三个阶段:评估1720、执行1740和终止1730。可以使用评估和终止单元(etm)1742以及其他组件来实现评估阶段1720和终止1730。执行阶段1740可以使用执行单元(exam)1744以及其他组件来实现。这些将在本文中详细描述。
评估
当从imem1708获取指令时,指令的生命开始。生命周期的第一阶段是评估。在该阶段期间,执行以下示例性功能:从imem1708取指令;程序计数器管理;指令评估,以进行指令操作码解码,并得到输入操作数的寄存器id、输出目的地寄存器id、整数或向量操作、分支和跳转功能;以及资源分配。当指令所需的所有资源都准备就绪时,指令离开评估阶段。因此,处理器1700可以具有评估单元(例如etm1742),其带有用于实现评估阶段1720的各方面的各种组件。
执行
一旦指令被评估,就可以被分派到执行阶段。在处理器1700内存在用于不同类型的指令的各种类型的执行单元。它们可以分为不同的类别:整数、向量、分支,跳转/系统和加载/存储。整数执行单元处理所有整数指令以及位操作指令。向量单元执行所有单指令多数据(simd)指令以及整数和浮点格式之间的转换指令。分支和跳转单元处理所有可能影响程序计数器的条件和无条件指令。加载/存储执行单元处理与dmem相关的加载和存储指令。
处理器1700中的指令执行可以是推测性的。这意味着可以在程序的状态完全解决之前计算和获得结果。一旦所有输入就绪,处理器1700执行单元对操作数进行操作。执行的结果临时存储在每个执行单元内的本地存储器中。根据推测性指令的解决,指令的结果可以继续到终止阶段,或者可以在不改变寄存器或数据存储器内容的情况下被丢弃。因此,处理器1700可以具有执行单元(例如,exm1744),其带有用于实现执行阶段1740的各方面的各种组件。
终止
处理器内的指令的最后阶段是终止。指令可以以几种方式终止。例如,当推测性决定被解决为不正确时,可以终止指令。在这种情况下,执行指令的结果将被丢弃。作为另一示例,对于解决了推测的指令,当来自执行单元的临时结果被移动到软件可见寄存器,即整数寄存器(ir)或向量寄存器(vr)中时,指令被终止。浮点寄存器是vr的子集。在具有正确推测的存储指令的情况下,当存储数据被发送到dmem时,指令终止。当分支或跳转决定被解决时,分支/跳转指令终止。寄存器为了跳转指令而发生更新。因此,处理器1700可以具有终止单元(例如etm1742),其带有用于实现评估阶段的各方面的各种组件。
指令集
处理器1700支持不同的示例性指令。处理器1700支持向量化浮点指令,其中并行处理多个浮点操作数。使用向量资源和计算单元的子集来执行浮点指令。
存储器
嵌入在处理器中的主存储器有二:指令存储器(imem)1708和包括本地dmem170和共享dmem1706(具有访问端口和共享dmemdma接口1704)的数据存储器(dmem)。
在核心初始化阶段期间,imem1708和dmem(本地dmem170和共享dmem1706)可以由外部代理通过处理器csr接口1702访问。一旦启用核心操作,存储器读取和写入端口专用于程序执行。如果核心是空闲的,则存储器内容通过csr接口1702保持可用。
指令存储器
处理器1700具有专用imem1708。imem1708中的指令被认为是静态的。对imem1708的访问与32位字边界地址对齐。对于大小64kb(tbd)的imem,最大处理器1700程序长度例如是16k32位指令。imem1708可以支持对64位对齐地址的64位数据读取或写访问。
数据存储器
处理器1700支持两个不同的dmem1706/1710端口。处理器1700可以连接到专用便笺式(scratchpad)存储器或本地存储器1710和/或共享存储器1706。共享数据存储器1706允许多个核心之间的数据移动,而本地dmem1710可以用于存储中间计算结果。
处理核心使用加载和存储指令来访问任何数据存储器。高速暂存区和共享存储器的存储器地址有区分。便笺式存储器提供快速、确定性的读取和写入延迟,而共享存储器存取延迟取决于对存储器的多个同时存取请求的仲裁结果,但提供额外的灵活性和共享。
作为示例,dmem1706/1710可以支持对128位对齐地址的128位数据读或写访问,启用16位字节写入支持。
寄存器
处理器1700支持不同的寄存器类型。一个示例是整数寄存器。在一个示例中,处理器1700具有一组32个32位寄存器,称为整数寄存器(ir)。ir是软件可见的,包含31个通用寄存器x1-x31。寄存器x0固定为常数0,不能修改。ir支持例如整数和二进制格式。为了支持simd,处理器1700具有一组32个128位寄存器,称为向量寄存器(vr)。vr是软件可见的,并且被称为v0-v31。vr支持例如半精度浮点、单精度浮点、固定点、整数和二进制格式。软件在使用寄存器时负责vr内容的格式。当处理器1700执行vr作为操作数的指令时,不会检查内容的格式。处理器1700假定内容的格式和指令的格式相符。
vr用作浮点寄存器f0-f31。当用作浮点寄存器时,f0-31寄存器空间是v0-31向量寄存器的最低有效位的叠加。换句话说,对v5的向量加载指令也将覆盖f5的内容;或对f10的浮点加载指令会覆盖v10的32lsb(v10的高96位必须被忽略)。将整数寄存器内容映射到向量寄存器内的任何浮点数据集的新指令被认为是处理器自定义扩展的一部分。
处理器1700实现多个控制和状态寄存器(csr)以配置和控制核心的操作并监视其状态。所有csr字段都是软件可见的,并使用csr指令访问。处理器1700还提供通过其csr接口对这些寄存器的读和写访问。
作为推测性处理器,处理器1700包含临时寄存器,以避免过早地改变软件可见寄存器。临时寄存器对程序不可见,不能由软件指定。这些寄存器的使用由处理器1700内的硬件支配。可以通过调试接口观察临时寄存器。每个执行单元都有自己的一组临时寄存器。在评估阶段期间,处理器1700分配虚拟临时寄存器(vtr)以保存指令的结果。直到被终止之前,该vtr保持与其指令相关联。vtr可以被重新指定给新的指令。虚拟临时寄存器允许处理器1700超额预定(oversubscribe)物理临时寄存器分配。每个虚拟临时寄存器可以用vtrid:1位超额预定id(假设虚拟对物理超额预定是2:1)和物理临时寄存器id唯一地标识。
计时器和监视器(watchdog)
处理器1700支持以下64位计时器:cycle:取指令数,包括推测性指令;time:对应于实际时间时钟的实时时间段的整数值;和instret:核心退回的指令数。
当核心复位时,所有定时器被清零。读取时,计时器不会复位。因此,必须将读取的值与其先前的读取值进行比较,以确定在最近一个观察周期内的事件(cycle,instret)或实时(time)的数量。
处理器1700实现监视计时器以监视核心的活动。监视计时器使用实际时间时钟来增量,其值与可配置阈值进行比较。当监视器值达到阈值时,生成中断。
time和监视计时器可以使用imem时钟的分数版本来跟踪记录时间。有多个时钟除法器比率(1、4、32和128)可用。
监视计时器检测核心中意外的致命状况(如死锁状况)。这旨在由软件周期性地监视,并且其阈值被相应地设置以防止中断。监视器中断被认为是致命的,会被转发到处理器中断输出,以请求来自外部代理的辅助。
异常
异常是在程序运行时发生的非正常状况。当异常发生时,处理器1700立即停止其程序执行并进入异常处理程序子例程。
处理器1700支持精度异常模式。所有异常前的指令都正常执行和终止。处理器1700寄存器状态由这些异常前指令更新。负责异常的指令不被终止,并且要求来自异常处理程序的辅助。在异常之后的任何运行中指令都可以被执行,但不能终止;因此,不改变处理器寄存器状态。
处理器1700支持以下示例异常:dmem地址违规(例如,超出范围、未对齐);imem地址违规(超出范围、未对齐);imem数据完整性违规(ecc错误);非法指令;系统调用指令(scall);系统中断指令(sbreak);和指令陷阱。
“陷阱”是指把与异常相关的信息传输到软件可见寄存器中。检测到异常时会发生陷阱。
指令陷阱
处理器1700处理特定的复杂指令。当这些指令由核心评估时,生成陷阱并调用异常处理程序。
造成陷阱的指令的清单可以是整数除法、浮点除法和浮点平方根。
异常处理程序
异常与指令相关联。处理器1700基于程序执行来按序处理异常。如果多个指令同时生成异常,则只考虑最早的指令。所有其他异常都将被忽略。
当在处理器1700内检测到异常时,程序进入异常处理程序。处理器1700支持可配置机器陷阱向量基地址寄存器,其中保存有异常处理程序的imem位置(程序计数)。
负责异常的指令的存储器地址被保存在机器异常程序计数寄存器中,并且根据异常原因来设置机器原因寄存器。
基于异常的严重性,异常处理程序决定恢复处理器1700操作所需的行动。对于非致命异常,如sbreak,异常处理程序可以在异常pc和4处恢复程序执行。对于致命异常,异常处理程序可以请求外部辅助来重置和重新初始化核心。
中断
中断指的是在处理器1700内部或外部发生的特殊事件。这些事件由错误状况或需要注意的正常的、知会性质的事件引起。与异常相反,中断不与来自正在执行的程序的任何指令相关联。当核心执行被中断时,当前程序计数必须在进入异常处理程序时保留,并在退出时恢复。
中断监视事件(中断源)上的活动,并保存挂起状态,直到中断被服务。异常处理程序的中断服务例程负责识别挂起的中断源、它们的严重程度并处理它们。
处理器1700支持以下中断源:内部中断、外部中断、通用中断)、消息或门铃(来自同一集群中的其他处理器)和门铃状态清除。
门铃状态清除中断(每个门铃一个)可以由源处理器使用,而不是轮询门铃状态,直到它在目的地处理器处被清除。
为了最大的灵活性,所有中断都可以是可屏蔽(maskable)的。中断掩码(mask)不影响中断挂起状态。掩码只是防止挂起的中断触发间接动作(例如进入异常处理程序、解锁wfi指令或更改输出中断状态)。
处理器1700为每个内部中断使用提供专用中断掩码。
例如,核心中断可以停止程序执行并进入异常处理程序。wfi中断可以解锁等待中断(wfi)指令并恢复程序执行。输出中断可以声明处理器输出中断。
核心中断
处理器1700生成内部核心中断信号,其将所有挂起中断与一组掩码组合。核心中断掩码应由软件根据每个中断源的优先级设置。只有高优先级中断才能被允许声明核心中断并调用异常处理程序。
核心中断强制etm指令解码阶段插入标志,并将下一条指令分派给exm分支解决单元。由于在调用异常处理程序时不执行该指令,所以保存了该指令的程序计数。该指令仅在中断服务例程完成且异常处理程序恢复程序执行后才重新评估。
处理器1700评估核心中断并根据机器陷阱向量基址进入异常处理程序例程。当调用异常处理程序时,核心中断由硬件自动屏蔽(使用csr中的全局核心中断掩码),以防止异常处理程序被中断。在退出异常处理程序之前,必须由程序手动重新启用该全局核心中断掩码。
异常处理程序使用机器原因寄存器来确定负责进入异常处理程序例程的事件的类型。如果原因是中断,则异常处理程序将启动其中断服务例程并读取挂起的中断状态,以确定要服务的源。中断服务例程仅清除已被服务的中断,并保留其他挂起中断,以供后续处理。
由于处理器1700提供挂起中断寄存器来确定中断状态,所以原因寄存器的异常代码字段未被使用,并且在中断上总是被设置为全1值(保留)。
被中断标志取代的指令的程序计数被保存在机器异常程序计数寄存器中,且机器原因寄存器用中断标志进行设置。异常处理程序在异常pc处恢复程序执行。异常处理程序保留中断前处理器寄存器上下文,并在退出其例程时恢复该上下文。
输出中断
处理器1700提供输出中断引脚(pin)。该中断引脚使用自己的中断源掩码。如果处理器被停止或死锁,则到期的监视计时器使用此引脚从外部设备或代理请求辅助。不能由在处理器上运行的异常处理程序例程进行本地服务的其他中断源也可以通过相应地设置掩码来激活输出中断引脚。
在核心上运行的异常处理程序将设置软件中断挂起,并激活其在输出中断引脚上的掩码。连接到处理器输出中断信号的设备或代理负责通过csr接口清除挂起的软件中断来清除中断状态。
等待中断
等待中断(wfi)指令用于将处理器1700同步到特定事件。在两个处理器之间的数据传输的场景下,接收方处理器程序将到达wfi指令并停止。当发送方处理器具有就绪数据时,就向接收方处理器发送门铃(中断),从而恢复程序执行。wfi指令还用于在达到软件中断点时将控制转交到调试器。
当核心执行wfi中断时,所有wfi后的指令都将被冲洗,并且核心停止从imem获取新指令。最终,所有wfi前的指令终止,核心变为空闲。处理器创建内部wfi解锁中断信号(具有其自己的一组中断掩码)以解锁核心并恢复指令获取机制。
在执行wfi指令之前,必须设置wfi中断掩码(使用csr写指令),以允许一个(或多个)中断事件解锁核心。
解锁核心的中断源仍然需要由异常处理程序进行服务和清除。因此,核心中断掩码必须最低限度地包括相同的wfi解锁中断源。对wfi指令解锁后,核心进入异常处理程序,挂起中断被清除,程序在wfi指令之后的指令处重新开始。
控制状态寄存器接口
csr接口1702可以访问所有处理器配置、控制和状态寄存器。接口由外部代理(或设备)控制。它主要用于初始化核心和运行调试操作。
接口使用源同步协议。读取或写入请求源自外部代理(控制方)。处理器(从属方)(源同步地)返回寄存器数据,并且分别在读和写访问时更新寄存器内容之一。
术语“csr”可以用于描述csr、自定义处理器配置和控制和状态寄存器
控制和配置单元(ccm)
ccm1714提供用于控制、配置和状态监视的处理器寄存器。ccm1714实现控制和状态寄存器(csr)以及附加的自定义处理器寄存器。那些寄存器可以通过程序的指令进行读写访问。处理器1700经由csr接口1702提供对其控制、配置和状态寄存器空间的访问。ccm1714还处理中断、计时器和计数器逻辑,并且实现几个调试特性。
ccm1714的示例性特性包括:向所述处理器核心和存储器提供复位逻辑;实现多个配置、控制和状态寄存器(csr),包括控制和状态寄存器(csr)和自定义处理器配置以及控制和状态寄存器的子集;对在处理器(内部访问)或外部代理(通过csr接口)上运行的程序提供对csr的读取和写访问;提供对imem的外部读取和写入访问,用于在所述初始化阶段写入所述程序;如果需要,提供对dmem的外部读和写访问以初始化数据存储器;管理中断,计时器和计数器;提供特殊的调试特性和端口;imem和dmem内容只能在核心空闲时修改;通过其csr接口对整数和向量寄存器的读取访问;使用dmem和加载指令来支持对处理器整数和向量寄存器的写访问。
指令存储控制器
图18示出了具有错误位生成单元1802、imem1804、错误检测单元1806以及配置和状态块1808的指令存储控制器(imc)1800的示意图。imc包含的imem1804保存有所有处理器指令。它控制ccm和评估和终止单元(etm)对imem的访问,这些是唯一直接连接到imc1800的单元。存储器和到imc1800的接口也在相同的时钟域上操作。imc1800向imem1804提供一个读取端口和一个写入端口。etm向imc1800发送读取请求以检索指令。imc1800执行从imem1804的双指令获取,一次提供最多两个32位指令。ccm向imc1800发送读取或写入请求,以将指令加载到imem1802中并验证其内容。
imc1800是存储控制器,其允许etm从imem1804提取指令,并允许ccm在imem1804中读取和写入指令。通过处理器的csr接口接收指令并将其传递到imc。imc收集指令并将它们写入imem1804。当指令由核心检索时,为指令添加错误代码位以支持错误检测。
ccm和etm端口可以是相互排斥的。ccm提供配置模式以选择其中一个接口。
imem写访问
用户通过处理器配置接口将指令加载到imem1804。这些指令被imc格式化为对imem1804的写访问。imc仅支持imem1804的静态更新。这意味着当程序正在运行时,imem1804的内容不能被修改。如果用户在程序期间尝试写入imem1804,则处理器行为是不确定的,并且可能导致程序的损坏。
指令获取
etm通过发送对应于程序计数的地址来从imem1804获取指令。地址是64位,对齐到双字边界(地址的低3位总是为零)。imc1800不对从etm接收的地址执行范围或对齐检查。
imc1800对每个读取请求从存储器检索64位数据和相关联的错误代码字。数据包含两个32位指令。位于低32位的指令将在高32位的指令之前执行。
错误检测
在发送到etm或ccm之前,会检查数据完整性的位错误。不执行纠错。当没有发现位错误时,相关的错误代码位将被剥离,并且两个指令被发送到etm而没有错误指示。如果检测到错误,则错误将导致处理器在正常操作中的异常。与错误相关联的imem1804地址被保留。出于调试目的,外部代理可以使用ccm端口读取错误数据。
流控制
imc1800不会对etm施加反向压力。它接受来自etm的所有读请求,并在三个周期后返回相应的读数据。类似地,imc不从etm接收反向压力。当从imem1804检索到指令数据时,imc1800无条件地将其发送到etm。
当处理器空闲时,可以改变imem访问模式。
评估和终止单元(etm)
图19提供具有核心单元192的处理器1900的示意图,该核心单元192具有评估和终止单元(etm)1904、执行单元(exm)1906和ccm1908。etm1904在处理器1900中处理指令生命周期的第一阶段和最后阶段。在寄存器提交控制器(rcc)1916处理指令终止的同时,指令获取和解码单元(ifd)1912和记分板单元(sbm)1914为指令评估阶段实现所需的功能。在一些示例性实施例中,etm1904可以被实现为评估单元和单独的终止单元。
处理器1900实现双指令获取机制。在核心初始化和重置解除声明之后,ifd1912向imem控制器(imc)1906发送读取请求,以从程序计数器的初始值开始读取指令存储器的内容。ifd1912一次获取两条指令,并将它们写入指令fifo(ififo)1910。
在评估阶段期间,对ififo1910的头部处的两个指令进行解码。作为指令解码的一部分,ifd1912为要分配和执行的指令确定资源要求(即所需的计算资源、所需的临时寄存器)。同时,sbm1914将资源可用性通告ifd1912。当在资源要求和资源可用性之间存在匹配时,ifd1912从ififo1910头部的指令束提取两个指令,并将其转发到sbm1914。指令不能独立地发送。
sbm1914是用于处理器核心1904的集中式控制单元,并且负责资源管理、指令依赖性跟踪和指令流控制。当从ifd1912接收到指令束时,sbm1914向每个指令分配指令标签,确定源输入依赖性,分配所需资源,并将解码的指令连同资源使用和流控制信息一起发送到执行单元(exm)1906。
在终止阶段,寄存器提交控制器(rcc)1916向临时寄存器读端口发送提交请求,以将指令结果提交到目的地整数、浮点或向量寄存器。分支和跳转指令在分支推测的冲洗或释放中终止。对于存储(st)指令的情况,指令终止由加载和存储控制器(lsc)处理。bru和lsc功能在执行单元(exm)部分详细说明。
etm包括以下示例性组件。ifd1912执行指令获取、解码和资源可用性检查功能。sbm1914执行资源管理,源输入依赖性跟踪,以及指令流控制和状态更新。rcc1916控制指令结果提交顺序。整数寄存器(ir)是32位通用整数寄存器集。向量寄存器(vr)是128位通用寄存器集,包含低32位处理器中的32位浮点寄存器(fr)。
性能
ifd支持来自imem的双指令。指令分配和执行速率取决于源输入依赖性和指令的资源使用。可以通过编译器优化分配速率(即通过最小化指令间相互依赖性和最大化可用资源的并行使用)。由于处理器的推测性质,即时指令提交速率将根据未决的推测性指令而提高或降低。
示例性功能
etm的评估单元处理以下示例性功能:指令获取和解码;资源管理;源输入依赖性跟踪;到exm的指令分配。
etm的终止单元处理以下示例性功能:整数和向量寄存器提交控制。
指令获取和解码单元(ifd)
图20示出了etm2000的指令获取和解码单元(ifd)2002的示例示意图。ifd2002从imem2004获取指令,对获取的指令进行解码,并且在将指令转发到记分板单元2006之前评估所需资源的可用性。ifd2002包括程序计数器2008、指令fifo(ififo)2010、指令解码器2012和资源匹配逻辑2014。ifd2012还可以包括用于分支支持2016的早期分支预测,其具有用于功能调用支持的返回地址堆栈和用于循环支持的循环预测缓冲区区。
程序计数器
程序计数器2008保存有将从imem2004获取的下一指令束的地址。该地址对应于程序计数。程序计数器2008在复位时被设置为零。当分支/跳转被预测为“已采用”时,程序计数器2008通过由bru2018在冲洗/异常时提供的新目标程序计数或由早期分支检测逻辑在分支/跳转被预测为“采纳”(taken)来进行更新。否则,对于正常指令流,程序计数增量8(imem2004是字节可寻址的)。如果程序计数器2008回滚(rollover),则ifd2002将不产生任何标志或异常。类似地,当程序计数器2008值被bru2018更新时,ifd2002并不对新程序计数执行任何范围检查,并假定bru2018已执行过imem2004范围和对齐检查。
发送到imc(指令存储控制器)的下一个指令地址值总是与双字(dw)边界对齐。当ifd2002从bru2018接收到新的冲洗请求的程序计数在32位边界(但不是与dw对齐)上对齐时,ifd2002会检测到该情况。字对齐的目标程序计数在被发送到imc之前会被转换为dw对齐的存储器地址。
程序计数器2008由imem2004周期时钟计时。然而,由bru2016提供的地址是以时钟脉冲被传送到ifd2002的。该时钟的上升沿指示冲洗请求,并且目标程序计数被重新采样到imem2004时钟域中作为程序计数器2008的新目标地址。例如,这可以使用异步时钟。
wfi(等待中断)指令使处理器停止当前程序执行,并在恢复之前等待外部事件。
当冲洗请求因wfi指令的执行而生成时,bru2016也会以信号通知ifd2002停止获取新指令(wfi_halt信号)。ifd2002将程序计数器2008重新同步到由bru2016提供的新的目标程序计数,并且监视解锁wfi指令的中断。
在检测到中断事件时,指令获取重新开始。如果在调试模式下操作,则指令获取将仅在调试启动信号的上升沿重新开始,由外部调试器通过处理器外部接口控制。
ifd2002支持单步调试模式,该模式在此时获取、评估、执行和终止一条指令。在这种模式下,程序计数器被强制在每次取指令之前等待调试启动信号。
由于imc是双指令获取,所以程序计数器2008增量4,并且基于程序计数器2008的当前值在针对槽#0(使槽#1无效)和针对槽#1(使槽#0无效)的读请求之间交替。
指令获取
直到ififo2010已满,ifd2002向imc发送具有程序计数器的值的读请求。imc响应于每个请求,返回表示两个连续的32位指令(也称为指令束)的64位数据块以及错误标志。如果检测到数据错误,则ifd2002将束中的两条指令均标记为无效,并且将不对这些指令执行任何资源匹配。此外,ifd2002向记分板单元2006发信号,通知有imem数据错误异常。这两条指令以及错误标志将被转发到记分板单元2006,其将向bru2016发送适当的异常请求。
处理器可以预期imem2004中的每个指令束都覆盖(cover)有能够检测存储器内容中的一位或多位错误的错误检测码字。检测到的错误不会更正,并在核心中生成异常。
ifd2002假定imc按顺序处理读请求。发送到imc的程序计数也使用周期性存储器时钟立即存储(即不等待数据返回)到深度8的地址队列中。
由imc(对于较低32位的槽标记为#0,对于较高32位的槽标记为#1)返回的指令束使用周期性存储器时钟存储在深度8的指令队列中。
地址和指令队列一起被称为ififo2010。地址和指令队列共享相同的读指针,但具有独立的写指针。每当指令束传送到记分板单元2006时,公共读指针增量。
ififo
当监视ififo2010满水平时,因为imc将返回指令数据,所以任何运行中的读取请求都被虑及。指令队列必须能够接受任何传入数据而不会溢出。对于ififo2010空水平,仅考虑指令队列。
如果ififo(地址队列)已满,则ifd2002停止向imc发送读请求。类似地,如果ififo2010(指令队列)为空,则ifd2002停止向记分板单元2006发送指令。
当ifd2002向imc发送具有从字对齐存储器地址导出的dw对齐存储器地址(即当从bru2018接收的地址不与dw对齐时)的指令请求时,位于imc响应束的槽#0中的指令在ififo2010中被标记为无效。该指令将不被下游逻辑评估(即不会对位于槽#0中的指令执行资源匹配)。
与指令数据一起,来自地址队列的相关联的程序计数2008也被转发到记分板单元2006。
指令冲洗
当发生程序不连续时,ifd2002从bru2016接收冲洗信号和新程序计数。
当接收到冲洗信号时,ifd2002通过将指令队列的写指针移动到读指针位置来删除ififo2010中的所有指令。地址队列的指针也被重新对齐。
然后,ifd2002将程序计数设置为从bru2018接收的新的目标程序计数,并且立即开始获取新的指令。冲洗后的读请求被添加到地址队列。从在冲洗请求之前启动的任何运行中读取请求接收的指令束均丢弃。只有来自冲洗后读请求的接收的指令数据被存储在指令队列中。
早期分支/跳转检测
为了减少在采纳分支时发生的冲洗惩罚,ifd实施乐早期分支检测(earlybranchdetection,ebd)2016。实质上,ebd2016检测来自imei2004的指令束内的后向分支,并且预测始终采纳后向分支。ebd2016计算所采纳的分支目标地址,并触发程序计数器2008重新同步到新的分支程序计数目的地。分支指令与预测位一起被转发到下游逻辑,该预测位指示分支是预测为采纳(p=1)还是未采纳(p=0)。bru2016评估并确认该预测位,并且仅当早期预测错误时才生成冲洗。bru2016还对分支目标程序计数执行目标程序计数范围和对齐检查。
ebd2016在从imem2004接收指令的时间与将指令写入ififo2010的时间之间引入一个额外的时钟周期延迟。配置字段启用ebd2016。禁用时,将绕过ebd2016。因此,预测位总是为0(不采纳)。
条件分支
ebd2016检查来自imem2004的指令束,并且当两个指令中的任何一个是分支时可以执行以下操作:计算分支目标地址(指令pc+12位偏移量);如果分支是前向分支,则ifd2002预测分支未被采纳,并且程序计数正常增量;如果分支是后向分支,则ifd2002预测分支被采纳,并将程序计数重新同步到分支目标地址;由于检测到的程序不连续性,ifd2002使所有运行中指令获取请求无效。来自无效的获取请求的指令数据在imc接口上接收时被忽略;不发生冲洗,并且已经存储在ififo2010中的指令不会被无效。
ebd2016做出的预测未必总是准确的,因此需要bru2016验证早期预测。为此,ebd2016将预测结果(一位)与指令一起存储。bru2018针对任何不正确的早期预测生成冲洗请求。
返回地址堆栈(ras)
与ebd2016并行地,ifd2002实施了4条目返回地址堆栈(ras)2016,其存储使用jalr和jal指令的过程调用的返回地址(程序计数+4)。对于jal或jalr指令,返回地址在目的地寄存器rd=x1时被推入堆栈。当源寄存器rs1=x1(且目的地寄存器rd=x0)时,返回地址从堆栈弹出。
ras2016允许准确预测过程调用的返回地址和程序计数器的早期重新同步,而无需宝贵的延迟来访问软件可见寄存器以获取返回地址。
ras2016仅提供了评估和执行jal和jalr指令的快速路径,并且不意味着替换过程调用的软件上下文保存和恢复操作。当堆栈满时,堆栈的最早的条目被推出堆栈,以释放空间用于传入新的返回地址。在冲洗时,ras2016被完全清除。如果在堆栈为空时看到具有源寄存器rs1=x1的jalr指令,则绕过ras2016机制,并且bru2018处理该指令。
跳转指令与指示是采纳跳转(p=1)还是不采纳跳转(p=0)的预测位一起被转发到下游逻辑。bru2018评估并确认预测位,并且仅当p=0时才生成冲洗。由于跳转总是导致冲洗,当bru2018看到p=0(跳转未采纳)时,这意味着ras机制未能处理该跳转指令(ras为空)。对于ebd2016,bru2018还对跳转目的地程序计数执行目标程序计数范围和对齐检查。
有配置字段启用ras2016特征。
jal
ras2016逻辑将jal跳转指令视为无条件采纳的分支。jal目的地程序计数总是可以在不访问寄存器的情况下计算出来。程序计数总是与新的跳转目标程序计数(指令pc+20位偏移)重新同步。
bru2018重新计算目标程序计数、验证预测并用返回程序计数更新目的地寄存器。由于在ras2016内没有执行地址范围检查,所以bru2018负责在计算的目标程序计数无效时生成异常。
jalr
jalr指令使用间接寻址进行目标程序计数计算。考虑两种场景。
如果ras2016水平不为空,则会预测跳转被采纳,并将ras2016顶部的返回程序计数视为基址。程序计数器重新同步到基址加上12位偏移(即时值)。
如果ras2016水平为空,则只有满足以下条件才能预测跳转指令被采纳:(1)jalr指令位于指令束内的槽#1中;(2)同一束内的槽#0由lui(加载上部立即)指令或由auipc(添加上部立即)指令占据;和(3)lui/auipc指令的目的地寄存器与jalr源寄存器相同。
如果满足这三个条件,则ras2016使用包含在束的两个槽中的信息来计算jalr指令的跳转目标程序计数。程序计数器将重新同步到该新的目的地程序计数。否则,预测跳转不被采纳,并且由bru2018处理,并且最终将发生冲洗。
对于jal指令,bru2018重新计算目标程序计数,验证预测并用返回程序计数更新目的地寄存器。
循环预测缓冲区
ifd2002实现作为ebd/ras2016的一部分的具有4个条目的缓冲区的循环预测缓冲区(lpb),以存储最近的四个后向分支的存储器地址(指令程序计数)及其目标程序计数。每个条目具有其有效状态。
因为ebd2016预测采纳后向分支,所以由后向分支表示的循环体将在首次被遇到时被输入到lpb中。
如果编译器使用前向分支指令来评估任何循环进入条件,则lpb正确地预测任何循环进入条件。如果编译器使用后向分支指令从循环结束回到循环开始,则lpb正确地预测循环迭代执行(循环退出条件除外)。lpb不能正确地预测环路退出条件。退出循环时可能总是需要冲洗。
在读取请求被发送到imc而不是等待稍后返回的指令数据时,lpb帮助程序计数器2008检测循环条件。当程序计数器值与lpb有效条目之一的指令pc匹配时,程序计数器被重新同步到相关联的目标程序计数。因为循环开始指令在循环结束指令之后立即被获取,所以此过程不需要使任何ififo2010条目无效。
最初,lpb为空。当lpb检测到后向分支时,指令和目标pc被存储在lpb条目之一中。程序计数器与目标pc重新同步,如关于ebd2016所述。
当lpb不为空并且检测到后向分支时,lpb首先检查该指令pc是否已经存在于lpb的有效条目之一中。如果它已经存在,则新地址将不会被写入lpb。否则,它将被写入空的lpb条目之一中。如果所有lpb条目都已经使用了,则当前分支指令替换最早的有效。
在冲洗期间保留所有lpb条目以允许支持循环嵌套。否则,内部循环退出将总是清除任何外部循环指令和目标程序计数的信息。
有配置字段启用lpb功能。
指令解码
解码过程检查输入的有效指令是否符合处理器支持的格式。从ififo2010提取的不符合格式的任何有效指令被声明为非法。对非法指令不执行资源匹配。如果非法指令位于槽#0中,则位于槽#1中的指令被设置为无效,并且不执行资源匹配。如果位于槽#0中的指令合法,但是位于槽#1中的指令非法,则位于槽#0中的指令将被正常地执行。
记分板单元2006负责将非法异常发送到bru2018,并且引发对异常处理程序的调用(具有从程序不连续性而生成的冲洗)。
解码逻辑从每个输入有效指令提取以下信息:8位操作码;最多20位具有有效状态的即时值;最多三个5位源操作数#1,每个都与该有效状态相关联;最多一个具有有效状态的5位目的地操作数。
由于存在多个指令格式,有效状态指示立即、源或目的字段是否有效。
解码逻辑将每个指令分配给以下类别之一:无效指令;非法指令;加载;存储;salu;bru;smul;vmac;valu;vlut;ccm;和nop。指令类别信息连同操作码、即时值和所有源操作数和目的地操作数一起,被转发到记分板单元2006。
使用独热编码将指令类别发送到记分板单元2006。ifd2002还会使用独热编码信号指示该指令是否应该由标量或向量cr执行。
资源匹配
基于指令类别,识别成功执行束内指令所需的资源(指令标签、cr队列、缓冲区、虚拟临时目的地寄存器)。ifd2002首先评估每个槽的每个资源类型的资源要求。ifd2002然后继续比较所需资源与记分板单元2006通告的可用资源。如果所需资源的数量小于或等于记分板单元2006所通告的可用资源的数量,则ifd2002声明有足够的资源。当对于所有有效指令存在足够的资源时,指令被传送到记分板单元2006。指令标签是所有有效指令所需的资源。非法指令被视为无效,因此不会消耗任何资源。
图20示出了基于指令类别的所需资源的示例表。对于该示例,使用整数寄存器x0作为其目的地寄存器的指令不需要vtir资源。在将下一个指令发送到记分板单元2006之前,ifd2002等待最小指令分配周期。最小时间段取决于记分板单元2006用最新指令束来更新资源状态并让新更新的状态信息回到ifd2002以进行下一指令束评估所需的时间。
记分板单元(sbm)
图21示出了etm2100的sbm2102的示例示意图,etm2100是处理器的中央控制单元。这样,sbm2102跟踪记录关于运行中指令和资源使用的信息,以便确保处理器的适当操作。sbm2102的主要功能包括资源管理、源输入依赖性跟踪和运行中指令以及提交状态跟踪。sbm2102从ifd2106接收经解码的指令,并向exm2108提供资源可用性信号以触发指令的执行。
资源管理
ifd2106依赖性于来自sbm2102的资源可用性信息来确定其是否能够转发ififo头部的指令束。因此,准确和及时地更新当前资源状态对于处理器的最佳操作至关重要。sbm2102具有资源管理器2104,其管理以下资源并且向ifd2106通告其可用性:指令标签;salu队列条目;smul队列条目;vmac队列条目;valu队列条目;vlut队列条目;加载队列条目;存储队列条目;分支队列条目;ccm队列条目;加载缓冲区;存储缓冲区;bru缓冲区;虚拟临时整数寄存器(vtir);和虚拟临时向量寄存器(vtvr)。
当ifd2106确定资源要求和当前指令束的可用性之间存在匹配时,就从ififo的头部提取指令束,并将解码的指令发送到sbm2102。然而,当sbm2102从ifd2106接收到该束时,sbm2102不知道当前指令束的资源要求,只知道有足够的可用资源。基于解码的指令信息,sbm2102计算当前束的资源使用,并为后续指令束更新资源可用性。
sbm2102将当前指令束所消耗的资源标记为“使用中”。当exam2108释放资源时,其向sbm2102发送相应的资源释放信号,sbm2102又将资源标记为可用。
指令标签
sbm2102向所有有效指令(包括nop,其可用于除了解决依赖性和流水线危险之外的其他功能)分配标签。在指令的整个生命周期中,指令标签用于跟踪记录指令状态并保持指令顺序。对于本例,在sbm2102中可以有32个可用标签。sbm2102将标签作为资源来管理,并且当被分配给指令时将标签标记为“使用中”,并且当指令终止时释放标签。此外,sbm2102跟踪记录标签分页,该标签分页每当当前标签索引回滚到零时进行触发。标签、标签分页和冲洗标志信息形成与指令一起发出的唯一标识符。标签分页仅在加载和存储地址冲突解决期间由lsc使用。在将两个指令与索引回滚之前和之后的标记进行比较时,需要分页位。sbm2102可以具有用于跟踪指令状态、指令标签等的指令状态单元2110。
对于nop指令这种特殊情况,sbm2102分配标签并将其记录在ift2106中以用于调试和跟踪目的。然而,sbm2102会立即终止nop指令,并且不将其发送到exm2108。
vtir和vtvr
如果指令生成的结果去往整数或向量寄存器中的位置,则sbm2102分配虚拟临时寄存器。有两种类型的虚拟临时寄存器:虚拟临时整数寄存器(vtir)和虚拟临时向量寄存器(vtvr)。vtir和vtvr用于将指令结果分别保存在整数和向量指令的临时位置,从而使得推测性结果在结果被写入目的地整数或向量寄存器之前可用于后续指令。sbm2102可以具有vtir/vtvr映射表2112和vtir/vtvr计数表2114。
类似于标签,sbm2102将vtir和vtvr作为可消耗资源管理。因此,它们在被分配时被标记为“使用中”,并且在相应的指令终止时被释放。vtir和vtvr由它们的虚拟索引引用,其可以包括以下信息:超额预定(over-subscription)(1位)和物理临时寄存器索引(5位)。
为了使释放vtir和vtvr的等待时间最小化,sbm2102实施了临时寄存器的“超额预定”。使用二比一的超额预定比率,sbm2102分配虚拟索引并且允许以同一物理临时寄存器位置为目标的两个指令同时处于运行中。换句话说,sbm2102可以用超额预定的vtir或vtvr向exm2108发送指令,而不验证它们引用的物理临时寄存器的可用性。
一旦指令到达exm2108中的预获取缓冲区,则在将指令发送到作为目标的计算资源(cr)之前,exm2108负责验证该物理临时位置的可用性。sbm2102跟踪记录每个vtir和vtvr的提交状态和“队列中”状态。exm2108使用vtir/vtvr提交和“队列中”状态来确定指令是否可以安全地分派到cr而不至有覆盖前置指令结果内容的风险,所述前置指令结果在终止之前被分配给同一个物理寄存器。
此外,sbm2102基于cr分配固定的vtir和vtvr索引。例如,sbm2102向salu0分配vtir索引0到3,然后是32到35。顺序地分配索引,使得由salu0执行的指令将以轮叫方式将其结果写入所分配的vtir。一旦所有物理索引(上述示例中的0到3)用尽,sbm2102就超额预定vtir和vtvr索引,将超额预定位设置为1(在上面的示例中为32到35)。
图23示出了分配给每个cr的vtir和vtvr索引的表。映射索引以在定位虚拟临时寄存器时提供位4∶2的简易解码。未使用的vtir/vtvr索引则被保留。
vtir和vtvr计数表
作为资源管理功能的一部分,sbm2102跟踪记录引用特定vtir和vtvr位置用于其源输入的指令的数量。该信息保存在vtir和vtvr计数表2114中。每次sbm2102分配一个引用特定vtir和vtvr用于其任何源输入的指令,都使关联计数器增量。然后,当指令离开预获取阶段时,exm2108将vtir/vtvr计数释放信号发送到sbm2102。该释放信号是基于每条指令的。即使指令多次使用相同的vtir或vtvr位置作为其源输入,但对于由该指令引用的每个vtir(或vtvr),sbm2102也仅预计一个释放信号。当sbm2102接收到释放信号时,就使vtir或vtvr计数减量。在关联的vtir或vtvr资源可以被释放以供重复使用之前,vtir/vtvr计数器值必须为零。换句话说,在可以被sbm释放之前,不能有任何引用该vtir或vtvr的未决的指令。
cr队列和缓冲区
与其他资源类似,sbm2102将cr队列条目可用性和ld、st、bru缓冲区可用性作为资源进行管理,当被分配时将其标记为“使用中”,然后当从exm2108接收到释放信号时进行释放。sbm2102支持图24的表中所示的cr队列/缓冲区分配。ld和st缓冲区在整数和向量指令之间共享。
源输入依赖性跟踪
为了跟踪记录源输入依赖性,sbm2102将最新的临时寄存器分配信息存储在vtir和vtvr映射表2112中。这两个表存储有分配给目的地整数寄存器(ir)和向量寄存器(vr)位置的vtir和vtvr的最新索引。vtir和vtvr映射表2112还跟踪记录每个临时寄存器的运行中状态。当vtir或vtvr被分配给指令时,其被视为“运行中”,直到其内容被提交到ir或vr中的目的地寄存器位置为止。这在图25中用标号2514示出。
图25示出了sbm2102的示例性数据流。在2500,当sbm2102从ifd2106接收到指令束时,在2506,sbm2102对指令进行解码,并且通过参考vtir和vtvr映射表2512来确定每个操作数的源输入的原点。如果源输入来自运行中vtir或vtvr,则sbm2102设置cr的指示以从分配给ir或vr的当前vtir或vtvr读取源输入。否则,sbm设置cr的指示以直接从ir或vr读取源输入。
同时,sbm2102用分配给当前指令束的最新vtir和vtvr来更新vtir和vtvr映射表2112。vtir和vtvr映射表2512分别由ir和vr位置进行索引,如图25所示。
在2504,sbm2102将原始ir/vr源输入索引(在2508处作为源输入映射示出)和它们的虚拟寄存器映射(在2510处作为目的地映射示出)发送到exm。在2516,将解码的指令提供给exm2504。
当遇到控制转移(跳转或分支)指令、异常或系统指令所引发的程序不连续性(冲洗请求)时,sbm2102将当前vtir和vtvr映射表2512的状态保存到堆栈中。由于处理器支持最多四个活动中的程序不连续性,因此潜在必须保存最多四个vtir/vtvr映射2512。堆栈中的vtir和vtvr映射2512继续更新运行中状态信息,同时保持vtir/vtvr映射的内容静态。在冲洗的情况下,sbm在与引起冲洗的指令相关联的堆栈中检索vtir/vtvr映射2512,并且当操作从冲洗恢复时,使它们成为“活动”映射。由于映射的内容反映了冲洗前指令所用的临时寄存器分配,并且该映射中的临时寄存器的运行状态是最新的,所以sbm2102具有最新的冲洗前vtir和vtvr分配信息,可为冲洗后指令正确地确定源输入依赖性。在一些示例中,整数寄存器(x0)的第一地址位置可以硬连线为全零。因此,如果目的地寄存器被设置为x0,则sbm2102不分配临时寄存器。如果sbm2102在从冲洗恢复操作之前要等待所有冲洗前指令提交它们的结果,则不需要在堆栈中存储vtir和vtvr映射。
运行指令表(ift)
sbm2102实施了运行表(ift)2106(图22)以跟踪记录关于指令的相关信息,其稍后在指令生命周期中进行使用。ift2106具有32个条目,并且用指令标签进行索引。
ift表2106中的条目可以包括以下信息:标签“使用中”指示(1位);指令提交状态(1位);nop指示(1位);需要的vtir(1位);需要的vtvr(1位);目的地ir或vr(5位);目的地vtir或vtvr(6位);和pc(32位)。
由于vtir和vtvr所需的字段是相互排斥的(一个指令只有一个目的地寄存器,因此只能消耗一个虚拟临时寄存器),目的地ir/vr和目的地vtir/vtvr的类型(整数或向量)可以使用vtir和vtvr所要求的字段来确定。
当sbm2102向exm2108发送指令时,会将ift2106条目写入表的标签位置。同时,sbm2102将该条目标记为“使用中”,将提交状态标记为“未提交”。当指令的结果已被提交到最终目的地寄存器时,sbm2102从exm2108接收标签释放信号。在这种情况下,sbm2102将提交状态设置为“已提交”,并将该条目标记为“未使用”,从而释放该标签并使其可用于重新分配。除了释放标签之外,sbm2102查找与该标签相关联的ift条目,以确定该指令是否使用了vtir或vtvr资源。如果使用了vtir或vtvr资源,则sbm等待vtir或vtvr计数表中的相关条目等于零并释放该临时寄存器资源。
对于不生成结果的指令,该条目在分配时标记为已使用,但“提交状态”仍为“已提交”。对于这样的指令,不需要vtir或vtvr释放。
ift2102条目保留在表中,直到条目被重新分配并被后续指令覆盖。
临时寄存器提交状态和队列中状态位
除了用于标签的“提交”和“使用中”指示符之外,sbm2102还记录着临时寄存器的提交和队列内状态,以便例如支持2∶1超额预定。当临时寄存器被提交到ir或vr时,设置vtir/vtvr提交状态位,并且当sbm2102将临时寄存器分配给后续指令时,清除vtir/vtvr提交状态位。类似地,sbm2102还维护临时寄存器的“队列中”状态。临时寄存器(vtir和vtvr)在被sbm2102分配的时间直到exm2108发送相关指令到目标cr以供执行的时间为止,被认为是在“队列中”。当指令离开预获取阶段并进入执行阶段时,exm2108向sbm发送释放信号,以清除分配给指令的临时寄存器的“队列中”状态。
vtir和vtvr提交和队列中状态位由exm2108使用以确定超额预定的临时寄存器是否已经被提交或已被重新分配给后续指令。当设置任何一个状态位时,exm2108可以从预获取缓冲区分派等待中的指令,而无覆盖先前超额预定的临时寄存器位置的可能性。
推测状态位
sbm2102跟踪记录推测性指令。处理器将任何能导致指令流水线冲洗或者能创建异常的指令视为推测性。以下是推测性指令的示例:跳转和分支指令;系统指令(sbreak,scall);以及加载和存储指令。可潜在导致算术异常(即浮点除以零)的指令不被视为推测性指令。
当sbm2102发出推测性指令时,其将其推测状态位标记为推测性。当指令的推测性质被解决时,lsc或bru发送推测释放信号到sbm。sbm清除推测状态位。然后,当所有前置指令的推测性已被移除时,rcc使用此信息来允许提交指令。
冲洗状态位
sbm2102从bru接收冲洗请求信号以及与引起冲洗的指令相关联的标签和bru缓冲区索引。当接收到冲洗信号时,sbm取消声明其就绪信号以阻止ifd2106发送任何更多的指令。然而,sbm2102在处理冲洗之前会先完成对当前指令束的处理。
如前面部分所述,sbm2102会从堆栈中检索与bru缓冲区索引相关联的vtir和vtvr映射,并使它们成为与冲洗后指令一起使用的活动vtir和vtvr映射。另外,sbm2102释放标签、vtir和vtvr资源等被推测性地分配给在引起冲洗的指令之后的指令。这允许sbm2102在操作恢复时将资源重新使用于冲洗后指令。
sbm2102跟踪记录冲洗标记(fm)。每次发生冲洗时,sbm2102增量fm,并且当操作从冲洗恢复时,使用更新的fm。在增量fm之前,sbm2102设置被冲洗指令的冲洗状态位。冲洗状态位与当前冲洗标记相关联。exm2108使用冲洗状态位来确定给定指令是否已经被冲洗。
最后,如果导致冲洗的跳转指令生成必须提交到ir的结果,则sbm2102清除与该指令相关联的推测位。这允许rcc控制提交排序和标签的释放,并且vtir的发生如同正常流。同时,sbm2102声明其就绪信号,以向ifd指示其可用于处理冲洗后指令。
如果冲洗指令没有要提交到ir的结果,则sbm2102释放引起冲洗的指令的标签,并立即设置其就绪状态。
当操作在冲洗之后恢复时,sbm2102分配标签、vtir和vtvr资源,分配过程从由于冲洗而被释放的资源开始,但是使用新的冲洗标记。例如,如果具有标签4的指令引起了冲洗,并且标签5、6和7已经用冲洗标记2冲洗,则当操作重新开始时,sbm2102将标签5分配给具有更新了的清除标记3的第一个冲洗后指令。使用来自exm2108的正常释放信号来释放其他资源,例如队列条目。因此,除了标签释放之外,即使使用资源的指令已经被冲洗,exm2108也必须发送用于其他资源的释放信号(即cr队列释放)。sbm2102支持最多四个未决的冲洗(冲洗标记)。在一些示例情况下,可能存在超过4个未决的冲洗。如果冲洗标记回滚,并且当在cr队列中仍然有使用某冲洗标记的未决冲洗指令时,sbm2102开始重新使用该冲洗标记,则冲洗状态位被覆盖,并且cr队列中先前被冲洗的指令将潜在地丢失其“冲洗状态”。可以“or”冲洗状态位而不是覆盖它们,以保持先前的冲洗状态等等。否则,就需要跟踪记录“冲洗状态释放”以防止这种情况出现,无论其可能性有多低。
异常处理
sbm2102不在单元内生成异常。然而,当ifd2106检测到异常(例如imem数据错误、非法指令)时,会将异常指示转发到sbm2102。sbm2102继而将标签分配给引起异常的指令,并将其发送到bru。
bru按顺序处理异常请求,声明冲洗请求,并将其与引起冲洗的指令的标签一起,发送到其他单元。冲洗的原因(分支、跳转或异常)也由bru发布。如果冲洗是由异常引起的,则sbm2102查找与该冲洗标签相关联的ift条目并检索程序计数。然后,sbm2102将异常pc发送到ccm。
寄存器提交控制器(rcc)
在终止阶段期间,rcc执行管理提交排序的任务。图26示出了rcc2600的框图。
处理器分别为ir2604和vr2606支持五个和四个提交端口。rcc2600基于vtir和vtvr功能组2608、2610来分配提交端口。图27提供了示出提交端口分配的示例表。当指令产生整数或向量结果时,必须在指令完成时(如果指令没有被冲洗)提交到分配的整数或向量寄存器,同时保持指令提交序列的顺序。该提交顺序基于在指令评估阶段sbm分配给指令的标签的“寿命”来确定。
rcc2600跟踪记录提交指针。从当前提交指针指向的标签开始,rcc评估最多八个连续指令标签和相关联的推测状态位,以便确定是否可以提交该结果。此外,rcc2600参考ift2602以确定指令是否要求将该结果提交到ir或vr。
如果前置指令的所有未决推测已经解决,并且如果指令要求其结果被写入整数或向量寄存器,则rcc2600通过设置与每个vtir或vtvr相关联的ok2commit位2612来允许提交通过。
在设置ok2commit位2612之前,rcc2600不必等待指令结果在临时寄存器中可用。基于ok2commit值,rcc2600中的提交请求生成器(crg)选择应当提交哪个由提交端口所服务的临时寄存器(基于轮叫优先级方案),并且将提交请求发送到作为目标的临时寄存器组。一旦crg将提交请求发送到exm中的vtir或vtvr组2608、2610,就会在发出下一个提交请求之前等待来自exm的确认。
类似地,rcc2600设置ok2term位2614以指示所有先前的推测已经解决。这些位由指令标签引用。ok2term位2614由exm用于确定是否所有先前的推测性指令都已被清除,从而确定是否可以将st数据发送到dmem。bru还使用ok2term位2614在生成冲洗或异常请求信号之前确定先前的推测性指令状态。ccm使用ok2term位2614以便确定是否能够更新控制和状态寄存器(csr)的内容。
不导致冲洗的分支指令不必在为该指令向sbm发送推测释放信号之前等待其ok2term位2614被设置。
整数寄存器单元(irm)
etm实施了32个通用寄存器集。整数寄存器单元(irm)包括32个整数寄存器和支持来自exm的源操作数读请求的读端口。当从exm接收到读请求时,irm查找请求的寄存器内容并在其关联的读数据端口上发送。irm支持15个读端口。到各对应cr的读端口连接的数量在图28的表中示出。
此外,irm支持5个写端口,以将数据从临时整数寄存器提交到ir中。
向量寄存器单元(vrm)
为了支持处理器的自定义扩展,向量寄存器单元(vrm)实施了向量寄存器。vrm为向量cr实施了7个源输入读端口。这些示于图29的表中。此外,vrm实施了4个写端口,以将数据从临时向量寄存器提交到vr中。如果在专用cr(而不是向量cr)中执行32位浮点指令,则必须更新vrm的读端口数。
初始化
etm中的程序计数器设置为初始值为零。在释放处理器核心复位后,etm在启用时开始从imem获取指令。
调试特性
ifd支持单步模式,在该模式下进行对单个指令的获取、评估和执行。指令获取机制由经由处理器外部接口控制的脉冲调节。处理器提供活动状态以指示指令是否已经被终止。
为了方便硬件和软件调试,sbm提供了一种推测覆盖模式,以忽略任何指令的推测性质。
etm通过图30的表中所示的调试端口提供以下可观察的信号。
可控脉冲发生器
除脉冲发生器外,etm内部逻辑只能被监视,不能通过可写调试寄存器进行控制、初始化或配置。只有在单步模式下操作时,脉冲发生器才需要激活自己的“外部触发器”。该模式允许进入到指令生命周期,一次一个阶段。
执行单元(exm)
图31示出了处理器中的执行单元(exm)3100的示例示意图。exm由具有以下示例组件的多个计算资源(cr)3102组成:标量单元(两个salu、一个smul)和向量单元(一个valu、一个vmac、一个vlut);加载和存储控制器(lsc)中的两个加载和一个存储单元;以及一个分支解决单元(bru)。
exm3100的主要任务是指令执行。所有标量和向量cr共享公同的架构,而lsc和bru单元被自定义为分别处理加载/存储和分支/跳转指令。
etm3108发送具有cr的所有所需信息的指令,以在评估阶段3106之后在专用临时寄存器中排队、执行和在专用临时寄存器中存储结果。临时寄存器可被所有其他cr3102使用专用读端口访问,以允许乱序推测性执行。寄存器提交控制器(rcc)在etm3108的终止阶段3104中通过将整数(32位)、浮点(32位)或向量(128位)数据从临时寄存器传送到其目的地寄存器来终止指令。指令的终止仅在来自前置指令的所有推测被解决时进行。
以下示例性特性可以由exm3100实现:解码和路由(通道mux)从etm接收的指令;提供队列以在执行指令之前保存指令;为所有有效指令源操作数生成读取请求;使用计算单元执行指令并将结果存储在临时寄存器中;向其他cr和rcc提供对临时寄存器中的推测性结果的访问;处理来自etm记分板的冲洗状态指示;向etm回报指令状态(用于终止)和资源更新(用于重新分配到新指令)。
本文描述的设备、系统和方法的实施例可以在硬件和软件的组合中实现。这些实施例可以在可编程计算机上实现,每个计算机包括至少一个处理器、数据存储系统(包括易失性存储器或非易失性存储器或其他数据存储元件或其组合)以及至少一个通信接口。
示例性处理器可以包括各种单元或组件。在其他示例中,各单元可以是用于提供本文所描述的功能的硬件和软件模块。
将程序代码应用于输入数据以执行本文所述的功能并生成输出信息。输出信息被应用于一个或多个输出设备。在一些实施例中,通信接口可以是网络通信接口。在元件可以组合的实施例中,通信接口可以是软件通信接口,例如用于进程间通信的软件通信接口。在其他实施例中,可以存在以硬件、软件及其组合来实现的通信接口的组合。
以上描述提供了许多示例实施例。尽管每个实施例表示本发明要素的单个组合,但是其他示例可以包括所公开要素的所有可能组合。因此,如果一个实施例包括要素a、b和c,并且第二实施例包括要素b和d,则也可以使用a、b、c或d的其余组合。
术语“连接”或“耦合到”可以包括直接耦合(其中彼此耦合的两个元件彼此接触)和间接耦合(其中有至少一个附加元件位于两个元件之间)。
尽管已经详细描述了实施例,但是应当理解,可以进行各种改变、替换和变更。
此外,本申请的范围不旨在限于说明书中描述的过程、机器、制造、物质组成、装置、方法和步骤的特定实施例。本领域的普通技术人员从本发明的公开内容中将容易地理解,对于目前存在或将来开发的过程、物质、机器、制造、物质组成、装置、方法或步骤,凡执行与本文所述的相应实施例基本上相同的功能或实现基本相同的结果的,均可以利用。因此,所附权利要求旨在将这些过程、机器、制造、物质组成、装置、方法或步骤等包括在其范围之内。
可以理解,上述和所示的示例仅旨在为示例性的。
- 还没有人留言评论。精彩留言会获得点赞!